Mi padre siempre duda al realizar transacciones costosas en línea. Siempre tiene miedo de que la máquina cometa un error. Solo imagine que transfiere todo su activo financiero de una cuenta a otra y, debido a algún error de datos, se transfiere a la cuenta de otra persona. Sin embargo, no dudo ni un segundo en realizar cualquier tipo de transacciónLa "transacción" se refiere al proceso mediante el cual se lleva a cabo un intercambio de bienes, servicios o dinero entre dos o más partes. Este concepto es fundamental en el ámbito económico y legal, ya que implica el acuerdo mutuo y la consideración de términos específicos. Las transacciones pueden ser formales, como contratos, o informales, y son esenciales para el funcionamiento de mercados y negocios.... online. ¿Qué ha provocado una diferencia tan grande en nuestras percepciones? Probablemente la razón sea la alta precisión en tales transacciones que he presenciado desde mi temprana edad. ¿Qué hace que estas infinidad de transacciones realizadas en bancos, con aerolíneas, con comercio electrónico sean tan precisas?
En gran medida, esto se debe a RDBMS, que se adhiere estrictamente a los principios ACID (atomicidad, consistencia, aislamiento y durabilidad). Pero con el tiempo debido a la alta presión de los datos crecientes, hemos comenzado a utilizar bases de datos NoSQL. NoSQL elimina la necesidad de un esquema, por lo tanto, empuja la capacidad de manejo de datos por un gran margenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial... al comprometer el ACID. Sin embargo, con aplicaciones de soporte precisas implementadas, NoSQL proporciona una buena combinación de alta capacidad de manejo de datos con buena precisión. En este artículo analizaremos las bases de datos NoSQL populares.
Crédito de la imagen: http://www.tomsitpro.com
¿Forma completa de NoSQL?
NoSQL en realidad no tiene una forma completa o incluso un significado real. El término fue acuñado accidentalmente en un evento por Johan Oskarsson para discutir la red distribuida de código abierto. El “#NoSQL” era solo una etiqueta hash de Twitter para organizar esta reunión. Luego, algunas personas de la base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... en esta reunión encontraron este hashtag apropiado para nombrar estas bases de datos no relacionales. Realmente no tenemos una definición estricta para NoSQL. Sin embargo, a continuación se muestran algunas características comunes de las bases de datos NoSQL:
1. No son relacionales
2. Principalmente de código abierto
3. Todos son aptos para clústeres
4. Son menos esquemas
5. Surgieron del mundo web del siglo XXI.
Sin embargo, a menudo nos referimos a NoSQL como sin esquema, esto no significa que estas bases de datos no se adhieran a ningún tipo de esquema. Por ejemplo, considere la siguiente expresión NoSQL:
Tab1[“Revenue” ] * Tab1[“Total count”]
NoSQL tiene un esquema implícito, que puede no ser constante en toda la base de datos. Tal cosa es tanto una bendición como una maldición. Lo básico es que cada vez que queremos modificar un campo necesitamos entender este esquema implícito. Lo bueno es que con un esquema cambiante, se requiere un esfuerzo mucho menor para agregar esta base de datos en comparación con RDBMS. Además, RDBMS no es excelente con una red distribuida, lo que no es el caso de NoSQL.
Tipos de bases de datos NoSQL
Sin embargo, en la literatura NoSQL se ha dividido en 4 tipos principales, encontré una forma muy interesante sugerida por Martin Fowler para categorizar NoSQL. Según la forma en que NoSQL almacena los datos, es principalmente de dos tipos:
1. Base de datos agregada
2. Base de datos basada en gráficos
La principal diferencia entre los dos es que en el tipo agregado, la base de datos intenta almacenar toda la información para una identificación en particular (puede ser una persona, una transacción o un producto, etc.) como un solo objeto. Mientras que el tipo de gráfico sigue la filosofía exactamente opuesta. La base de datos de tipo gráfico intenta cortar los datos en información muy granular y los almacena con todas las relaciones o aristas compartidas. Discutiremos las bases de datos agregadas, que son más comunes en la actualidad, en este artículo.
Bases de datos agregadas
Tomemos un ejemplo para comprender este concepto de base de datos agregada. A continuación se muestra cómo se ve un artículo sobre analyticsvidhya:
 Si estuviéramos usando RDBMS para almacenar nuestros datos para DataPeaker, habríamos creado tablas relacionales. Uno puede ser para información relacionada con el autor, otro puede ser sobre la información relacionada con el artículo e incluso otro puede corresponder a cada categoría. Pero cuando abrimos un artículo, necesitamos todas estas informaciones juntas. Por lo tanto, estamos más interesados en información agregada que en información tan granular. Sin embargo, la información granular podría haberme dado un mejor alcance de análisis, por lo que podría estar más interesado en minimizar el tiempo de carga de la página web. Por lo tanto, necesitamos una base de datos en la que toda esta información se almacene en un solo lugar. Esto puede denominarse bases de datos orientadas a agregados.
Si estuviéramos usando RDBMS para almacenar nuestros datos para DataPeaker, habríamos creado tablas relacionales. Uno puede ser para información relacionada con el autor, otro puede ser sobre la información relacionada con el artículo e incluso otro puede corresponder a cada categoría. Pero cuando abrimos un artículo, necesitamos todas estas informaciones juntas. Por lo tanto, estamos más interesados en información agregada que en información tan granular. Sin embargo, la información granular podría haberme dado un mejor alcance de análisis, por lo que podría estar más interesado en minimizar el tiempo de carga de la página web. Por lo tanto, necesitamos una base de datos en la que toda esta información se almacene en un solo lugar. Esto puede denominarse bases de datos orientadas a agregados.
Bases de datos de valores clave / Bases de datos de documentos :
Las bases de datos de valores clave y las bases de datos de documentos son muy similares. Puede pensar en las bases de datos de documentos como una forma anidada de bases de datos de valores clave. A continuación, se muestra una base de datos de clave-valor simple:
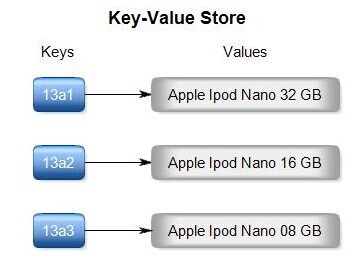
Crédito de la imagen: http://nosql.rishabhagrawal.com
Ahora, si quiero obtener información en un Ipod de 16 GB, solo necesito proporcionar el KET «13a2» a la base de datos. A continuación se muestra cómo se verá una base de datos de documentos:

Tenga en cuenta que en cada documento tenemos información agregada sobre esa identificación. Vincula esto con nuestro ejemplo de analyticsvidhya. En nuestro caso, tendremos todo el nombre del autor, el nombre del título, etc. como pares clave-valor en cada documento. Ahora puedo extraer todo el documento de una vez, ya que está almacenado en el mismo objeto.
Bases de datos orientadas a columnas :
Imagine que tiene una tabla de pedidos RDBMS con 1 millón de filas y 100 columnas. Ahora desea extraer todos los nombres de los clientes con pedidos de más de $ 500. Básicamente, necesita un comando en solo dos columnas, pero para hacer esta consulta, esencialmente tendrá que navegar por las 100 columnas. Las bases de datos orientadas a columnas dan una solución a este problema. Una discusión detallada sobre este tipo de base de datos está fuera del alcance de este artículo, pero lo que necesita comprender es solo el concepto subyacente. A continuación se muestra un ejemplo simple de una base de datos orientada a filas y a columnas:
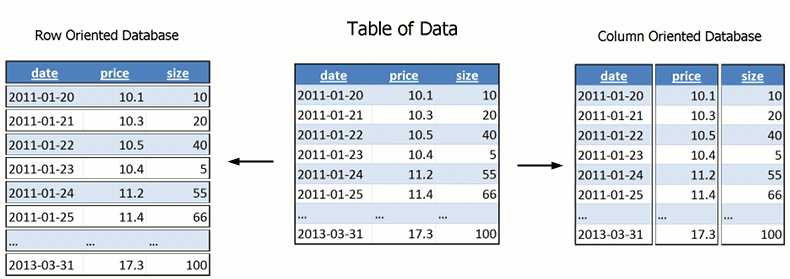
Crédito de la imagen: www.timestored.com
La base de datos orientada a columnas almacena cada columna en una ubicación separada, lo que nos permite llegar solo a aquellas columnas que son necesarias para nosotros. Esto hace que las consultas sean mucho más rápidas en las operaciones de búsqueda y filtrado.
Notas finales
Las bases de datos NoSQL están ampliando nuestros límites para almacenar y analizar datos. Con tales estructuras sin esquema, también nos permiten cambiar variables / atributos en cualquier momento. Son excepcionalmente rápidos para ejecutar consultas en estas entidades agregadas. Sin embargo, esta declaración viene con un título que en caso de que la operación no deba realizarse en el nivel agregado de la tabla, se vuelve más complicado en comparación con RDBMS. Por ejemplo, si tenemos datos almacenados para cada pedido en la base de datos agregada NoSQL. Cualquier consulta que tenga que ver con estos ID de pedido será excepcionalmente rápida. Pero en caso de que necesite información a nivel de cliente o producto, es posible que estas tablas no sean muy eficientes. Para tales procesos, necesitará escribir consultas de MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data..... Por lo tanto, todo depende del tipo de uso en cuanto a qué base de datos le conviene más.
¿Le resultó útil el artículo? Comparta con nosotros sus experiencias con diferentes tipos de bases de datos NoSQL. Háganos saber su opinión sobre este artículo en el cuadro a continuación.





