Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción

Web Scraping es un método o arte para obtener o eliminar datos de Internet o sitios web y almacenarlos localmente en su sistema. Web Scripting es una estrategia programada para adquirir mucha información de los sitios.
La gran mayoría de esta información es información no estructurada en un diseño HTML que luego se convierte en información organizada en una página de contabilidad o un conjunto de datos, por lo que tiende a utilizarse en diferentes aplicaciones. Existe una amplia gama de enfoques para realizar web scraping para obtener información de los sitios. Estos incluyen la utilización de aplicaciones web, API específicas o, en cualquier caso, hacer su código para web scraping sin ningún tipo de preparación.
Numerosos sitios enormes como Google, Twitter, Facebook, StackOverflow, etc. tienen API que le permiten acceder a su información en una organización organizada. Esta es la opción más ideal, pero las diferentes configuraciones regionales no permiten a los clientes acceder a mucha información en una estructura organizada o, en esencia, no progresan de manera tan mecánica. Por ahí, es ideal utilizar Web Scraping para buscar información en el sitio.

Web Scrapers puede extraer toda la información sobre destinos específicos o la información particular que necesita un cliente. Preferiblemente, es ideal si indica la información que necesita para que el raspador web simplemente concentre esa información rápidamente. Por ejemplo, debe rayar una página de Amazon para los tipos de exprimidores disponibles, sin embargo, es posible que solo necesite la información sobre los modelos de varios exprimidores y no las auditorías del cliente.
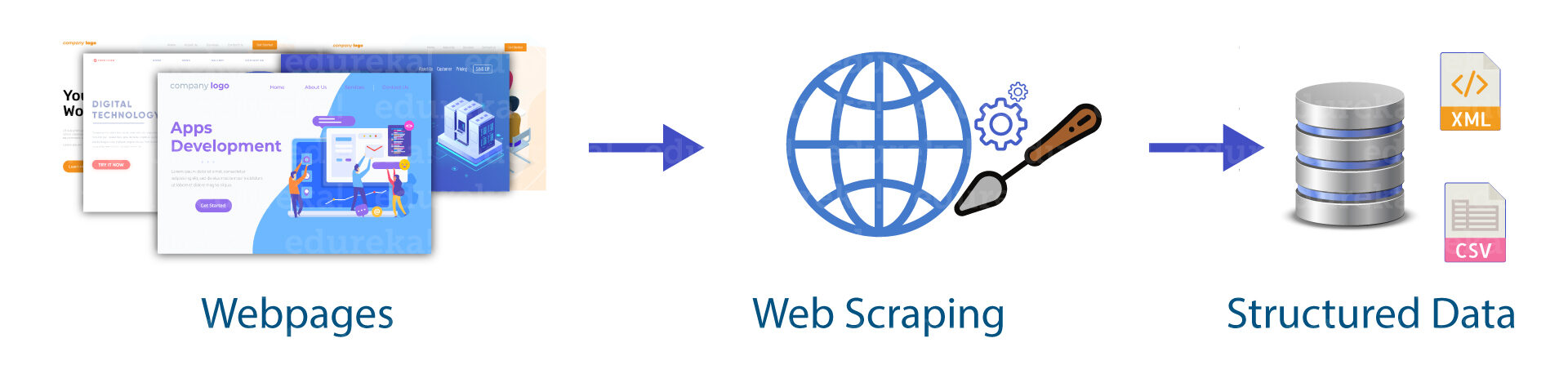
Entonces, cuando un depurador web necesita rayar un sitio web, primero se le proporcionan las URL de las configuraciones regionales necesarias. En ese punto, apila todo el código HTML para esos destinos y un raspador más desarrollado puede incluso concentrar todos los componentes CSS y Javascript también. En ese punto, el raspador adquiere la información necesaria de este código HTML y cede esta información en la organización indicada por el cliente.
Generalmente, esto es como una página de contabilidad de Excel o un registro CSV, sin embargo, la información también se puede guardar en diferentes organizaciones, por ejemplo, un documento JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software....

Bibliotecas populares de Python para web scraping
- Peticiones
- Hermosa sopa 4
- lxml
- Selenio
- Scrapy
AutoScraper
Es una biblioteca de raspado web de Python para hacer que el raspado web sea inteligente, automático, rápido y fácil. También es liviano, lo que significa que no afectará mucho a su PC. Un usuario puede usar fácilmente esta herramienta para raspar datos debido a su interfaz fácil de usar. Para comenzar, solo necesita escribir algunas líneas de códigos y verá la magia.
Solo tiene que proporcionar la URL o el contenido HTML de la página web de la que desea eliminar los datos, además, un resumen de la información de prueba que debemos eliminar de esa página. Esta información puede ser texto, URL o cualquier etiqueta HTML de esa página. Aprende las reglas de raspado por sí solo y devuelve elementos similares.
En este artículo, investigaremos Autoscraper y percibiremos cómo podemos utilizarlo para eliminar información de nosotros.

Instalación
Hay 3 formas de instalar esta biblioteca en su sistema.
- Instalar desde el repositorio de git usando pip:
pip install git+https://github.com/alirezamika/autoscraper.git
pip install autoscraper
python setup.py install
Importando biblioteca
Solo importaremos un raspador automático, ya que es adecuado solo para rayar la web. A continuación se muestra el código para importar:
from autoscraper import AutoScraper
Definición de la función de raspado web
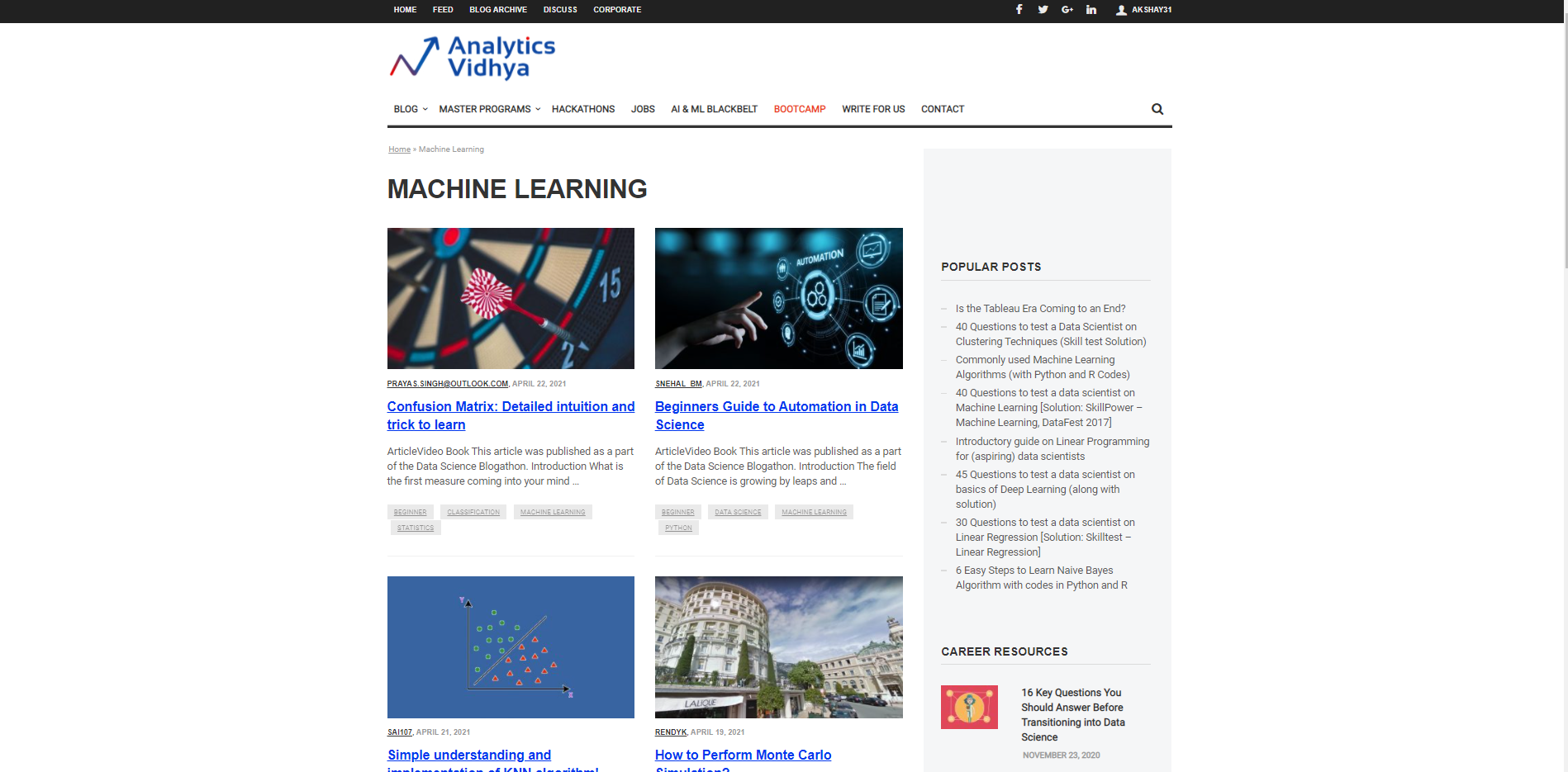
Permítanos comenzar caracterizando una URL desde la cual se utilizará para traer la información y la prueba de información necesaria que se va a traer. Supongamos que queremos buscar el títulos para diferentes artículos sobre Machine Learning en el sitio web DataPeaker. Por lo tanto, tenemos que pasar la URL de la sección del blog de aprendizaje automático de DataPeaker y la segunda lista de buscados. La lista de buscados es una lista que es Data de muestra que queremos extraer de esa página. Por ejemplo, aquí la lista de buscados es un título de cualquier blog en la sección de blogs de aprendizaje automático de DataPeaker.
url="https://www.analyticsvidhya.com/blog/category/machine-learning/" wanted_list = ['Confusion Matrix: Detailed intuition and trick to learn']
Podemos agregar uno o varios candidatos a la lista de buscados. También puede colocar URL en la lista de buscados para recuperar las URL.
Iniciar el AutoScraper
El siguiente paso después de iniciar la URL y la lista de buscados es llamar a la función AutoScraper. Nuestro objetivo es utilizar esta función para construir el modelo de raspador y realizar raspado web en esa página en particular.
Esto se puede iniciar usando el siguiente código:
scraper = AutoScraper()
Construyendo el Objeto
Este es el paso final en el web scraping con esta biblioteca en particular. Aquí, cree el objeto y muestre el resultado del web scraping.
scraper = AutoScraper() result = scraper.build(url, wanted_list) print(result)

Aquí, en la imagen de arriba, puedes ver que regresa. el título de los blogs en el sitio web de DataPeaker en la sección de aprendizaje automático, de manera similar, podemos obtener las URL de los blogs simplemente pasando la URL de muestra en la lista de buscados que definimos anteriormente.
url="https://www.analyticsvidhya.com/blog/category/machine-learning/" wanted_list = ['https://www.analyticsvidhya.com/blog/2021/04/confusion-matrix-detailed-intuition-and-trick-to-learn/'] scraper = AutoScraper() result = scraper.build(url, wanted_list) print(result)
Aquí está la salida del código anterior. Puede ver que he pasado esta vez la URL en la lista de buscados, como resultado, puede ver el resultado como las URL de los blogs

Guardar el modelo
Nos permite guardar el modelo que tenemos que construir para poder recargarlo cuando sea necesario.
Para guardar el modelo, use el siguiente código
scraper.save('blogs') #Give it a file path
Para cargar el modelo, use el siguiente código:
scraper.load('blogs')
Nota: Aparte de cada una de estas funcionalidades, el raspador automático también le permite caracterizar direcciones IP de proxy con el objetivo de que pueda utilizarlas para obtener información. Simplemente necesitamos caracterizar los proxies y pasarlos como un argumento a la función de construcción como se muestra a continuación:
proxies = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
result = scraper.build(url, wanted_list, request_args=dict(proxies=proxies))
Para obtener más información, consulte el siguiente enlace: AutoScraper
Conclusión
En este artículo, percibimos cómo podemos utilizar Autoscraper para web scraping haciendo un modelo básico y simple de utilizar. Vimos varios formatos en los que se puede recuperar información utilizando Autoscraper. También podemos guardar y cargar el modelo para utilizarlo más tarde, lo que ahorra tiempo y esfuerzo. Autoscraper es asombroso, fácil de utilizar y eficiente.
Gracias por leer este artículo y por tu paciencia. Déjame en la sección de comentarios sobre comentarios. Comparta este artículo, me dará la motivación para escribir más blogs para la comunidad de ciencia de datos.
Identificación de correo: gakshay1210@ gmail.com
Sígueme en LinkedIn: LinkedIn
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





