Introducción
¡La inteligencia artificial y el aprendizaje automático serán nuestro mayor ayudante en la próxima década!
Hoy por la mañana, estaba leyendo un artículo que informaba que un sistema de inteligencia artificial ganó contra 20 abogados y los abogados estaban realmente felices de que la inteligencia artificial pueda ocuparse de una parte repetitiva de sus roles y ayudarlos a trabajar en temas complejos. Estos abogados se alegraron de que la inteligencia artificial les permita desempeñar funciones más satisfactorias.
Hoy, compartiré un ejemplo similar: cómo contar el número de personas en una multitud usando Aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y visión artificial? Pero, antes de hacer eso, desarrollemos un sentido de lo fácil que es la vida para un científico de conteo de multitudes.
Actúe como un científico de conteo de multitudes
¡Empecemos!
¿Me pueden ayudar a contar / estimar el número de personas en esta imagen que asistirán a este evento?

Ok, ¿qué tal este?

Fuente: Conjunto de datos de ShanghaiTech
Le coges el truco. Al final de este tutorial, crearemos un algoritmo para el conteo de multitudes con una precisión asombrosa (en comparación con humanos como tú y yo). ¿Usarás tal asistente?
PD Este artículo asume que tienes un conocimiento básico de cómo funcionan las redes neuronales convolucionales (CNN). Puede consultar la publicación a continuación para obtener más información sobre este tema antes de continuar:
Tabla de contenido
- ¿Qué es el conteo de multitudes?
- ¿Por qué se requiere el conteo de multitudes?
- Comprensión de las diferentes técnicas de visión por computadora para el conteo de multitudes
- La arquitectura y los métodos de formación de CSRNet
- Construyendo su propio modelo de conteo de multitudes en Python
Este artículo está muy inspirado en el artículo: CSRNet: Redes neuronales convolucionales dilatadas para comprender las escenas muy congestionadas.
¿Qué es el conteo de multitudes?
El conteo de multitudes es una técnica para contar o estimar la cantidad de personas en una imagen. Tómese un momento para analizar la siguiente imagen:
Fuente: Conjunto de datos de ShanghaiTech
¿Puede darme un número aproximado de cuántas personas hay en el cuadro? Sí, incluidos los que están presentes en segundo plano. El método más directo es contar manualmente a cada persona, pero ¿tiene eso sentido práctico? ¡Es casi imposible cuando la multitud es tan grande!
Los científicos de multitudes (sí, ¡ese es un título de trabajo real!) Cuentan la cantidad de personas en ciertas partes de una imagen y luego extrapolan para llegar a una estimación. Más comúnmente, hemos tenido que confiar en métricas crudas para estimar este número durante décadas.
Seguramente debe haber un enfoque mejor y más exacto.
¡Sí hay!
Si bien todavía no tenemos algoritmos que nos puedan dar el número EXACTO, la mayoría visión por computador Las técnicas pueden producir estimaciones impresionantemente precisas. Primero entendamos por qué el conteo de multitudes es importante antes de sumergirnos en el algoritmo detrás de él.
¿Por qué es útil el conteo de multitudes?
Comprendamos la utilidad del conteo de multitudes con un ejemplo. Imagínese esto: su empresa acaba de terminar de organizar una gran conferencia sobre ciencia de datos. Durante el evento se llevaron a cabo muchas sesiones diferentes.
Se le pide que analice y estime el número de personas que asistieron a cada sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el.... Esto ayudará a su equipo a comprender qué tipo de sesiones atrajeron a las multitudes más grandes (y cuáles fallaron en ese sentido). Esto dará forma a la conferencia del próximo año, ¡así que es una tarea importante!

Hubo cientos de personas en el evento, ¡contarlas manualmente llevará días! Ahí es donde entran en juego sus habilidades como científico de datos. ¡Se las arregló para obtener fotos de la multitud en cada sesión y crear un modelo de visión por computadora para hacer el resto!
Hay muchos otros escenarios en los que los algoritmos de conteo de multitudes están cambiando la forma en que funcionan las industrias:
- Contando el número de personas que asisten a un evento deportivo
- Estimar cuántas personas asistieron a una inauguración o una marcha (manifestaciones políticas, tal vez)
- Monitoreo de áreas de alto tráfico
- Ayudar con la asignación de personal y la asignación de recursos.
¿Puedes pensar en otros casos de uso? ¡Házmelo saber en la sección de comentarios a continuación! Podemos conectarnos y tratar de descubrir cómo podemos usar técnicas de conteo de multitudes en su escenario.
Comprensión de las diferentes técnicas de visión por computadora para el conteo de multitudes
En términos generales, actualmente hay cuatro métodos que podemos usar para contar el número de personas en una multitud:
1. Métodos basados en detección
Aquí, usamos un detector similar a una ventana en movimiento para identificar a las personas en una imagen y contar cuántas hay. Los métodos utilizados para la detección requieren clasificadores bien entrenados que puedan extraer características de bajo nivel. Aunque estos métodos funcionan bien para detectar rostros, no funcionan bien en imágenes llenas de gente, ya que la mayoría de los objetos de destino no son claramente visibles.
2. Métodos basados en regresiones
No pudimos extraer características de bajo nivel con el enfoque anterior. Los métodos basados en la regresión triunfan aquí. Primero recortamos los parches de la imagen y luego, para cada parche, extraemos las características de bajo nivel.
3. Métodos basados en la estimación de la densidad
Primero creamos un mapa de densidad para los objetos. Luego, el algoritmo aprende un mapeo lineal entre las características extraídas y sus mapas de densidad de objetos. También podemos usar la regresión de bosque aleatoria para aprender el mapeo no lineal.
4. Métodos basados en CNN
Ah, buenas y confiables redes neuronales convolucionales (CNN). En lugar de mirar los parches de una imagen, creamos un método de regresión de un extremo a otro utilizando CNN. Esto toma la imagen completa como entrada y genera directamente el recuento de personas. Las CNN funcionan muy bien con tareas de regresión o clasificación, y también han demostrado su valía en la generación de mapas de densidad.
CSRNet, una técnica que implementaremos en este artículo, implementa una CNN más profunda para capturar características de alto nivel y generar mapas de densidad de alta calidad sin expandir la complejidad de la red. Entendamos qué es CSRNet antes de pasar a la sección de codificación.
Comprensión de la arquitectura y el método de formación de CSRNet
CSRNet utiliza VGG-16 como interfaz debido a su gran capacidad de aprendizaje por transferencia. El tamaño de salida de VGG es una quinta parte del tamaño de entrada original. CSRNet también utiliza capas convolucionales dilatadas en la parte posterior.
Pero, ¿qué demonios son las circunvoluciones dilatadas? Es una pregunta justa. Considere la siguiente imagen:
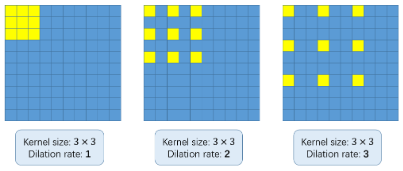
El concepto básico de usar convoluciones dilatadas es agrandar el kernel sin aumentar los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto..... Entonces, si la tasa de dilatación es 1, tomamos el kernel y lo convertimos en toda la imagen. Mientras que, si aumentamos la tasa de dilatación a 2, el núcleo se extiende como se muestra en la imagen de arriba (siga las etiquetas debajo de cada imagen). Puede ser una alternativa a la agrupación de capas.
Matemáticas subyacentes (recomendado, pero opcional)
Me voy a tomar un momento para explicar cómo funcionan las matemáticas. Tenga en cuenta que esto no es obligatorio para implementar el algoritmo en Python, pero le recomiendo que aprenda la idea subyacente. Esto será útil cuando necesite ajustar o modificar su modelo.
Suponga que tenemos una entrada x (m, n), un filtro w (i, j) y la tasa de dilatación r. La salida y (m, n) será:
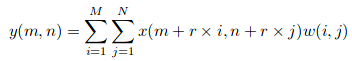
Podemos generalizar esta ecuación usando un núcleo (k * k) con una tasa de dilatación r. El núcleo se agranda a:
([k + (k-1)*(r-1)] * [k + (k-1)*(r-1)])
Entonces se ha generado la verdad básica para cada imagen. La cabeza de cada persona en una imagen dada se difumina usando un kernel gaussiano. Todas las imágenes se recortan en 9 parches y el tamaño de cada parche es una cuarta parte del tamaño original de la imagen. ¿Conmigo hasta ahora?
Los primeros 4 parches se dividen en 4 cuartos y los otros 5 parches se recortan al azar. Finalmente, se toma el espejo de cada parche para duplicar el conjunto de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.....
Eso, en pocas palabras, son los detalles de la arquitectura detrás de CSRNet. A continuación, veremos sus detalles de entrenamiento, incluida la métrica de evaluación utilizada.
El descenso de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... estocástico se utiliza para entrenar CSRNet como una estructura de extremo a extremo. Durante el entrenamiento, la tasa de aprendizaje fija se establece en 1e-6. La función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... se toma como la distancia euclidiana para medir la diferencia entre la verdad del terreno y el mapa de densidad estimado. Esto se representa como:
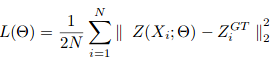
donde N es el tamaño del lote de entrenamiento. La métrica de evaluación utilizada en CSRNet es MAE y MSE, es decir, error absoluto medio y error cuadrático medio. Estos vienen dados por:
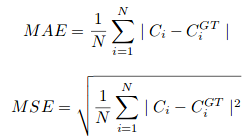
Aquí, Ci es el recuento estimado:
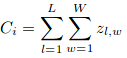
L y W son el ancho del mapa de densidad predicho.
Nuestro modelo primero predecirá el mapa de densidad para una imagen dada. El valor de píxel será 0 si no hay ninguna persona presente. Se asignará un cierto valor predefinido si ese píxel corresponde a una persona. Entonces, calcular los valores totales de píxeles correspondientes a una persona nos dará el recuento de personas en esa imagen. Impresionante, ¿verdad?
Y ahora, damas y caballeros, ¡es hora de finalmente construir nuestro propio modelo de conteo de multitudes!
Construyendo su propio modelo de conteo de multitudes
¿Listo con su portátil encendido?
Implementaremos CSRNet en el conjunto de datos de ShanghaiTech. Esto contiene 1198 imágenes anotadas de un total combinado de 330,165 personas. Puede descargar el conjunto de datos desde aquí.
Utilice el siguiente bloque de código para clonar el repositorio CSRNet-pytorch. Contiene todo el código para crear el conjunto de datos, entrenar el modelo y validar los resultados:
git clone https://github.com/leeyeehoo/CSRNet-pytorch.git
Por favor instalar CUDA y PyTorch antes de continuar. Estos son la columna vertebral detrás del código que usaremos a continuación.
Ahora, mueva el conjunto de datos al repositorio que clonó anteriormente y descomprímalo. Luego, necesitaremos crear los valores de verdad básicos. los make_dataset.ipynb archivo es nuestro salvador. Solo necesitamos hacer cambios menores en ese cuaderno:
#setting the root to the Shanghai datasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.... you have downloaded
# change the root path as per your location of dataset
root="/home/pulkit/CSRNet-pytorch/"
Ahora, generemos los valores reales básicos para las imágenes en part_A y part_B:
Generar el mapa de densidad para cada imagen es un paso de tiempo. Así que prepara una taza de café mientras se ejecuta el código.
Hasta ahora, hemos generado los valores de verdad básicos para las imágenes en part_A. Haremos lo mismo con las imágenes part_B. Pero antes de eso, veamos una imagen de muestra y tracemos su mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas.... de verdad del suelo:
plt.imshow(Image.open(img_paths[0]))
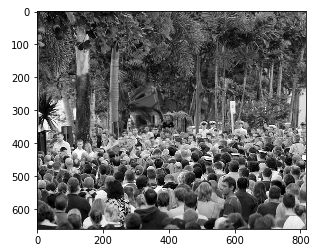
¡Las cosas se están poniendo interesantes!
gt_file = h5py.File(img_paths[0].replace('.jpg','.h5').replace('images','ground-truth'),'r')
groundtruth = np.asarray(gt_file['density'])
plt.imshow(groundtruth,cmap=CM.jet)
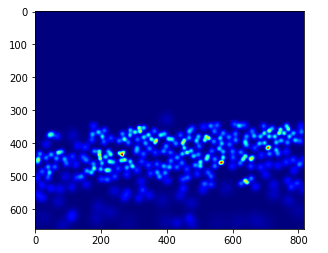
Cuentemos cuántas personas están presentes en esta imagen:
np.sum(groundtruth)
270.32568
Del mismo modo, generaremos valores para part_B:
Ahora, tenemos las imágenes, así como sus correspondientes valores de verdad fundamental. ¡Es hora de entrenar a nuestro modelo!
Usaremos los archivos .json disponibles en el directorio clonado. Solo tenemos que cambiar la ubicación de las imágenes en los archivos jsonJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software.... Para hacer esto, abra el archivo .json y reemplace la ubicación actual con la ubicación donde se encuentran sus imágenes.
Tenga en cuenta que todo este código está escrito en Python 2. Realice los siguientes cambios si está utilizando cualquier otra versión de Python:
- En model.py, cambie xrange en la línea 18 a range
- Cambie la línea 19 en model.py con: list (self.frontend.state_dict (). Items ())[i][1].datos[:] = lista (mod.state_dict (). items ())[i][1].datos[:]
- En image.py, reemplace ground_truth con ground-truth
¿Hizo los cambios? Ahora, abra una nueva ventana de terminal y escriba los siguientes comandos:
cd CSRNet-pytorch python train.py part_A_train.json part_A_val.json 0 0
Nuevamente, siéntese porque esto llevará algo de tiempo. Puede reducir el número de épocas en el train.py archivo para acelerar el proceso. Una buena opción alternativa es descargar los pesos pre-entrenados. de aquí si no tienes ganas de esperar.
Finalmente, verifiquemos el desempeño de nuestro modelo en datos invisibles. Usaremos el val.ipynb archivo para validar los resultados. Recuerde cambiar la ruta a los pesos e imágenes previamente entrenados.
#defining the image path img_paths = [] for path in path_sets: for img_path in glob.glob(os.path.join(path, '*.jpg')): img_paths.append(img_path)
model = CSRNet()
#defining the model model = model.cuda()
#loading the trained weights
checkpoint = torch.load('part_A/0model_best.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
Compruebe el MAE (error absoluto medio) en las imágenes de prueba para evaluar nuestro modelo:
Tenemos un valor MAE de 75,69, que es bastante bueno. Ahora revisemos las predicciones en una sola imagen:
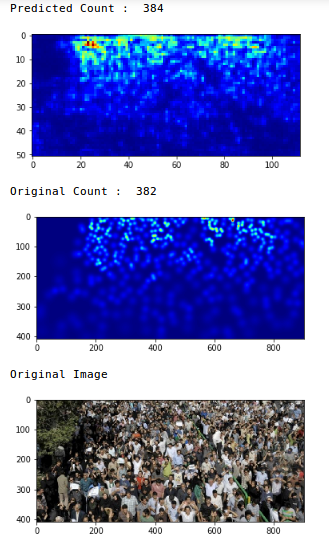 Vaya, el recuento original era 382 y nuestro modelo estimó que había 384 personas en la imagen. ¡Esa es una actuación muy impresionante!
Vaya, el recuento original era 382 y nuestro modelo estimó que había 384 personas en la imagen. ¡Esa es una actuación muy impresionante!
¡Felicitaciones por construir su propio modelo de conteo de multitudes!
Notas finales
Te animo a que pruebes este enfoque en diferentes imágenes y compartas tus resultados en la sección de comentarios a continuación. El conteo de multitudes tiene muchas aplicaciones diversas y ya está siendo adoptado por organizaciones y organismos gubernamentales.
Es una habilidad útil para agregar a su cartera. Un gran número de industrias buscarán científicos de datos que puedan trabajar con algoritmos de conteo de multitudes. ¡Aprende, experimenta con él y date el regalo del aprendizaje profundo!
¿Le resultó útil este artículo? No dude en dejarme sus sugerencias y comentarios a continuación, y estaré feliz de comunicarme con usted.
También debe consultar los recursos a continuación para aprender y explorar el maravilloso mundo de la visión por computadora:





