Clasificación del árbol de decisión | Guía para la clasificación del árbol de decisiones
Contenidos
Visión general
¿Qué es el algoritmo del árbol de clasificación de decisiones?
Cómo construir un árbol de decisiones desde cero
Terminologías relacionadas con el árbol de decisiones
Diferencia entre bosque aleatorio y árbol de decisión
Implementación de código Python de árboles de decisión
Hay varios algoritmos en el aprendizaje automático para problemas de regresión y clasificación, pero optando por El mejor y más eficiente algoritmo para el conjunto de datos dado es el punto principal a realizar mientras se desarrolla un buen modelo de aprendizaje automático.
Uno de estos algoritmos buenos para problemas de clasificación / categóricos y de regresión es el árbol de decisión
Los árboles de decisión generalmente implementan exactamente la capacidad de pensamiento humano al tomar una decisión, por lo que es fácil de entender.
La lógica detrás del árbol de decisiones se puede entender fácilmente porque muestra una estructura de tipo de diagrama de flujo / estructura en forma de árbol que facilita la visualización y extracción de información del proceso en segundo plano.
Tabla de contenido
¿Qué es un árbol de decisiones?
Elementos de los árboles de decisión
Cómo tomar una decisión desde cero
¿Cómo funciona el algoritmo del árbol de decisión?
Conocimiento de EDA (análisis de datos exploratorios)
Árboles de decisión y bosques aleatorios
Ventajas de Decision Forest
Desventajas de Decision Forest
Implementación de código Python
1. ¿Qué es un árbol de decisiones?
Un árbol de decisiones es un algoritmo de aprendizaje automático supervisado. Se utiliza tanto en algoritmos de clasificación como de regresión.. El árbol de decisiones es como un árbol con nodos. Las ramas dependen de varios factores. Divide los datos en ramas como estas hasta que alcanza un valor de umbral. Un árbol de decisión consta de los nodos raíz, los nodos secundarios y los nodos hoja.
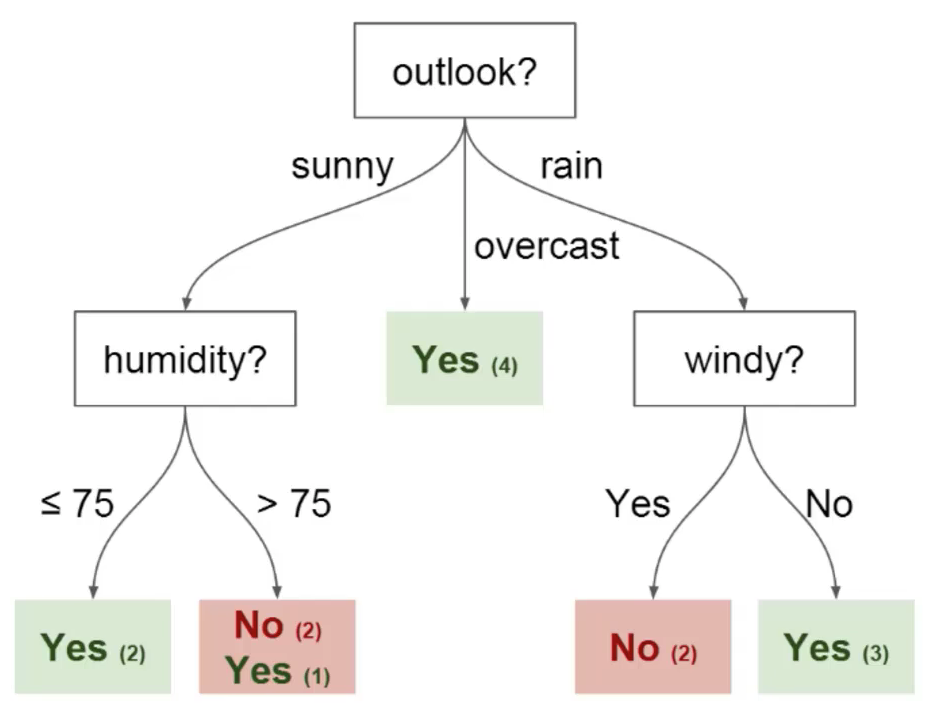
Comprendamos los métodos del árbol de decisiones tomando un escenario de la vida real
Imagina que juegas al fútbol todos los domingos y siempre invitas a tu amigo a jugar contigo. A veces, tu amigo viene y otras no.
El factor de venir o no depende de numerosas cosas, como el clima, la temperatura, el viento y la fatiga. Comenzamos a tomar en consideración todas estas características y comenzamos a rastrearlas junto con la decisión de su amigo de venir a jugar o no.
Puede utilizar estos datos para predecir si su amigo vendrá a jugar al fútbol o no. La técnica que podría utilizar es un árbol de decisiones. Así es como se vería el árbol de decisiones después de la implementación:
2. Elementos de un árbol de decisiones
Cada árbol de decisión consta de la siguiente lista de elementos:
un nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos....
b Bordes
c Raíz
d Hojas
a) Nodos: Es el punto donde el árbol se divide según el valor de algún atributo / característica del conjunto de datos.
b) Bordes: Dirige el resultado de una división al siguiente nodo que podemos ver en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior que hay nodos para características como perspectiva, humedad y viento. Hay una ventaja para cada valor potencial de cada uno de esos atributos / características.
c) Raíz: Este es el nodo donde tiene lugar la primera división.
d) Hojas: Estos son los nodos terminales que predicen el resultado del árbol de decisiones.
3. ¿Cómo construir árboles de decisiones desde cero?
Al crear un árbol de decisión, lo principal es seleccionar el mejor atributo de la lista de características totales del conjunto de datos para el nodo raíz y para los subnodos. La selección de los mejores atributos se logra con la ayuda de una técnica conocida como medida de selección de atributos (ASM).
Con la ayuda de ASM, podemos seleccionar fácilmente las mejores características para los respectivos nodos del árbol de decisiones.
Hay dos técnicas para la MAPE:
a) Ganancia de información
b) ÍndiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de Gini
a) Ganancia de información:
1La ganancia de información es la medición de los cambios en el valor de la entropía después de la división / segmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo.... del conjunto de datos en función de un atributo.
2 Indica cuánta información nos proporciona una característica / atributo.
3 Siguiendo el valor de la ganancia de información, se está realizando la división del nodo y la construcción del árbol de decisión.
El árbol de decisión 4 siempre intenta maximizar el valor de la ganancia de información, y un nodo / atributo que tiene el valor más alto de la ganancia de información se divide primero. La ganancia de información se puede calcular utilizando la siguiente fórmula:
Ganancia de información = Entropía (S) – [(Weighted Avg) *Entropy(each feature)
Entropy: Entropy signifies the randomness in the datasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos..... It is being defined as a metric to measure impurity. Entropy can be calculated as:
Entropy(s)= -P(yes)log2 P(yes)- P(no) log2 P(no)
Where"WHERE" es un término en inglés que se traduce como "dónde" en español. Se utiliza para hacer preguntas sobre la ubicación de personas, objetos o eventos. En contextos gramaticales, puede funcionar como adverbio de lugar y es fundamental en la formación de preguntas. Su correcta aplicación es esencial en la comunicación cotidiana y en la enseñanza de idiomas, facilitando la comprensión y el intercambio de información sobre posiciones y direcciones....,
S= Total number of samples
P(yes)= probability of yes
P(no)= probability of no.
b) Gini Index:
Gini index is also being defined as a measure of impurity/ purity used while creating a decision tree in the CART(known as Classification and Regression Tree) algorithm.
An attribute havingEl verbo "haber" en español es un auxiliar fundamental que se utiliza para formar tiempos compuestos. Su conjugación varía según el tiempo y el sujeto, siendo "he", "has", "ha", "hemos", "habéis" y "han" las formas del presente. Además, en algunas regiones, se usa "haber" como un verbo impersonal para indicar existencia, como en "hay" para "there is/are". Su correcta utilización es esencial para una comunicación efectiva en español.... a low Gini index value should be preferred in contrast to the high Gini index value.
It only creates binary splits, and the CART algorithm uses the Gini index to create binary splits.
Gini index can be calculated using the below formula:
Gini Index= 1- ∑jPj2
Where pj stands for the probability
4. How Does the Decision Tree Algorithm works?
The basic idea behind any decision tree algorithm is as follows:
1. SelectEl comando "SELECT" es fundamental en SQL, utilizado para consultar y recuperar datos de una base de datos. Permite especificar columnas y tablas, filtrando resultados mediante cláusulas como "WHERE" y ordenando con "ORDER BY". Su versatilidad lo convierte en una herramienta esencial para la manipulación y análisis de datos, facilitando la obtención de información específica de manera eficiente.... the best Feature using Attribute Selection Measures(ASM) to split the records.
2. Make that attribute/feature a decision node and break the dataset into smaller subsets.
3 Start the tree-building process by repeating this process recursively for each child until one of the following condition is being achieved :
a) All tuples belonging to the same attribute value.
b) There are no more of the attributes remaining.
c ) There are no more instances remaining.
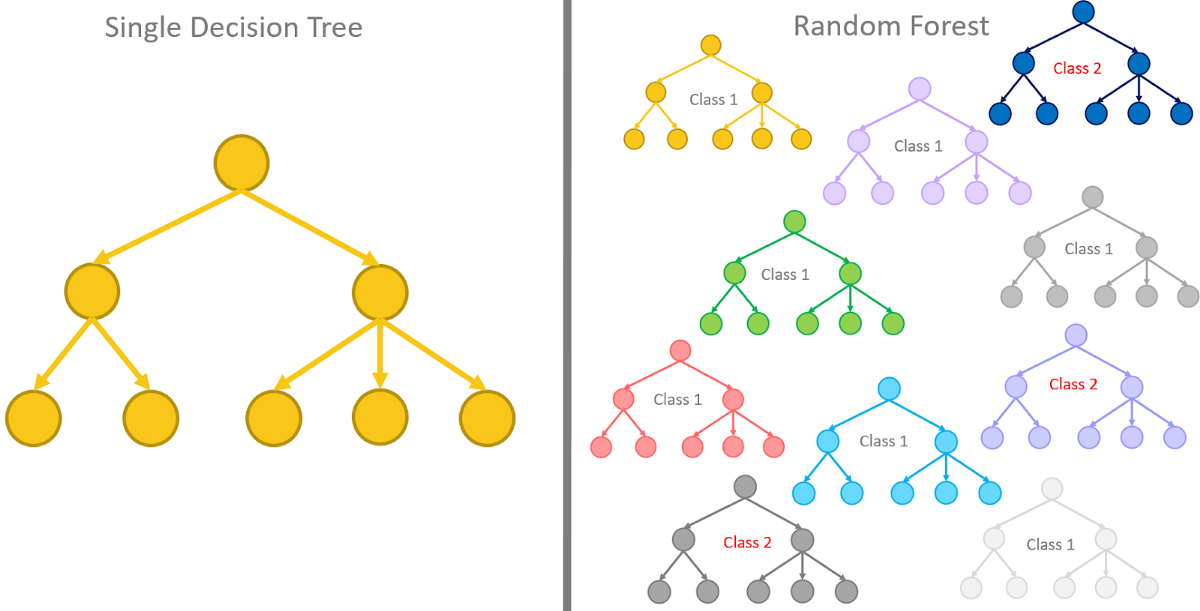
5. Decision Trees and Random Forests
Decision trees and Random forest are both the tree methods that are being used in Machine Learning.
Decision trees are the Machine Learning models used to make predictions by going through each and every feature in the data set, one-by-one.
Random forests on the other hand are a collection of decision trees being grouped together and trained together that use random orders of the features in the given data sets.
Instead of relying on just one decision tree, the random forest takes the prediction from each and every tree and based on the majority of the votes of predictions, and it gives the final output. In other words, the random forest can be defined as a collection of multiple decision trees.
6. Advantages of the Decision Tree
1 It is simple to implement and it follows a flow chart type structure that resembles human-like decision making.
2 It proves to be very useful for decision-related problems.
3 It helps to find all of the possible outcomes for a given problem.
4 There is very little need for data cleaning in decision trees compared to other Machine Learning algorithms.
5 Handles both numerical as well as categorical values
7. Disadvantages of the Decision Tree
1 Too many layers of decision tree make it extremely complex sometimes.
2 It may result in overfittingEl sobreajuste, o overfitting, es un fenómeno en el aprendizaje automático donde un modelo se ajusta demasiado a los datos de entrenamiento, capturando ruido y patrones irrelevantes. Esto resulta en un rendimiento deficiente en datos no vistos, ya que el modelo pierde capacidad de generalización. Para mitigar el sobreajuste, se pueden emplear técnicas como la regularización, la validación cruzada y la reducción de la complejidad del modelo.... ( which can be resolved using the Random Forest algorithm)
3 For the more number of the class labels, the computational complexity of the decision tree increases.
8. Python Code Implementation
#Numerical computing libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Divida el conjunto de datos en datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y datos de prueba
from sklearn.model_selection import train_test_split
x = raw_data.drop('Kyphosis', axis = 1)
y = raw_data['Kyphosis']
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, y, test_size = 0.3)
#Entrenar el modelo de árbol de decisiones
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(x_training_data, y_training_data)
predictions = model.predict(x_test_data)
# Medir el rendimiento del modelo de árbol de decisiones
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
print(classification_report(y_test_data, predictions))
print(confusion_matrix(y_test_data, predictions))
Con esto termino este blog. Hola a todos, Namaste Me llamo Pranshu Sharma y soy un entusiasta de la ciencia de datos
Muchas gracias por tomarse su valioso tiempo para leer este blog. No dude en señalar cualquier error (después de todo, soy un aprendiz) y proporcionar los comentarios correspondientes o dejar un comentario.