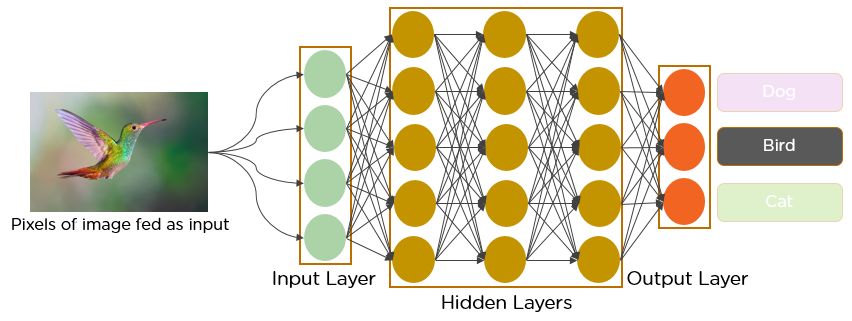
Introducción
En las últimas décadas, Deep Learning ha demostrado ser una herramienta muy poderosa debido a su capacidad para manejar grandes cantidades de datos. El interés por utilizar capas ocultas ha superado las técnicas tradicionales, especialmente en el reconocimiento de patrones. Una de las redes neuronales profundas más populares son las redes neuronales convolucionales.
Desde la década de 1950, los primeros días de la IA, los investigadores han luchado por crear un sistema que pueda comprender los datos visuales. En los años siguientes, este campo pasó a conocerse como Visión por Computadora. En 2012, la visión por computadora dio un salto cuántico cuando un grupo de investigadores de la Universidad de Toronto desarrolló un modelo de inteligencia artificial que superó los mejores algoritmos de reconocimiento de imágenes y eso también por un amplio margenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial....
El sistema de inteligencia artificial, que se conoció como AlexNet (que lleva el nombre de su creador principal, Alex Krizhevsky), ganó el concurso de visión por computadora ImageNet de 2012 con una asombrosa precisión del 85 por ciento. El subcampeón obtuvo un modesto 74 por ciento en la prueba.
En el corazón de AlexNet estaban las redes neuronales convolucionales, un tipo especial de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... que imita aproximadamente la visión humana. A lo largo de los años, las CNN se han convertido en una parte muy importante de muchas aplicaciones de visión por computadora y, por lo tanto, en una parte de cualquier curso de visión por computadora en línea. Así que echemos un vistazo al funcionamiento de las CNN.
Antecedentes de las CNN
Las CNN se desarrollaron y utilizaron por primera vez alrededor de la década de 1980. Lo máximo que podía hacer una CNN en ese momento era reconocer los dígitos escritos a mano. Se usaba principalmente en los sectores postales para leer códigos postales, códigos pin, etc. Lo importante a recordar sobre cualquier modelo de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... es que requiere una gran cantidad de datos para entrenar y también requiere una gran cantidad de recursos informáticos. Este fue un gran inconveniente para las CNN en ese período y, por lo tanto, las CNN solo se limitaron a los sectores postales y no pudieron ingresar al mundo del aprendizaje automático.
En 2012, Alex Krizhevsky se dio cuenta de que había llegado el momento de recuperar la rama del aprendizaje profundo que utiliza redes neuronales multicapa. La disponibilidad de grandes conjuntos de datos, para ser conjuntos de datos de ImageNet más específicos con millones de imágenes etiquetadas y una abundancia de recursos informáticos, permitió a los investigadores revivir las CNN.
¿Qué es exactamente una CNN?
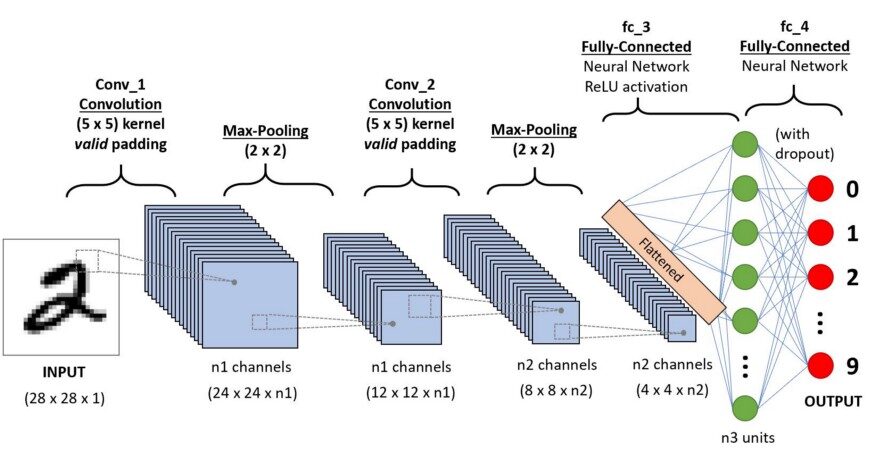
En aprendizaje profundo, a red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... (CNN / ConvNet) es una clase de redes neuronales profundas, más comúnmente aplicado para analizar imágenes visuales. Ahora, cuando pensamos en una red neuronal, pensamos en multiplicaciones de matrices, pero ese no es el caso de ConvNet. Utiliza una técnica especial llamada convolución. Ahora en matematicas circunvolución es una operación matemática sobre dos funciones que produce una tercera función que expresa cómo la forma de una es modificada por la otra.
Pero realmente no necesitamos ir más allá de la parte matemática para entender qué es una CNN o cómo funciona.
La conclusión es que el papel de ConvNet es reduzca las imágenes a una forma que sea más fácil de procesar, sin perder características que son críticas para obtener una buena predicción.
¿Como funciona?
Antes de pasar al funcionamiento de CNN, cubramos los conceptos básicos, como qué es una imagen y cómo se representa. Una imagen RGB no es más que una matriz de valores de píxeles que tiene tres planos, mientras que una imagen en escala de grises es la misma pero tiene un solo plano. Eche un vistazo a esta imagen para comprender más.
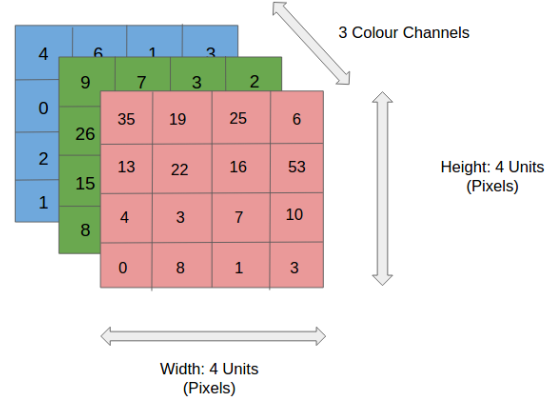
Para simplificar, sigamos con imágenes en escala de grises mientras tratamos de entender cómo funcionan las CNN.
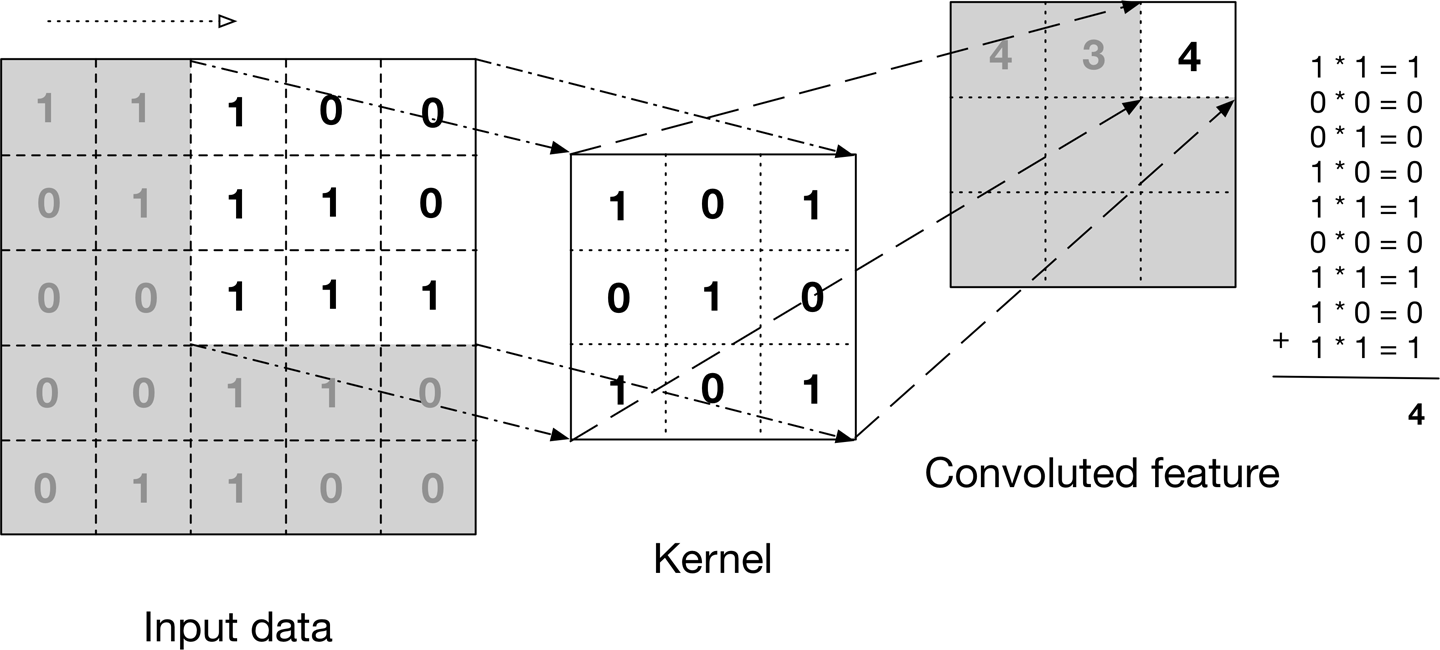
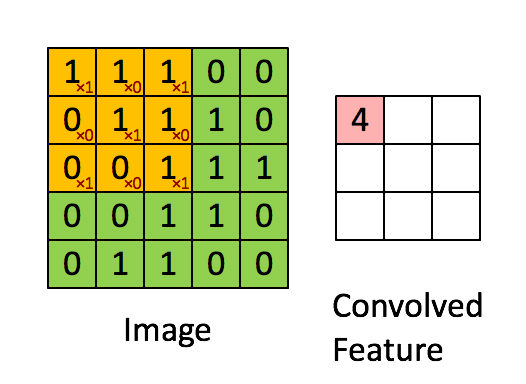
La imagen de arriba muestra lo que es una convolución. Tomamos un filtro / núcleo (matriz de 3 × 3) y lo aplicamos a la imagen de entrada para obtener la función convolucionada. Esta característica convolucionada se pasa a la siguiente capa.
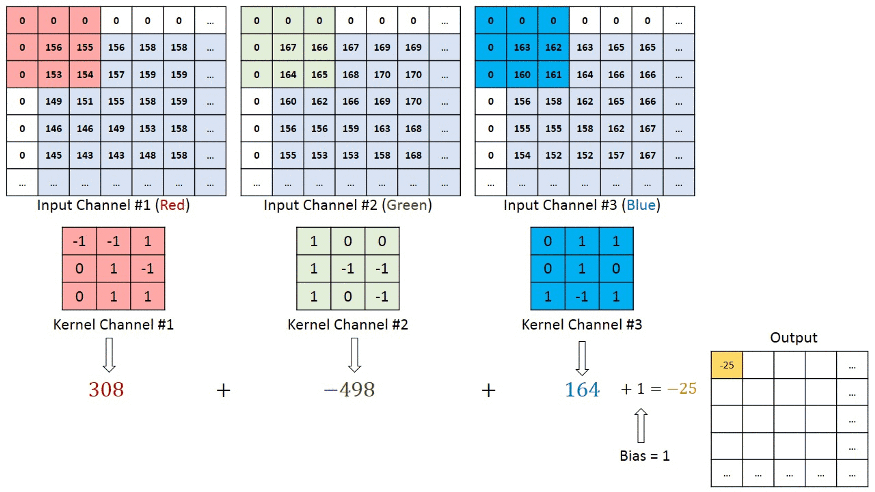
En el caso del color RGB, el canal eche un vistazo a esta animación para comprender su funcionamiento.
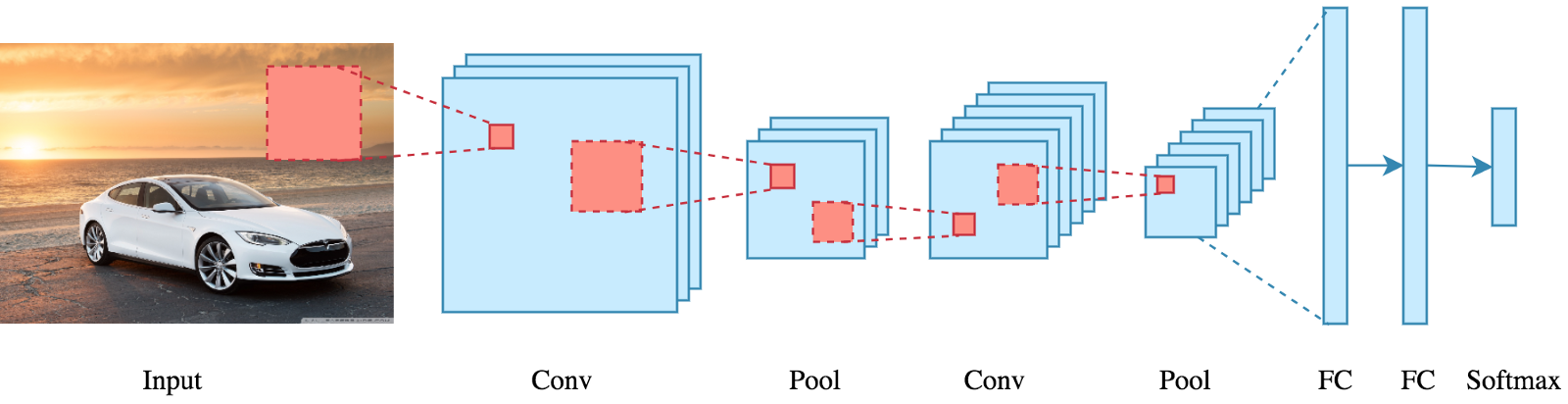
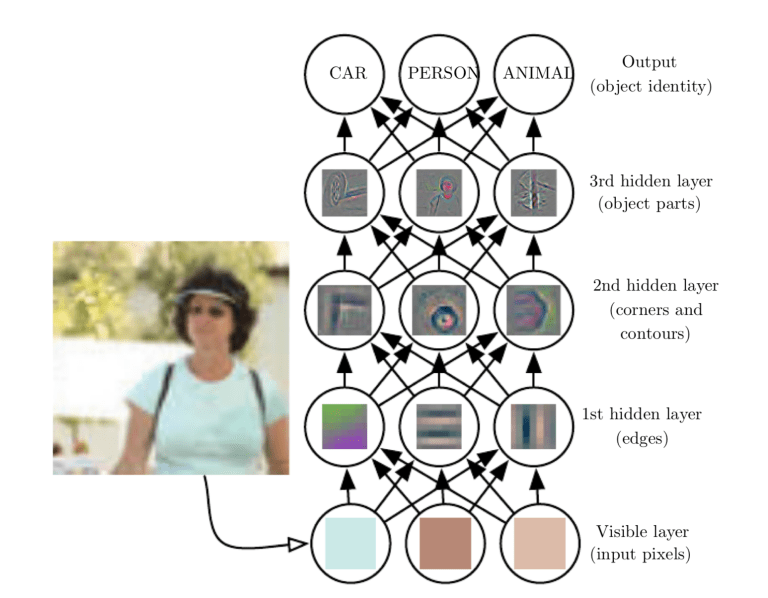
Las redes neuronales convolucionales están compuestas por múltiples capas de neuronas artificiales. Las neuronas artificiales, una imitación aproximada de sus contrapartes biológicas, son funciones matemáticas que calculan la suma ponderada de múltiples entradas y salidas de un valor de activación. Cuando ingresa una imagen en una ConvNet, cada capa genera varias funciones de activación que se pasan a la siguiente capa.
La primera capa generalmente extrae características básicas como bordes horizontales o diagonales. Esta salida se pasa a la siguiente capa, que detecta características más complejas, como esquinas o bordes combinacionales. A medida que nos adentramos en la red, podemos identificar características aún más complejas, como objetos, caras, etc.

Según el mapa de activación de la capa de convolución final, la capa de clasificación genera un conjunto de puntuaciones de confianza (valores entre 0 y 1) que especifican la probabilidad de que la imagen pertenezca a una «clase». Por ejemplo, si tiene una ConvNet que detecta gatos, perros y caballos, la salida de la capa final es la posibilidad de que la imagen de entrada contenga alguno de esos animales.
¿Qué es una capa de agrupación?
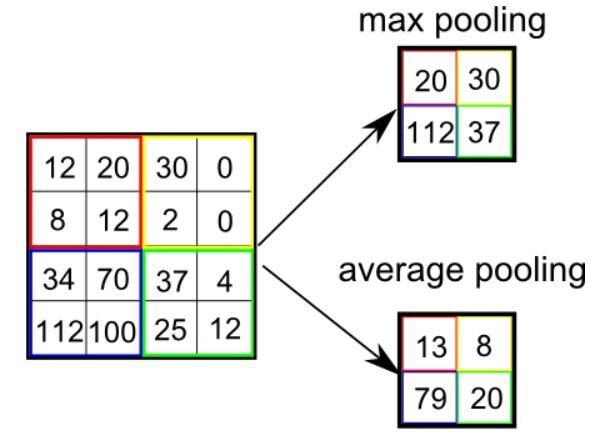
Similar a la capa convolucionalLa capa convolucional, fundamental en las redes neuronales convolucionales (CNN), se utiliza principalmente para el procesamiento de datos con estructuras en forma de cuadrícula, como imágenes. Esta capa aplica filtros que extraen características relevantes, como bordes y texturas, permitiendo que el modelo reconozca patrones complejos. Su capacidad para reducir la dimensionalidad de los datos y mantener información esencial la convierte en una herramienta clave en tareas de visión por computadora..., la capa de agrupación es responsable de reducir el tamaño espacial de la entidad convolucionada. Esto es para Disminuir la potencia computacional requerida para procesar los datos. reduciendo las dimensiones. Hay dos tipos de agrupación agrupación media y agrupación máxima. Solo he tenido experiencia con Max Pooling hasta ahora y no he enfrentado ninguna dificultad.
Entonces, lo que hacemos en Max Pooling es encontrar el valor máximo de un píxel de una parte de la imagen cubierta por el kernel. Max Pooling también funciona como Supresor de ruido. Descarta las activaciones ruidosas por completo y también realiza la eliminación de ruido junto con la reducción de dimensionalidad.
Por otra parte, Agrupación promedio devuelve el promedio de todos los valores de la parte de la imagen cubierta por el Kernel. La agrupación promedio simplemente realiza la reducción de la dimensionalidad como un mecanismo de supresión de ruido. Por tanto, podemos decir que La agrupación máxima funciona mucho mejor que la agrupación promedio.
Limitaciones
A pesar del poder y la complejidad de los recursos de las CNN, brindan resultados detallados. En la raíz de todo, se trata simplemente de reconocer patrones y detalles que son tan diminutos y discretos que pasan desapercibidos para el ojo humano. Pero cuando se trata de comprensión el contenido de una imagen falla.
Echemos un vistazo a este ejemplo. Cuando pasamos la imagen de abajo a una CNN, detecta a una persona de alrededor de 30 años y un niño probablemente alrededor de los 10 años. Pero cuando miramos la misma imagen, comenzamos a pensar en múltiples escenarios diferentes. Tal vez sea un día de padre e hijo, un picnic o tal vez estén acampando. Tal vez sea un terreno escolar y el niño marcó un gol y su papá está feliz así que lo levanta.

Estas limitaciones son más que evidentes cuando se trata de aplicaciones prácticas. Por ejemplo, las CNN se utilizaron ampliamente para moderar contenido en las redes sociales. Pero a pesar de los vastos recursos de imágenes y videos en los que fueron capacitados, todavía no puede bloquear y eliminar por completo el contenido inapropiado. Como resulta que marcó una estatua de 30.000 años con desnudez en Facebook.
Varios estudios han demostrado que las CNN capacitadas en ImageNet y otros conjuntos de datos populares no detectan objetos cuando los ven bajo diferentes condiciones de iluminación y desde nuevos ángulos.
¿Significa esto que las CNN son inútiles? Sin embargo, a pesar de los límites de las redes neuronales convolucionales, no se puede negar que han causado una revolución en la inteligencia artificial. Hoy en día, las CNN se utilizan en muchos aplicaciones de visión artificial como reconocimiento facial, búsqueda y edición de imágenes, realidad aumentada y más. Como muestran los avances en las redes neuronales convolucionales, nuestros logros son notables y útiles, pero todavía estamos muy lejos de replicar los componentes clave de la inteligencia humana.

¡Gracias por leer! Si disfrutó leyendo este artículo, por favor compartir para ayudar a otros a encontrarlo! No dudes en dejar un comentario 💬 a continuación. Puedes conectarte conmigo en GitHub, LinkedIn
¿Tiene comentarios? Seamos amigos en Gorjeo.
¡Todo lo mejor y feliz codificación! 😀
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





