Visión general
- Aquí hay una lista de los 10 artículos principales publicados este año por DataPeaker
- Los artículos se han clasificado en orden descendente, en función de sus opiniones.
- Siéntase libre de agregar más artículos en la sección de comentarios que crea que la comunidad debería leer.
Introducción
La escritura es la mejor forma de mejorar la retención. Convertir sus aprendizajes en sus propias palabras no solo conduce a una mejor comprensión, sino que también conduce a una observación innata, que a su vez conduce a mejorar la curiosidad.
En resumen, la escritura eleva su proceso de aprendizaje a niveles insondables.
La escritura es el núcleo de los principios de DataPeaker. Siempre hemos intentado ofrecer el mejor contenido posible y 2020 no fue diferente para nosotros. Con más de 500 artículos publicados este año, el viaje de la escritura nunca se detiene para nosotros.
En este artículo, destacamos los 10 artículos más leídos por la comunidad de Data Science en nuestro blog, publicado este año.
¡Así que pongamos la pelota a rodar!
El artículo con mejor rendimiento de nuestro blog es el que se basa en las preguntas más fundamentales que le hace a un científico de datos o analista de datos en una entrevista.
«¿Cuántos proyectos de ciencia de datos ha completado hasta ahora?»

La respuesta marca la diferencia. La ciencia de datos no es un campo en el que la comprensión teórica le ayude a empezar. Son los proyectos que realiza y la práctica que tiene lo que determina su probabilidad de éxito.
Simplemente hacer cursos o obtener certificaciones no es suficiente. Casi todos los que conocemos tienen certificaciones en varios aspectos de la ciencia de datos. No agrega ningún valor a su currículum si no lo combina con la experiencia práctica.
Pero, ¿qué proyecto de ciencia de datos debería elegir? En DataPeaker nos encanta recopilar los mejores proyectos de ciencia de datos cada mes y, en este artículo, hemos recopilado los mejores proyectos de ciencia de datos de código abierto para el mes de junio de 2020.
Puede verificarlo aquí.
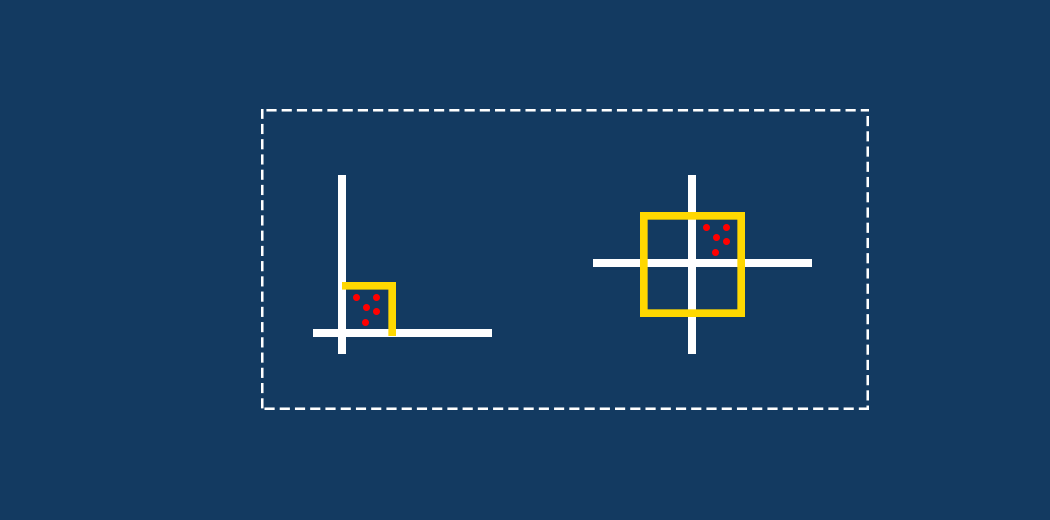
La escala de características le ayuda a convertir varias variables que tienen una miríada de unidades de medida, como kilogramos, rupias, años, etc., en medidas sin unidades. Pero la pregunta es ¿qué método de escalado usar?
Uno de los obstáculos a los que se enfrenta todo científico de datos es el dilema de elegir entre NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... y Estandarización. La mayoría de los cursos no se enfocan en este tema. La escala de características es uno de los pasos de preprocesamiento más importantes y jugar con este concepto sin el conocimiento adecuado puede conducir a un modelo inexacto o sesgado.
El artículo también habla sobre por qué algunos modelos de aprendizaje automático mejoran drásticamente con el escalado de funciones, mientras que otros ni siquiera se mueven un poco.
Puedes leer el artículo aquí.
“¿Cuáles son las mejores herramientas para realizar tareas de ciencia de datos? ¿Y qué herramienta debería usted retomar como un recién llegado a la ciencia de datos? «

La esencia del artículo se cubre en la pregunta anterior. Una vez que identificamos qué aprender a nivel personal, o hacer a nivel profesional con los datos, necesitamos identificar las herramientas que mejor se adaptan a la tarea. Este artículo trata sobre la identificación de la mejor herramienta de ajuste.
La ciencia de datos es un tema muy amplio y cada espectro requiere que los datos se traten de una manera única. Y dado que sus modelos tienden a tener un gran impacto en las decisiones de la organización, es realmente importante identificar qué herramientas utilizar.
El artículo se divide en 2 partes, la primera se centra en las herramientas para manejar Big Data en términos de volumen, variedad y velocidad. La siguiente parte habla de herramientas para la ciencia de datos en términos de: informes e inteligencia empresarial, modelado predictivo y aprendizaje automático, inteligencia artificial.
Puedes leer el artículo aquí.
2020 pasará a los libros de historia como el año que cambió a toda la humanidad. Cada faceta de la vida se vio afectada por el Coronavirus y era imperativo que las personas de todos los dominios se unieran y contribuyeran a resolver este problema.
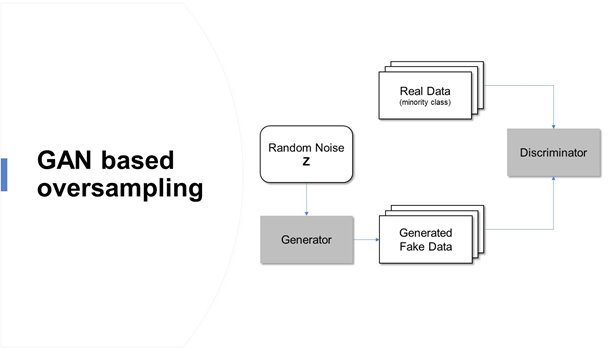
El artículo cubre el uso de Generative Adversarial Networks (GAN), una técnica de sobremuestreo de datos Covid-19 sesgados de palabras reales para predecir el riesgo de mortalidad. Esta historia nos brinda una mejor comprensión de cómo los pasos de preparación de datos, como el manejo de datos desequilibrados, mejorarán el rendimiento de nuestro modelo.
Los datos y el modelo central de este artículo se consideran del estudio reciente (julio de 2020) sobre «Predicción de la salud del paciente de COVID-19 mediante el algoritmo de bosque aleatorio impulsado» por Celestine Iwendi, Ali Kashif Bashir, Atharva Peshkar. et al. Este estudio utilizó el algoritmo Random Forest impulsado por el modelo AdaBoost y predijo la mortalidad de pacientes individuales con un 94% de precisión. En este artículo, se consideraron el mismo modelo y los mismos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... del modelo para analizar claramente la mejora de la precisión del modelo existente mediante el uso de la técnica de sobremuestreo basada en GAN.
Puedes leer el artículo aquí.
¿Por qué el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud...?
Esta es una pregunta perfecta. Estamos inundados de algoritmos de aprendizaje automático. No hay escasez en el recuento y cualquier tipo de datos se pueden resolver utilizando cualquiera de estos algoritmos.

Además, los algoritmos de aprendizaje profundo requieren una gran potencia informática. Entonces, ¿es necesario utilizar estos algoritmos?
Este artículo es un testimonio de todas las consultas que cuestionan la necesidad del aprendizaje profundo y sus redes neuronales, como las redes neuronales convolucionales (CNN), las redes neuronales recurrentes (RNN), las redes neuronales artificiales (ANN), etc. El aprendizaje profundo reemplaza al aprendizaje automático en términos de límites de decisión e ingeniería de características.
Puedes leer el artículo aquí.
Muchos de nosotros aún no conocemos los diferentes dominios del sector de datos. Todavía usamos estos términos indistintamente y causa una gran confusión durante la comunicación.

Hay un aumento en la demanda tanto de Business Analytics como de Data Science. Se espera que el tamaño de su mercado alcance los $ 100 mil millones y $ 140 mil millones, respectivamente, para 2025. Por lo tanto, solo tiene sentido comprender qué significan realmente ambos dominios, sus responsabilidades y cuáles son las similitudes que llevan a que estos términos se usen indistintamente.
En DataPeaker, nos hemos encontrado con muchos aspirantes a profesionales de la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico.... que quieren elegir «Business Analytics» o «Data Science» como carrera, pero ni siquiera están seguros de la distinción entre estos dos roles. Antes de sumergirse en su propia elección, debe tener claro qué camino desea tomar, ¿verdad? ¡Podría ser una elección que defina la carrera!
Este artículo explora las similitudes y diferencias entre la analítica empresarial y la ciencia de datos y trata de ofrecerle una mejor imagen.
Puedes leer el artículo aquí.
Algunas de las tareas más simples, como unir tablas, pueden parecer complicadas en Python. Este artículo es una guía simple para unir 2 tablas usando la biblioteca de pandas sin problemas.
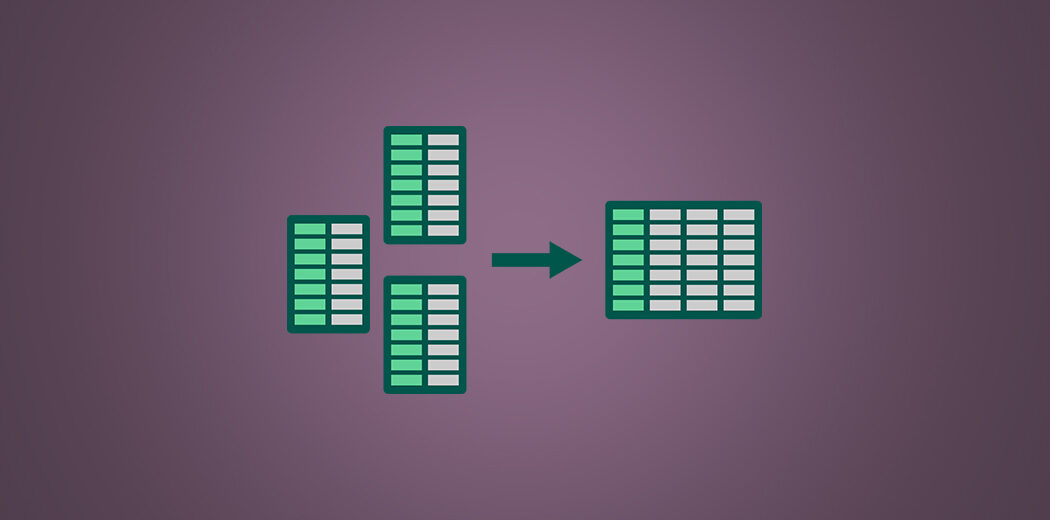
Nuestro séptimo artículo con mejor rendimiento lo ayudará a comprender los diferentes tipos de combinaciones en Pandas:
- Unión interna en Pandas
- Únete completo en Pandas
- Unión a la izquierda en Pandas
- Únete a la derecha en Pandas
Puedes leer el artículo aquí.

Este es el segundo artículo de un proyecto de código abierto de ciencia de datos que aparece en esta lista. Lo tomamos como una clara señal de que el aprendizaje no ha pasado a un segundo plano cuando se trata de aspirantes a la ciencia de datos.
Este artículo contenía los principales proyectos de ciencia de datos de código abierto para el mes de abril. La lista incluye-
- Convierta cualquier imagen en una foto 3D
- Transforma una imagen en una ilustración de dibujos animados
- Seguimiento de objetos múltiples de un solo disparo
- Jukebox de OpenAI: un modelo generativo para la música
- ShyNet: análisis web amigable con la privacidad y sin cookies
- Manual de análisis de fútbol
Puedes leer el artículo aquí.

La codificación es una experiencia muy personal para cualquier científico de datos, analista de negocios, analista de datos o cualquier programador.
Todos hemos llegado a un punto en nuestro viaje de codificación en el que sentimos que una herramienta en particular es perjudicial para nuestra eficiencia. La razón puede variar desde su estilo de codificación, su posición en la ruta de aprendizaje o cualquier otra razón que haga que la herramienta sea incompatible para usted.
Ahí es donde entra en juego la identificación del IDE correcto. Un IDE nos ayuda a escribir y ejecutar código Python para análisis, ciencia de datos, desarrollo de software y una gran cantidad de otras tareas. Hay varios IDE en el mercado en este momento, con su propio conjunto de características, ventajas y desventajas.
Puedes leer el artículo aquí.
¿Cómo representamos esos datos de una manera que ayude a nuestro equipo de liderazgo o tomadores de decisiones a llegar a un consenso rápidamente?
La respuesta a la pregunta anterior es una visualización concisa. No puede crear un modelo en Excel o Python y simplemente esperar que las partes interesadas comprendan las implicaciones.

Excel ha sido un líder del mercado en lo que respecta a EDA y tareas de visualización durante más de 35 años. La mayoría de las empresas confían en él, especialmente las pequeñas por sus características.
En este artículo, analizamos los siguientes paneles:
- Seguimiento de ventas en línea
- Análisis de marketing
- Gestión de proyectos
- Seguimiento de ingresos
- Gestión de recursos humanos
Puedes leer el artículo aquí.
Notas finales
El año 2020 fue un salto para la comunidad de aprendizaje automático. Espero que estos artículos sobre ciencia de datos le resulten útiles en su viaje de aprendizaje. Háganos saber sus pensamientos en los comentarios a continuación.
¡Seguir aprendiendo! ¡Y nunca dejes de escribir!





