Este post fue difundido como parte del Blogatón de ciencia de datos.
¿Te parecen interesantes la IA y el ML?
¿Está interesado en convertirse en ingeniero de aprendizaje automático? ¿Ha aprendido lenguajes de programación como Python o R, pero tiene dificultades para avanzar? (Esto sucede principalmente en el caso de los autodidactas). ¿Encuentra intimidantes palabras como Estadística, Probabilidad y Regresión? Es absolutamente comprensible sentirse así, especialmente si viene de un entorno no técnico. Pero hay una solución para esto. Y es …. para comenzar. Recuerde, si nunca comienza, nunca cometerá errores y es factible que nunca aprenda. Por lo tanto empieza con algo pequeño.
Regresión lineal simple
¿Cuándo usamos LR?
Vamos a crear un modelo de aprendizaje automático simple usando regresión lineal. Pero antes de pasar a la parte de codificación, veamos los conceptos básicos y la lógica detrás de esto. La regresión se utiliza en el algoritmo de aprendizaje automático supervisado, que es el algoritmo más usado en este momento. El análisis de regresión es un método en el que establecemos una vinculación entre una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente (y) y una variable independiente (x); lo que nos posibilita predecir y pronosticar los resultados. ¿Recuerdas haber resuelto ecuaciones como y = mx + c de tus días escolares? En caso de ser así, felicitaciones. Ya conoce la regresión lineal simple. Si no es así, no es difícil aprender en absoluto.
Consideremos un ejemplo popular. El número de horas invertidas en el estudio y las notas obtenidas en el examen. En esta circunstancia, las calificaciones obtenidas dependen del número de horas que el estudiante invierta en estudiar, por eso, las calificaciones obtenidas son la variable dependiente y y el número de horas es la variable independiente x. El objetivo es desarrollar un modelo que nos ayude a predecir las notas obtenidas para un nuevo número de horas determinado. Lo vamos a lograr usando Regresión lineal.
Para tener muy claro este concepto, consideremos otro ejemplo. En un conjunto de datos con la cantidad de calorías consumidas y el peso ganado, el peso ganado depende de las calorías consumidas por una persona. Por eso, el peso ganado es la variable dependiente y y el número de calorías es la variable independiente x.
y = mx + c es la ecuación de la línea de regresión que mejor se ajusta a los datos y, a veces, además se representa como y = b0 + b1X. Aquí,
y es la variable dependiente, en esta circunstancia, las notas obtenidas.
x es la variable independiente, en esta circunstancia, el número de horas.
mo b1 es la pendiente de la recta de regresión y el coeficiente de la variable independiente.
c o b0 es la intersección de la línea de regresión.
La lógica es calcular la pendiente (m) e interceptar (c) con los datos disponibles y después lograremos calcular el valor de y para cualquier valor de x.
Se requieren paquetes y códigos de Python
Ahora, ¿cómo realizar la regresión lineal en Python? Necesitamos importar algunos paquetes, a saber NumPy para trabajar con matrices, Sklearn para realizar regresión lineal, y Matplotlib para trazar la línea de regresión y los gráficos. Tenga en cuenta que es casi imposible tener conocimiento de cada paquete y biblioteca en Python, especialmente para principiantes. Por eso, se recomienda seguir buscando el paquete adecuado cuando sea necesario para una tarea. Es más fácil recordar el uso de paquetes con experiencia práctica involucrada, en lugar de simplemente leer teóricamente la documentación disponible en ellos.
Pasando a la parte de codificación. El primer paso es importar los paquetes requeridos.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
Teniendo en cuenta que este es su primer modelo de aprendizaje automático, eliminaremos algunas complicaciones tomando una muestra muy pequeña, en lugar de utilizar datos de una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... grande. Esto además ayudará a ver claramente el resultado en los gráficos y a apreciar el concepto de manera efectiva.
xpuntos = np.array ([10, 11, 12, 13, 14, 15]) .reforma (-1,1)
ypoints = np.array ([53, 52, 60, 63, 72, 70])
Note que estamos remodelando el xpuntos tener una columna y muchas filas. El predictor (x) debe ser una matriz de matrices y la solución (y) puede ser una matriz simple.
Una variable Linreg se crea como una instancia de Regresión lineal. Puede tomar parámetros que son opcionales. No son necesarios para este ejemplo, por lo que los ignoraremos. Como sugiere el nombre, el .encajar() El método se ajusta al modelo y se utiliza para estimar algunos de los parámetros del modelo, lo que significa que calcula el valor optimizado de myc usando los datos dados.
linreg = LinearRegression()
linreg.fit(xpoints, ypoints)
.predecir() El método se utiliza para obtener la solución predicha usando el modelo y toma el predictor xpuntos como argumento.
y_pred = linreg.predict(xpoints)
Ahora, imprime y_pred y observe que los valores están bastante cerca de puntos. Si las respuestas pronosticadas y reales disponen un valor cercano, significa que el modelo es preciso. En un caso ideal, los valores de respuesta predichos y reales se superpondrían.
El módulo pyplot de la biblioteca Matplotlib se ha importado como plt. Entonces podemos trazar fácilmente los gráficos usando .dispersión() el cual toma xpuntos y puntos como argumentos. Traza la solución real. La solución prevista se traza usando.trama() función. El gráfico se puede etiquetar usando.xlabel y .ylabel.
plt.scatter (puntos x, puntos y)
plt.plot (puntos x, y_pred)
plt.xlabel («puntos x»)
plt.ylabel («puntos y»)
plt.show ()
plt.show () muestra todos los objetos de figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... en este momento activos.
Los atributos .coef_ y .interceptar_ da la pendiente que es además el coeficiente de x, y la intersección de y. Significa que y = c = 8.80, aproximadamente, cuando x = 0 e y = 4.22 (1) + 8.80 = 13.02 (aproximadamente) cuando x = 1. Tenga en cuenta que en la salida la intersección es escalar y el coeficiente es una matriz.
print(linreg.coef_)
print(linreg.intercept_)
Hemos construido nuestro modelo. Ahora intenta predecir la solución y_new para un nuevo valor de predictor x_new = 16. ¡Allí! Tenemos un modelo que puede predecir la solución para cualquier predictor dado.
x_new = np.array ([16]) .reforma (-1,1)
y_new = linreg.predict (x_new)
imprimir (y_new)
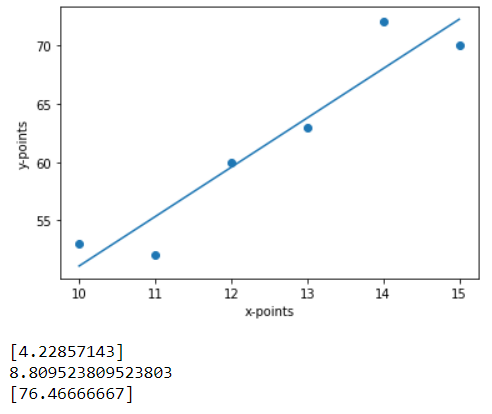
La imagen de arriba es el aspecto que podría tener el resultado final. Las 3 salidas debajo de la gráfica son la solución a nuestra impresión() declaraciones. Entonces son pendiente, intersección y y_new respectivamente.
La ecuación de la recta de regresión es y = 4,23x + 8,80. Entonces, de acuerdo con la ecuación, cuando x = 16,
y = 4,23 * (16) + 8,80 = 76,48. La pequeña diferencia en el cálculo se debe a los puntos decimales.
Nosotros podemos utilizar .puntaje() método que toma muestras xey como sus 2 argumentos para hallar R2 o el coeficiente de determinación. El mejor valor para R2 es 1.0 y además puede tomar valores negativos, dado que el modelo puede ser peor. Un valor más cercano de R2 a 1.0 indica la eficiencia de nuestro modelo.
linreg.score(xpoints, ypoints)
Ejecute el código y verá que el valor de R2 es 0,89, por lo que el pronóstico del modelo es fiable.
¿Que sigue?
Esto es tan simple como una regresión lineal. No es la única forma, pero me pareció la forma más sencilla y fácil. No se detenga aquí. Cuando se sienta cómodo con esto, puede avanzar un paso y considerar un conjunto de datos más grande. A modo de ejemplo, un archivo CSV. Necesitarás trabajar con Pandas y paquetes NumPy en ese caso. A continuación, puede probar un modelo de regresión lineal o logística múltiple. Sigue aprendiendo y practicando.
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





