Este artículo fue publicado como parte del Blogatón de ciencia de datos
GitHub es una de las plataformas de gestión de código fuente y control de versiones más populares. También es uno de los sitios de redes sociales más grandes para programadores. Los desarrolladores de software lo utilizan para mostrar sus habilidades a los reclutadores y gerentes de contratación. Al analizar los repositorios en GitHub, podemos obtener información valiosa como el comportamiento del usuario, qué hace que un repositorio sea popular o qué tecnologías son tendencia entre los desarrolladores hoy en día, y mucho más.
Puede encontrar el código completo utilizado en el artículo aquí.
He usado los ‘Repositorios de GitHub 2020’ conjunto de datos de Kaggle, ya que es más reciente.
Implementación
Vamos git esto comenzó importando las bibliotecas necesarias y leyendo los datos de entrada,
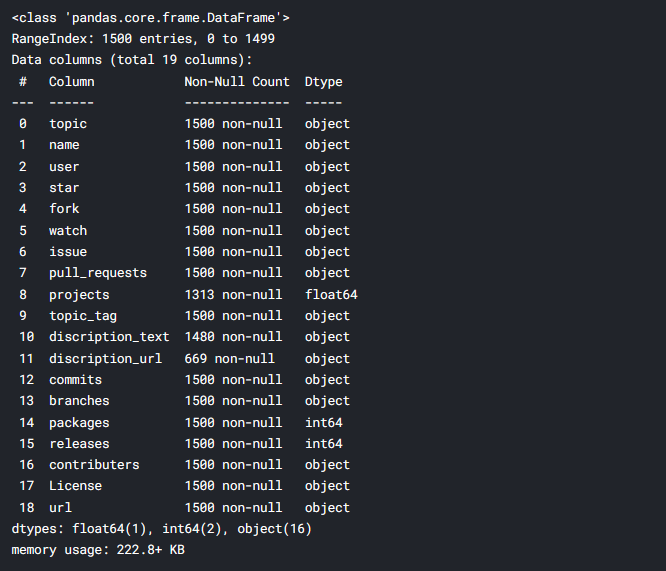
El conjunto de datos contiene 19 columnas, de las cuales elegí 11 columnas basadas en las terminologías más populares de GitHub y las relevantes para el contexto de este análisis. Puede ver que hay errores tipográficos en los nombres de las columnas, los he renombrado para mayor claridad.
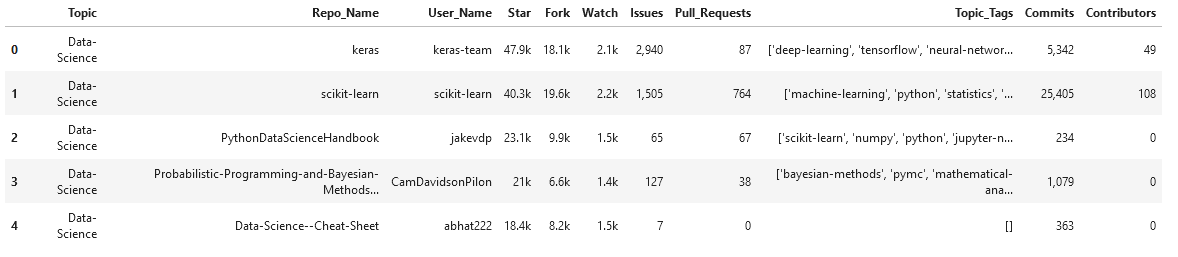
Un breve resumen sobre las columnas de los datos,
- Tema – Una etiqueta que describe el campo o dominio del repositorio.
- Repo_Name – Nombre del repositorio (nombre corto del repositorio)
- Nombre de usuario – Nombre del propietario del repositorio
- Estrella – Número de estrellas que ha recibido un repositorio
- Tenedor – Número de veces que se ha bifurcado un repositorio
- Mirar – Número de usuarios que miran el repositorio
- Cuestiones – Número de problemas abiertos
- Pull_Requests – Total de solicitudes de extracción generadas
- Topic_Tags – Lista de etiquetas de temas agregadas a ese repositorio por el usuario
- Compromete – Número total de confirmaciones realizadas
- Colaboradores – Número de personas que contribuyen al repositorio
Date cuenta cómo Estrella, Tenedor, y Mirar las columnas contienen ‘Kansas para denotar miles, así que vamos a convertirlos en múltiplos de 1000. Además, reemplazando el ‘,’(comas) del Cuestiones y Compromete columnas.
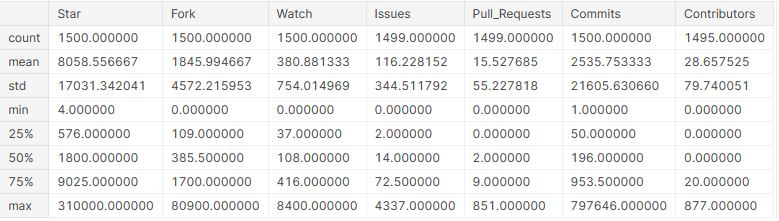
Ahora que las columnas son numéricas, podemos obtener información estadística básica de ellas.
# display basic statistical details about the columns github_df.describe()
1. Análisis de los principales repositorios según su popularidad
¿Qué hace que un repositorio de GitHub sea popular? Esta pregunta se puede responder con 3 métricas: estrella, reloj y bifurcación.
- Estrella: cuando a un usuario le gusta su repositorio o quiere mostrar algo de agradecimiento, lo marca con una estrella.
- Ver: cuando un usuario desea ser notificado de todas las actividades en un repositorio, lo ve.
- Bifurcación: cuando un usuario desea una copia del repositorio o tiene la intención de hacer alguna contribución, la bifurca.
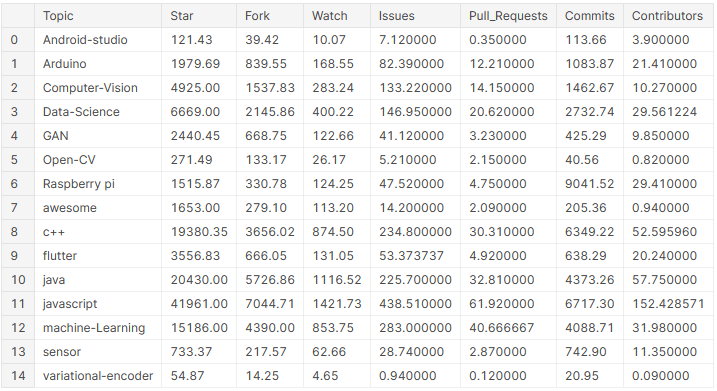
# create a dataframe with average values of the columns across all topics
pop_mean_df = github_df.groupby('Topic').mean().reset_index()
pop_mean_df
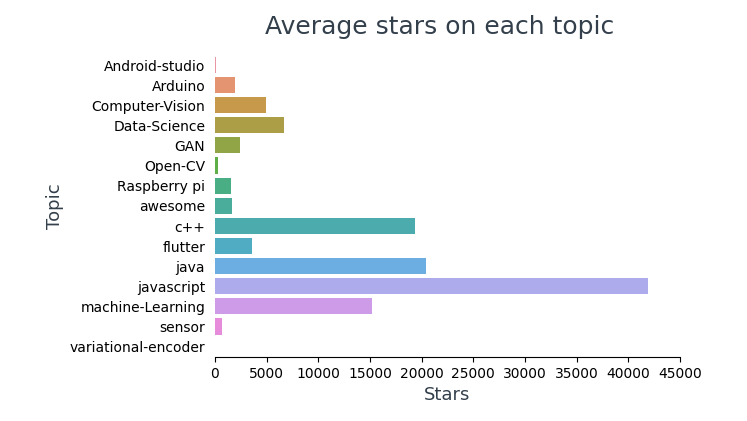
1.1 Análisis de estrellas
Visualizar la cantidad promedio de estrellas en cada tema,
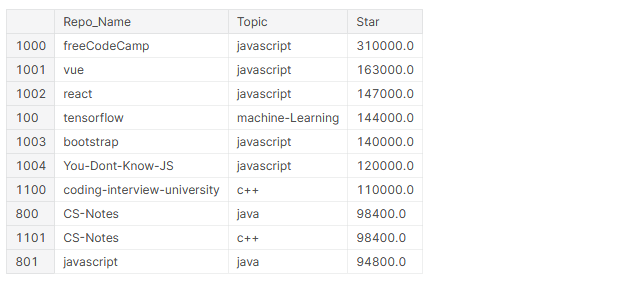
# top 10 most starred repos github_df.nlargest(n=10, columns="Star")[['Repo_Name','Topic','Star']]
# Consejo rápido: '33[1m' prints a string in bold and '33[0m' prints it back normally.
print('Most starred repository is {}{}{} in the topic {}{}{} with {}{}{} stars'.
format('33[1m',github_df.iloc[github_df['Star'].idxmax ()]['Repo_Name'], '33[0m',
'33[1m',github_df.iloc[github_df['Star'].idxmax ()]['Topic'], '33[0m',
'33[1m',github_df.iloc[github_df['Star'].idxmax ()]['Star'], '33[0m'))

In the top 10 most starred repositories, 4 are frameworks (Vue, React, TensorFlow, BootStrap) and 6 of them are about JavaScript.
1.2 Analysis of Watch
Visualizing the average number of watchers across each topic,
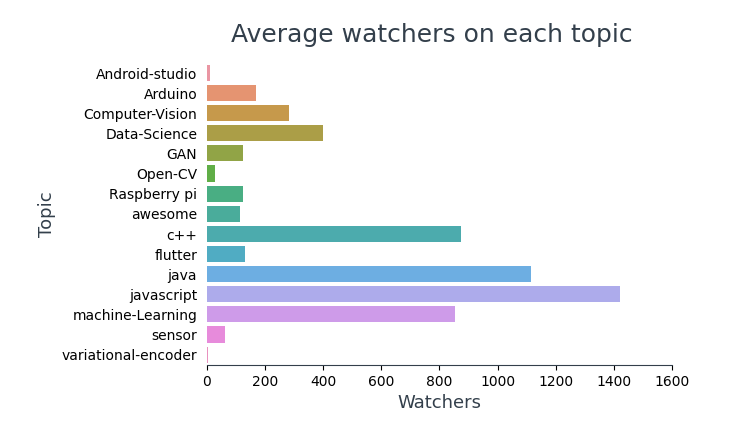
Note: Code for the above graph is the same as the ‘Average Stars on each topic’ except for the column names. I have not added the same to avoid redundancy.
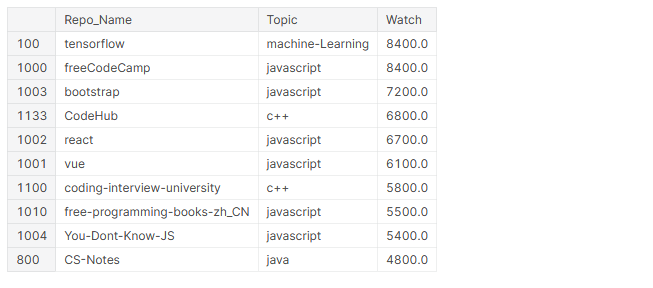
# top 10 most watched repos github_df.nlargest(n=10, columns="Watch")[['Repo_Name','Topic','Watch']]
print('Most watched repository is {}{}{} in the topic {}{}'.
format('33[1m',github_df.iloc[github_df['Watch'].idxmax()]['Repo_Name'],
'33[0m','33[1m',github_df.iloc[github_df['Watch'].idxmax()]['Topic']))

En los 10 repositorios más vistos, 4 son frameworks (TensorFlow, BootStrap, React, Vue), 6 son sobre JavaScript y 5 de ellos contienen contenido de aprendizaje para programadores.
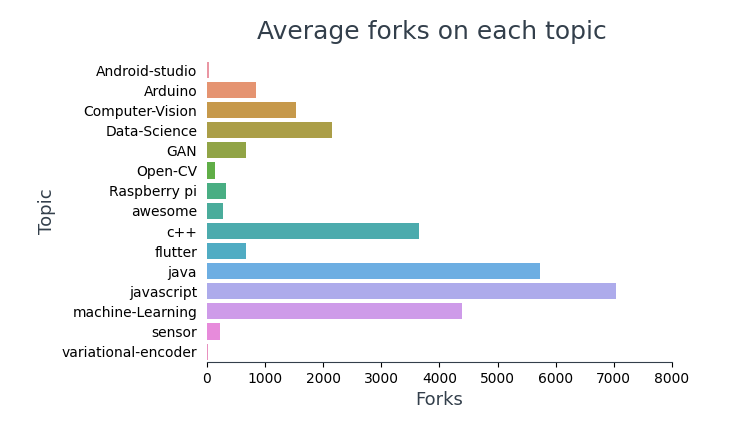
1.3 Análisis de Fork
Visualizar la cantidad promedio de bifurcaciones en cada tema,
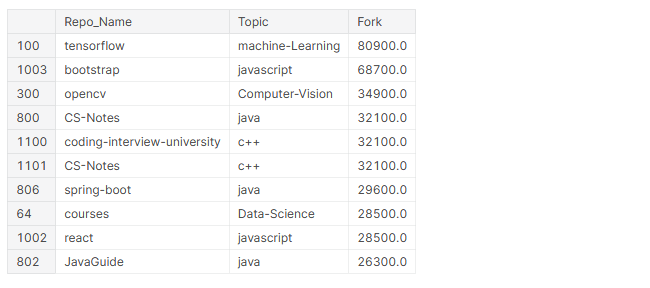
# top 10 most forked repos github_df.nlargest(n=10, columns="Fork")[['Repo_Name','Topic','Fork']]
print('Most forked repository is {}{}{} in the topic {}{}'.
format('33[1m',github_df.iloc[github_df['Fork'].idxmax()]['Repo_Name'],'33[0m',
'33[1m',github_df.iloc[github_df['Fork'].idxmax()]['Topic']))

En el top 10 de repositorios más bifurcados, 4 son frameworks (TensorFlow, bootstrap, spring-boot, react) y 5 de ellos contienen contenido de aprendizaje para programadores.
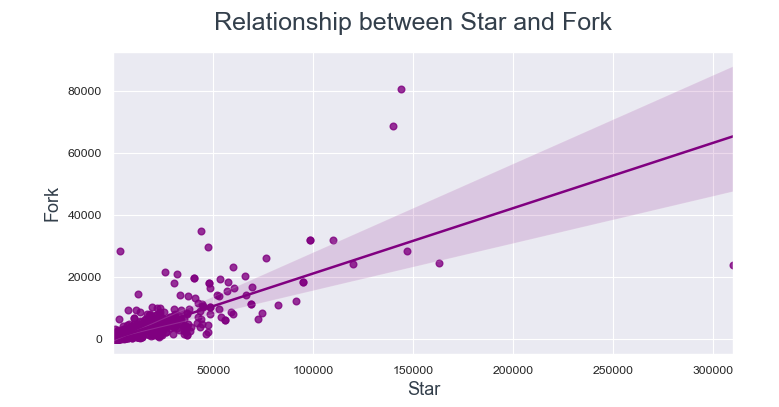
1.4 Relación entre estrella, horquilla y reloj
A menudo, los usuarios bifurcan un repositorio cuando quieren contribuir a él. Entonces, exploremos la relación entre horquilla de estrella y horquilla de reloj.
# set figure size and dpi
fig, ax = plt.subplots(figsize=(8,4), dpi=100)
# set seaborn theme for background grids
sns.set_theme('paper')
# plot the data
sns.regplot(data=github_df, x='Watch', y='Fork', color="purple");
# set x and y-axis labels and title
ax.set_xlabel('Watch', fontsize=13, color="#333F4B")
ax.set_ylabel('Fork', fontsize=13, color="#333F4B")
fig.subtitle('Relationship between Watch and Fork',fontsize=18, color="#333F4B")
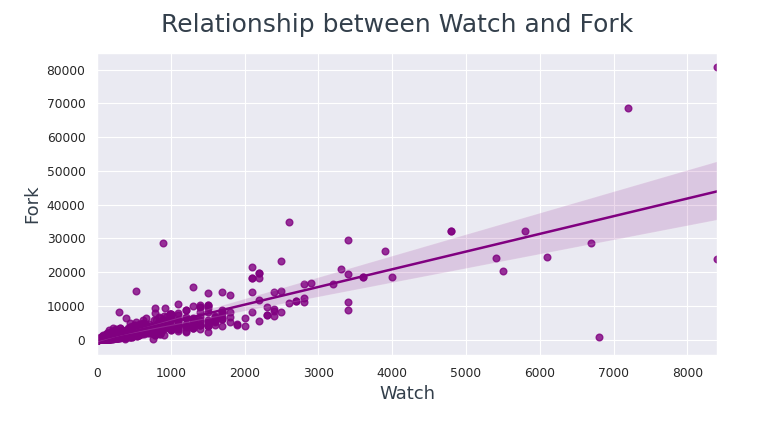
Los puntos de datos están mucho más cerca de la línea de regresión entre Watch y Fork en comparación con Star y Fork.
De esto podemos concluir, si un usuario está viendo un repositorio, es más probable que lo bifurque.
2. Análisis de usuarios con más repositorios
Echemos un vistazo a los usuarios que tienen repositorios más populares.
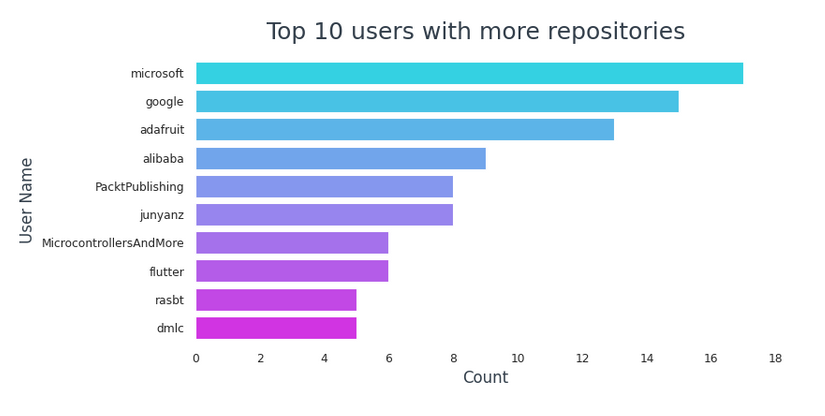
En el top 10 de usuarios con más repositorios,
- Microsoft encabeza la lista con 17 repositorios.
- Google sigue con 15 repositorios.
- 6 de ellos son empresas o propiedad de una empresa (Microsoft, Google, Adafruit, Alibaba, PacktPublishing, flutter)
- 3 son usuarios individuales (junyanz, rasbt, MicrocontrollersAndMore)
3. Comprensión de las actividades de contribución en los repositorios
GitHub es famoso por su gráfico de contribución.
Este gráfico es un registro de todas las contribuciones que ha realizado un usuario. Siempre que un usuario realiza una confirmación, abre un problema o propone una solicitud de extracción, se considera una contribución. Hay cuatro columnas relacionadas con las contribuciones en nuestro conjunto de datos, Problemas, Pull_Requests, Commits, Colaboradores. Veamos si existe alguna relación real entre ellos.
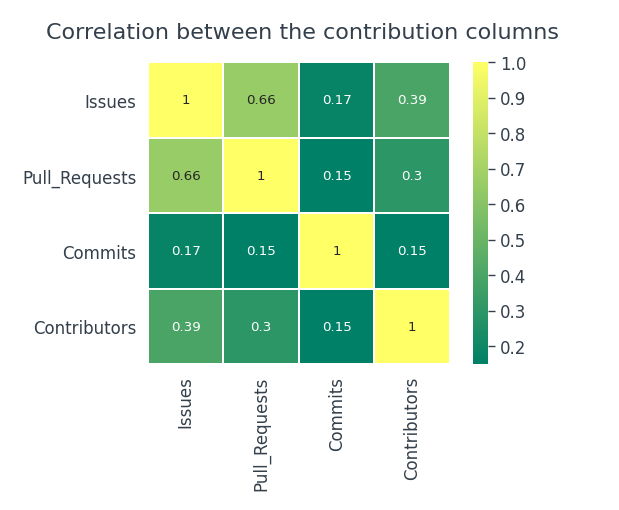
El número de confirmaciones no depende de ningún problema, solicitudes de extracción o contribuyentes. Existe una relación positiva moderada entre los problemas y las solicitudes de extracción.
Exploremos los 100 repositorios más populares y veamos si es lo mismo,
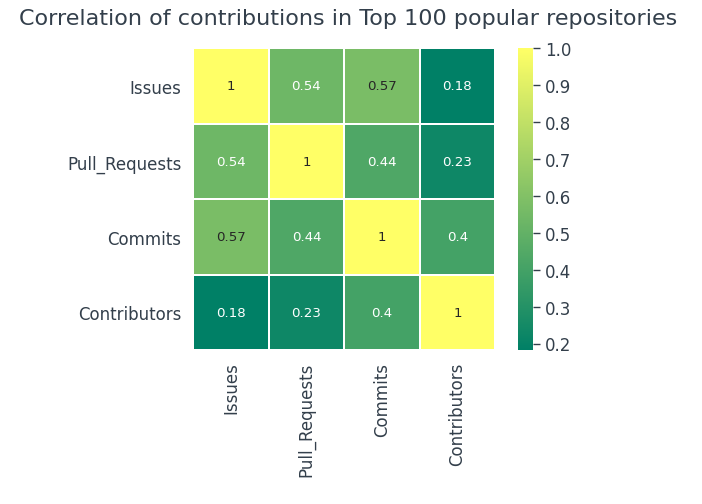
Es casi lo mismo en los 100 repositorios más populares que en el conjunto de datos general.
Busquemos usuarios con más repositorios,
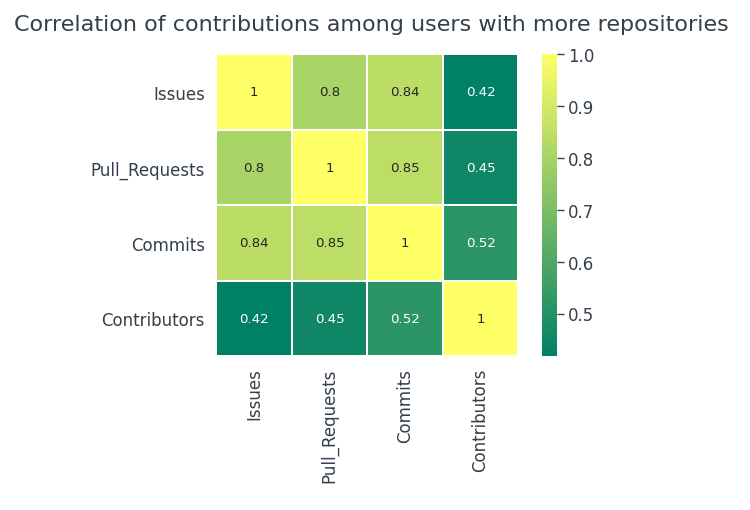
Sorprendentemente, los usuarios con más repositorios tienden a ser más activos. Existe una correlación positiva bastante fuerte entre
- Confirma y extrae solicitudes
- Compromisos y problemas
- Problemas y solicitudes de extracción
En lo que respecta a las contribuciones,
- No existe una relación real entre las actividades de contribución en el conjunto de datos general.
- Tampoco existe una correlación entre las contribuciones en los 100 repositorios más populares.
- Si los usuarios tienden a tener más repositorios, entonces las posibilidades de contribuciones son bastante mayores.
4. Análisis de etiquetas de tema
La columna topic_tags consta de listas. Para encontrar etiquetas populares, convierta toda la columna en una lista de listas y cuente la aparición de cada etiqueta. Con eso, podemos visualizar algunas de las etiquetas de temas más populares y ver qué temas tienden a etiquetarse más.
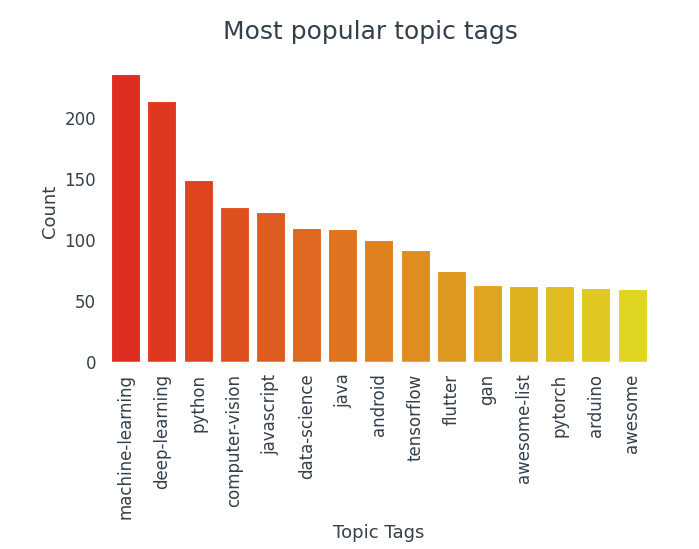
De las 15 etiquetas más populares, 10 pertenecen al mundo de la ciencia de datos.
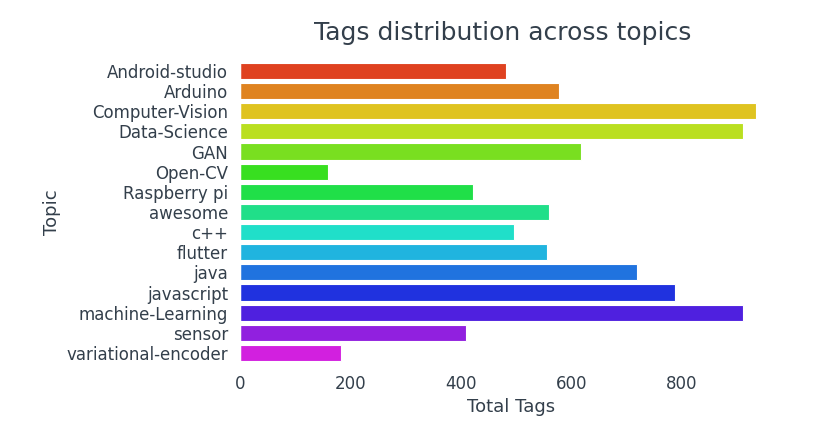
Los repositorios con temas de Visión por computadora, Ciencia de datos y Aprendizaje automático tienden a estar más etiquetados.
Terminemos con una nube de palabras de topic_tags,
Inferencia:
- Entre los 10 repositorios más destacados, vistos y bifurcados, 4 son frameworks.
- Tensorflow es el repositorio bifurcado y más visto.
- Si un usuario está mirando un repositorio, es más probable que lo bifurque.
- Microsoft y Google tienden a ser usuarios con repositorios más populares.
- En el top 10 de usuarios con repositorios más populares, 6 de ellos son empresas.
- No existe una relación real entre las actividades de contribución (problemas, solicitudes de extracción, confirmaciones).
- Las etiquetas más utilizadas son Machine Learning, Deep Learning, Python, Computer Vision, JavaScript.
- Los repositorios con temas de Visión por computadora, Ciencia de datos y Aprendizaje automático tienen más etiquetas.
Si hubiéramos analizado datos de hace una década, estas tendencias habrían sido completamente diferentes. ¡Es como si la ciencia de datos hubiera tenido un crecimiento monstruoso en los últimos años!
¡Gracias por ver todo el camino hasta aquí! Me encantaría conectarme LinkedIn
Avíseme en la sección de comentarios si tiene alguna inquietud, comentario o crítica. ¡Que tenga un buen día!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





