Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y... es un marco utilizado en entornos de computación en clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... para analizar big data. Apache Spark puede trabajar en un entorno distribuido en un grupo de computadoras en un clúster para procesar de manera más efectiva grandes conjuntos de datos. Este motor de código abierto Spark admite una amplia gama de lenguajes de programación, incluidos Scala, Java, R y Python.
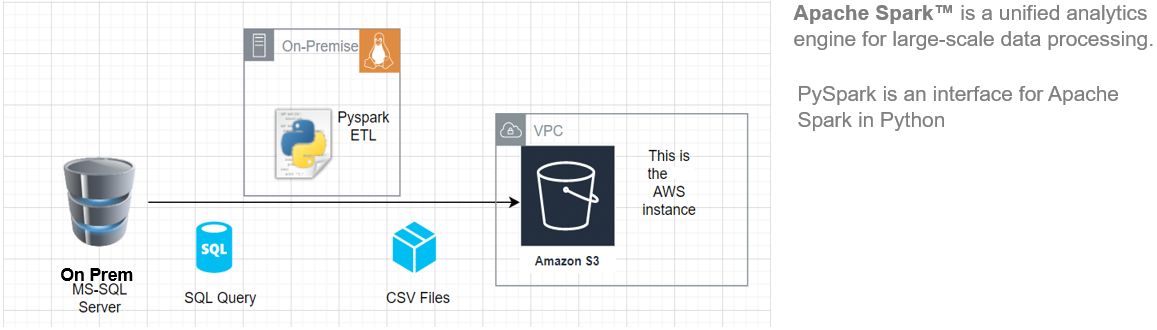
En este artículo, le mostraré cómo comenzar a instalar Pyspark en su Ubuntu máquina y luego construir una tubería ETL básica para extraer datos de carga de transferencia de un sistema RDBMS remoto a un AWS S3 Cubeta.
Esta arquitectura ETL se puede utilizar para transferir cientos de Gigabytes de datos desde cualquier servidor de base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... RDBMS (en este artículo hemos utilizado MS SQL Server) a un bucket de Amazon S3.
Ventajas clave de usar Apache Spark:
- Ejecute cargas de trabajo 100 veces más rápido que Hadoop
- Compatible con Java, Scala, Python, R y SQL
Fuente: Esta es una imagen original.
Requisitos
Para comenzar, debemos tener los siguientes requisitos previos:
- Un sistema que ejecuta Ubuntu 18.04 o Ubuntu 20.04
- Una cuenta de usuario con privilegios de sudo
- Una cuenta de AWS con acceso de carga al bucket de S3
Antes de descargar y configurar Spark, debe instalar las dependencias de paquetes necesarias. Asegúrese de que los siguientes paquetes ya estén configurados en su sistema.
Para confirmar las dependencias instaladas ejecutando estos comandos:
java -version; git --version; python --version

Instalar PySpark
Descargue la versión de Spark que desee del sitio web oficial de Apache. Descargaremos Spark 3.0.3 con Hadoop 2.7 ya que es la versión actual. A continuación, use el comando wget y la URL directa para descargar el paquete Spark.
Cambie su directorio de trabajo a / opt / spark.
cd /opt/spark
sudo wget https://downloads.apache.org/spark/spark-3.0.3/spark-3.0.3-bin-hadoop2.7.tgz

Extraiga el paquete guardado usando el comando tar. Una vez que se completa el proceso de untar, la salida muestra los archivos que se han descomprimido del archivo.
tar xvf spark-*
ls -lrt spark-*

Configurar el entorno de Spark
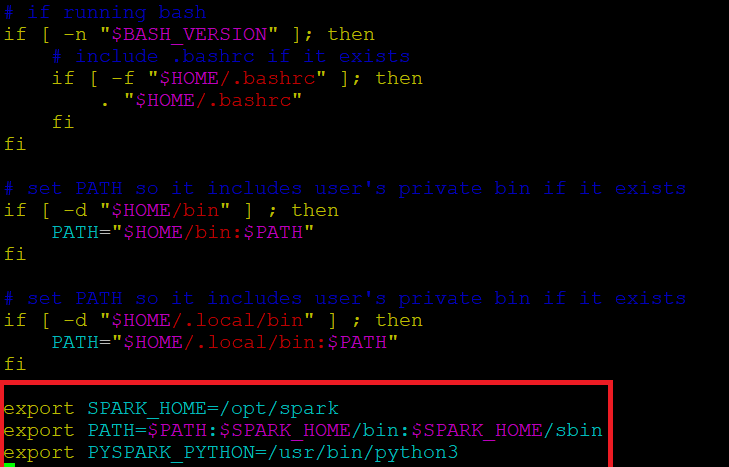
Antes de iniciar un servidor Spark, necesitamos configurar algunas variables de entorno. Hay algunos directorios de Spark que debemos agregar al perfil predeterminado. Utilice el editor vi o cualquier otro editor para agregar estas tres líneas a .profile:
vi ~/.profile
Inserte estas 3 líneas al final del archivo .profile.
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin export PYSPARK_PYTHON=/usr/bin/python3
Guarde los cambios y salga del editor. Cuando termine de editar el archivo, cargue el .perfil archivo en la línea de comando escribiendo. Alternativamente, podemos salir del servidor y volver a iniciar sesión para que los cambios surtan efecto.
source ~/.profile
Start / Stop Spark Master & Worker
Vaya al directorio de instalación de Spark / opt / spark / spark *. Tiene todos los scripts necesarios para iniciar / detener los servicios de Spark.
Ejecute este comando para iniciar Spark Master.
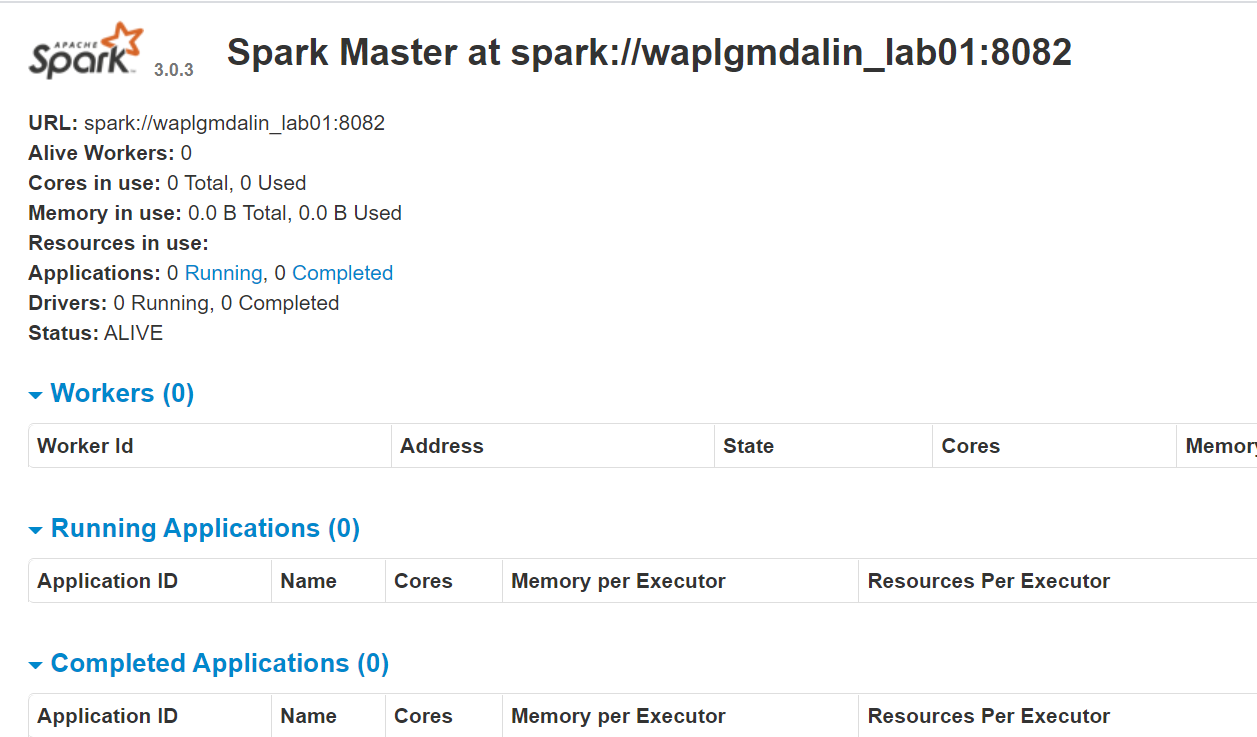
start-master.shPara ver la interfaz web de Spark, abra un navegador web e ingrese la dirección IP del host local en el puerto 8080. (Este es el puerto predeterminado que Spark usa si necesita cambiarlo, hágalo en el script start-master.sh). Alternativamente, puede reemplazar 127.0.0.1 con la dirección IP de red real de su máquina host.
http://127.0.0.1:8080/La página web muestra la URL maestra de Spark, los nodos de trabajo, la utilización de recursos de la CPU, la memoria, las aplicaciones en ejecución, etc.
Ahora, ejecute este comando para iniciar una instancia de trabajador de Spark.
start-slave.sh spark://0.0.0.0:8082
o
start-slave.sh spark://waplgmdalin_lab01:8082
La propia página web del trabajador se ejecuta en http://127.0.0.1:8084/ pero debe estar vinculado al maestro. Es por eso que pasamos la URL maestra de Spark como parámetro al script start-slave.sh. Para confirmar si el trabajador está correctamente vinculado al maestro, abra el vínculo en un navegador.
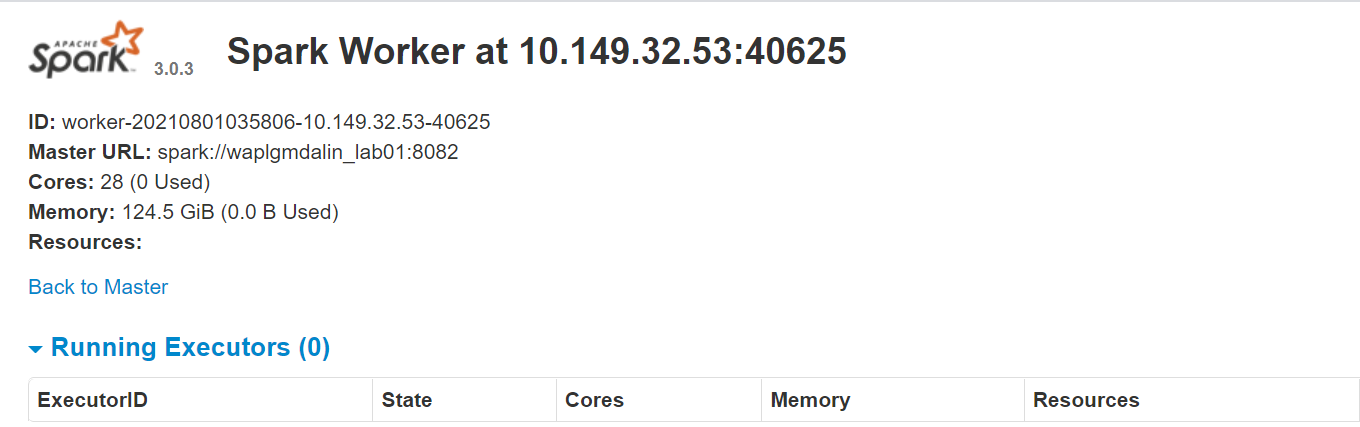
Asignación de recursos al trabajador de Spark
De forma predeterminada, cuando inicia una instancia de trabajador, utiliza todos los núcleos disponibles en la máquina. Sin embargo, por razones prácticas, es posible que desee limitar la cantidad de núcleos y la cantidad de RAM asignada a cada trabajador.
start-slave.sh spark://0.0.0.0:8082 -c 4 -m 512M
Aquí, hemos asignado 4 núcleos y 512 MB de RAM al trabajador. Confirmemos esto reiniciando la instancia del trabajador.
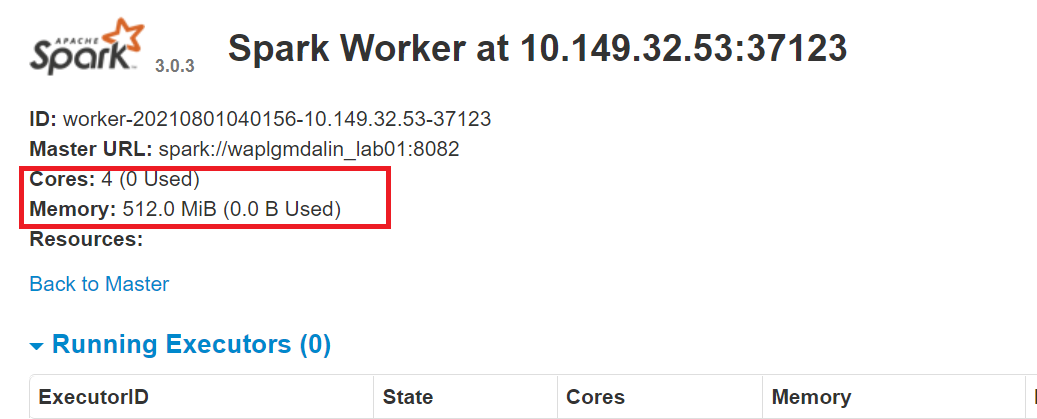
Para detener al maestro instancia iniciada ejecutando el script anterior, ejecute:
stop-master.shPara detener a un trabajador que corre proceso, ingrese este comando:
stop-slave.shConfigurar conexión MS SQL
En este ETL de PySpark, nos conectaremos a una instancia de servidor MS SQL como sistema de origen y ejecutaremos consultas SQL para obtener datos. Entonces, primero tenemos que descargar las dependencias necesarias.
Descargue el archivo jar de MS-SQL (mssql-jdbc-9.2.1.jre8) del sitio web de Microsoft y cópielo en el directorio «/ opt / spark / jars».
https://www.microsoft.com/en-us/download/details.aspx?id=11774
Descargue el archivo jar de Spark SQL (chispa-sql_2.12-3.0.3.jar) desde el sitio de descarga de Apache y cópielo en el directorio ‘/ opt / spark / jars ”.
https://jar-download.com/?search_box=org.apache.spark+spark.sql
Edite el .profile, agregue las clases PySpark y Py4J a la ruta de Python:
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.10.9-src.zip:$PYTHONPATH
Configurar la conexión AWS S3
Para conectarnos a una instancia de AWS, necesitamos descargar los tres archivos jar y copiarlos en el directorio «/ opt / spark / jars». Verifique la versión de Hadoop que está utilizando actualmente. Puede obtenerlo de cualquier jar presente en su instalación de Spark. Si la versión de Hadoop es 2.7.4, descargue el archivo jar para la misma versión. Para Java SDK, debe descargar la misma versión que se utilizó para generar el paquete Hadoop-aws.
Asegúrese de que las versiones sean las más recientes.
- hadoop-aws-2.7.4.jar
- aws-java-sdk-1.7.4.jar
- jets3t-0.9.4.jar
sudo wget https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk/1.11.30/aws-java-sdk-1.7.4.jar sudo wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/2.7.3/hadoop-aws-2.7.4.jar sudo wget https://repo1.maven.org/maven2/net/java/dev/jets3t/jets3t/0.9.4/jets3t-0.9.4.jar
Desarrollo de Python
Cree un directorio de trabajo llamado ‘scripts’ para almacenar todos los scripts y archivos de configuración de Python. Cree un archivo llamado «sqlfile.py» que contendrá las consultas SQL que queremos ejecutar en el servidor de base de datos remoto.
vi sqlfile.py
Inserte la siguiente consulta SQL en el archivo sqlfile.py que extraerá los datos. Antes de este paso, es recomendable realizar una prueba de ejecución de esta consulta SQL en el servidor para tener una idea de la cantidad de registros devueltos.
query1 = """(select * from sales-data where date >= '2021-01-01' and status="Completed")"""
Guarde y salga del archivo.
Cree un archivo de configuración llamado «config.ini» que almacenará las credenciales de inicio de sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... y los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de la base de datos.
vi config.ini
Inserte los siguientes parámetros de conexión de AWS y MSSQL en el archivo. Tenga en cuenta que hemos creado secciones independientes para almacenar los parámetros de conexión de AWS y MSSQL. Puede crear tantas instancias de conexión de base de datos como sea necesario, siempre que cada una se mantenga en su propia sección (mssql1, mssql2, aws1, aws2, etc.).
[aws]
ACCESS_KEY=BBIYYTU6L4U47BGGG&^CF SECRET_KEY=Uy76BBJabczF7h6vv+BFssqTVLDVkKYN/f31puYHtG BUCKET_NAME=s3-bucket-name DIRECTORY=sales-data-directory [mssql] url = jdbc:sqlserver://PPOP24888S08YTA.APAC.PAD.COMPANY-DSN.COM:1433;databaseName=Transactions database = Transactions user = MSSQL-USER password = MSSQL-Password dbtable = sales-data filename = data_extract.csv
Guarde y salga del archivo.
Cree una secuencia de comandos de Python llamada «Data-Extraction.py».
Importar bibliotecas para Spark y Boto3
Spark está implementado en Scala, un lenguaje que se ejecuta en la JVM, pero como estamos trabajando con Python usaremos PySpark. La versión actual de PySpark es 2.4.3 y funciona con Python 2.7, 3.3 y superior. Puede pensar en PySpark como un contenedor basado en Python sobre la API de Scala.
Aquí, AWS SDK para Python (Boto3) para crear, configurar y administrar servicios de AWS, como Amazon EC2 y Amazon S3. El SDK proporciona una API orientada a objetos, así como acceso de bajo nivel a los servicios de AWS.
Importe las bibliotecas de Python para iniciar una sesión de Spark, query1 desde sqlfile.py y boto3.
from pyspark.sql import SparkSession import shutil import os import glob import boto3 from sqlfile import query1 from configparser import ConfigParser
Crear una SparkSession
SparkSession proporciona un único punto de entrada para interactuar con el motor Spark subyacente y permite programar Spark con API de DataFrame y DatasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos..... Lo más importante es que restringe la cantidad de conceptos y construcciones con las que un desarrollador tiene que trabajar mientras interactúa con Spark. En este punto, puede usar el ‘Chispa – chispear’ variable como su objeto de instancia para acceder a sus métodos e instancias públicos durante la duración de su trabajo de Spark. Dale un nombre a la aplicación.
appName = "PySpark ETL Example - via MS-SQL JDBC"
master = "local"
spark = SparkSession
.builder
.master(master)
.appName(appName)
.config("spark.driver.extraClassPath","/opt/spark/jars/mssql-jdbc-9.2.1.jre8.jar")
.getOrCreate()
Leer el archivo de configuración
Hemos almacenado los parámetros en un archivo «config.ini» para separar los parámetros estáticos del código Python. Esto ayuda a escribir un código más limpio sin ningún tipo de codificación. Este modulo implementa un lenguaje de configuración básico que proporciona una estructura similar a la que vemos en los archivos .ini de Microsoft Windows.
url = config.get('mssql-onprem', 'url')
user = config.get('mssql-onprem', 'user')
password = config.get('mssql-onprem', 'password')
dbtable = config.get('mssql-onprem', 'dbtable')
filename = config.get('mssql-onprem', 'filename')
ACCESS_KEY=config.get('aws', 'ACCESS_KEY')
SECRET_KEY=config.get('aws', 'SECRET_KEY')
BUCKET_NAME=config.get('aws', 'BUCKET_NAME')
DIRECTORY=config.get('aws', 'DIRECTORY')
Ejecutar la extracción de datos
Spark incluye una fuente de datosUna "fuente de datos" se refiere a cualquier lugar o medio donde se puede obtener información. Estas fuentes pueden ser tanto primarias, como encuestas y experimentos, como secundarias, como bases de datos, artículos académicos o informes estadísticos. La elección adecuada de una fuente de datos es crucial para garantizar la validez y la fiabilidad de la información en investigaciones y análisis.... que puede leer datos de otras bases de datos utilizando JDBC. Ejecute SQL en la base de datos remota conectándose utilizando los parámetros de conexión y el controlador JDBC de Microsoft SQL Server. En la opción «consulta», si desea leer una tabla completa, proporcione el nombre de la tabla; de lo contrario, si desea ejecutar la consulta de selección, especifique el mismo. Los datos devueltos por SQL se almacenan en un marco de datos Spark.
jdbcDF = spark.read.format("jdbc")
.option("url", url)
.option("query", query2)
.option("user", user)
.option("password", password)
.option("driver", "com.microsoft.sqlserver.jdbc.SQLServerDriver")
.load()
jdbcDF.show(5)
Guardar marco de datos como archivo CSV
El marco de datos se puede almacenar en el servidor como archivo. Archivo CSV. Noe, este paso es opcional en caso de que desee escribir el marco de datos directamente en un bucket de S3, este paso se puede omitir. PySpark, por defecto, crea múltiples particiones, para evitarlo podemos guardarlo como un solo archivo usando la función coalesce (1). A continuación, movemos el archivo a la carpeta de salida designada. Opcionalmente, elimine el directorio de salida creado si solo desea guardar el marco de datos en el depósito de S3.
path="output"
jdbcDF.coalesce(1).write.option("header","true").option("sep",",").mode("overwrite").csv(path)
shutil.move(glob.glob(os.getcwd() + '/' + path + '/' + r'*.csv')[0], os.getcwd()+ '/' + filename )
shutil.rmtree(os.getcwd() + '/' + path)
Copiar el marco de datos en el depósito S3
Primero, cree una sesión ‘boto3’ utilizando el acceso de AWS y los valores de clave secreta. Recupere los valores del bucket y del subdirectorio de S3 donde desea cargar el archivo. los subir archivo() acepta un nombre de archivo, un nombre de depósito y un nombre de objeto. El método maneja archivos grandes dividiéndolos en porciones más pequeñas y cargando cada porción en paralelo.
session = boto3.Session(
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
)
bucket_name=BUCKET_NAME
s3_output_key=DIRECTORY + filename
s3 = session.resource('s3')
# Filename - File to upload
# Bucket - Bucket to upload to (the top level directory under AWS S3)
# Key - S3 object name (can contain subdirectories). If not specified then file_name is used
s3.meta.client.upload_file(Filename=filename, Bucket=bucket_name, Key=s3_output_key)
Archivos de limpieza
Después de cargar el archivo en el bucket de S3, elimine los archivos que queden en el servidor; de lo contrario, arroje un error.
if os.path.isfile(filename):
os.remove(filename)
else:
print("Error: %s file not found" % filename)
Conclusión
Apache Spark es un marco de computación en clúster de código abierto con capacidad de procesamiento en memoria. Fue desarrollado en el lenguaje de programación Scala. Spark ofrece muchas características y capacidades que lo convierten en un marco de Big Data eficiente. El rendimiento y la velocidad son las principales ventajas de Spark. Puede cargar los terabytes de datos y procesarlos sin problemas configurando un clúster de varios nodos. Este artículo da una idea de cómo escribir un ETL basado en Python.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





