Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
CSV es un tipico formato de archivo es decir de uso frecuente en dominios como METROonetario Servicios, etc. La mayoría de las aplicaciones pueden habilitar usted para importar y exportar conocimiento en formato CSV.
Por lo tanto, es necesario inducir un buen entendimiento del formato CSV a un controlador superior los datos usted está usó con cotidiano.
Entonces, a lo largo de Este artículo, veremos varios casos de operando con archivos CSV y proporcionar ejemplos para vincular todo a lo largo de.
Tabla de contenido
1. ¿Qué es CSV?
2. Operaciones básicas con archivos CSV
- Trabajar con archivos CSV
- Abrir un archivo CSV
- Guardar un archivo CSV
3. ¿Por qué archivos CSV?
4. Conceptos básicos de la función read_csv () de Pandas
- Importación de pandas
- Abrir un archivo CSV local
- Abrir un archivo CSV desde una URL
5. Comprender los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de la función read_csv ()
- parámetro sep
- parámetro index_col
- parámetro de encabezado
- parámetro use_cols
- parámetro de compresión
- parámetro skiprows
- parámetro nrows
- parámetro de codificación
- parámetro error_bad_lines
- parámetro dtype
- parámetro parse_dates
- parámetro de convertidores
- parámetro na_values
Empecemos,
¿Qué es un CSV?
CSV (valores separados por comas) tal vez un formato de archivo simple acostumbrado para almacenar datos tabulares, igual que una hoja de cálculo o una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos..... El archivo CSV almacena datos tabulares (números y texto) en texto sin formato. Cada línea del archivo podría ser un registro de datos. Cada registro consta de 1 o más campos, separados por comas, la utilización de la coma como separador de campo es que el fuente del nombre para este formato de archivo.
Operaciones básicas con archivos CSV
En Operaciones básicas, vamos a entender las siguientes tres cosas:
- Cómo trabajar con archivos CSV
- Cómo abrir un archivo CSV
- Cómo guardar un archivo CSV
Trabajar con archivos CSV
Trabajar con archivos CSV no es esa tarea tediosa pero es bastante sencilla. Sin embargo, contando con tu flujo de trabajo, ahí puede llegar a ser advertencias que simplemente podria querer para observar Fuera por.
Abrir un archivo CSV
Si tienes un archivo CSV, usted ábralo en Excel sin muchos problemas. Solo abre Excel, abierto y busque el archivo CSV para figurar con (o haga clic con el botón derecho en el archivo CSV y elija Abrir en Excel). Después de abrir el archivo, notará que la info es simple texto sin formato en diferentes celdas.
Guardar un archivo CSV
Si tú deseas para ahorrar un montón de su libro de trabajo actual en un archivo CSV, usted tiene usar el posterior comandos:
Archivo -> Guardar como … y elija archivo CSV.
La mayoría de las veces, recibirá esta advertencia:

Fuente de la imagen: imágenes de Google
Entendamos qué nos está diciendo este error.
Aquí Excel está intentando mencionar es que sus archivos CSV no guardan ningún razonable formateo en lo mínimo.
Por ejemplo, No se guardarán los anchos de columna, los estilos de fuente, los colores, etc.
Solo tus datos antiguos están salvado en un excesivamente archivo separado por comas.
Tenga en cuenta que incluso después de usted ponlo a un lado, Excel seguirá mostrando los formatos que tu solo tenía, así que no se deje engañar por esto y piense que después de abrir el libro de trabajo de nuevo que sus formatos seguirán allí. No lo estarán.
Incluso después de abrir un CSV Entra Excel, si aplica un formato bastante en lo mínimo, como ajustar el ancho de las columnas hacer ejercicio la info, Excel todavía te advertirá que tu solo no puedo guardar los formatos que tu solo adicional, usted recibe una advertencia como esta:

Fuente de la imagen: imágenes de Google
Entonces, el objetivo notar es decir sus formatos nunca se pueden guardar en archivos CSV.
¿Por qué archivos CSV?
Los archivos CSV se utilizan como la forma más sencilla hablar datos entre diferentes aplicaciones. Supongamos que tiene una aplicación de base de datos y desea exportar la info a un archivo. Si tú deseas para exportarlo a un archivo de Excel, la aplicación de base de datos haría admite la exportación a archivos XLS *.
Sin embargo, dado que el formato de archivo CSV es extremadamente sencillo y ligero (mucho mucho por lo tanto que los archivos XLS *), es más fácil para variado aplicaciones para apoyarlo. En su uso básico, tiene una línea de texto, con cada columna de datos ir formas alternativas por una coma. Eso es todo. Y debido a esta simplicidad, es simple para los desarrolladores. para hacer Exportar importar sentido práctico con archivos CSV para transferir conocimiento entre aplicaciones en lugar de mucho sofisticado formatos de archivo.
Por ejemplo,
Tengamos una datos tabulados en el formulario dado a continuación:

Si convertimos estos datos en un Formato CSV, entonces se ve así:

Ahora, hemos terminado con todos los conceptos básicos de los archivos CSV. Entonces, en la parte posterior del artículo, discutiremos cómo trabajar con archivos CSV de manera detallada.
Importación de pandas
En primer lugar, importamos las dependencias necesarias como Pandas Biblioteca de Python.
import pandas as pd
Entonces, la dependencia se importa, ahora podemos cargar y leer el conjunto de datos fácilmente.
función read-csv
- Es una función importante de pandas leer archivos CSV y realizar operaciones en ellos.
- Esta función nos ayuda a cargar el archivo desde su máquina local o desde cualquier URL.
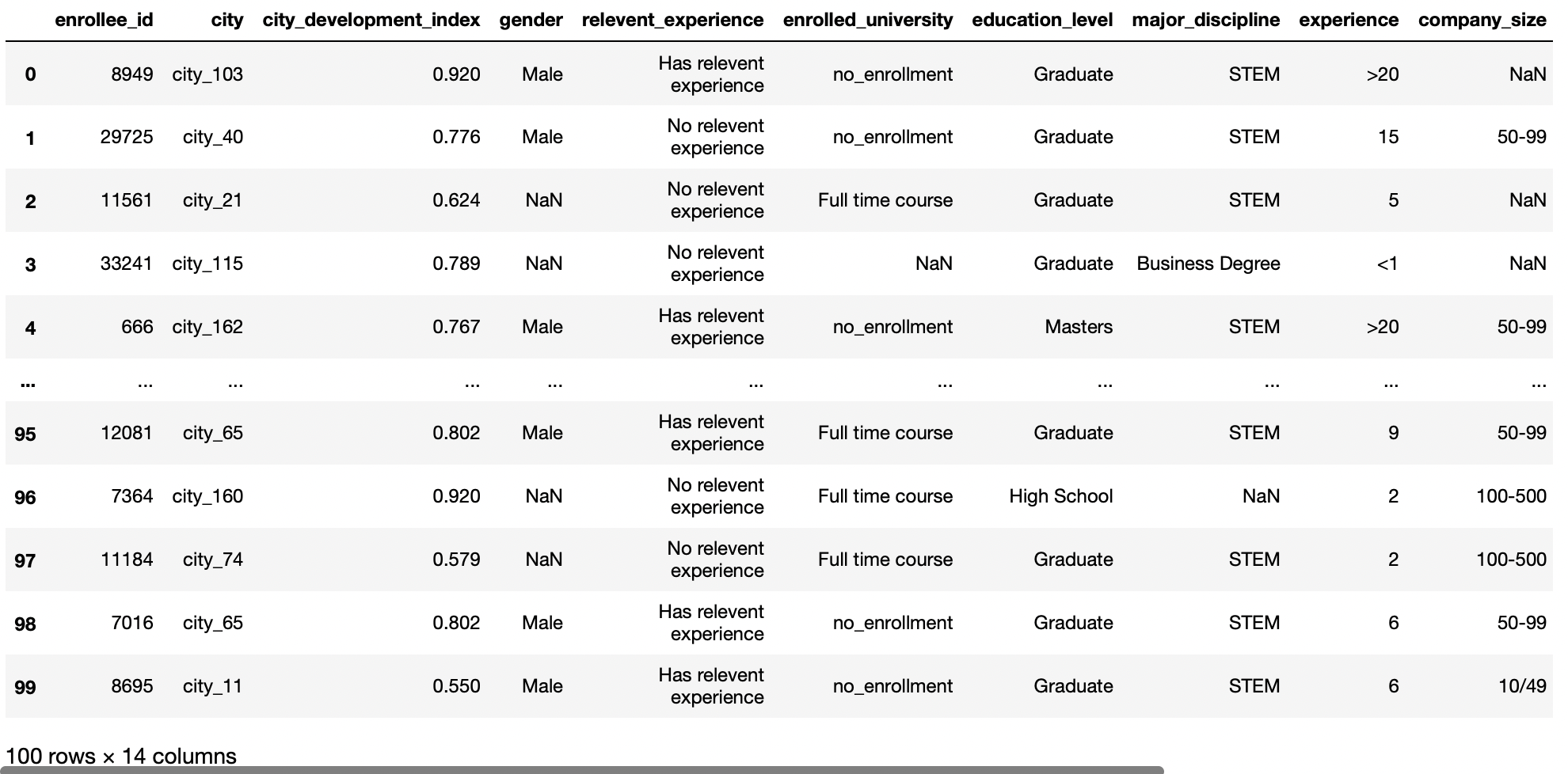
Abrir un archivo CSV local
Si el archivo está presente en la misma ubicación que en nuestro archivo Python, entonces proporcione el nombre del archivo solo para cargar ese archivo; de lo contrario, debe proporcionar la ruta relativa al mismo.
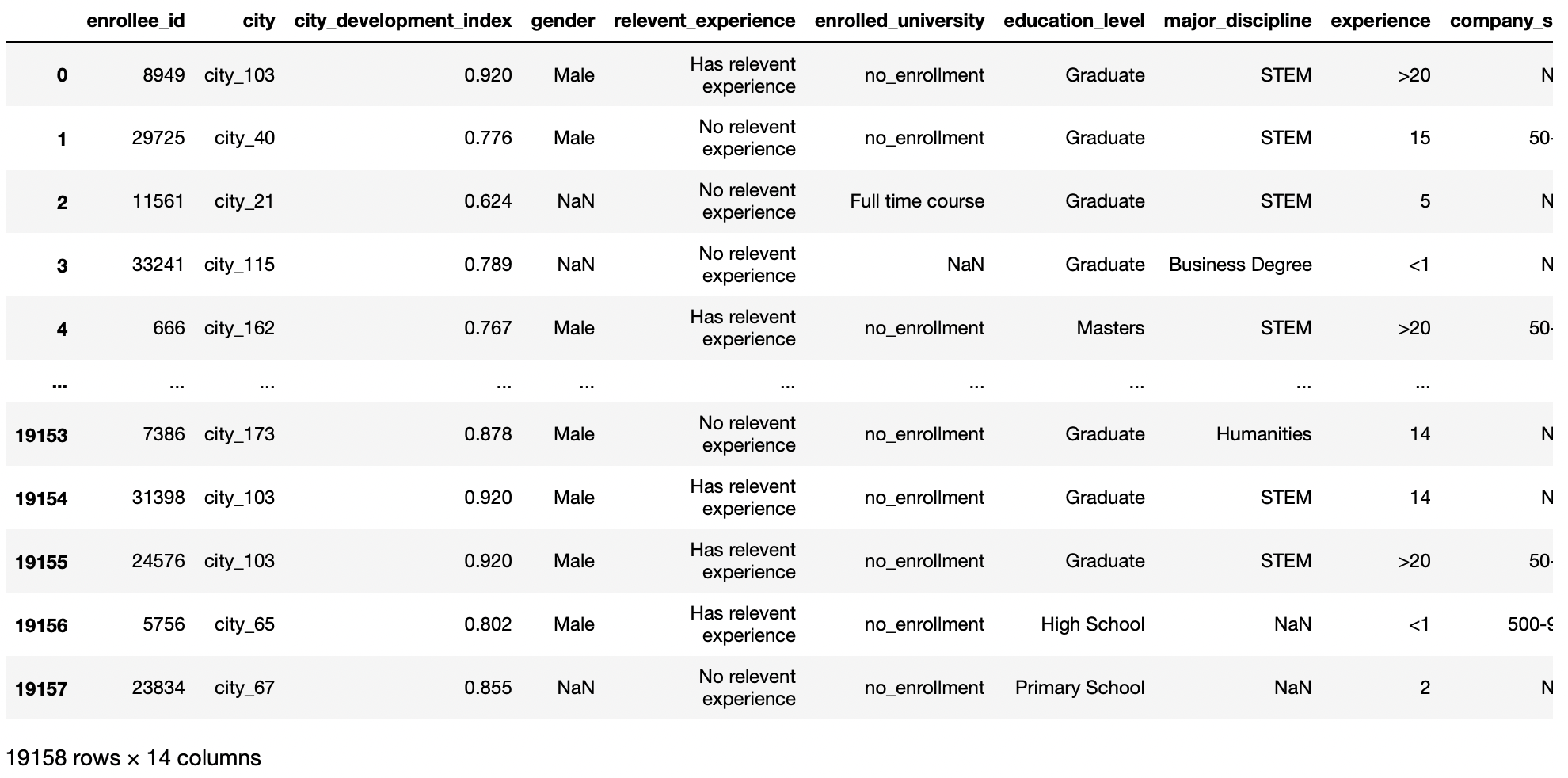
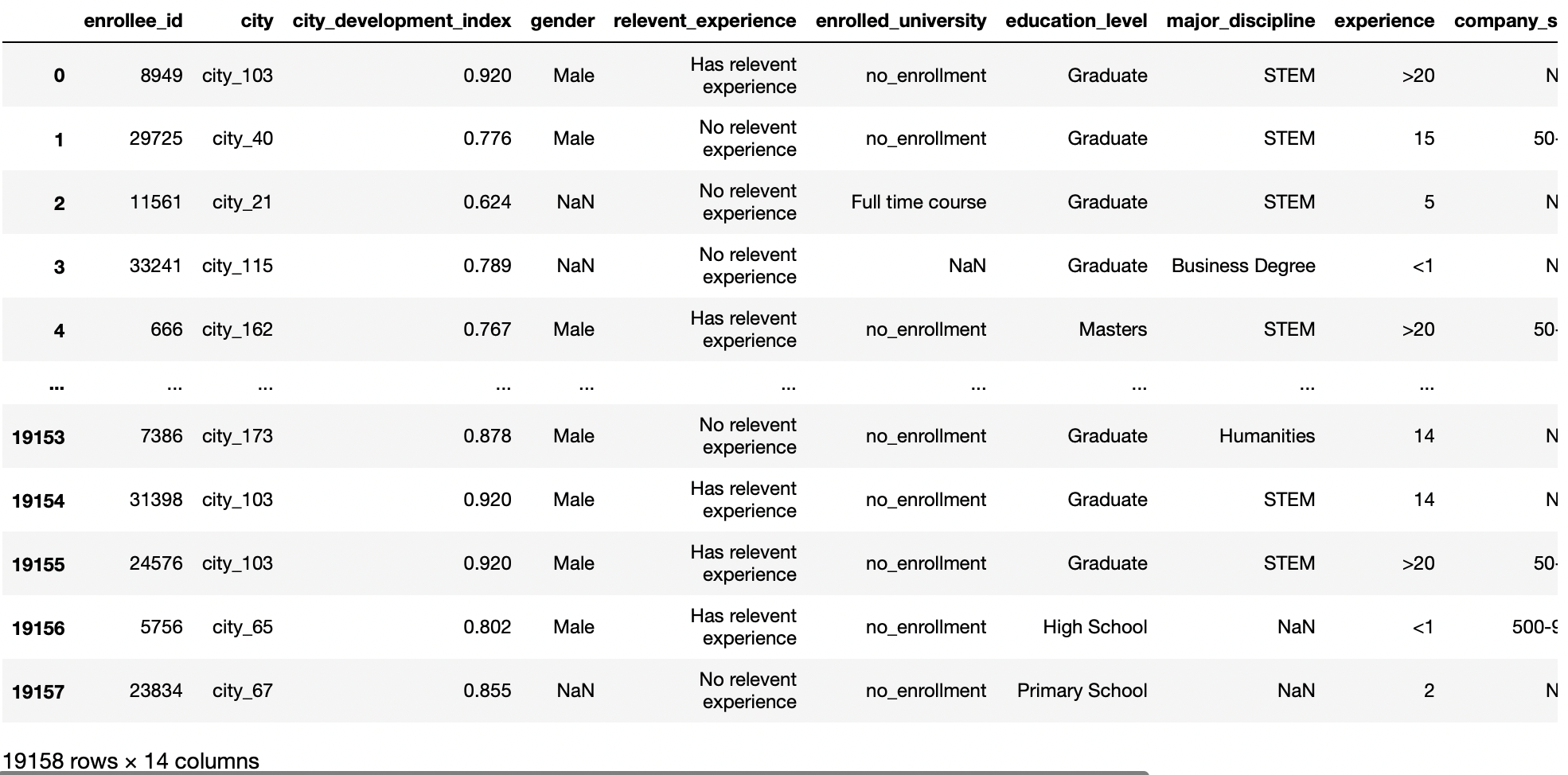
df = pd.read_csv('aug_train.csv')
df
Producción:
Abrir un archivo CSV desde una URL
Si el archivo no está presente directamente en nuestra máquina local, pero tenemos que buscar los datos de una URL determinada, entonces tomamos la ayuda del módulo de solicitudes para cargar esos datos.
import requests
from io import StringIO
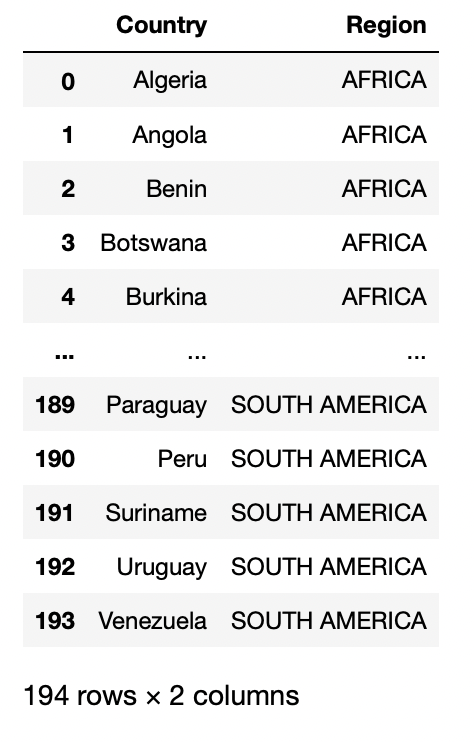
url = "https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0"}
req = requests.get(url, headers=headers)
data = StringIO(req.text)
pd.read_csv(data)
Producción:
parámetro sep
Si tenemos un conjunto de datos en el que las entidades en una fila en particular no están separadas por una coma, entonces tenemos que usar el parámetro sep para especificar el separador o delimitador.
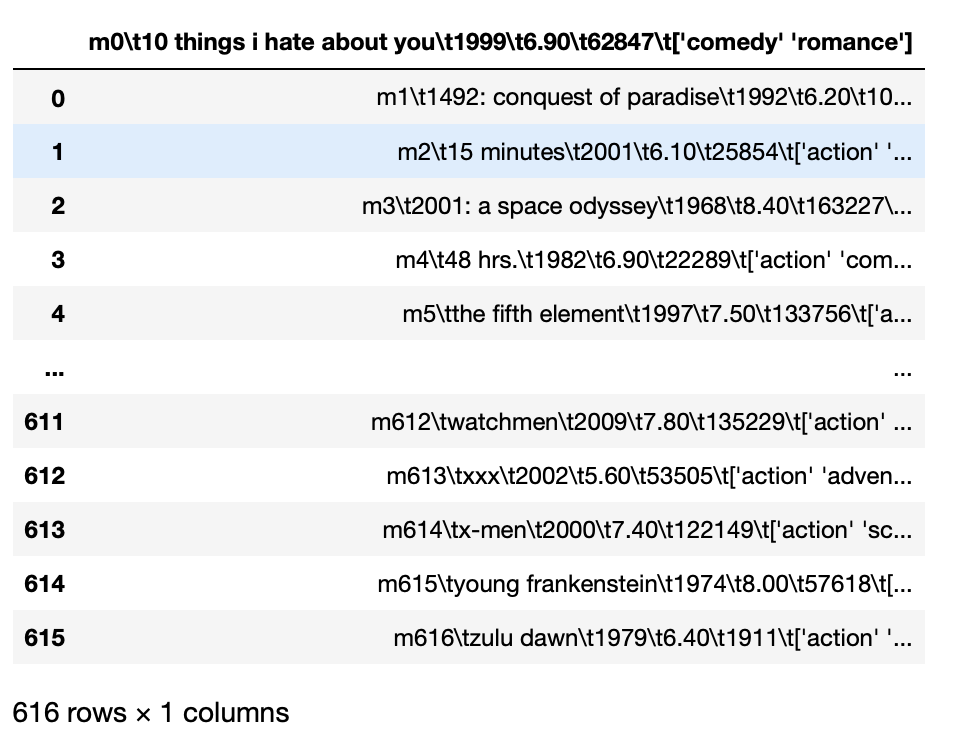
Por ejemplo, Si tenemos un archivo tsv, es decir, las entidades están separadas por tabulaciones y si intentamos cargar directamente estos datos, todas las entidades se cargan combinadas.
import pandas as pd
pd.read_csv('movie_titles_metadata.tsv')
Producción:
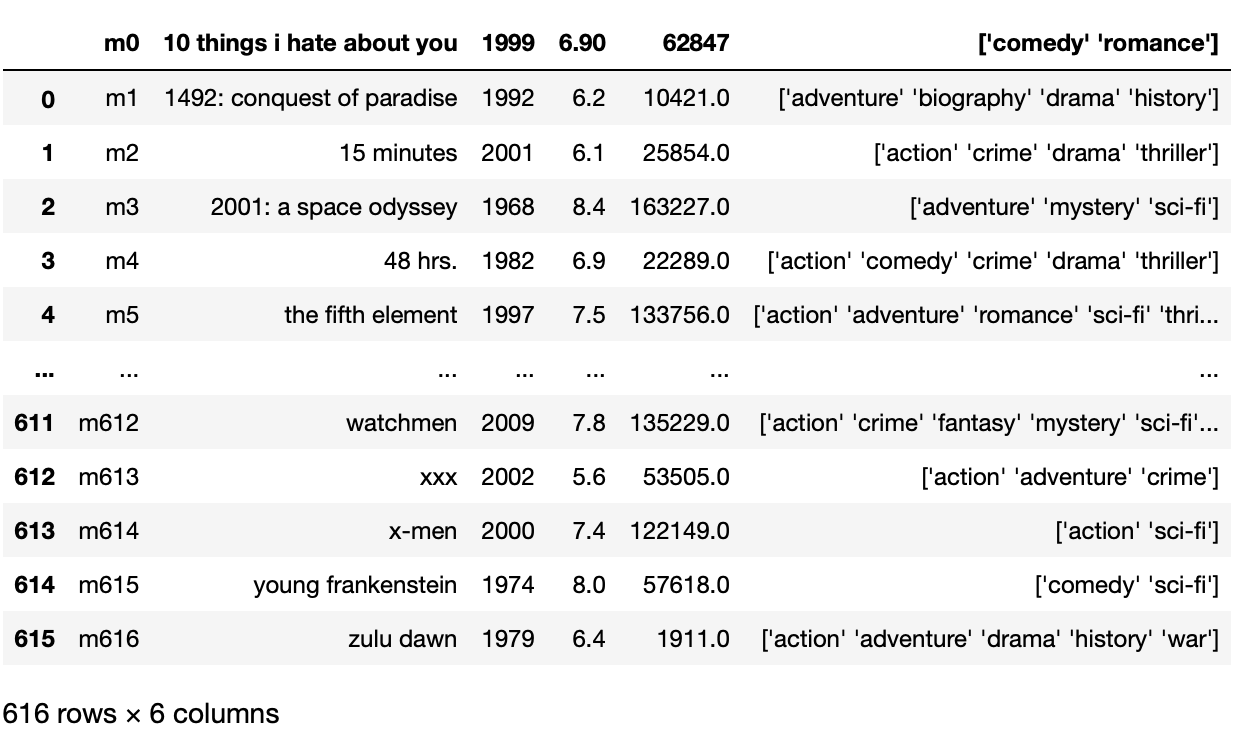
Para resolver el problema anterior para el archivo CSV, tenemos que sobrescribir el parámetro sep para ‘t’ en lugar de ‘,’ que es un separador predeterminado.
import pandas as pd
pd.read_csv('movie_titles_metadata.tsv',sep='t')
Producción:
En el ejemplo anterior, hemos observado que la primera fila se trata como el nombre de la columna, y para resolver este problema y hacer nuestro nombre personalizado para las columnas, tenemos que especificar la lista de palabras con nombres como el nombre de la lista.
pd.read_csv('movie_titles_metadata.tsv',sep='t',names=['sno','name','release_year','rating','votes','genres'])
Producción:
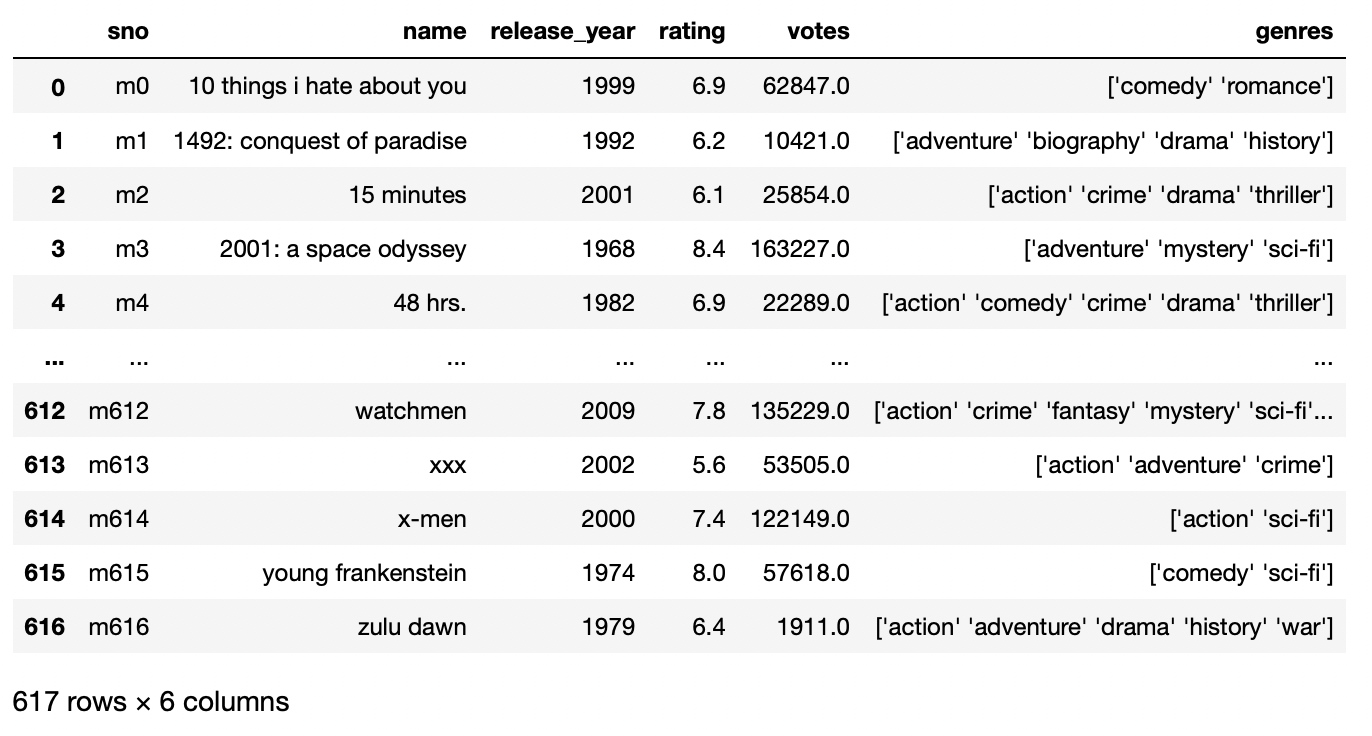
parámetro index-col
Este parámetro nos permite establecer qué columnas se utilizarán como índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... del marco de datos. El valor predeterminado para este parámetro es Ninguno, y los pandas agregarán automáticamente una nueva columna a partir de 0 para describir la columna de índice.
Entonces, nos permite usar una columna como etiquetas de fila para un DataFrame dado. Esta función es útil cuando nos permite tener una columna de ID presente con nuestro conjunto de datos y esa columna no se ve afectada por nuestras predicciones, por lo que hacemos que esa columna sea nuestro índice de filas en lugar del predeterminado.
pd.read_csv('aug_train.csv',index_col="enrollee_id")
Producción:
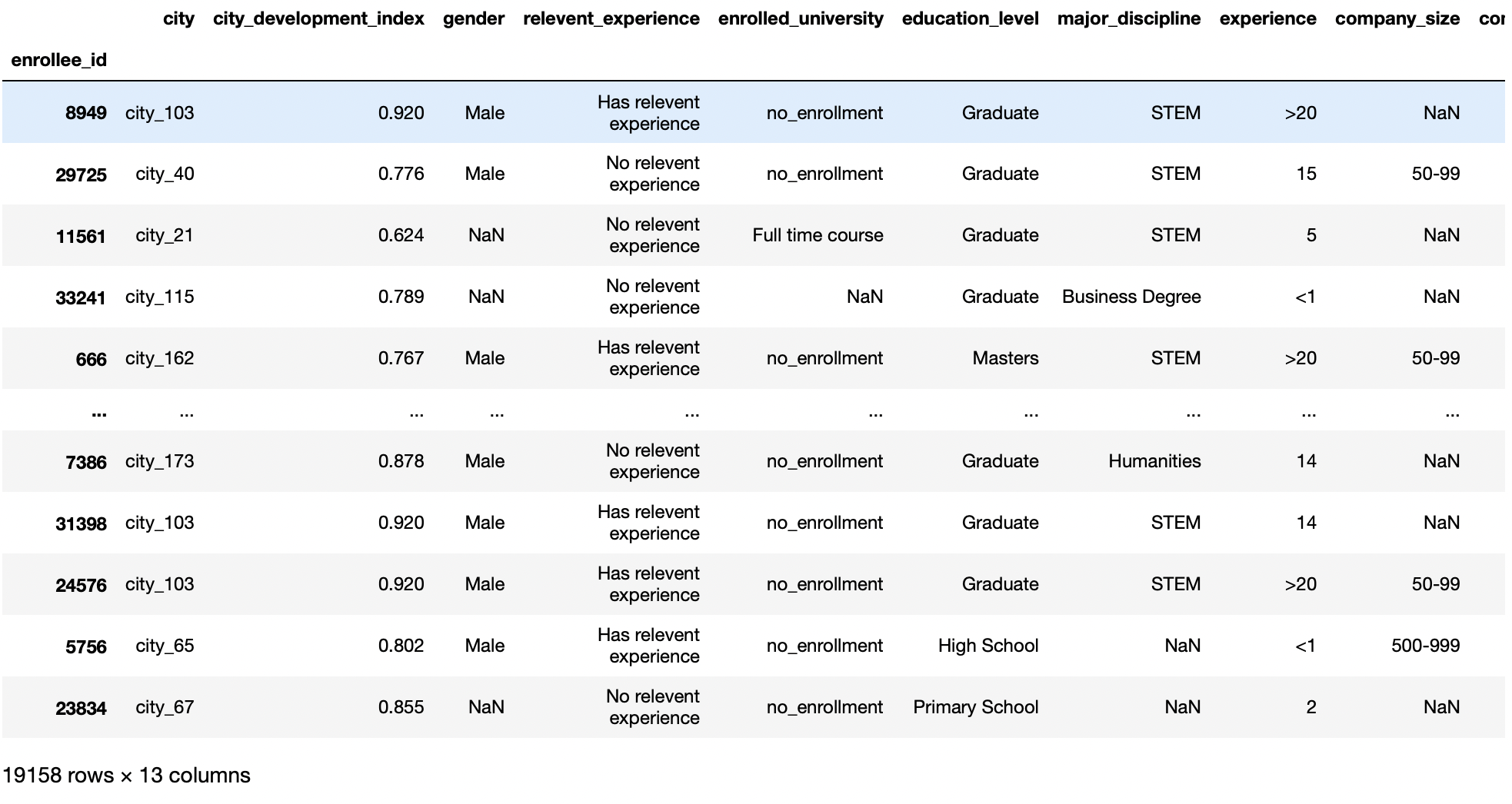
parámetro de encabezado
Esto nos permite especificar qué fila se utilizará como nombres de columna para su marco de datos. Espera la entrada como un valor int o una lista de valores int.
El valor predeterminado para este parámetro es encabezado = 0, lo que implica que la primera fila del archivo CSV se considerará como nombres de columna.
pd.read_csv('test.csv',header=1)
Producción:
parámetro use-cols
Especifique qué columnas importar del conjunto de datos completo al marco de datos. Puede ingresar una lista de valores int o directamente los nombres de las columnas.
Esta función es útil cuando tenemos que hacer nuestro análisis solo en algunas columnas, no en todas las columnas de nuestro conjunto de datos.
Entonces, este parámetro devuelve un subconjunto de las columnas de su conjunto de datos.
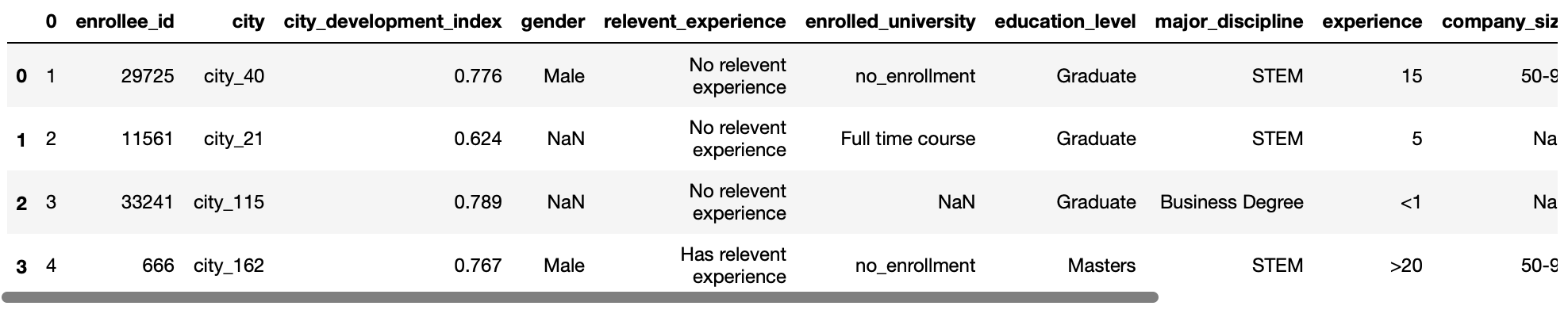
pd.read_csv('aug_train.csv',usecols=['enrollee_id','gender','education_level'])
Producción:
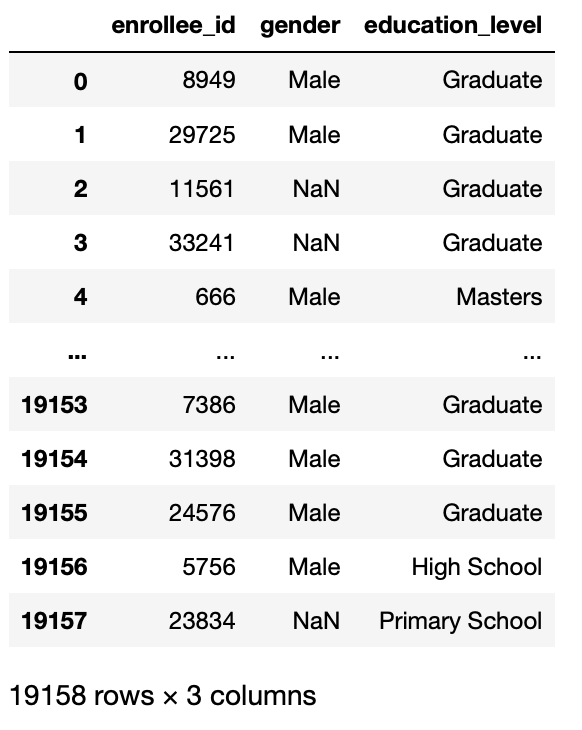
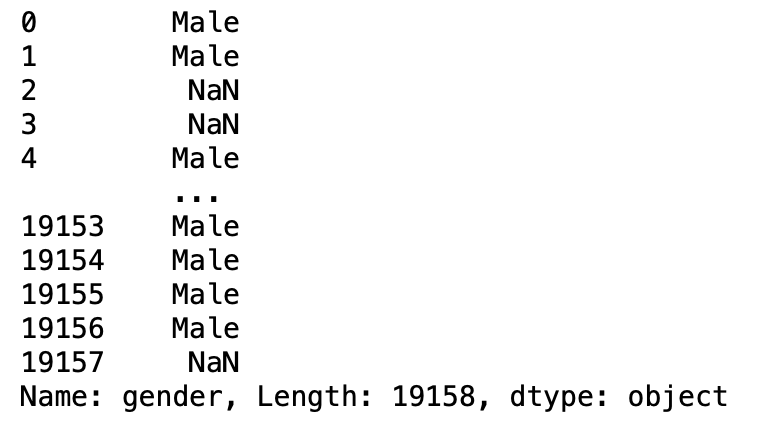
parámetro de compresión
Si es verdadero y solo se pasa una columna, devuelve la serie pandas en lugar de un DataFrame.
pd.read_csv('aug_train.csv',usecols=['gender'],squeeze=True)
Producción:
parámetro skiprows
Este parámetro se utiliza para omitir filas pasadas en el nuevo marco de datos.
pd.read_csv('aug_train.csv',skiprows=[0,1])
Producción:
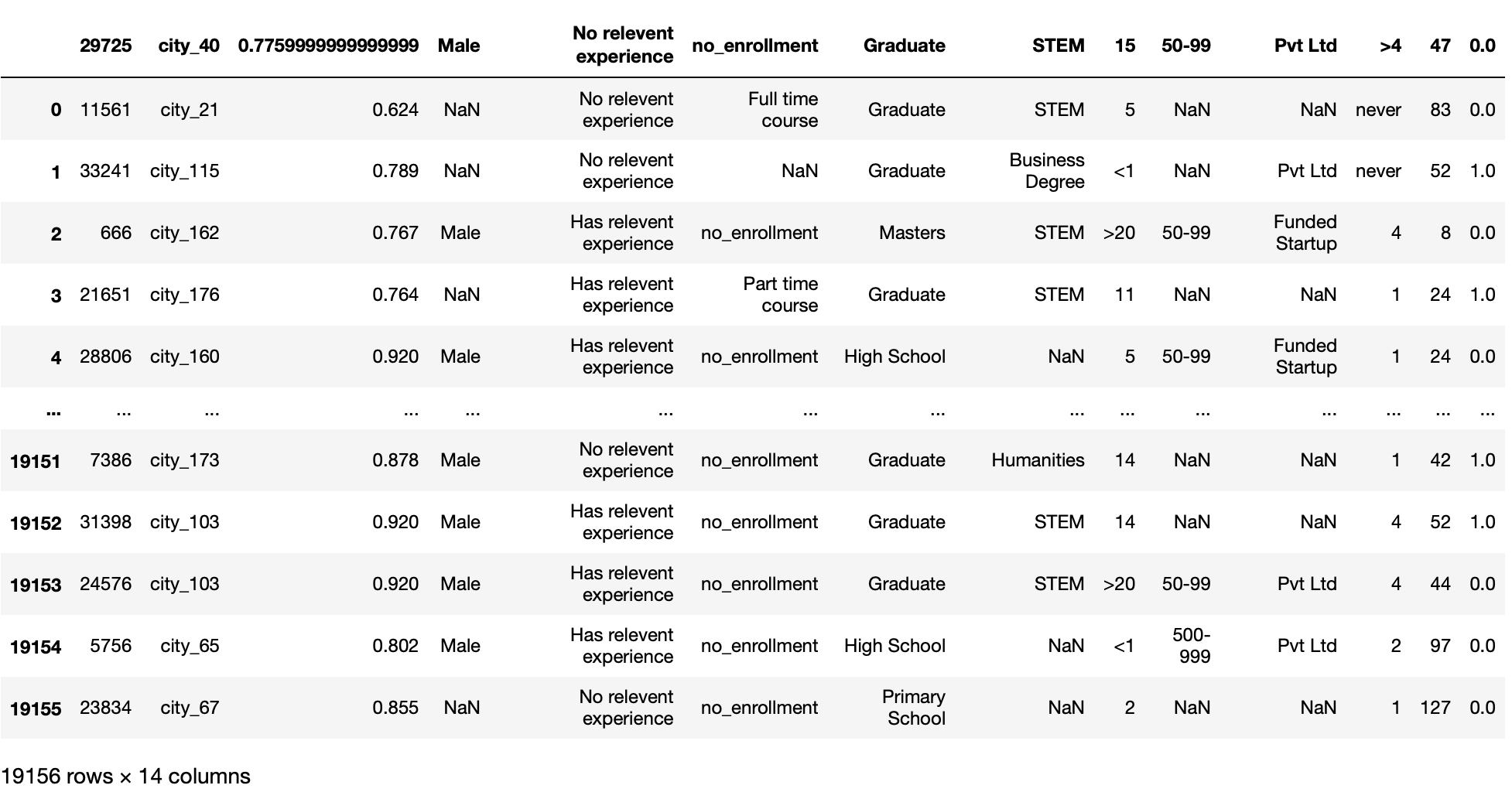
parámetro nrows
Esta función solo lee el número fijo (decidido por el usuario) de las primeras filas del archivo. Necesita un valor int.
Este parámetro es útil cuando tenemos un conjunto de datos enorme y queremos cargar nuestro conjunto de datos en fragmentos en lugar de cargar directamente el conjunto de datos completo.
pd.read_csv('aug_train.csv',nrows=100)
Producción:
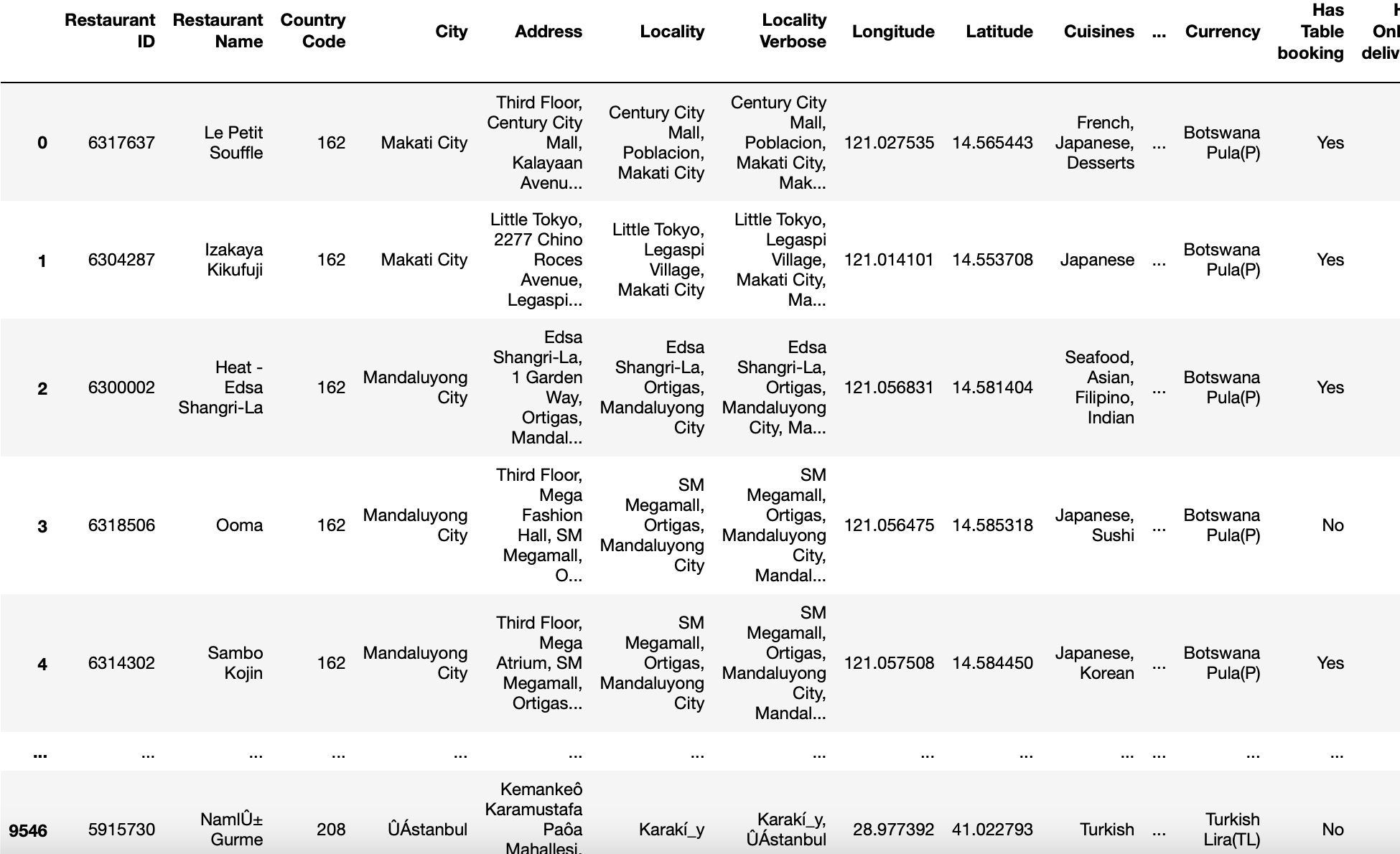
parámetro de codificación
Este parámetro ayuda a determinar qué codificación debe usar para UTF al leer o escribir archivos.
A veces, lo que sucede es que nuestros archivos no están codificados en la forma predeterminada, es decir, UTF-8. Entonces, guardar eso con un editor de texto o agregar el parámetro «Codificación = ‘utf-8 ′ no funciona. En ambos casos, devuelve el error.
Entonces, para resolver este problema, llamamos a nuestra función read_csv con codificación = ‘latin1 ′, codificación =’ iso-8859-1 ′ o codificación = ‘cp1252 ′ (estas son algunas de las diversas codificaciones que se encuentran en Windows).
pd.read_csv('zomato.csv',encoding='latin-1')
Producción:
parámetro error-bad-lines
Si tenemos un conjunto de datos en el que algunas líneas tienen demasiados campos (Por ejemplo, una línea CSV con demasiadas comas), luego, de forma predeterminada, se genera y causa una excepción, y no se devolverá ningún DataFrame.
Entonces, para resolver este tipo de problemas, tenemos que hacer que este parámetro sea False, luego estas «líneas defectuosas» se eliminarán del DataFrame que se devuelve. (Solo válido con analizador C)
pd.read_csv('BX-Books.csv', sep=';', encoding="latin-1",error_bad_lines=False)
Producción:
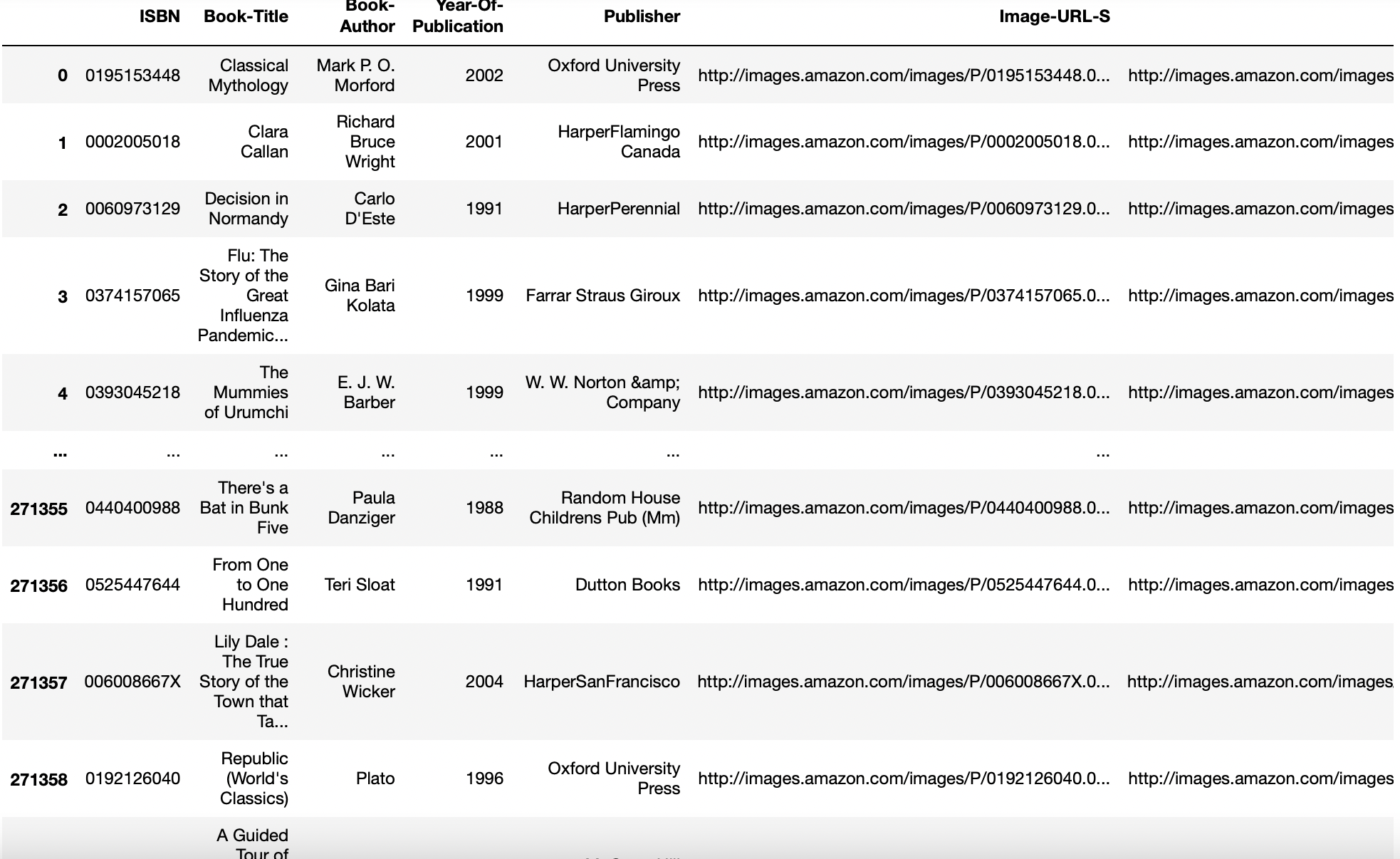
parámetro dtype
Tipo de datos para datos o columnas. Por ejemplo, {‘a’: np.float64, ‘b’: np.int32}
A veces, para convertir nuestras columnas del tipo de datos flotante al tipo de datos int, esta función es útil.
pd.read_csv('aug_train.csv',dtype={'target':int}).info()
Producción:
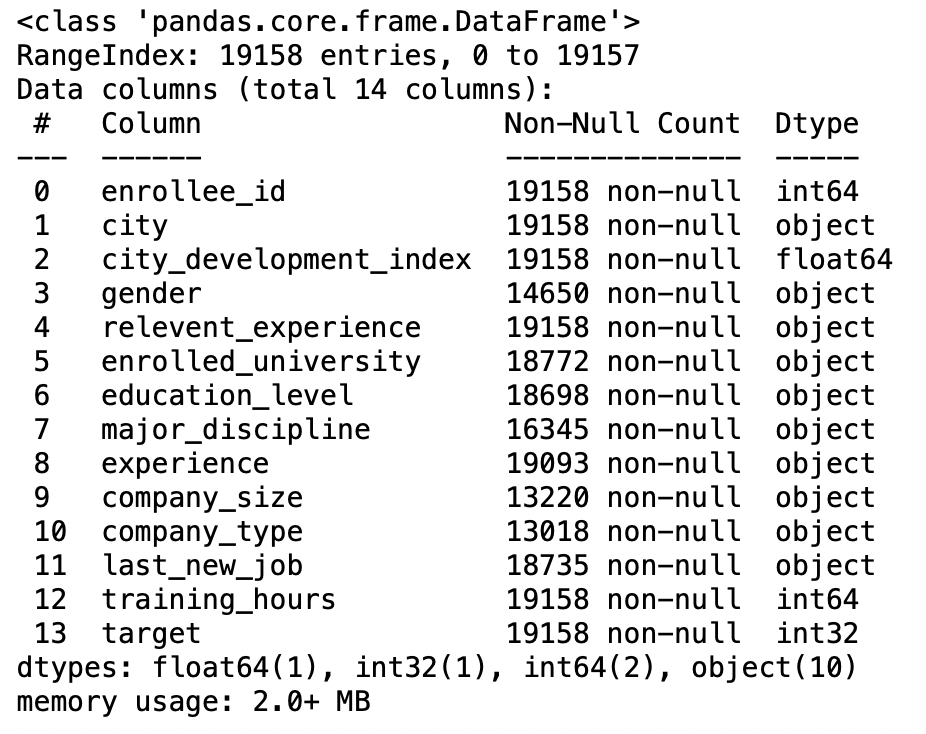
parámetro parse-fechas
Si hacemos que este parámetro sea True, entonces intenta analizar el índice.
Por ejemplo, Si [1, 2, 3] -> intente analizar las columnas 1, 2, 3 cada una como una columna de fecha separada y si tenemos que combinar las columnas 1 y 3 y analizar como una columna de fecha única, utilice [[1,3]].
pd.read_csv('IPL Matches 2008-2020.csv',parse_dates=['date']).info()
Producción:
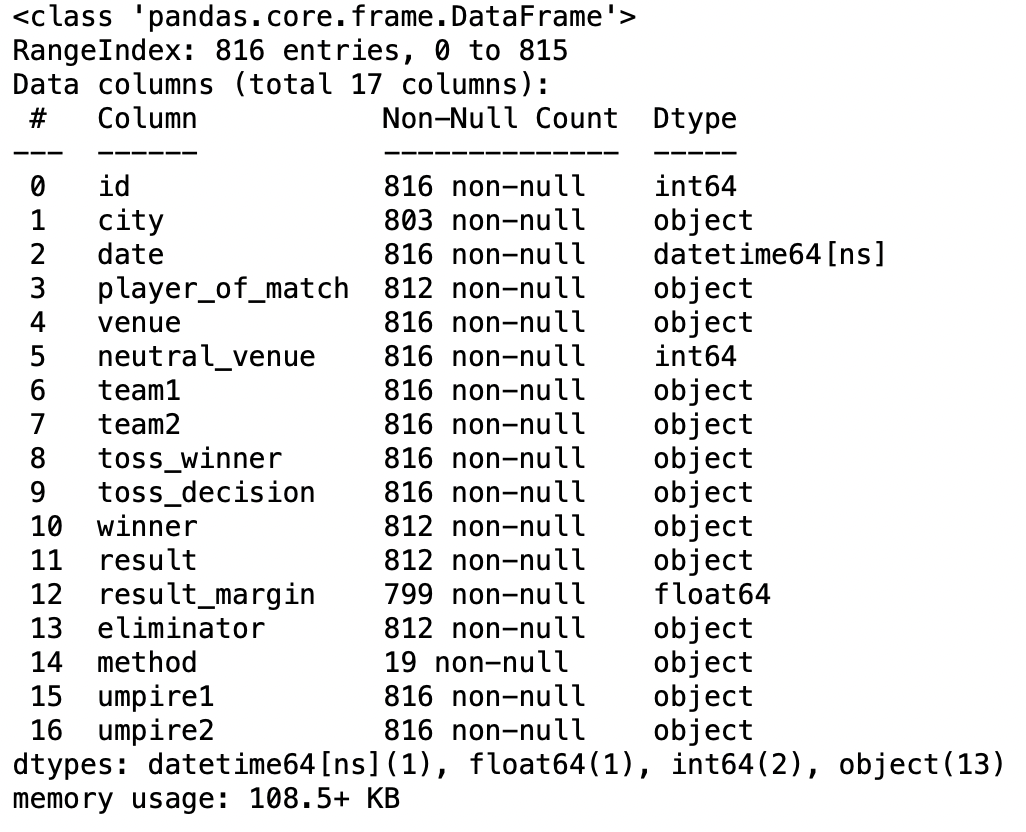
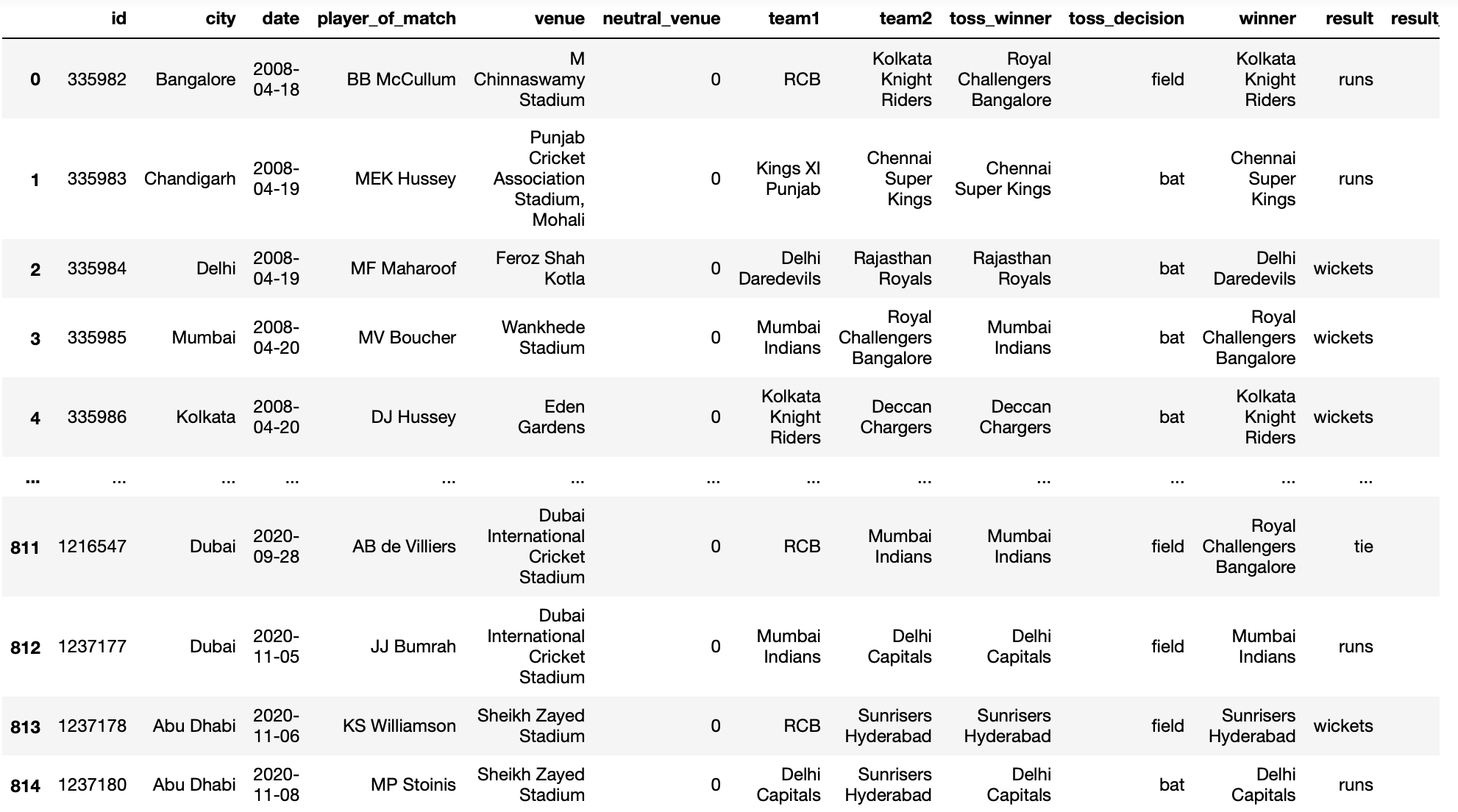
parámetro de convertidores
Este parámetro nos ayuda a convertir valores en las columnas en base a una función personalizada dada por el usuario.
def rename(name):
if name == "Royal Challengers Bangalore":
return "RCB"
else:
return name
rename("Royal Challengers Bangalore")
Producción:
‘RCB’
pd.read_csv('IPL Matches 2008-2020.csv',converters={'team1':rename})
Producción:
parámetro de valores na
Como sabemos, los valores perdidos predeterminados serán NaN. Si queremos que otras cadenas se consideren como NaN, entonces tenemos que usar este parámetro. Espera una lista de cadenas como entrada.
A veces, en nuestro conjunto de datos, se usa otro tipo de símbolo para convertirlos en valores perdidos, por lo que en ese momento para entender esos valores como perdidos, usamos este parámetro.
pd.read_csv('aug_train.csv',na_values=['Male',])
Producción:
¡Esto completa nuestra discusión!
NOTA: En este artículo, solo discutiremos aquellos parámetros que son muy útiles al trabajar con archivos CSV a diario. Pero si está interesado en conocer más parámetros, consulte el sitio web oficial de Pandas aquí.
O puede referirse a esto Enlace además.
Notas finales
¡Gracias por leer!
Si te gustó y quieres saber más, ve a mis otros artículos sobre ciencia de datos y aprendizaje automático haciendo clic en el Enlace
No dude en ponerse en contacto conmigo en Linkedin, Correo electrónico.
¿Algo no mencionado o quieres compartir tus pensamientos? No dude en comentar a continuación y me pondré en contacto con usted.
Sobre el Autor
Chirag Goyal
Actualmente, estoy cursando mi Licenciatura en Tecnología (B.Tech) en Ciencias de la Computación e Ingeniería de la Instituto Indio de Tecnología de Jodhpur (IITJ). Estoy muy entusiasmado con el aprendizaje automático, el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y la inteligencia artificial.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





