Este artículo fue publicado como parte del Blogatón de ciencia de datos
Este artículo tiene como objetivo comparar cuatro algoritmos diferentes de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y aprendizaje automático para construir un detector de spam y evaluar su rendimiento. El conjunto de datos que utilizamos procedía de una muestra aleatoria de asuntos y cuerpos de correo electrónico que contenían tanto spam como correos electrónicos nocivos en numerosas proporciones, que convertimos en lemas. La detección de correo no deseado es uno de los proyectos más efectivos de aprendizaje profundo, pero a menudo también es un proyecto en el que las personas pierden la confianza para buscar el modelo más simple con fines de precisión. En este artículo, vamos a detectar el correo no deseado en el correo utilizando cuatro técnicas diferentes y compararlas para obtener el modelo más preciso.
¿POR QUÉ DETECCIÓN DE SPAM?
Un correo electrónico se ha convertido en uno de los tipos de comunicación más importantes. En 2014, se estima que hay 4,1 mil millones de cuentas de correo electrónico en todo el mundo, y alrededor de 196 mil millones de correos electrónicos se envían día tras día en todo el mundo. El spam es una de las principales amenazas que se presentan a los usuarios de correo electrónico. Todos los flujos de correo electrónico que fueron spam en 2013 son el 69,6%. Por lo tanto, una tecnología de filtrado de spam eficaz es una contribución significativa a la sostenibilidad del ciberespacio y nuestra sociedad. Dado que la importancia del correo electrónico no es menor que la de su cuenta bancaria que contiene 1Cr., Protegerlo de spam o fraudes también es obligatorio.
Preparación de datos
Para preparar los datos, seguimos los pasos a continuación:
1. Descargue correos electrónicos de spam y ham a través del servicio de comida para llevar de Google como un archivo de caja.
2. Lea los archivos mbox en listas usando el paquete ‘buzón’. Cada elemento de la lista contenía un correo electrónico individual. En la primera iteración, incluimos 1000 correos de radioaficionado y 400 correos de spam (probamos diferentes proporciones después de la primera iteración).
3. Desempaquetó cada correo electrónico y concatenó su asunto y cuerpo. Decidimos incluir el asunto del correo electrónico también en nuestro análisis porque también es un gran indicador de si un correo electrónico es spam o ham.
4. Convirtió las listas en marcos de datos, se unió a los marcos de datos de spam y de radioaficionado, y mezcló el marco de datos resultante.
5. Divida la trama de datos en tramas de datos de prueba y de tren. Los datos de prueba fueron el 33% del conjunto de datos original.
6. Divida el texto del correo en lemas y aplique la transformación TF-IDF usando CountVectorizer seguido del transformador TF-IDF.
7. Se entrenaron cuatro modelos usando los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....:
- Bayes ingenuo
- Árboles de decisión
- Máquina de vectores de soporte (SVM)
- Bosque aleatorio
8. Utilizando los modelos entrenados, predijo la etiqueta de correo electrónico para el conjunto de datos de prueba. Se calcularon cuatro métricas para medir el rendimiento de los modelos como Exactitud, Precisión, Recuperación, Puntaje F, AUC.
CÓDIGO
1.Importar las bibliotecas
#import all the needed libraries import mailbox %matplotlib inline import matplotlib.pyplot as plt import csv from textblob import TextBlob import pandas import sklearn #import cPickle import numpy as np from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer from sklearn.naive_bayes import MultinomialNB from sklearn.svm import SVC, LinearSVC from sklearn.metrics import classification_report, f1_score, accuracy_score, confusion_matrix from sklearn.pipeline import Pipeline from sklearn.grid_search import GridSearchCV from sklearn.cross_validation import StratifiedKFold, cross_val_score, train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.learning_curve import learning_curve #import metrics libraries from sklearn.metrics import confusion_matrix from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import roc_auc_score
2.Función para obtener el texto del correo electrónico del cuerpo del correo electrónico
def getmailtext(message): #getting plain text 'email body'
body = None
#check if mbox email message has multiple parts
if message.is_multipart():
for part in message.walk():
if part.is_multipart():
for subpart in part.walk():
if subpart.get_content_type() == 'text/plain':
body = subpart.get_payload(decode=True)
elif part.get_content_type() == 'text/plain':
body = part.get_payload(decode=True)
#if message only has a single part
elif message.get_content_type() == 'text/plain':
body = message.get_payload(decode=True)
#return mail text which concatenates both mail subject and body
mailtext=str(message['subject'])+" "+str(body)
return mailtext
3. Leer el archivo de correo electrónico spam m-box
mbox = mailbox.mbox('Spam.mbox')
mlist_spam = []
#create list which contains mail text for each spam email message
for message in mbox:
mlist_spam.append(getmailtext(message))
#break
#read ham mbox email file
mbox_ham = mailbox.mbox('ham.mbox')
mlist_ham = []
count=0
#create list which contains mail text for each ham email message
for message in mbox_ham:
mlist_ham.append(getmailtext(message))
if count>601:
break
count+=1
4. Crear dos conjuntos de datos a partir de correos electrónicos no deseados / ham que contengan información como el texto del correo, la etiqueta del correo y la longitud del correo.
#create 2 dataframes for ham spam mails which contain the following info- #Mail text, mail length, mail is ham/spam label import pandas as pd spam_df = pd.DataFrame(mlist_spam, columns=["message"]) spam_df["label"] = "spam" spam_df['length'] = spam_df['message'].map(lambda text: len(text)) print(spam_df.head()) ham_df = pd.DataFrame(mlist_ham, columns=["message"]) ham_df["label"] = "ham" ham_df['length'] = ham_df['message'].map(lambda text: len(text)) print(ham_df.head())

5.Función para aplicar transformaciones BOW y TF-IDF
def features_transform(mail):
#get the bag of words for the mail text
bow_transformer = CountVectorizer(analyzer=split_into_lemmas).fit(mail_train)
#print(len(bow_transformer.vocabulary_))
messages_bow = bow_transformer.transform(mail)
#print sparsity value
print('sparse matrix shape:', messages_bow.shape)
print('number of non-zeros:', messages_bow.nnz)
print('sparsity: %.2f%%' % (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1])))
#apply the TF-IDF transform to the output of BOW
tfidf_transformer = TfidfTransformer().fit(messages_bow)
messages_tfidf = tfidf_transformer.transform(messages_bow)
#print(messages_tfidf.shape)
#return result of transforms
return messages_tfidf
6. Función para imprimir las métricas de rendimiento del modelo asociado
#function which takes in y test value and y predicted value and prints the associated model performance metrics
def model_assessment(y_test,predicted_class):
print('confusion matrix')
print(confusion_matrix(y_test,predicted_class))
print('accuracy')
print(accuracy_score(y_test,predicted_class))
print('precision')
print(precision_score(y_test,predicted_class,pos_label="spam"))
print('recall')
print(recall_score(y_test,predicted_class,pos_label="spam"))
print('f-Score')
print(f1_score(y_test,predicted_class,pos_label="spam"))
print('AUC')
print(roc_auc_score(np.where(y_test=='spam',1,0),np.where(predicted_class=='spam',1,0)))
plt.matshow(confusion_matrix(y_test, predicted_class), cmap=plt.cm.binary, interpolation='nearest')
plt.title('confusion matrix')
plt.colorbar()
plt.ylabel('expected label')
plt.xlabel('predicted label')
Comencemos el análisis comparativo de cuatro modelos diferentes para obtener el algoritmo de mayor rendimiento.
1.Modelo ingenuo de Bayes
Bayes ingenuo con un enfoque de bolsa de palabras usando TF-IDFNaive Bayes es el algoritmo de clasificación más simple (rápido de formar, usado regularmente para la detección de spam). es un método popular (línea de base) para la categorización de texto, el asunto de juzgar documentos como pertenecientes a una categoría o lo contrario (como spam o legítimo, deportes o política, etc.) con frecuencias de palabras debido a las características.
Extracción de características usando BOW:
TF-IDFTerm Frequency: la frecuencia inversa del documento utiliza todos los tokens dentro del conjunto de datos como vocabulario. La frecuencia del término y la cantidad de documentos durante los cuales se produce el token son responsables de determinar la frecuencia inversa del documento. Lo que esto asegura es que, si un token ocurre con frecuencia durante un documento, ese token tendrá un TF alto pero si ese token ocurre con frecuencia dentro de la mayor parte de los documentos, entonces reduce el IDF. Tanto estas matrices TF como IDF para un documento seleccionado se multiplican y normalizan para hacer el TF-IDF de un documento.
CÓDIGO
#create and fit NB model modelNB=MultinomialNB() modelNB.fit(train_features,y_train) #transform test features to test the model performance test_features=features_transform(mail_test) #NB predictions predicted_class_NB=modelNB.predict(test_features) #assess NB model_assessment(y_test,predicted_class_NB)
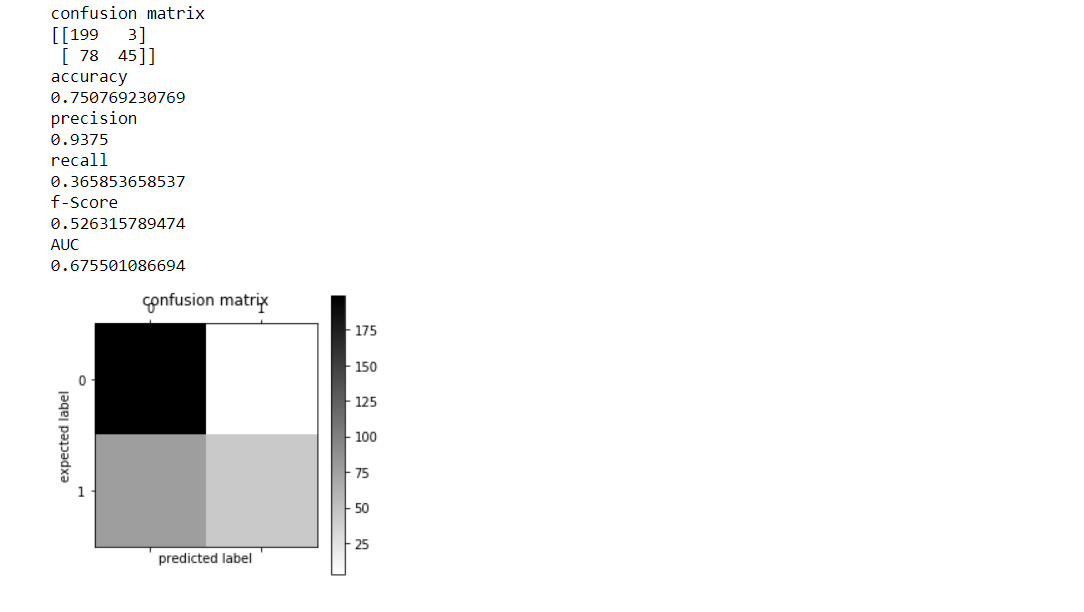
2.Modelo de árbol de decisión
Los árboles de decisión se utilizan para clasificación y regresión. La teoría podría ser una medida para definir este grado de desorganización durante un sistema llamado Entropía. El factor de entropía varía de una muestra a otra. La entropía es cero para la muestra homogénea, y para la muestra de dividendos iguales, la entropía es 1. Elige la división que tiene una entropía mínima en comparación con el nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... principal y otras divisiones. Cuanto menor es la entropía, mayor es.
CÓDIGO
#create and fit tree model model_tree=DecisionTreeClassifier() model_tree.fit(train_features,y_train) #run model on test and print metrics predicted_class_tree=model_tree.predict(test_features) model_assessment(y_test,predicted_class_tree)

3. Máquina de vectores de soporte
Tanto los desafíos de clasificación como de regresión funcionan perfectamente para este conocido algoritmo de aprendizaje automático supervisado (SVM). Sin embargo, se emplea principalmente en problemas de clasificación. Cuando trabajamos con este algoritmo, en un espacio n-dimensional, vamos a trazar cada elemento de datos hasta cierto punto, de modo que el valor de cada característica sea el valor de una coordenada seleccionada. Support Vector Machine podría incluso ser una frontera que segregue mejor las 2 clases (hiperplano / línea).
CÓDIGO
#create and fit SVM model model_svm=SVC() model_svm.fit(train_features,y_train) #run model on test and print metrics predicted_class_svm=model_svm.predict(test_features) model_assessment(y_test,predicted_class_svm)


4. Bosque aleatorio
El bosque aleatorio es como un algoritmo de arranque con un modelo de árbol de llamadas (CART). La predicción de la última palabra podría ser una función de cada predicción. Esta predicción final puede ser simplemente la media de todas las predicciones. El bosque aleatorio proporciona predicciones bastante más precisas cuando se coloca junto a modelos simples CART / CHAID o de regresión en muchos escenarios. Estos casos generalmente tienen un gran número de variables predictivas y un tamaño de muestra enorme. esto a menudo se debe a que captura la varianza de varias variables de entrada en un tiempo uniforme y permite que un gran número de observaciones participen en la predicción.
CÓDIGO
from sklearn.ensemble import RandomForestClassifier #create and fit model model_rf=RandomForestClassifier(n_estimators=20,criterion='entropy') model_rf.fit(train_features,y_train) #run model on test and print metrics predicted_class_rf=model_rf.predict(test_features) model_assessment(y_test,predicted_class_rf)
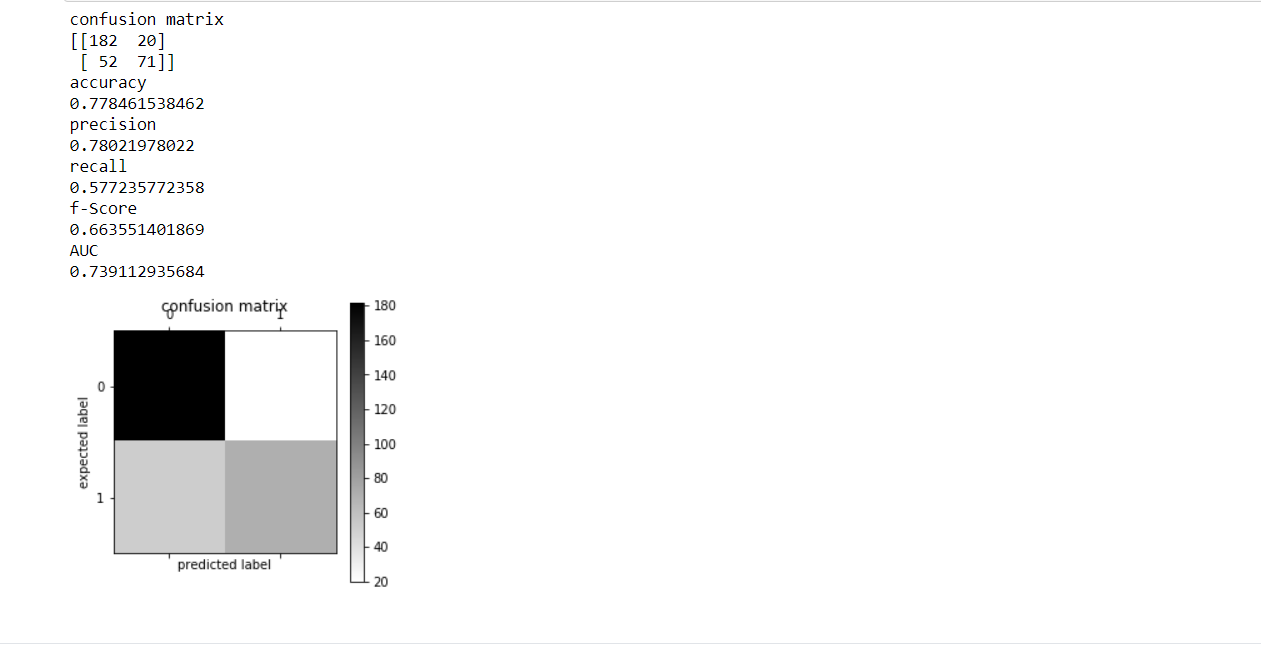
COMPARACIÓN:-
Al ver la salida de los 4 modelos, puede comparar y encontrar su precisión fácilmente. De acuerdo con la explicación anterior, el orden decreciente de precisión se representa como:
PRECISIÓN DEL MODELO
BOSQUE ALEATORIO 0.77846
BAHÍAS NAIVAS 0,75076
ÁRBOL DE DECISIONES MODELO 0.65538
MÁQUINA DE VECTOR DE SOPORTE 0.62153
RESULTADOS
Los resultados son muy claros de que Random Forest es el método más preciso para detectar correos electrónicos no deseados. La razón de lo mismo es su capacidad de amplio desvío para encontrar la mejor característica utilizando su aleatoriedad. El modelo que no se puede utilizar para tal detección de correo no deseado es SVM. La razón de lo mismo es su pequeña expansión. SVM no puede tener la capacidad de manejar grandes cantidades de datos.
CONCLUSIÓN
Este artículo lo ayudará en la implementación de un proyecto de detección de spam con la ayuda del aprendizaje profundo. Esto se basa en gran medida en un análisis comparativo de cuatro modelos diferentes. Estén atentos a Analytics Vidya para los próximos artículos. Puede usar esto como referencia. No dude en poner sus aportes en el chatbox a continuación. También puedes enviarme un ping en LinkedIn en https://www.linkedin.com/in/shivani-sharma-aba6141b6/
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





