Este artículo fue publicado como parte del Blogatón de ciencia de datos
1. Objetivo
El objetivo de este artículo es predecir los precios de los vuelos dados los distintos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto..... Los datos utilizados en este artículo están disponibles públicamente en Kaggle. Este será un problema de regresión ya que la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... objetivo o dependiente es el precio (valor numérico continuo).
2. Introducción
Las compañías aéreas utilizan algoritmos complejos para calcular los precios de los vuelos dadas las diversas condiciones presentes en ese momento en particular. Estos métodos tienen en cuenta factores financieros, de marketing y sociales para predecir los precios de los vuelos.
Hoy en día, el número de personas que utilizan vuelos ha aumentado significativamente. Es difícil para las aerolíneas mantener los precios, ya que los precios cambian dinámicamente debido a diferentes condiciones. Es por eso que intentaremos utilizar el aprendizaje automático para resolver este problema. Esto puede ayudar a las aerolíneas al predecir qué precios pueden mantener. También puede ayudar a los clientes a predecir los precios futuros de los vuelos y planificar su viaje en consecuencia.
3. Datos utilizados
Se utilizaron datos de Kaggle, que es una plataforma de acceso gratuito para científicos de datos y entusiastas del aprendizaje automático.
Fuente: https://www.kaggle.com/nikhilmittal/flight-fare-prediction-mh
Estamos usando jupyter-notebook para ejecutar la tarea de predicción de precios de vuelo.
4. Análisis de datos
El procedimiento de extraer información de datos brutos dados se llama análisis de datos. Aquí usaremos eda módulo de preparación de datos biblioteca para hacer este paso.
from dataprep.eda import create_report
import pandas as pd
dataframe = pd.read_excel("../output/Data_Train.xlsx")
create_report(dataframe)
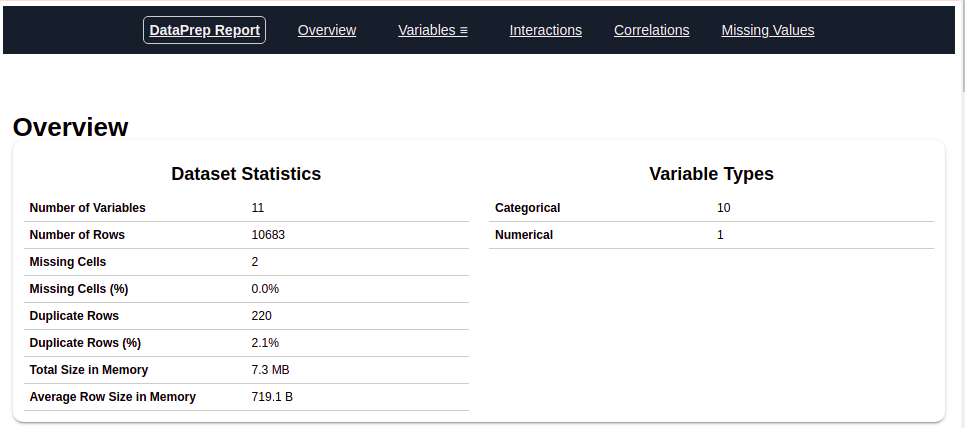
Después de ejecutar el código anterior, obtendrá un informe como se muestra en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior. Este informe contiene varias secciones o pestañas. La sección ‘Descripción general’ de este informe nos proporciona toda la información básica de los datos que estamos utilizando. Para los datos actuales que estamos usando, obtuvimos la siguiente información:
Número de variables = 11
Número de filas = 10683
Número de tipo categórico de característica = 10
Número de tipo numérico de característica = 1
Filas nuplicadas = 220, etc.
Exploremos otras secciones del informe una por una.
4.1 Variables
Después de seleccionar la sección de variables, obtendrá información como se muestra en las siguientes figuras.
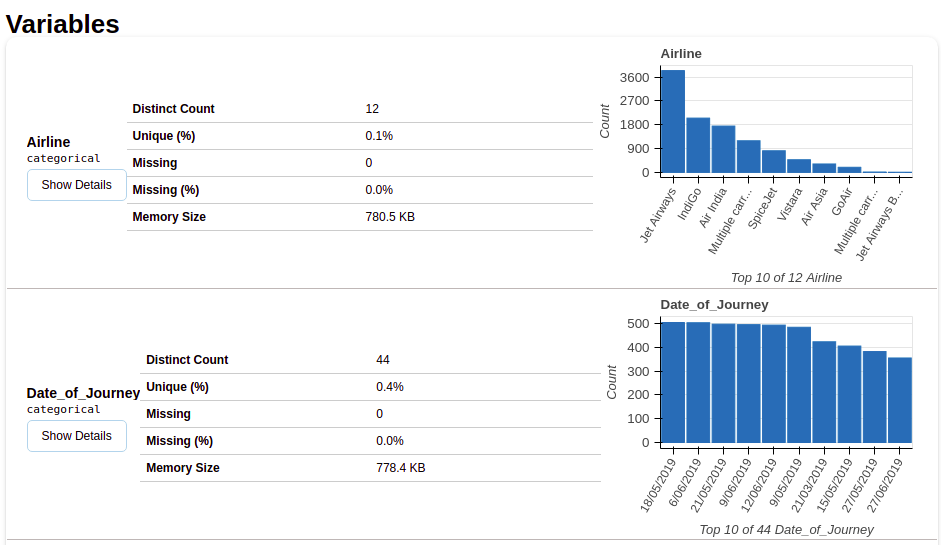
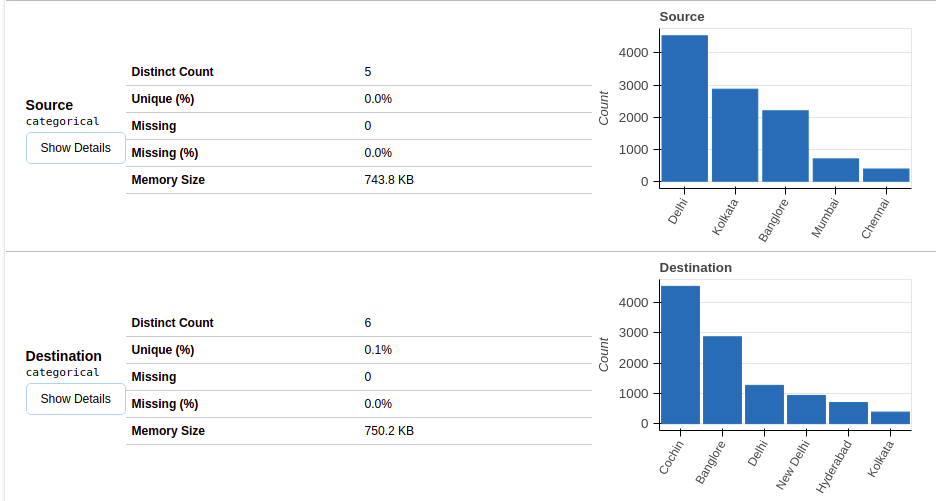
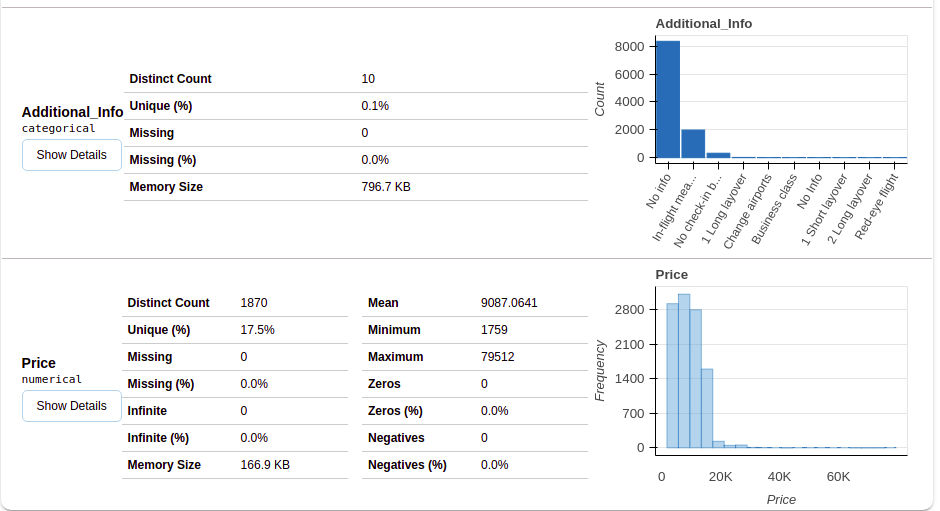
Esta sección proporciona el tipo de cada variable junto con una descripción detallada de la variable.
4.2 Valores perdidos
Esta sección tiene varias formas en las que podemos analizar los valores perdidos en las variables. Discutiremos tres métodos más utilizados, gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad...., espectro y mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas..... Exploremos cada uno por uno.
4.2.1 Gráfico de barras
El método de gráfico de barras muestra el ‘número de valores perdidos y presentes’ en cada variable en un color diferente.
4.2.2 Espectro
El método del espectro muestra el porcentaje de valores perdidos en cada variable.
4.2.3 Mapa de calor
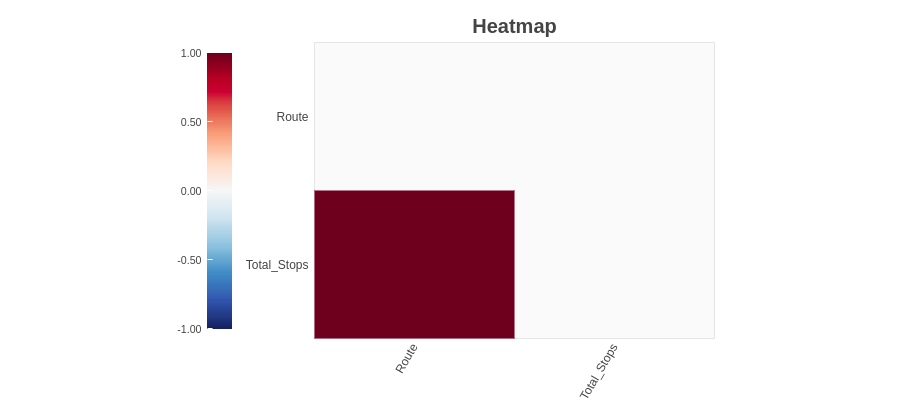
El método del mapa de calor muestra las variables que tienen valores perdidos en términos de correlación. Dado que ‘Ruta’ y ‘Total_Paradas’ están altamente correlacionados, ambos tienen valores perdidos.
Como podemos observar, las variables ‘Ruta’ y ‘Total_Paradas’ tienen valores perdidos. Dado que no encontramos ninguna información de valores faltantes del método de gráfico de barras y espectro, pero encontramos variables de valores faltantes utilizando el método del mapa de calor. Combinando esta información, podemos decir que las variables ‘Ruta’ y ‘Total_Paradas’ tienen valores perdidos pero son muy bajos.
5. Preparación de datos
Antes de comenzar la preparación de datos, primero echemos un vistazo a los datos.
dataframe.head()

Como vimos en Análisis de datos, hay 11 variables en los datos dados. A continuación se muestra la descripción de cada variable.
Aerolínea: Nombre de la aerolínea utilizada para viajar
Date_of_Journey: Fecha en la que viajó una persona
Fuente: Lugar de inicio del vuelo
Destino: Lugar de finalización del vuelo
Ruta: Contiene información sobre la ubicación de inicio y finalización del viaje en el formato estándar utilizado por las aerolíneas.
Dep_Time: Hora de salida del vuelo desde el lugar de inicio
Hora de llegada: Hora de llegada del vuelo al destino
Duración: Duración del vuelo en horas / minutos
Paradas_total: Número total de escalas que realizó el vuelo antes de aterrizar en el destino.
Información adicional: Muestra cualquier información adicional sobre un vuelo
Precio: Precio del vuelo
Pocas observaciones sobre algunas de las variables:
1. ‘Precio‘será nuestra variable dependiente y todas las variables restantes se pueden utilizar como variables independientes.
2. ‘Total_Paradas‘se puede utilizar para determinar si el vuelo fue directo o con conexión.
5.1 Manejo de valores perdidos
Como descubrimos, las variables ‘Ruta’ y ‘Total_Paradas’ tienen valores perdidos muy bajos en los datos. Veamos ahora el porcentaje de valores perdidos en los datos.
(dataframe.isnull().sum()/dataframe.shape[0])*100
Producción :
Airline 0.000000 Date_of_Journey 0.000000 Source 0.000000 Destination 0.000000 Route 0.009361 Dep_Time 0.000000 Arrival_Time 0.000000 Duration 0.000000 Total_Stops 0.009361 Additional_Info 0.000000 Price 0.000000 dtype: float64
Como podemos observar, ‘Route’ y ‘Total_Stops’ tienen ambos 0.0094% de valores perdidos. En este caso, es mejor eliminar los valores perdidos.
dataframe.dropna(inplace= True) dataframe.isnull().sum()
Producción :
Airline 0 Date_of_Journey 0 Source 0 Destination 0 Route 0 Dep_Time 0 Arrival_Time 0 Duration 0 Total_Stops 0 Additional_Info 0 Price 0 dtype: int64
Ahora no tenemos ningún valor perdido.
5.2 Manejo de variables de fecha y hora
Tenemos ‘Date_of_Journey’, una ‘variable de tipo de fecha y’ Dep_Time ‘,’ Arrival_Time ‘que captura información de tiempo.
Podemos extraer ‘Journey_day’ y ‘Journey_Month’ de la variable ‘Date_of_Journey’. «Día del viaje» muestra el día del mes en el que se inició el viaje.
dataframe["Journey_day"] = pd.to_datetime(dataframe.Date_of_Journey, format="%d/%m/%Y").dt.day dataframe["Journey_month"] = pd.to_datetime(dataframe["Date_of_Journey"], format = "%d/%m/%Y").dt.month dataframe.drop(["Date_of_Journey"], axis = 1, inplace = True)
De manera similar, podemos extraer ‘Hora de salida’ y ‘Hora de salida’ así como ‘Hora de llegada y Minuto de llegada’ de las variables ‘Hora_dep.’ Y ‘Hora de llegada’ respectivamente.
dataframe["Dep_hour"] = pd.to_datetime(dataframe["Dep_Time"]).dt.hour dataframe["Dep_min"] = pd.to_datetime(dataframe["Dep_Time"]).dt.minute dataframe.drop(["Dep_Time"], axis = 1, inplace = True)
dataframe["Arrival_hour"] = pd.to_datetime(dataframe.Arrival_Time).dt.hour dataframe["Arrival_min"] = pd.to_datetime(dataframe.Arrival_Time).dt.minute dataframe.drop(["Arrival_Time"], axis = 1, inplace = True)
También tenemos información sobre la duración de la variable ‘Duración’. Esta variable contiene información combinada de horas y minutos de duración.
Podemos extraer ‘Duración_horas’ y ‘Duración_minutos’ por separado de la variable ‘Duración’.
def get_duration(x):
x=x.split(' ')
hours=0
mins=0
if len(x)==1:
x=x[0]
if x[-1]=='h':
hours=int(x[:-1])
else:
mins=int(x[:-1])
else:
hours=int(x[0][:-1])
mins=int(x[1][:-1])
return hours,mins
dataframe['Duration_hours']=dataframe.Duration.apply(lambda x:get_duration(x)[0])
dataframe['Duration_mins']=dataframe.Duration.apply(lambda x:get_duration(x)[1])
dataframe.drop(["Duration"], axis = 1, inplace = True)
5.3 Manejo de datos categóricos
Aerolínea, Origen, Destino, Ruta, Total_Paradas, Información adicional son las variables categóricas que tenemos en nuestros datos. Manejemos cada uno por uno.
Variable de aerolínea
Veamos cómo se relaciona la variable Aerolínea con la variable Precio.
import seaborn as sns
sns.set()
sns.catplot(y = "Price", x = "Airline", data = train_data.sort_values("Price", ascending = False), kind="boxen", height = 6, aspect = 3)
plt.show()
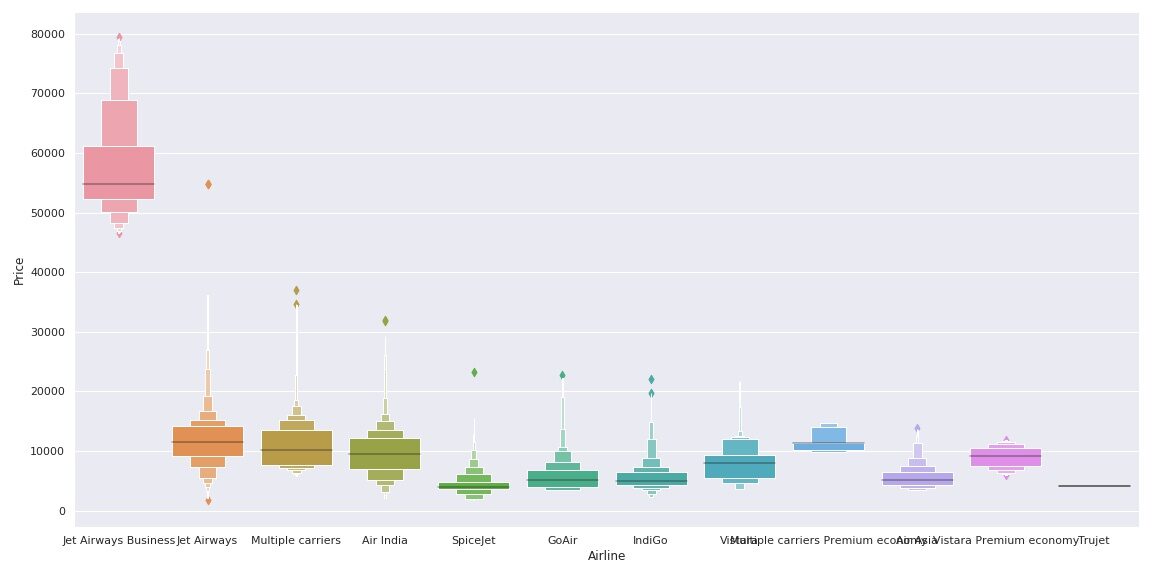
Como podemos ver, el nombre de la aerolínea importa. ‘JetAirways Business’ tiene el rango de precios más alto. El precio de otras aerolíneas también varía.
Desde el Aerolínea variable es Datos categóricos nominales (No hay orden de ningún tipo en los nombres de las aerolíneas) usaremos codificación one-hot para manejar esta variable.
Airline = dataframe[["Airline"]] Airline = pd.get_dummies(Airline, drop_first= True)
Los datos de ‘Aerolínea’ codificados en One-Hot se guardan en la variable Aerolínea como se muestra en el código anterior.
Variable de origen y destino
Nuevamente, las variables de ‘Fuente’ y ‘Destino’ son datos categóricos nominales. Usaremos la codificación One-Hot nuevamente para manejar estas dos variables.
Source = dataframe[["Source"]] Source = pd.get_dummies(Source, drop_first= True) Destination = train_data[["Destination"]] Destination = pd.get_dummies(Destination, drop_first = True)
Variable de ruta
La variable de ruta representa la ruta del viaje. Dado que la variable ‘Total_Stops’ captura la información si el vuelo es directo o conectado, he decidido eliminar esta variable.
dataframe.drop(["Route", "Additional_Info"], axis = 1, inplace = True)
Total_Paradas Variable
dataframe["Total_Stops"].unique()
Producción:
array(['non-stop', '2 stops', '1 stop', '3 stops', '4 stops'],
dtype=object)
Aquí, sin escalas significa 0 escalas, lo que significa vuelo directo. De manera similar, el significado de otros valores es obvio. Podemos ver que es un Datos categóricos ordinales entonces usaremos LabelEncoder aquí para manejar esta variable.
dataframe.replace({"non-stop": 0, "1 stop": 1, "2 stops": 2, "3 stops": 3, "4 stops": 4}, inplace = True)
Variable Additional_Info
dataframe.Additional_Info.unique()
Producción:
array(['No info', 'In-flight meal not included',
'No check-in baggage included', '1 Short layover', 'No Info',
'1 Long layover', 'Change airports', 'Business class',
'Red-eye flight', '2 Long layover'], dtype=object)
Como podemos ver, esta característica captura información relevante que puede afectar el precio del vuelo de manera significativa. También se repiten los valores ‘Sin información’. Manejemos eso primero.
dataframe['Additional_Info'].replace({"No info": 'No Info'}, inplace = True)
Ahora bien, esta variable también es Datos categóricos nominales. Usemos One-Hot Encoding para manejar esta variable.
Add_info = dataframe[["Additional_Info"]] Add_info = pd.get_dummies(Add_info, drop_first = True)
5.4 Marco de datos final
Ahora crearemos el marco de datos final concatenando todas las características codificadas por etiquetas y One-hot en el marco de datos original. También eliminaremos las variables originales con las que hemos preparado nuevas variables codificadas.
dataframe = pd.concat([dataframe, Airline, Source, Destination,Add_info], axis = 1) dataframe.drop(["Airline", "Source", "Destination","Additional_Info"], axis = 1, inplace = True)
Veamos el número de variables finales que tenemos en el marco de datos.
dataframe.shape[1]
Producción:
38
Entonces, tenemos 38 variables en el marco de datos final, incluida la variable dependiente ‘Precio’. Solo hay 37 variables para el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.....
6. Construcción de modelos
X=dataframe.drop('Price',axis=1)
y=dataframe['Price']
#train-test split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
6.1 Aplicación de la predicción perezosa
Uno de los problemas del ejercicio de creación de modelos es «¿Cómo decidir qué algoritmo de aprendizaje automático aplicar?»
Aquí es donde entra en juego Lazy Prediction. Lazy Prediction es una biblioteca de aprendizaje automático disponible en Python que puede proporcionarnos rápidamente el rendimiento de múltiples clasificaciones estándar o modelos de regresión en múltiples matrices de rendimiento.
Vamos a ver cómo funciona…
Como estamos trabajando en una tarea de Regresión, usaremos modelos Regresores.
from lazypredict.Supervised import LazyRegressor reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None) models, predictions = reg.fit(x_train, x_test, y_train, y_test) models.head(10)
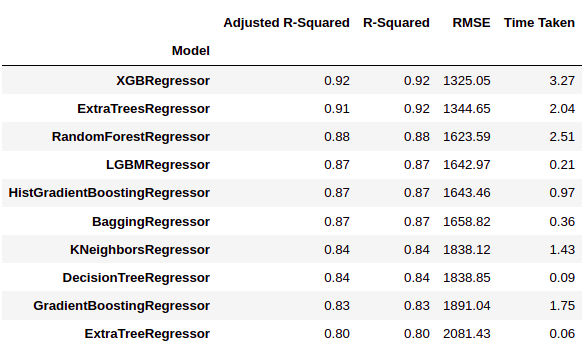
Como podemos ver, LazyPredict nos da resultados de múltiples modelos en múltiples matrices de desempeño. En la figura anterior, hemos mostrado los diez mejores modelos.
Aquí ‘XGBRegressor’ y ‘ExtraTreesRegressor’ superan significativamente a otros modelos. Se necesita una gran cantidad de tiempo de entrenamiento con respecto a otros modelos. En este paso podemos elegir la prioridad si queremos «tiempo» o «rendimiento».
Hemos decidido elegir «rendimiento» sobre el tiempo de entrenamiento. Así que entrenaremos a ‘XGBRegressor y visualizaremos los resultados finales.
6.2 Entrenamiento de modelos
from xgboost import XGBRegressor model = XGBRegressor() model.fit(x_train,y_train)
Producción:
XGBRegressor(base_score=0.5, booster="gbtree", colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type="gain", interaction_constraints="",
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints="()",
n_estimators=100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None)
Comprobemos el rendimiento del modelo …
y_pred = model.predict(x_test)
print('Training Score :',model.score(x_train, y_train))
print('Test Score :',model.score(x_test, y_test))
Producción:
Training Score : 0.9680428701701702 Test Score : 0.918818721300552
Como podemos ver, la puntuación del modelo es bastante buena. Visualicemos los resultados de algunas predicciones.
number_of_observations=50
x_ax = range(len(y_test[:number_of_observations]))
plt.plot(x_ax, y_test[:number_of_observations], label="original")
plt.plot(x_ax, y_pred[:number_of_observations], label="predicted")
plt.title("Flight Price test and predicted data")
plt.xlabel('Observation Number')
plt.ylabel('Price')
plt.legend()
plt.show()
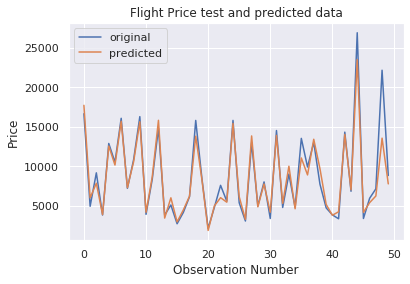
Como podemos observar en la figura anterior, las predicciones del modelo y los precios originales se superponen. Este resultado visual confirma la alta puntuación del modelo que vimos anteriormente.
7. Conclusión
En este artículo, vimos cómo aplicar la biblioteca Laze Prediction para elegir el mejor algoritmo de aprendizaje automático para la tarea en cuestión.
Lazy Prediction ahorra tiempo y esfuerzos para crear un modelo de aprendizaje automático al proporcionar rendimiento del modelo y tiempo de capacitación. Uno puede elegir cualquiera según la situación en cuestión.
También se puede utilizar para crear un conjunto de modelos de aprendizaje automático. Hay muchas formas en las que se pueden utilizar las funcionalidades de la biblioteca LazyPredict.
Espero que este artículo le haya ayudado a comprender los enfoques de análisis de datos, preparación de datos y creación de modelos de una manera mucho más sencilla.
Comuníquese con la sección de comentarios en caso de cualquier consulta.
Gracias y que tenga un buen día. 🙂
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





