Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué es el aprendizaje automático?
Aprendizaje automático: El aprendizaje automático (ML) es un proceso altamente iterativo y ML Los modelos se aprenden de experiencias pasadas y también para analizar los datos históricos. Además, los modelos ML pueden identificar los patrones para hacer predicciones sobre el futuro del conjunto de datos dado.

W¿Por qué es importante el aprendizaje automático?
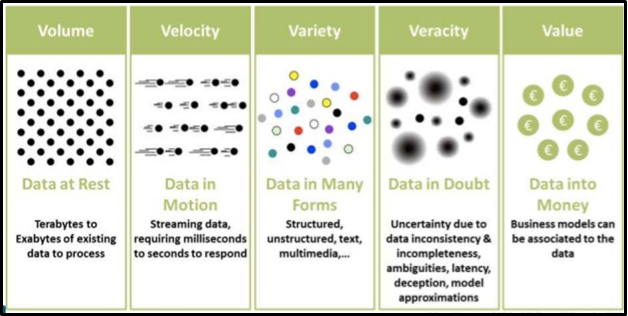
Dado que las 5V están dominando el mundo digital actual (volumen, variedad, visibilidad de variación y valor), la mayoría de las industrias están desarrollando varios modelos para analizar su presencia y oportunidades en el mercado, basándose en este resultado, están entregando los mejores productos. servicios a sus clientes a gran escala.
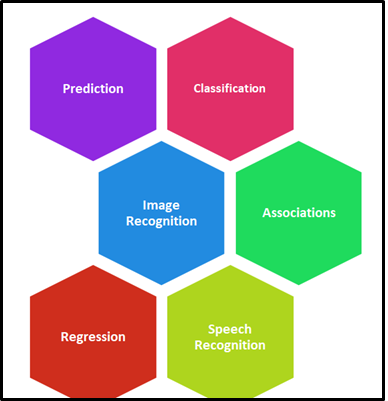
¿Cuáles son las principales aplicaciones de aprendizaje automático?
El aprendizaje automático (ML) es ampliamente aplicable en muchas industrias y la implementación y mejora de sus procesos. Actualmente, ML se ha utilizado en múltiples campos e industrias sin límites. La siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... representa el área donde ML juega un papel vital.
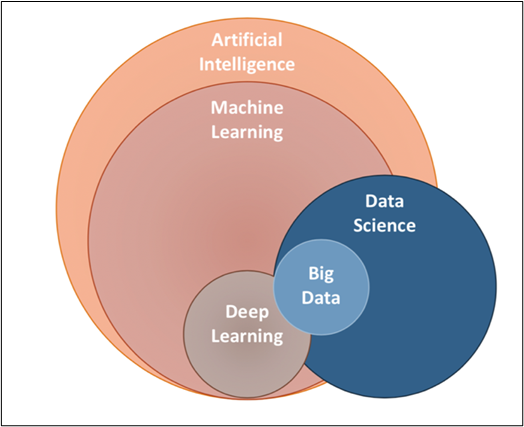
¿Dónde está el aprendizaje automático en el espacio de la IA?
Solo eche un vistazo al Diagrama de Venn, podríamos entender dónde está el ML en el espacio de la IA y cómo se relaciona con otros componentes de la IA.
Como sabemos los Jargons que vuelan a nuestro alrededor, veamos rápidamente de qué habla exactamente cada componente.
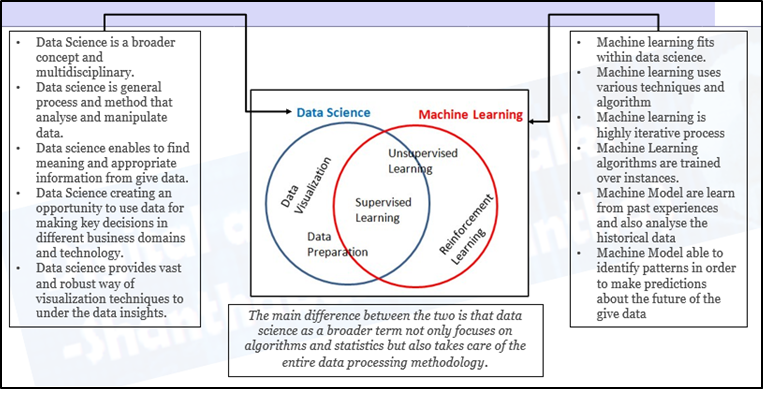
¿Cómo se relacionan la ciencia de datos y el aprendizaje automático?
Proceso de aprendizaje automático, es el primer paso en el proceso de ML para tomar los datos de múltiples fuentes y seguido de un proceso de datos afinado, estos datos serían la fuente para los algoritmos de ML basados en la declaración del problema, como los modelos predictivos, de clasificación y otros que están disponibles en el espacio del mundo ML. Discutamos cada proceso uno por uno aquí.
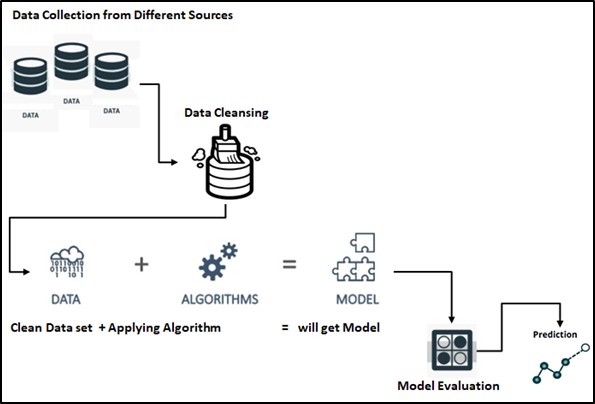
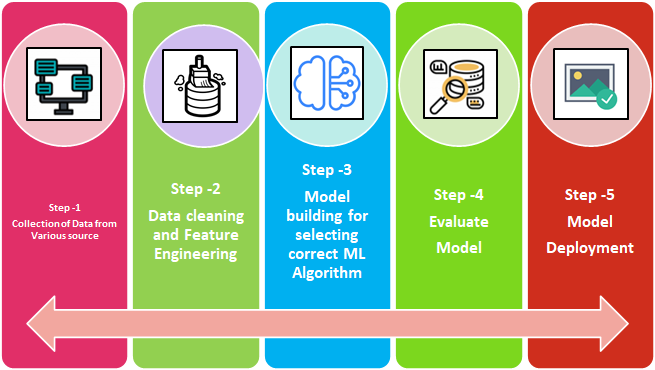
Aprendizaje automático – Etapas: Podemos dividir las etapas del proceso de AA en 5 como se menciona a continuación en el diagrama de flujo.
- Conjunto de datos
- Negociación de datos
- Construcción del modelo
- Evaluación del modelo
- Despliegue del modelo
Identificación de los problemas comerciales, antes de pasar a las etapas anteriores. Entonces, debemos tener claro el objetivo del propósito de la implementación del ML. Encontrar la solución al problema dado / identificado. debemos recopilar los datos y realizar un seguimiento adecuado de las etapas siguientes.
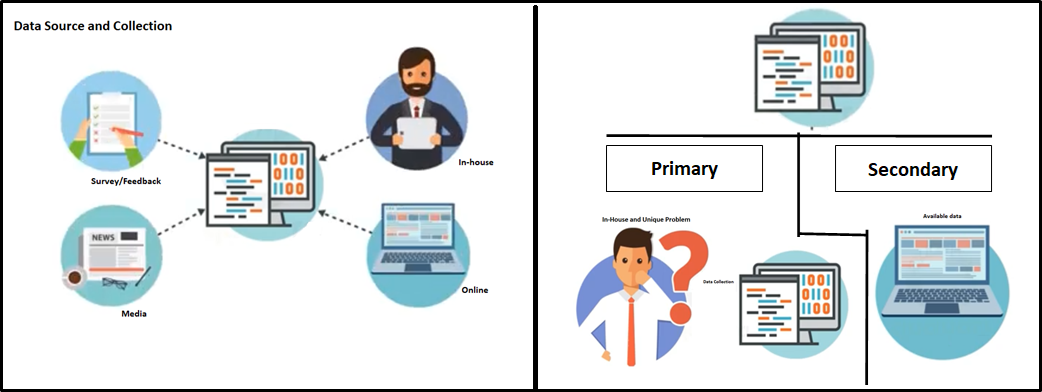
Conjunto de datos
La recopilación de datos de diferentes fuentes puede ser interna y / o externa para satisfacer los requisitos / problemas comerciales. Los datos pueden estar en cualquier formato. CSV, XML.JSON, etc., aquí Big Data juega un papel vital para asegurarse de que los datos correctos estén en el formato y estructura esperados.
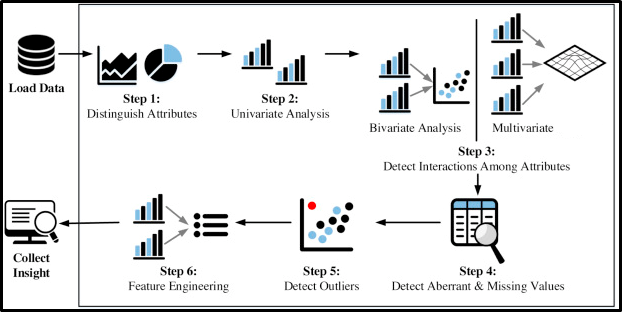
Negociación de datos y procesamiento de datos: El objetivo principal de esta etapa y enfoque son los siguientes.
Procesamiento de datos (EDA):
- Comprender el conjunto de datos dado y ayudar a limpiar el conjunto de datos dado.
- Le brinda una mejor comprensión de las características y las relaciones entre ellas
- Extraer variables esenciales y dejar atrás / eliminar variables no esenciales.
- Manejo de valores perdidos o error humano.
- Identificación de valores atípicos.
- El proceso de EDA maximizaría los conocimientos de un conjunto de datos.
Ingeniería de funciones:
- Manejo de valores perdidos en las variables
- Convierta categórico en numérico ya que la mayoría de los algoritmos necesitan características numéricas.
- Necesita corregir no gaussiano (normal). Los modelos lineales asumen que las variables tienen distribución gaussiana.
- Encontrar valores atípicos están presentes en los datos, por lo que truncamos los datos por encima de un umbral o transformamos los datos mediante la transformación de registros.
- Escale las características. Esto es necesario para dar la misma importancia a todas las características y no más a aquella cuyo valor es mayor.
- La ingeniería de características es un proceso costoso y que requiere mucho tiempo.
- La ingeniería de características puede ser un proceso manual, se puede automatizar
EntrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y pruebas:
- Los datos de entrenamiento se utilizan para asegurarse de que la máquina reconozca los patrones de los datos, se utiliza la validación cruzada de los datos para garantizar una mejor precisión y
la eficiencia del algoritmo que se utiliza para entrenar la máquina. - Los datos de prueba se utilizan para ver qué tan bien la máquina puede predecir nuevas respuestas en función de su entrenamiento.
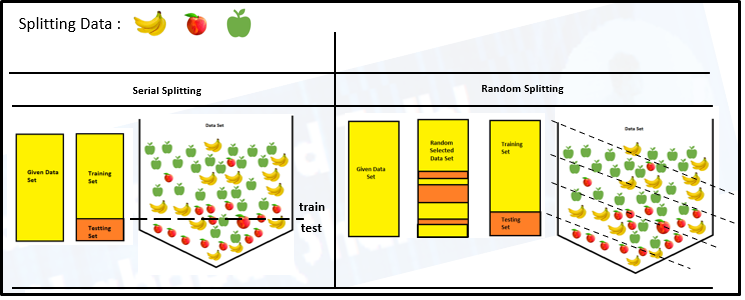
- El procedimiento de división de prueba de tren se utiliza para estimar el rendimiento de ML de los algoritmos cuando se utilizan para hacer predicciones sobre datos que no son
utilizado para entrenar el modelo.
Capacitación
- Los datos de entrenamiento son el conjunto de datos en el que entrena el modelo.
- Entrene datos de los que el modelo ha aprendido las experiencias.
- Los conjuntos de entrenamiento se utilizan para ajustar y ajustar sus modelos.
Pruebas
- Los datos de prueba son los datos que se utilizan para verificar si el modelo tiene
aprendió lo suficientemente bien de las experiencias que obtuvo en el conjunto de datos de trenes. - Conjuntos de prueba
son datos «invisibles» para evaluar sus modelos.
Datos del tren: Entrena nuestro algoritmo de aprendizaje automático
Datos de prueba: Después de entrenar el modelo, los datos de prueba se utilizan para probar su eficiencia y rendimiento del modelo.
El propósito del estado aleatorio en la división de prueba de tren: estado aleatorio asegura que el divisiones que generas son reproducibles. los estado aleatorio que proporcionas se utiliza como semilla para el aleatorio generador de números. Esto asegura que el aleatorio los números se generan en el mismo orden.
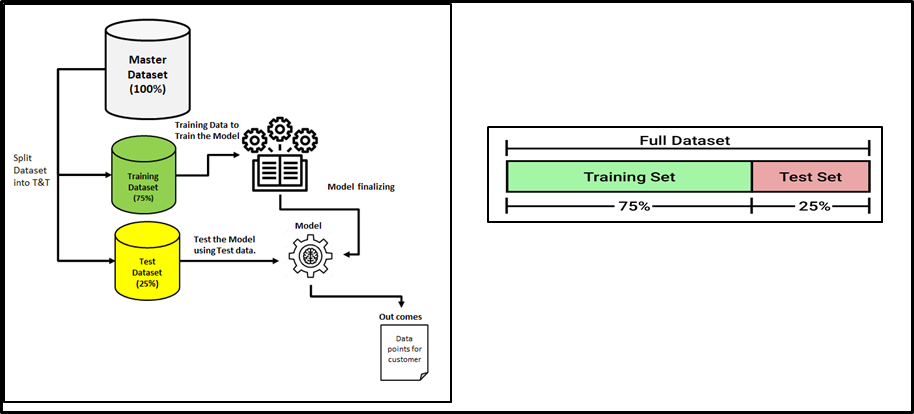
Datos divididos en conjunto de entrenamiento / prueba
- Solíamos dividir un conjunto de datos en datos de entrenamiento y datos de prueba en el espacio de aprendizaje automático.
- El rango dividido suele ser del 20% al 80% entre las etapas de prueba y entrenamiento del conjunto de datos dado.
- Se gastaría una gran cantidad de datos para entrenar su modelo
- El resto de la cantidad se puede gastar para evaluar su modelo de prueba.
- Pero no puede mezclar / reutilizar los mismos datos para fines de entrenamiento y prueba
- Si evalúa su modelo con los mismos datos que utilizó para entrenarlo, su modelo podría estar muy sobreajustado. Luego se plantea la cuestión de si los modelos pueden predecir nuevos datos.
- Por lo tanto, debe tener subconjuntos de prueba y entrenamiento separados de su conjunto de datos.
EVALUACIÓN DEL MODELO: Cada modelo tiene su propia mitología de evaluación de modelos, algunas de las mejores evaluaciones están aquí.
- Evaluar la regresión Modelo.
- Suma del error al cuadrado (SSE)
- Error cuadrático medio (MSE)
- Error cuadrático medio (RMSE)
- Error absoluto medio (MAE)
- Coeficiente de determinación (R2)
- R2 ajustado
- Evaluar Clasificación Modelo.
- Matriz de confusión.
- Puntuación de precisión.
- AUC y ROC.
Despliegue de un ML-modelo simplemente significa la integración del modelo finalizado en un entorno de producción y la obtención de resultados para tomar decisiones comerciales.
Por lo tanto, espero que pueda comprender el flujo del proceso de punta a punta del aprendizaje automático y creo que sería útil para usted. Gracias por su tiempo.





