Introducción
Muchos analistas malinterpretan el término «impulso» utilizado en la ciencia de datos. Permítanme brindarles una explicación interesante de este término. El impulso otorga poder a los modelos de aprendizaje automático para mejorar su precisión de predicción.
Los algoritmos de impulso son uno de los algoritmos más utilizados en las competiciones de ciencia de datos. Los ganadores de nuestro últimos hackatones están de acuerdo en que intentan impulsar el algoritmo para mejorar la precisión de sus modelos.
En este artículo, explicaré cómo funciona el algoritmo de impulso de una manera muy simple. También he compartido los códigos de Python a continuación. Me he saltado las intimidantes derivaciones matemáticas que se utilizan en Boosting. Porque eso no me habría permitido explicar este concepto en términos simples.
Empecemos.

¿Qué es impulsar?
Definición: El término «Impulso» se refiere a una familia de algoritmos que convierte a un alumno débil en un alumno fuerte.
Entendamos esta definición en detalle resolviendo un problema de identificación de correo electrónico no deseado:
¿Cómo clasificaría un correo electrónico como SPAM o no? Como todos los demás, nuestro enfoque inicial sería identificar los correos electrónicos «spam» y «no spam» utilizando los siguientes criterios. Si:
- El correo electrónico tiene solo un archivo de imagen (imagen promocional), es un SPAM
- El correo electrónico solo tiene enlace (s), es un SPAM
- El cuerpo del correo electrónico consta de una oración como «Ganaste un premio en metálico de $ xxxxxx», es un SPAM
- Correo electrónico de nuestro dominio oficial «Analyticsvidhya.com«, No es un SPAM
- Correo electrónico de fuente conocida, no SPAM
Anteriormente, hemos definido varias reglas para clasificar un correo electrónico en ‘spam’ o ‘no spam’. Pero, ¿cree que estas reglas individualmente son lo suficientemente fuertes como para clasificar con éxito un correo electrónico? No.
Individualmente, estas reglas no son lo suficientemente poderosas como para clasificar un correo electrónico en ‘spam’ o ‘no spam’. Por lo tanto, estas reglas se denominan aprendiz débil.
Para convertir a un alumno débil en un alumno fuerte, combinaremos la predicción de cada alumno débil utilizando métodos como:
• Usando promedio / promedio ponderado
• Considerando que la predicción tiene mayor voto
Por ejemplo: arriba, hemos definido 5 estudiantes débiles. De estos 5, 3 se votan como ‘SPAM’ y 2 se votan como ‘No es SPAM’. En este caso, de forma predeterminada, consideraremos un correo electrónico como SPAM porque tenemos un voto más alto (3) para ‘SPAM’.
¿Cómo funcionan los algoritmos de impulso?
Ahora sabemos que el impulso combina a un alumno débil, también conocido como alumno básico, para formar una regla sólida. Una pregunta inmediata que debería surgir en tu mente es: ‘¿Cómo impulsar la identificación de reglas débiles?‘
Para encontrar una regla débil, aplicamos algoritmos de aprendizaje base (ML) con una distribución diferente. Cada vez que se aplica el algoritmo de aprendizaje base, genera una nueva regla de predicción débil. Este es un proceso iterativo. Después de muchas iteraciones, el algoritmo de impulso combina estas reglas débiles en una sola regla de predicción fuerte.
Aquí hay otra pregunta que podría atormentarlo ».¿Cómo elegimos una distribución diferente para cada ronda? ‘
Para elegir la distribución correcta, estos son los siguientes pasos:
Paso 1: El alumno básico toma todas las distribuciones y asigna el mismo peso o atención a cada observación.
Paso 2: Si hay algún error de predicción causado por el algoritmo de aprendizaje de la primera base, entonces prestamos mayor atención a las observaciones que tienen un error de predicción. Luego, aplicamos el siguiente algoritmo de aprendizaje base.
Paso 3: Repita el paso 2 hasta que se alcance el límite del algoritmo de aprendizaje base o se logre una mayor precisión.
Finalmente, combina los resultados del alumno débil y crea un alumno fuerte que finalmente mejora el poder de predicción del modelo. El impulso se presta más atención a los ejemplos que están mal clasificados o tienen errores más altos por las reglas débiles anteriores.
Tipos de algoritmos de impulso
El motor subyacente utilizado para impulsar algoritmos puede ser cualquier cosa. Puede ser un sello de decisión, un algoritmo de clasificación que maximiza los márgenes, etc. Hay muchos algoritmos de impulso que utilizan otros tipos de motores, como:
- AdaBoost (Adaptive AumentarEn g)
- Aumento del árbol de degradado
- XGBoost
En este artículo, nos centraremos en AdaBoost y Gradient Boosting seguidos de sus respectivos códigos de Python y nos centraremos en XGboost en el próximo artículo.
Aumento del algoritmo: AdaBoost
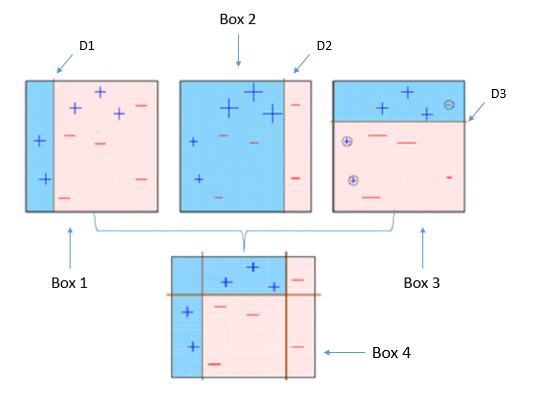
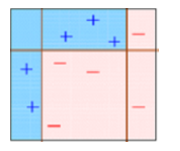
Este diagrama explica acertadamente Ada-boost. Entendamos de cerca:
Recuadro 1: Puede ver que hemos asignado pesos iguales a cada punto de datos y aplicado un muñón de decisión para clasificarlos como + (más) o – (menos). El muñón de decisión (D1) ha generado una línea vertical en el lado izquierdo para clasificar los puntos de datos. Vemos que, esta línea vertical ha predicho incorrectamente tres + (más) como – (menos). En tal caso, asignaremos pesos más altos a estos tres + (más) y aplicaremos otro muñón de decisión.
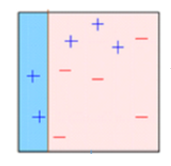
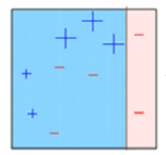
Recuadro 2: Aquí, puede ver que el tamaño de tres + (más) predichos incorrectamente es mayor en comparación con el resto de los puntos de datos. En este caso, el segundo muñón de decisión (D2) intentará predecirlos correctamente. Ahora, una línea vertical (D2) en el lado derecho de este cuadro ha clasificado correctamente tres + (más) mal clasificados. Pero nuevamente, ha causado errores de clasificación errónea. Esta vez con tres – (menos). Nuevamente, asignaremos un mayor peso a tres – (menos) y aplicaremos otro muñón de decisión.
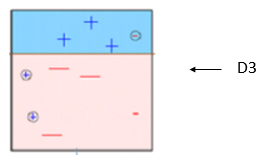
Recuadro 3: Aquí, tres – (menos) reciben pesos más altos. Se aplica un muñón de decisión (D3) para predecir correctamente estas observaciones mal clasificadas. Esta vez se genera una línea horizontal para clasificar + (más) y – (menos) basándose en un mayor peso de observación mal clasificada.
Recuadro 4: Aquí, hemos combinado D1, D2 y D3 para formar una predicción fuerte que tiene una regla compleja en comparación con un alumno débil individual. Puede ver que este algoritmo ha clasificado estas observaciones bastante bien en comparación con cualquiera de los estudiantes débiles individuales.
AdaBoost (Adaptive Aumentaring): Funciona con un método similar al descrito anteriormente. Se ajusta a una secuencia de estudiantes débiles en diferentes datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... ponderados. Empieza por predecir el conjunto de datos original y da el mismo peso a cada observación. Si la predicción es incorrecta utilizando el primer alumno, entonces se da mayor peso a las observaciones que se han predicho incorrectamente. Al ser un proceso iterativo, continúa agregando aprendices hasta que se alcanza un límite en el número de modelos o precisión.
Principalmente, usamos sellos de decisión con AdaBoost. Pero podemos usar cualquier algoritmo de aprendizaje automático como aprendiz base si acepta el peso en el conjunto de datos de entrenamiento. Podemos usar algoritmos AdaBoost para problemas de clasificación y regresión.
Puede consultar el artículo «Cómo ser inteligente con el aprendizaje automático: AdaBoost» para comprender los algoritmos de AdaBoost con más detalle.
Código Python
Aquí hay una ventana de codificación en vivo para comenzar. Puede ejecutar los códigos y obtener el resultado en esta ventana:
Puede ajustar los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para optimizar el rendimiento de los algoritmos, he mencionado a continuación los parámetros clave para el ajuste:
- n_estimators: Controla el número de estudiantes débiles.
- tasa de aprendizaje:CControla la contribución de los estudiantes débiles en la combinación final. Hay una compensación entre tasa de aprendizaje y n_estimators.
- estimadores_base: Ayuda a especificar diferentes algoritmos de aprendizaje automático.
También puede ajustar los parámetros de los alumnos básicos para optimizar su rendimiento.
Algoritmo de impulso: aumento de gradiente
En el aumento de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en..., entrena muchos modelos secuencialmente. Cada nuevo modelo minimiza gradualmente la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... (y = ax + b + e, e necesita atención especial ya que es un término de error) de todo el sistema usando Descenso de gradiente método. El procedimiento de aprendizaje se ajustó consecutivamente a nuevos modelos para proporcionar una estimación más precisa de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de respuesta.
La idea principal detrás de este algoritmo es construir nuevos alumnos base que puedan correlacionarse al máximo con el gradiente negativo de la función de pérdida, asociado con todo el conjunto. Puede consultar el artículo «Aprenda el algoritmo de aumento de gradiente» para comprender este concepto con un ejemplo.
En la biblioteca Python Sklearn, usamos Gradient Tree Boosting o GBRT. Es una generalización del impulso a funciones de pérdida diferenciables arbitrarias. Se puede utilizar tanto para problemas de regresión como de clasificación.
Código Python
from sklearn.ensemble import GradientBoostingClassifier #For Classification from sklearn.ensemble import GradientBoostingRegressor #For Regression
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1) clf.fit(X_train, y_train)
- n_estimators: Controla el número de estudiantes débiles.
- tasa de aprendizaje:CControla la contribución de los estudiantes débiles en la combinación final. Hay una compensación entre tasa de aprendizaje y n_estimators.
- máxima profundidad: profundidad máxima de los estimadores de regresión individuales. La profundidad máxima limita el número de nodos en el árbol. Ajuste este parámetro para obtener el mejor rendimiento; el mejor valor depende de la interacción de las variables de entrada.
Puede ajustar la función de pérdida para un mejor rendimiento.
Nota final
En este artículo, analizamos el impulso, uno de los métodos de modelado de conjuntos para mejorar el poder de predicción. Aquí, hemos discutido la ciencia detrás del impulso y sus dos tipos: AdaBoost y Gradient Boost. También estudiamos sus respectivos códigos de Python.
En mi próximo artículo, discutiré sobre otro tipo de algoritmos de impulso que ahora es un secreto de días para ganar concursos de ciencia de datos “XGBoost”.
¿Le ha resultado útil este artículo? Comparta sus opiniones / pensamientos en la sección de comentarios a continuación.





