Tema a cubrir
- ¿Qué es el análisis de datos exploratorios?
- ¿Cuál es la necesidad de automatizar el análisis de datos exploratorios?
- Bibliotecas de Python para automatizar el análisis de datos exploratorios
Análisis exploratorio de datos
es una técnica de exploración de datos para comprender los diversos aspectos de los datos. Es una especie de resumen de datos. Es uno de los pasos más importantes antes de realizar cualquier tarea de aprendizaje automático o aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
Los científicos de datos llevan a cabo procedimientos de análisis de datos exploratorios para explorar, diseccionar y resumir las cualidades fundamentales de los conjuntos de datos, utilizando regularmente enfoques de representación de información. Los procedimientos de EDA toman en consideración un control convincente de las fuentes de información, lo que permite a los científicos de datos descubrir las respuestas adecuadas que necesitan al encontrar diseños de información, detectar inconsistencias, verificar suposiciones o probar especulaciones.
Los científicos de datos utilizan análisis de datos exploratorios para observar qué conjuntos de datos pueden descubrir más allá de la demostración convencional de información o asignaciones de pruebas de especulación. Esto les permite adquirir información de arriba a abajo sobre los factores en los conjuntos de datos y sus conexiones. El análisis de datos exploratorio puede ayudar a reconocer errores claros, distinguir excepciones en conjuntos de datos, obtener conexiones, descubrir elementos significativos, descubra diseños con información privilegiada y brinde nuevos conocimientos.
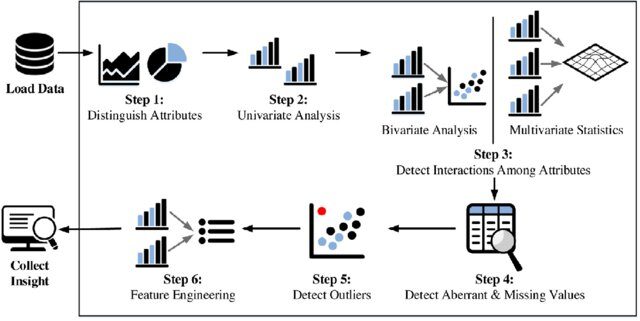
Pasos en el análisis exploratorio de datos
Necesidad de automatizar el análisis de datos exploratorios
El movimiento ampliado de los clientes en la web, los instrumentos refinados para controlar el tráfico web, la multiplicación de teléfonos móviles, los dispositivos habilitados para la web y los sensores de IoT son los elementos esenciales que aceleran el ritmo de la era de la información en la actualidad. En esta era computarizada, las asociaciones de todos los tamaños comprenden que la información puede asumir un papel crucial en la mejora de su competencia, rentabilidad y habilidades dinámicas, lo que genera mayores acuerdos, ingresos y beneficios.
Hoy en día, la mayoría de las organizaciones se acercan a inmensos conjuntos de datos, sin embargo, solo tener grandes medidas de información no mejora el negocio, excepto si las empresas investigan los datos accesibles e impulsan el desarrollo autorizado.

En el ciclo de vida de un proyecto de ciencia de datos o cualquier proyecto de aprendizaje automático, más del 60% de tu tiempo entra en cosas como análisis de datos, selección de características, ingeniería de características, etc. Debido a que es la parte más importante o la columna vertebral de un proyecto de ciencia de datos, es esa parte en particular en la que tiene que realizar muchas actividades como limpiar los datos, manejar los valores faltantes , manejar valores atípicos, manejar conjuntos de datos desequilibrados, cómo manejar características categóricas y mucho más. Así que si quieres ahorra tu tiempo en el análisis de datos exploratorios, podemos usar bibliotecas de Python como dtale, perfil de pandas, sweetviz y autoviz para automatizar nuestras tareas.

Las bibliotecas automatizan el análisis de datos exploratorios
En este blog, discutimos cuatro bibliotecas de Python importantes. Estos se enumeran a continuación:
- cuento
- perfil de pandas
- sweetviz
- autoviz
D-cuento
Es una biblioteca que se ha lanzado en febrero de 2020 que nos permite visualizar fácilmente el marco de datos de pandas. Tiene muchas características que son muy útiles para el análisis de datos exploratorios. Está hecho usando el backend del matraz y reacciona al frontend. Admite gráficos interactivos, gráficos 3D, mapas de calor, la correlación entre características, crea columnas personalizadas y muchos más. Es el más famoso y el favorito de todos.
Instalación
dtale se puede instalar usando el siguiente código:
pip install dtale
Análisis de datos exploratorios con D-tale
Profundicemos en el análisis de datos exploratorios utilizando esta biblioteca. Primero, tenemos que escribir un código para lanzar la aplicación interactiva d-tale localmente:
import dtale import pandas as pd df = pd.read_csv(‘data.csv’) d = dtale.show(df) d.open_browser()
Aquí estamos importando pandas y dtale. Estamos leyendo el conjunto de datos usando la función read_csv () y finalmente mostramos los datos en el navegador localmente usando la función mostrar y abrir el navegador.
Muestra los datos de la misma manera que lo hacen los pandas, pero tiene una característica adicional, tiene un menú en la esquina superior izquierda que nos permite hacer muchas cosas y muestra un recuento de columnas y filas en nuestro conjunto de datos.
La salida del código anterior se muestra a continuación:
Si hace clic en cualquier encabezado de columna, aparecerá el menú desplegable. Le brindará muchas opciones, como ordenar los datos, describir el conjunto de datos, análisis de columnas y muchas más. También puede comprobar esta función por su cuenta
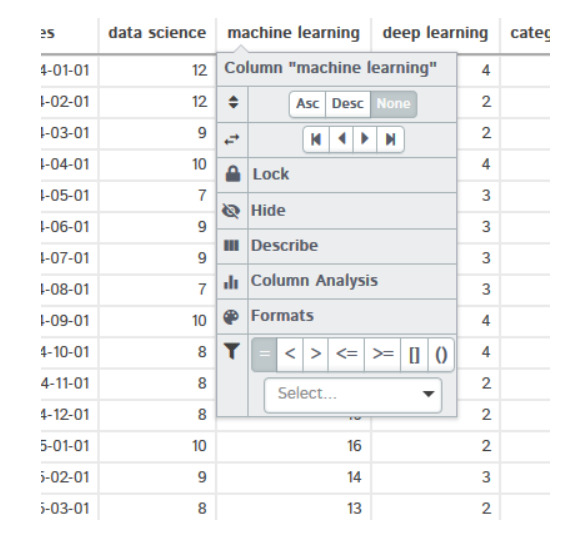
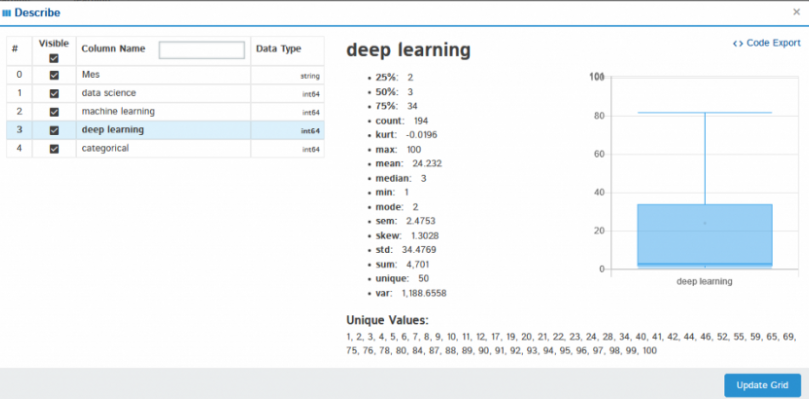
Si hace clic en Describir, muestra el análisis estadístico de la columna seleccionada como media, medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos...., máxima, mínima varianza, desviación estándar, cuartiles y muchos más.
Del mismo modo, puede probar otras funciones por su cuenta, como análisis de columnas, formatos, filtros.
Magic of dtale: haga clic en el botón de menú y encontrará todas las opciones disponibles
No es posible cubrir todas las características, pero estoy cubriendo la más interesante.
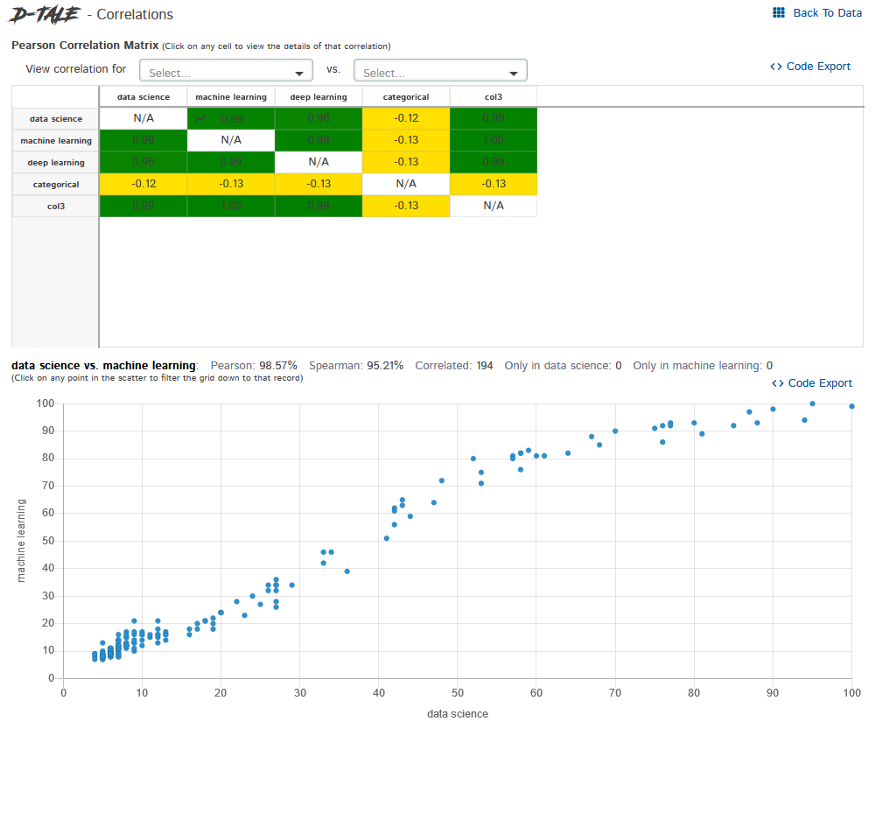
Correlaciones – Nos muestra cómo se correlacionan las columnas entre sí.
Gráficos– Cree gráficos de aduanas como gráficos de líneas, gráficos de barras, gráficos circulares, gráficos apilados, diagramas de dispersión, mapas geológicos, etc.
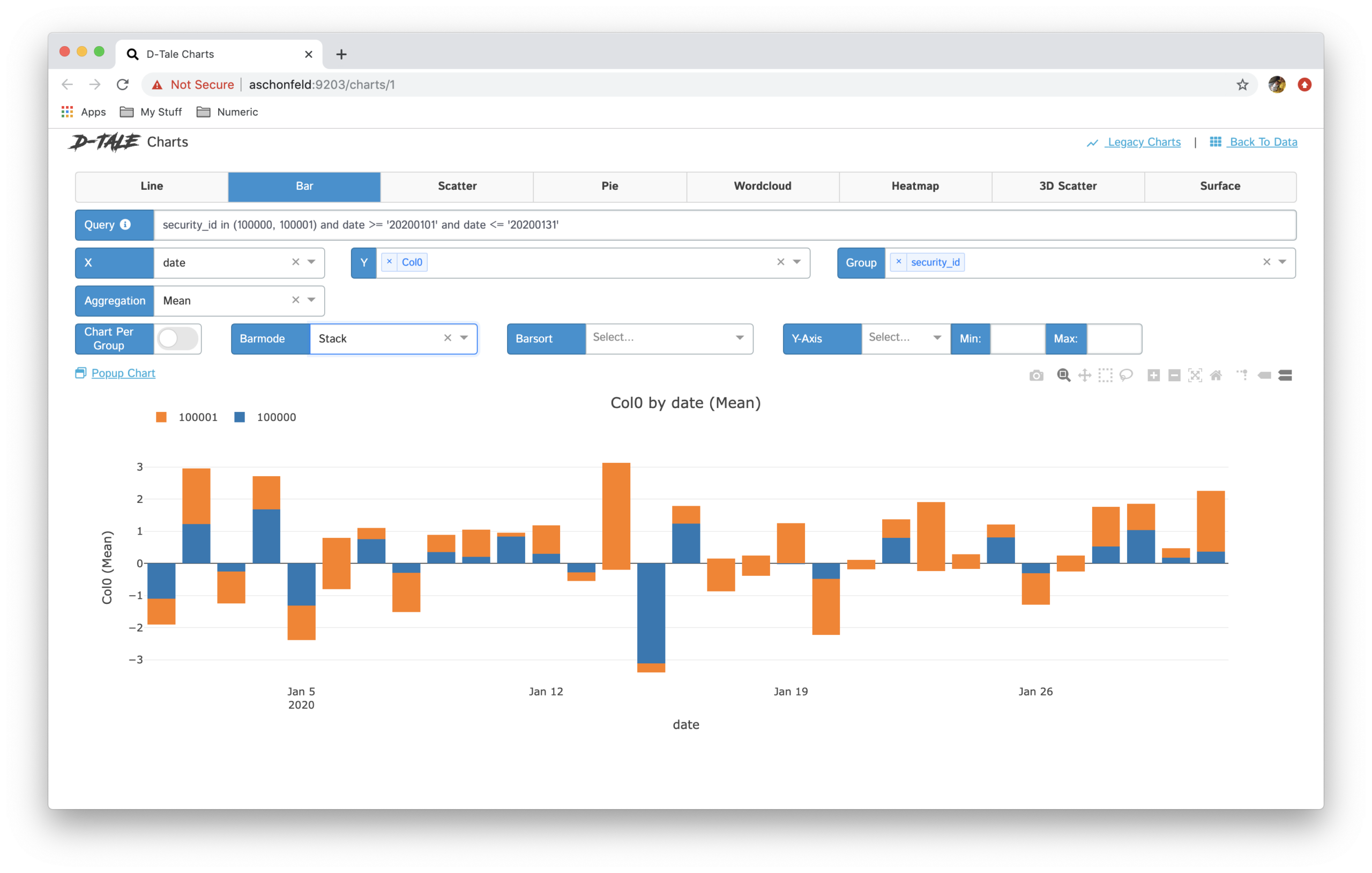
Hay muchos opcionales disponibles en esta biblioteca para el análisis de datos. Esta herramienta es muy útil y hace que el análisis de datos exploratorios sea mucho más rápido en comparación con el uso de bibliotecas tradicionales de aprendizaje automático como pandas, matplotlib, etc.
Para obtener documentación oficial, consulte este enlace:
Perfilado de pandas

Es una biblioteca de código abierto escrita en Python y generó informes HTML interactivos y describe varios aspectos del conjunto de datos. Las funcionalidades clave incluyen el manejo de valores perdidos, estadísticas de conjuntos de datos como media, moda, mediana, asimetría, desviación estándar, etc., gráficos como histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... y correlaciones también.
Instalación
La creación de perfiles de pandas se puede instalar usando el siguiente código:
pip install pandas-profiling
Análisis de datos exploratorios mediante la creación de perfiles de Pandas
Profundicemos en el análisis de datos exploratorios utilizando esta biblioteca. Estoy usando un conjunto de datos de muestra para comenzar con la creación de perfiles de pandas, verifique el siguiente código:
#importing required packages
import pandas as pd
import pandas_profiling
import numpy as np
#importing the data
df = pd.read_csv('sample.csv')
#descriptive statistics
pandas_profiling.ProfileReport(df)
A continuación se muestra la salida mágica del código anterior
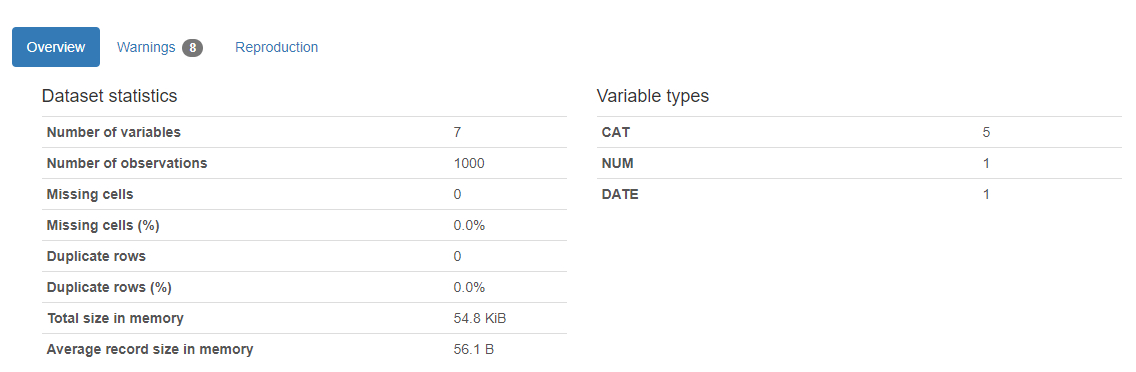
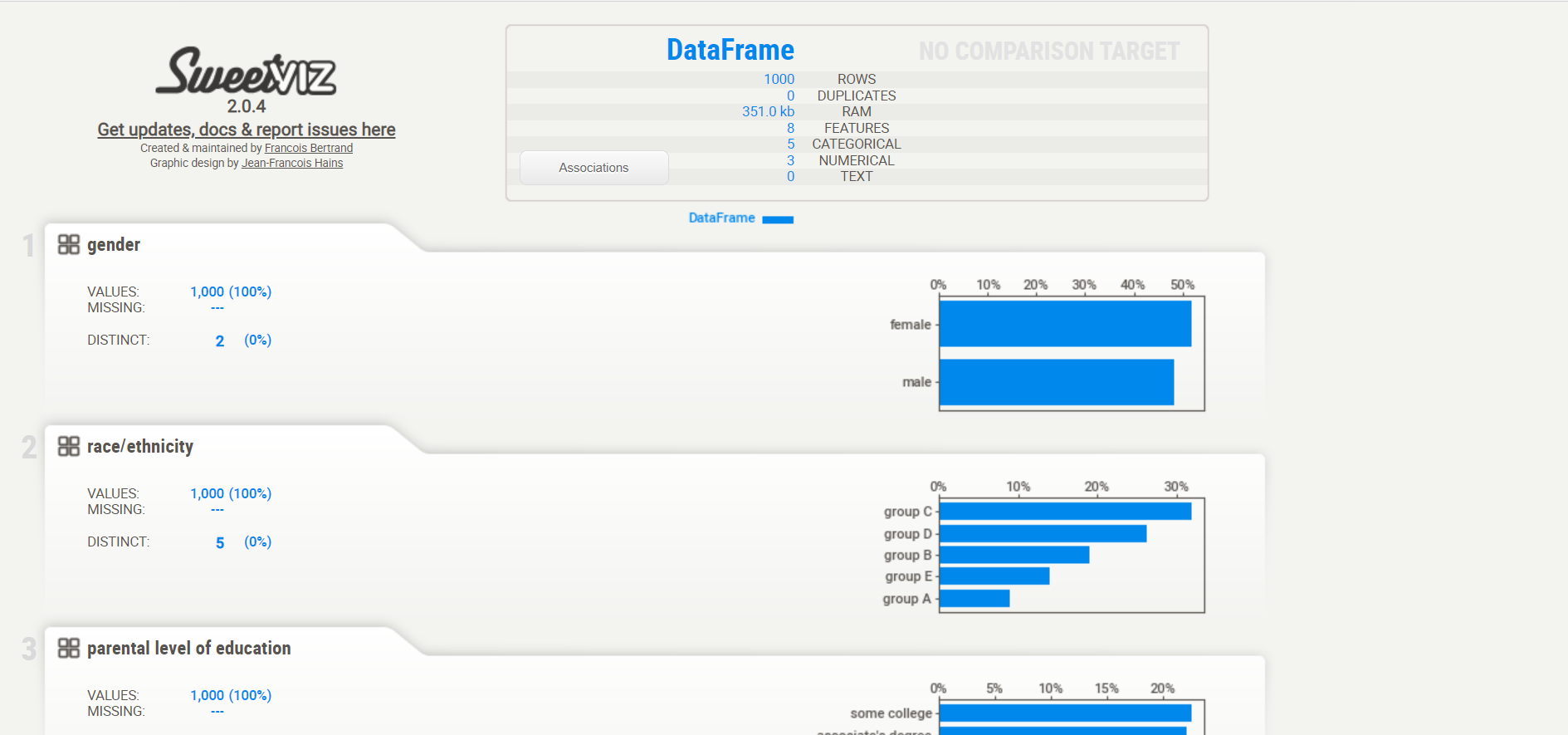
Aquí está el resultado. Aparecerá un informe y devolverá cuántas variables hay en nuestro conjunto de datos, el número de filas, las celdas que faltan en el conjunto de datos, el porcentaje de celdas que faltan, el número y el porcentaje de filas duplicadas. Los datos de celdas faltantes y duplicadas son muy importantes para nuestro análisis, ya que describen la imagen más amplia del conjunto de datos. El informe también muestra el tamaño total de la memoria. También muestra los tipos de variables en el lado derecho de la salida.
La sección de variables muestra el análisis de una columna en particular. Por ejemplo para el variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... categórica, aparecerá la siguiente salida.
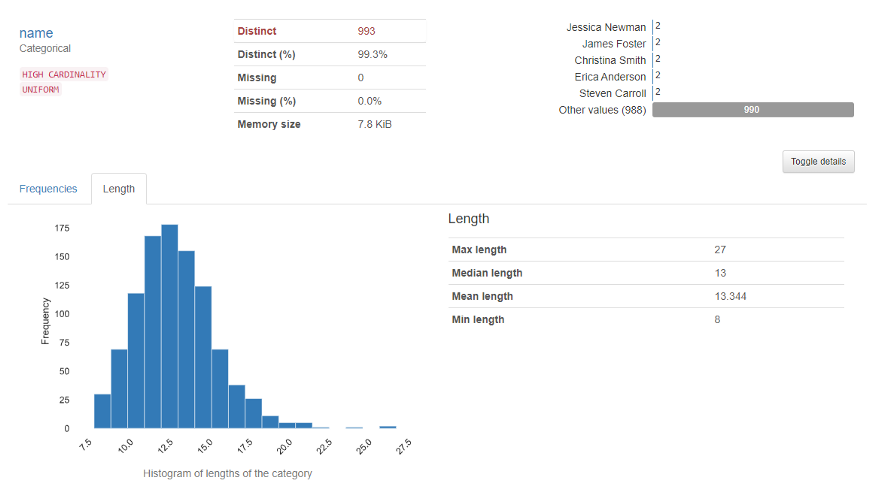
Para el variable numérica, aparecerá la siguiente salida
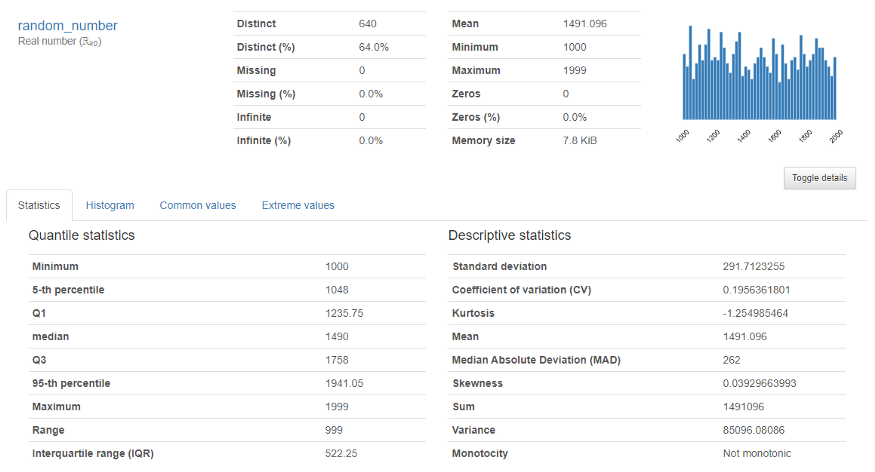
Proporciona un análisis en profundidad de variables numéricas como cuantil, media, suma mediana, varianza, monotonicidad, rango, curtosis, rango intercuartílico y muchas más.
Correlaciones e interacción: Describe cómo se correlacionan las variables entre sí mediante. Estos datos son muy necesarios para los científicos de datos.
Para más información, consulte la documentación oficial:
Sweetviz
Es una biblioteca de Python de código abierto que solía obtener visualizaciones, lo que es útil en el análisis de datos exploratorios con solo unas pocas líneas de códigos. La biblioteca se puede utilizar para visualizar las variables y comparar el conjunto de datos.
Instalación
Esta biblioteca se puede instalar usando el siguiente código:
pip install sweetviz
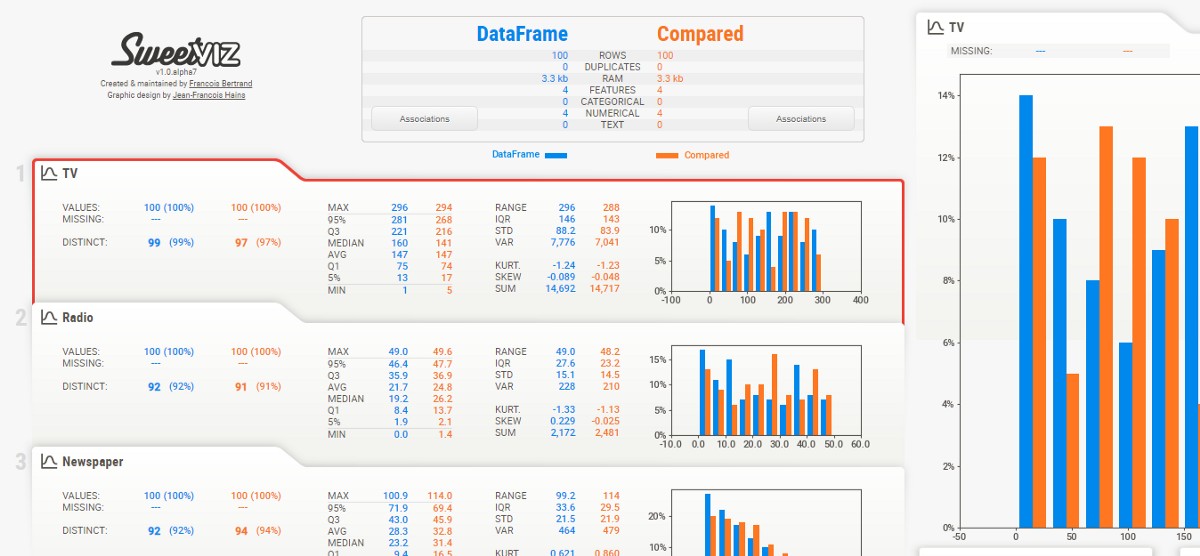
Análisis de datos exploratorios con SweetViz
Profundicemos en el análisis de datos exploratorios utilizando esta biblioteca. Estoy usando un conjunto de datos de muestra para comenzar, verifique el siguiente código
import sweetviz
import pandas as pd
df = pd.read_csv('sample.csv')
my_report = sweetviz.analyze([df,'Train'], target_feat="SalePrice")
my_report.show_html('FinalReport.html')
Reporte final:
Para más información, consulte la documentación oficial:
Autoviz
Significa Visualizar automáticamente. La visualización es posible con cualquier tamaño del conjunto de datos con unas pocas líneas de código.

Instalación
pip install autoviz
Visualización
Código de muestra:
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
df = AV.AutoViz('sample.csv')
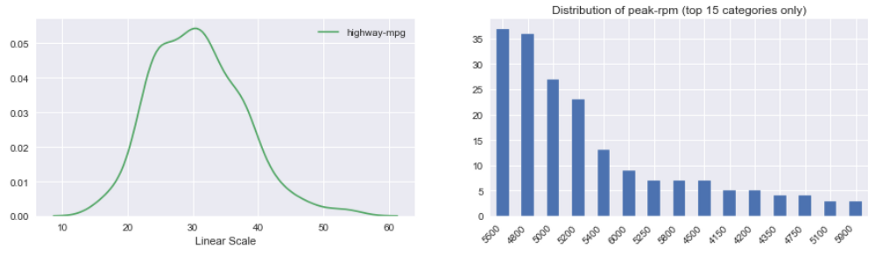
Histograma de variable continua:
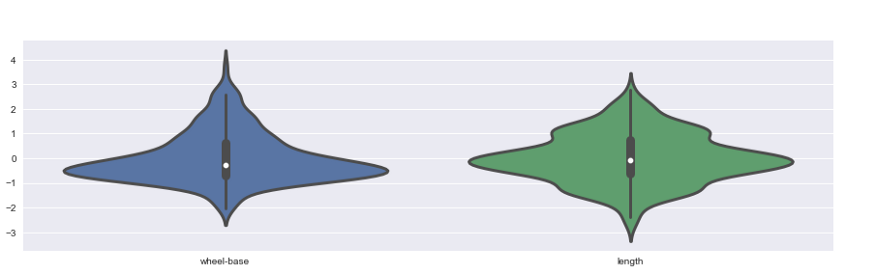
Tramas de violín:
Mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas....:
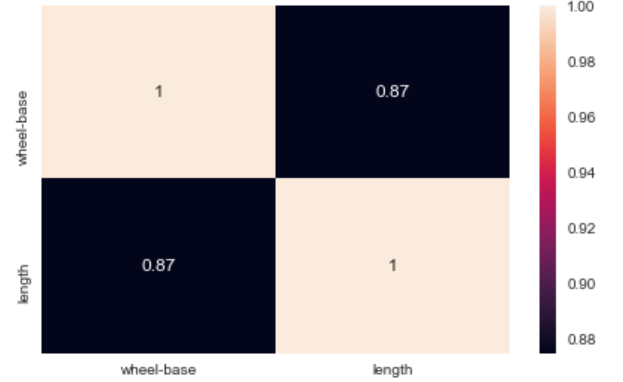
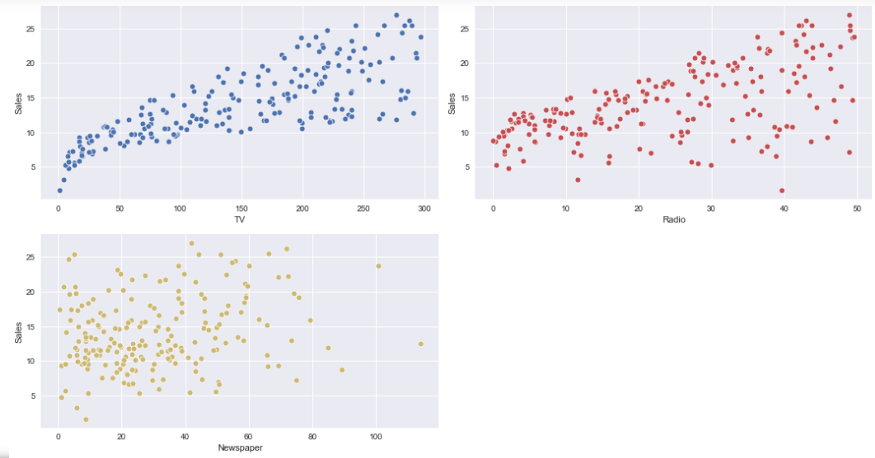
Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....:
Para más información, consulte la documentación oficial:
Gracias por leer esto. Si te gusta este artículo, compártelo con tus amigos. En caso de cualquier sugerencia / duda, comente a continuación.
Identificación de correo: [email protected]
Sígueme en LinkedIn: LinkedIn
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





