Introducción
Cuando comienza con la ciencia de datos, comienza de manera simple. Pasas por proyectos simples como Problema de predicción de préstamos o Predicción de ventas de Big Mart. Estos problemas tienen datos estructurados ordenados de forma ordenada en un formato tabular. En otras palabras, se le alimenta con cuchara la parte más difícil en la canalización de la ciencia de datos.

Los conjuntos de datos en la vida real son mucho más complejos.
Primero debe comprenderlo, recopilarlo de varias fuentes y organizarlo en un formato que esté listo para su procesamiento. Esto es aún más difícil cuando los datos están en un formato no estructurado, como una imagen o un audio. Esto es así porque tendría que representar datos de imagen / audio de una manera estándar para que sean útiles para el análisis.
La abundancia de datos no estructurados
Curiosamente, los datos no estructurados representan una gran oportunidad poco explotada. Está más cerca de cómo nos comunicamos e interactuamos como humanos. También contiene mucha información útil y poderosa. Por ejemplo, si una persona habla; no solo obtienes lo que dice, sino también cuáles fueron las emociones de la persona a partir de la voz.
Además, el lenguaje corporal de la persona puede mostrarte muchas más características sobre una persona, ¡porque las acciones hablan más que las palabras! En resumen, los datos no estructurados son complejos, pero procesarlos puede generar recompensas fáciles.
En este artículo, pretendo cubrir una descripción general del procesamiento de audio / voz con un estudio de caso para que pueda obtener una introducción práctica a la resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... de problemas de procesamiento de audio.
¡Sigamos adelante!
Tabla de contenido
- ¿A qué te refieres con datos de audio?
- Aplicaciones del procesamiento de audio
- Manejo de datos en el dominio de audio
- ¡Resolvamos el desafío UrbanSound!
- Intermedio: nuestra primera presentación
- ¡Resolvamos el desafío! Parte 2: Construyendo mejores modelos
- Pasos futuros para explorar
¿A qué te refieres con datos de audio?
Directa o indirectamente, siempre estás en contacto con el audio. Su cerebro procesa y comprende continuamente datos de audio y le brinda información sobre el medio ambiente. Un ejemplo simple pueden ser sus conversaciones con personas que hace a diario. Este discurso es discernido por la otra persona para continuar con las discusiones. Incluso cuando cree que se encuentra en un entorno tranquilo, tiende a captar sonidos mucho más sutiles, como el susurro de las hojas o la salpicadura de la lluvia. Este es el alcance de su conexión con el audio.
Entonces, ¿puedes de alguna manera captar este audio flotando a tu alrededor para hacer algo constructivo? ¡Sí, por supuesto! Hay dispositivos construidos que lo ayudan a captar estos sonidos y representarlos en formato legible por computadora. Ejemplos de estos formatos son
- formato wav (archivo de audio de forma de onda)
- formato mp3 (MPEG-1 Audio Layer 3)
- Formato WMA (Windows Media Audio)
Si piensa en cómo se ve un audio, no es más que un formato de datos en forma de onda, donde la amplitud del audio cambia con respecto al tiempo. Esto se puede representar pictóricamente de la siguiente manera.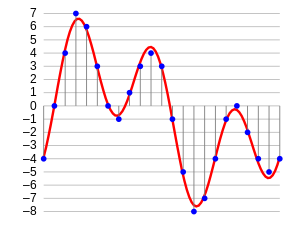
Aplicaciones del procesamiento de audio
Aunque comentamos que los datos de audio pueden ser útiles para el análisis. Pero, ¿cuáles son las posibles aplicaciones del procesamiento de audio? Aquí enumeraría algunos de ellos.
- Indexación de colecciones de música según sus características de audio.
- Recomendar música para canales de radio
- Búsqueda de similitudes para archivos de audio (también conocido como Shazam)
- Procesamiento y síntesis de voz: generación de voz artificial para agentes conversacionales
Aquí tienes un ejercicio; ¿Puedes pensar en una aplicación de procesamiento de audio que potencialmente pueda ayudar a miles de vidas?
Manejo de datos en el dominio de audio
Al igual que con todos los formatos de datos no estructurados, los datos de audio tienen un par de pasos de preprocesamiento que deben seguirse antes de que se presenten para su análisis. Cubriremos esto en detalle en un artículo posterior, aquí obtendremos una intuición de por qué se hace esto.
El primer paso es cargar los datos en un formato comprensible para la máquina. Para esto, simplemente tomamos valores después de cada paso de tiempo específico. Por ejemplo; en un archivo de audio de 2 segundos, extraemos valores a medio segundo. Se llama muestreo de datos de audio, y la velocidad a la que se muestrea se llama tasa de muestreo.
Otra forma de representar datos de audio es convertirlos en un dominio diferente de representación de datos, es decir, el dominio de frecuencia. Cuando tomamos muestras de datos de audio, necesitamos muchos más puntos de datos para representar todos los datos y, además, la frecuencia de muestreo debe ser lo más alta posible.
Por otro lado, si representamos datos de audio en dominio de la frecuencia, se requiere mucho menos espacio computacional. Para tener una intuición, eche un vistazo a la imagen de abajo.
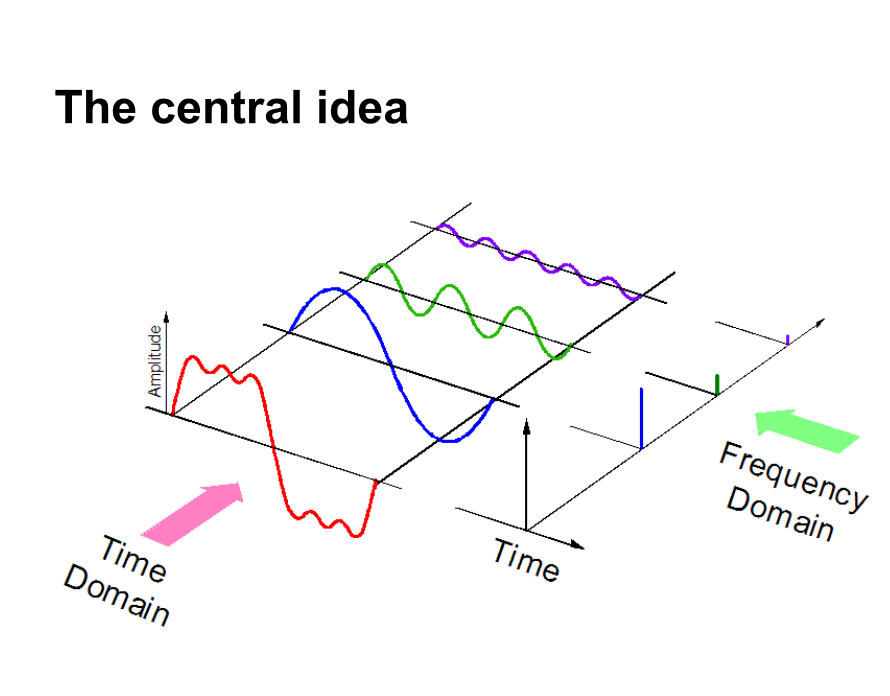
Aquí, separamos una señal de audio en 3 señales puras diferentes, que ahora se pueden representar como tres valores únicos en el dominio de la frecuencia.
Hay algunas formas más en las que se pueden representar los datos de audio, por ejemplo. utilizando MFC (cepstrums de frecuencia Mel. PD: Cubriremos esto en el artículo posterior). Estas no son más que formas diferentes de representar los datos.
Ahora, el siguiente paso es extraer características de estas representaciones de audio, de modo que nuestro algoritmo pueda trabajar en estas características y realizar la tarea para la que está diseñado. A continuación, se muestra una representación visual de las categorías de funciones de audio que se pueden extraer.
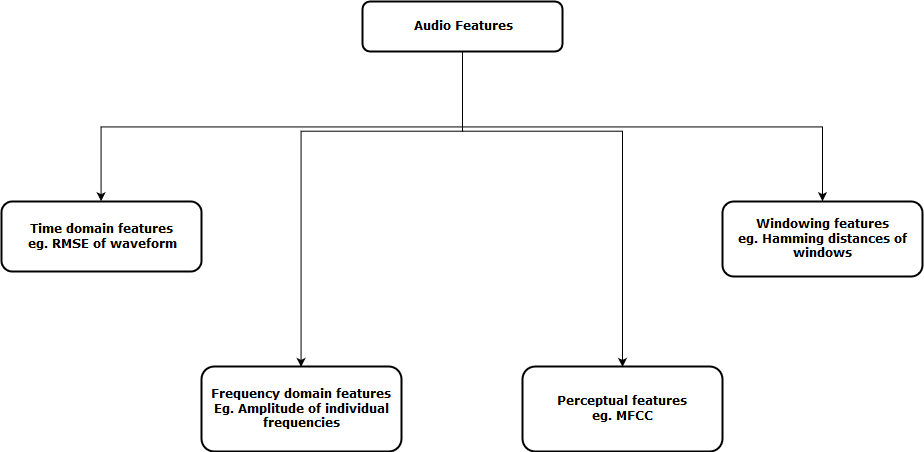
Después de extraer estas características, se envía al modelo de aprendizaje automático para su posterior análisis.
¡Resolvamos el desafío UrbanSound!
Tengamos una mejor visión general práctica en un proyecto de la vida real, el Desafío de sonido urbano. Este problema de práctica está destinado a presentarle el procesamiento de audio en el escenario de clasificación habitual.
El conjunto de datos contiene 8732 extractos de sonido (<= 4 s) de sonidos urbanos de 10 clases, a saber:
- aire acondicionado,
- bocina,
- niños jugando,
- ladrido de perro,
- perforación,
- Motor inactivo,
- disparo de arma
- martillo neumático,
- sirena y
- musica callejera
Aquí hay un extractoEl extracto es una sustancia obtenida mediante la concentración de compuestos de origen vegetal, animal o mineral. Se utiliza en diversas aplicaciones, como la industria alimentaria, farmacéutica y cosmética. Los extractos pueden presentarse en forma líquida, en polvo o como tinturas, y su producción implica técnicas como la maceración, la destilación o la extracción con solventes. Su uso permite aprovechar las propiedades beneficiosas de los ingredientes originales de manera más... de sonido del conjunto de datos. ¿Puedes adivinar a qué clase pertenece?
Para reproducir esto en el cuaderno de jupyter, simplemente puede seguir el código.
import IPython.display as ipd
ipd.Audio('../data/Train/2022.wav')
Ahora carguemos este audio en nuestro portátil como una matriz numerosa. Para esto usaremos librosa biblioteca en python. Para instalar librosa, simplemente escriba esto en la línea de comando
pip install librosaAhora podemos ejecutar el siguiente código para cargar los datos.
data, sampling_rate = librosa.load('../data/Train/2022.wav')
Cuando carga los datos, le da dos objetos; una matriz numerosa de un archivo de audio y la frecuencia de muestreo correspondiente por la que se extrajo. Ahora, para representar esto como una forma de onda (que originalmente es), use el siguiente código
% pylab inline import os import pandas as pd import librosa import glob plt.figure(figsize=(12, 4)) librosa.display.waveplot(data, sr=sampling_rate)
La salida sale de la siguiente manera
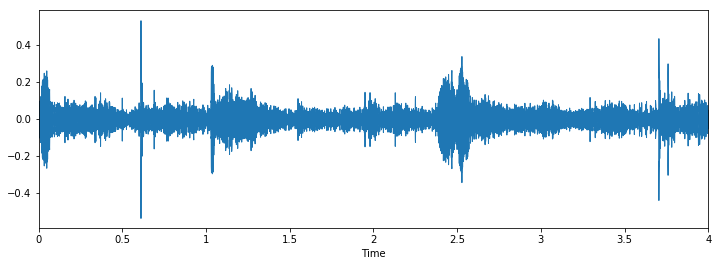
Inspeccionemos ahora visualmente nuestros datos y veamos si podemos encontrar patrones en los datos.
Class: jackhammerClass: drilling
Class: dog_barking
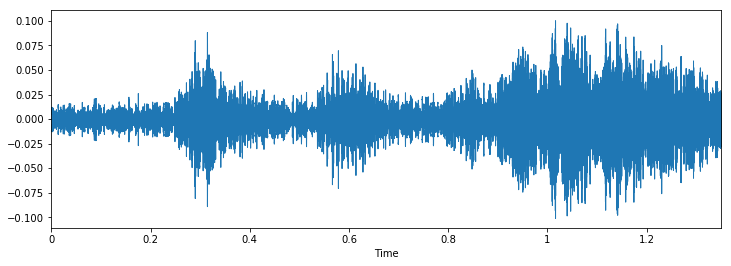
Podemos ver que puede ser difícil diferenciar entre martillo neumático y perforación, pero sigue siendo fácil distinguir entre ladrido de perros y perforación. Para ver más ejemplos de este tipo, puede utilizar este código
i = random.choice(train.index)
audio_name = train.ID[i]
path = os.path.join(data_dir, 'Train', str(audio_name) + '.wav')
print('Class: ', train.Class[i])
x, sr = librosa.load('../data/Train/' + str(train.ID[i]) + '.wav')
plt.figure(figsize=(12, 4))
librosa.display.waveplot(x, sr=sr)
Intermedio: nuestra primera presentación
Haremos un enfoque similar al que hicimos para el problema de detección de edad, para ver las distribuciones de clases y solo predecir la ocurrencia máxima de todos los casos de prueba como esa clase.
Veamos las distribuciones para este problema.
train.Class.value_counts()
Out[10]: jackhammer 0.122907 engine_idling 0.114811 siren 0.111684 dog_bark 0.110396 air_conditioner 0.110396 children_playing 0.110396 street_music 0.110396 drilling 0.110396 car_horn 0.056302 gun_shot 0.042318
Vemos que la clase martillo neumático tiene más valores que cualquier otra clase. Así que creemos nuestra primera presentación con esta idea.
test = pd.read_csv('../data/test.csv')
test['Class'] = 'jackhammer'
test.to_csv(‘sub01.csv’, index=False)
Esto parece una buena idea como punto de referencia para cualquier desafío, pero para este problema, parece un poco injusto. Esto es así porque el conjunto de datos no está muy desequilibrado.
¡Resolvamos el desafío! Parte 2: Construyendo mejores modelos
Ahora veamos cómo podemos aprovechar los conceptos que aprendimos anteriormente para resolver el problema. Seguiremos estos pasos para solucionar el problema.
Paso 1: carga archivos de audio
Paso 2: extraer funciones del audio
Paso 3: convierta los datos para pasarlos en nuestro modelo de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud...
Paso 4: Ejecute un modelo de aprendizaje profundo y obtenga resultados
A continuación se muestra un código de cómo implementé estos pasos
Paso 1 y 2 combinados: cargue archivos de audio y extraiga funciones
def parser(row):
# function to load files and extract features
file_name = os.path.join(os.path.abspath(data_dir), 'Train', str(row.ID) + '.wav')
# handle exception to check if there isn't a file which is corrupted
try:
# here kaiser_fast is a technique used for faster extraction
X, sample_rate = librosa.load(file_name, res_type="kaiser_fast")
# we extract mfcc feature from data
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)
except Exception as e:
print("Error encountered while parsing file: ", file)
return None, None
feature = mfccs
label = row.Class
return [feature, label]
temp = train.apply(parser, axis=1)
temp.columns = ['feature', 'label']
Paso 3: convierta los datos para pasarlos en nuestro modelo de aprendizaje profundo
from sklearn.preprocessing import LabelEncoder X = np.array(temp.feature.tolist()) y = np.array(temp.label.tolist()) lb = LabelEncoder() y = np_utils.to_categorical(lb.fit_transform(y))
Paso 4: Ejecute un modelo de aprendizaje profundo y obtenga resultados
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
num_labels = y.shape[1]
filter_size = 2
# build model
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss="categorical_crossentropy", metrics=['accuracy'], optimizer="adam")
Ahora entrenemos nuestro modelo
model.fit(X, y, batch_size=32, epochs=5, validation_data=(val_x, val_y))
Este es el resultado que obtuve al entrenar durante 5 épocas
Train on 5435 samples, validate on 1359 samples Epoch 1/10 5435/5435 [==============================] - 2s - loss: 12.0145 - acc: 0.1799 - val_loss: 8.3553 - val_acc: 0.2958 Epoch 2/10 5435/5435 [==============================] - 0s - loss: 7.6847 - acc: 0.2925 - val_loss: 2.1265 - val_acc: 0.5026 Epoch 3/10 5435/5435 [==============================] - 0s - loss: 2.5338 - acc: 0.3553 - val_loss: 1.7296 - val_acc: 0.5033 Epoch 4/10 5435/5435 [==============================] - 0s - loss: 1.8101 - acc: 0.4039 - val_loss: 1.4127 - val_acc: 0.6144 Epoch 5/10 5435/5435 [==============================] - 0s - loss: 1.5522 - acc: 0.4822 - val_loss: 1.2489 - val_acc: 0.6637
Parece estar bien, pero obviamente se puede aumentar la puntuación. (PD: podría obtener una precisión del 80% en mi conjunto de datos de validación). Ahora es tu turno, ¿puedes aumentar esta puntuación? Si es así, ¡házmelo saber en los comentarios a continuación!
Pasos futuros para explorar
Ahora que vimos aplicaciones simples, podemos idear algunos métodos más que pueden ayudarnos a mejorar nuestra puntuación.
- Aplicamos un modelo de red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... simple al problema. Nuestro próximo paso inmediato debería ser comprender dónde falla el modelo y por qué. Con esto, queremos conceptualizar nuestra comprensión de las fallas del algoritmo para que la próxima vez que construyamos un modelo, no cometa los mismos errores.
- Podemos construir modelos más eficientes que nuestros «mejores modelos», como las redes neuronales convolucionales o las redes neuronales recurrentes. Se ha demostrado que estos modelos resuelven este tipo de problemas con mayor facilidad.
- Tocamos el concepto de aumento de datos, pero no los aplicamos aquí. Puede probarlo para ver si funciona para el problema.
Notas finales
En este artículo, he ofrecido una breve descripción general del procesamiento de audio con un estudio de caso sobre el desafío UrbanSound. También he mostrado los pasos que realiza al tratar con datos de audio en python con el paquete librosa. Con este «shastra» en tu mano, espero que puedas probar tus propios algoritmos en el desafío Urban Sound, o intentar resolver tus propios problemas de audio en la vida diaria. Si tiene alguna sugerencia / idea, hágamelo saber en los comentarios a continuación.
Aprender, comprometerse , cortar a tajos y ser contratado!


Podcast: Reproducir en nueva ventana | Descargar





