Este blog fue publicado como parte de Blogatón de ciencia de datos 7
import pandas as pd
Cada proyecto de análisis de datos requiere un conjunto de datos. Estos conjuntos de datos están disponibles en varios formatos de archivo, como .xlsx, .json, .csv, .html. Convencionalmente, los conjuntos de datos se encuentran principalmente en .csv formato. CSV (o Valores Separados por Comas), como sugiere el nombre, tienen elementos de datos separados por comas. Los archivos CSV son archivos de texto sin formato que tienen un tamaño de archivo más ligero. Además, los archivos CSV se pueden ver y guardar en forma de tabla en herramientas populares como Microsoft Excel y Google Sheets.
Las comas utilizadas en los archivos CSV se conocen como delimitadores. Piense en los delimitadores como un límite de separación que distingue entre dos elementos de datos posteriores.
Leyendo archivos CSV usando Pandas
Para leer estos archivos CSV, usamos una función de la biblioteca Pandas llamada read_csv ().
df = pd.read_csv()
La función read_csv () tiene decenas de parámetros de los cuales uno es obligatorio y otros son opcionales para su uso ad hoc. Este parámetro obligatorio especifica el archivo CSV que queremos leer. Por ejemplo,
df = pd.read_csv("C:UsersRahulDesktopabc.csv")
Nota: Recuerde utilizar barras inclinadas hacia atrás dobles al especificar la ruta del archivo.

(Fuente: computadora personal)
El parámetro sep
Uno de los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... opcionales en read_csv () es sep, un nombre abreviado para separador. Este operador es el delimitador del que hablamos antes. Este parámetro sep le dice al intérprete, qué delimitador se usa en nuestro conjunto de datos o en el término de Layman, cómo se separan los elementos de datos en nuestro archivo CSV.
El valor predeterminado del parámetro sep es el coma (,) lo que significa que si no especificamos el parámetro sep en nuestra función read_csv (), se entiende que nuestro archivo está usando una coma como delimitador. Por lo tanto, en nuestro fragmento de código anterior, no especificamos el parámetro sep, se entendió que nuestro archivo tiene comas como delimitadores.
Usar otros delimitadores
A menudo puede suceder, el conjunto de datos en formato de archivo .csv tiene elementos de datos separados por un delimitador que no es una coma. Esto incluye punto y coma, dos puntos, espacio de tabulación, barras verticales, etc. En tales casos, necesitamos usar el parámetro sep dentro de la función read.csv (). Por ejemplo, un archivo llamado Example.csv es un archivo CSV separado por punto y coma.
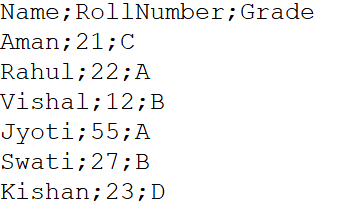
(Fuente: computadora personal)
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = ';')
Al ejecutar este código, obtenemos un marco de datos llamado df:
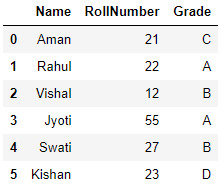
(Fuente: computadora personal)
Separador de barra vertical
Por lo tanto, un archivo delimitado por barras verticales se puede leer mediante:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = '|')
Separador de colon
Y un archivo delimitado por dos puntos se puede leer mediante:
df = pd.read_csv("C:UsersRahulDesktopExample.csv", sep = ':')
Separador de pestañas
A menudo podemos encontrar conjuntos de datos con formato de archivo .tsv. Estos archivos .tsv tienen valores separados por tabulaciones o podemos decir que tiene un espacio de tabulación como delimitador. Dichos archivos se pueden leer usando la misma función .read_csv () de pandas y necesitamos especificar el delimitador. Por ejemplo:
df = pd.read_csv("C:UsersRahulDesktopExample.tsv", sep = 't')
De manera similar, se pueden usar otros separadores en función del delimitador identificado de nuestros datos.
Conclusión
Siempre es útil comprobar cómo se almacenan nuestros datos en nuestro conjunto de datos. Es necesario comprender los datos antes de comenzar a trabajar con ellos. Se puede identificar un delimitador sin esfuerzo al verificar los datos. Según nuestra inspección, podemos usar el delimitador relevante en el parámetro sep.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





