El mundo de la detección de objetos
Me encanta trabajar en el espacio del aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... Francamente, es un campo vasto con una plétora de técnicas y marcos para analizar y aprender. Y la verdadera emoción de crear modelos de visión por computadora y aprendizaje profundo se produce cuando veo aplicaciones del mundo real como el reconocimiento facial y el seguimiento de la pelota en el cricket, entre otras cosas.
Y uno de mis conceptos favoritos de visión artificial y aprendizaje profundo es la detección de objetos. La capacidad de construir un modelo que pueda pasar por imágenes y decirme qué objetos están presentes, ¡es una sensación invaluable!

Cuando los humanos miramos una imagen, reconocemos el objeto de interés en cuestión de segundos. Este no es el caso de las máquinas. Por lo tanto, la detección de objetos es un problema de visión por computadora para localizar instancias de objetos en una imagen.
Estas son las buenas noticias: las aplicaciones de detección de objetos son más fáciles de desarrollar que nunca. Los enfoques actuales de hoy se centran en la canalización de un extremo a otro que ha mejorado significativamente el rendimiento y también ha ayudado a desarrollar casos de uso en tiempo real.
En este artículo, lo guiaré a través de cómo construir un modelo de detección de objetos usando la popular API de TensorFlow. Si es un recién llegado al aprendizaje profundo, la visión por computadora y el mundo de la detección de objetos, le recomiendo que consulte los siguientes recursos:
Tabla de contenido
- Un marco general para la detección de objetos
- ¿Qué es una API? ¿Por qué necesitamos una API?
- API de detección de objetos de TensorFlow
Un marco general para la detección de objetos
Normalmente, seguimos tres pasos al crear un marco de detección de objetos:
- Primero, se utiliza un modelo o algoritmo de aprendizaje profundo para generar un gran conjunto de cuadros delimitadores que abarcan la imagen completa (es decir, un componente de localización de objetos)

- A continuación, se extraen características visuales para cada uno de los cuadros delimitadores. Se evalúan y se determina si y qué objetos están presentes en las cajas en función de las características visuales (es decir, un componente de clasificación de objetos)

- En el último paso de posprocesamiento, los cuadros superpuestos se combinan en un solo cuadro delimitador (es decir, supresión no máxima)




Eso es todo, ¡está listo con su primer marco de detección de objetos!
¿Qué es una API? ¿Por qué necesitamos una API?
API significa Interfaz de programación de aplicaciones. Una API proporciona a los desarrolladores un conjunto de operaciones comunes para que no tengan que escribir código desde cero.
Piense en una API como el menú de un restaurante que proporciona una lista de platos junto con una descripción de cada plato. Cuando especificamos qué plato queremos, el restaurante hace el trabajo y nos proporciona platos terminados. No sabemos exactamente cómo el restaurante prepara esa comida, y realmente no es necesario.
En cierto sentido, las API ahorran mucho tiempo. También ofrecen comodidad a los usuarios en muchos casos. Piénselo: los usuarios de Facebook (¡incluyéndome a mí!) Aprecian la posibilidad de iniciar sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... en muchas aplicaciones y sitios utilizando su ID de Facebook. ¿Cómo crees que funciona esto? ¡Usando las API de Facebook, por supuesto!
Entonces, en este artículo, veremos la API de TensorFlow desarrollada para la tarea de detección de objetos.
API de detección de objetos de TensorFlow
La API de detección de objetos de TensorFlow es el marco para crear una red de aprendizaje profundo que resuelve los problemas de detección de objetos.
Ya existen modelos previamente entrenados en su marco a los que se refieren como Model Zoo. Esto incluye una colección de modelos previamente entrenados entrenados en el conjunto de datos COCO, el conjunto de datos KITTI y el conjunto de datos de imágenes abiertas. Estos modelos se pueden usar para inferencias si estamos interesados en categorías solo en este conjunto de datos.
También son útiles para inicializar sus modelos al entrenar en el nuevo conjunto de datos. Las diversas arquitecturas utilizadas en el modelo preentrenado se describen en esta tabla:

MobileNet-SSD
La arquitectura SSD es una red de convolución única que aprende a predecir las ubicaciones de los cuadros delimitadores y a clasificar estas ubicaciones en una sola pasada. Por lo tanto, SSD se puede entrenar de un extremo a otro. La red SSD consta de una arquitectura base (MobileNet en este caso) seguida de varias capas de convolución:

SSD opera en mapas de características para detectar la ubicación de los cuadros delimitadores. Recuerde: un mapa de características tiene el tamaño Df * Df * M. Para cada ubicación del mapa de características, se predicen k cuadros delimitadores. Cada cuadro delimitador lleva consigo la siguiente información:
- Cuadro delimitador de 4 esquinas compensar ubicaciones (cx, cy, w, h)
- Probabilidades de clase C (c1, c2,… cp)
SSD no predecir la forma de la caja, más bien dónde está la caja. Los k cuadros delimitadores tienen cada uno una forma predeterminada. Las formas se establecen antes del entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... real. Por ejemplo, en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior, hay 4 casillas, lo que significa k = 4.
Pérdida en MobileNet-SSD
Con el conjunto final de casillas emparejadas, podemos calcular la pérdida de esta manera:
L = 1/N (L class + L box)
Aquí, N es el número total de cajas emparejadas. La clase L es la pérdida softmax para la clasificación y la ‘caja L’ es la pérdida suave L1 que representa el error de las cajas emparejadas. La pérdida suave L1 es una modificación de la pérdida L1 que es más robusta a los valores atípicos. En el caso de que N sea 0, la pérdida también se establece en 0.
MobileNet
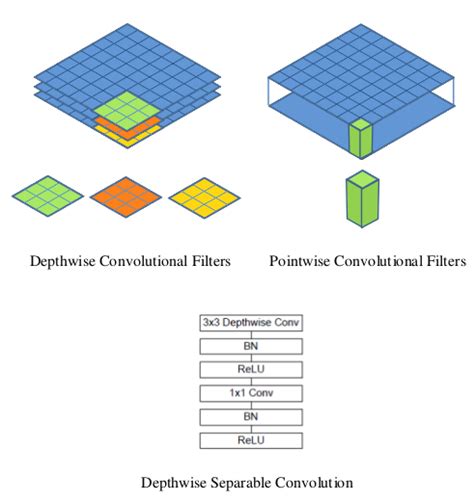
El modelo MobileNet se basa en convoluciones separables en profundidad que son una forma de convoluciones factorizadas. Estos factorizan una convolución estándar en una convolución en profundidad y una convolución de 1 × 1 llamada convolución puntual.
Para MobileNets, la convolución en profundidad aplica un solo filtro a cada canal de entrada. La convolución puntual luego aplica una convolución 1 × 1 para combinar las salidas de la convolución en profundidad.
Una convolución estándar filtra y combina entradas en un nuevo conjunto de salidas en un solo paso. La convolución separable en profundidad divide esto en dos capas: una capa separada para filtrar y una capa separada para combinar. Esta factorización tiene el efecto de reducir drásticamente el cálculo y el tamaño del modelo.
¿Cómo cargar el modelo?
A continuación se muestra el proceso paso a paso a seguir en Google Colab para que pueda visualizar fácilmente la detección de objetos. También puede seguir el código.
Instalar el modelo
Asegúrate de tener pycocotools instalado:
Obtener tensorflow/models o cd al directorio principal del repositorio:
Compile protobufs e instale el object_detection paquete:
Importar las bibliotecas necesarias
Importe el módulo de detección de objetos:
Preparación del modelo
Cargador
Cargando mapa de etiquetas
Etiquete mapas de índices de mapas con nombres de categorías para que cuando nuestra red de convolución prediga 5, sepamos que esto corresponde a un avión:
En aras de la simplicidad, probaremos en 2 imágenes:
Modelo de detección de objetos mediante la API de TensorFlow
Cargue un modelo de detección de objetos:
Verifique la firma de entrada del modelo (espera un lote de imágenes de 3 colores de tipo int8):
Agregue una función contenedora para llamar al modelo y limpiar las salidas:
Ejecútelo en cada imagen de prueba y muestre los resultados:
A continuación se muestra la imagen de ejemplo probada en ssd_mobilenet_v1_coco (MobileNet-SSD capacitado en el conjunto de datos COCO):

Inicio-SSD
La arquitectura del modelo Inception-SSD es similar a la del anterior MobileNet-SSD. La diferencia es que la arquitectura base aquí es el modelo Inception. Para saber más sobre la red de inicio, vaya aquí: Comprensión de la red de inicio desde cero.
¿Cómo cargar el modelo?
Simplemente cambie el nombre del modelo en la parte de Detección de la API:
Luego, haz la predicción siguiendo los pasos que seguimos anteriormente. ¡Voila!
RCNN más rápido
Las redes de detección de objetos de última generación dependen de algoritmos de propuesta de región para formular hipótesis sobre la ubicación de los objetos. Avances como SPPnet y Fast R-CNN han reducido el tiempo de ejecución de estas redes de detección, exponiendo el cálculo de la propuesta de región como un cuello de botella.
En Faster RCNN, alimentamos la imagen de entrada a la red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... para generar un mapa de características convolucional. A partir del mapa de características convolucional, identificamos la región de propuestas y las deformamos en cuadrados. Y al usar una capa de agrupación de RoI (capa de región de interés), los reformamos en un tamaño fijo para que pueda introducirse en una capa completamente conectada.
A partir del vector de características RoI, usamos una capa softmax para predecir la clase de la región propuesta y también los valores de compensación para el cuadro delimitador.
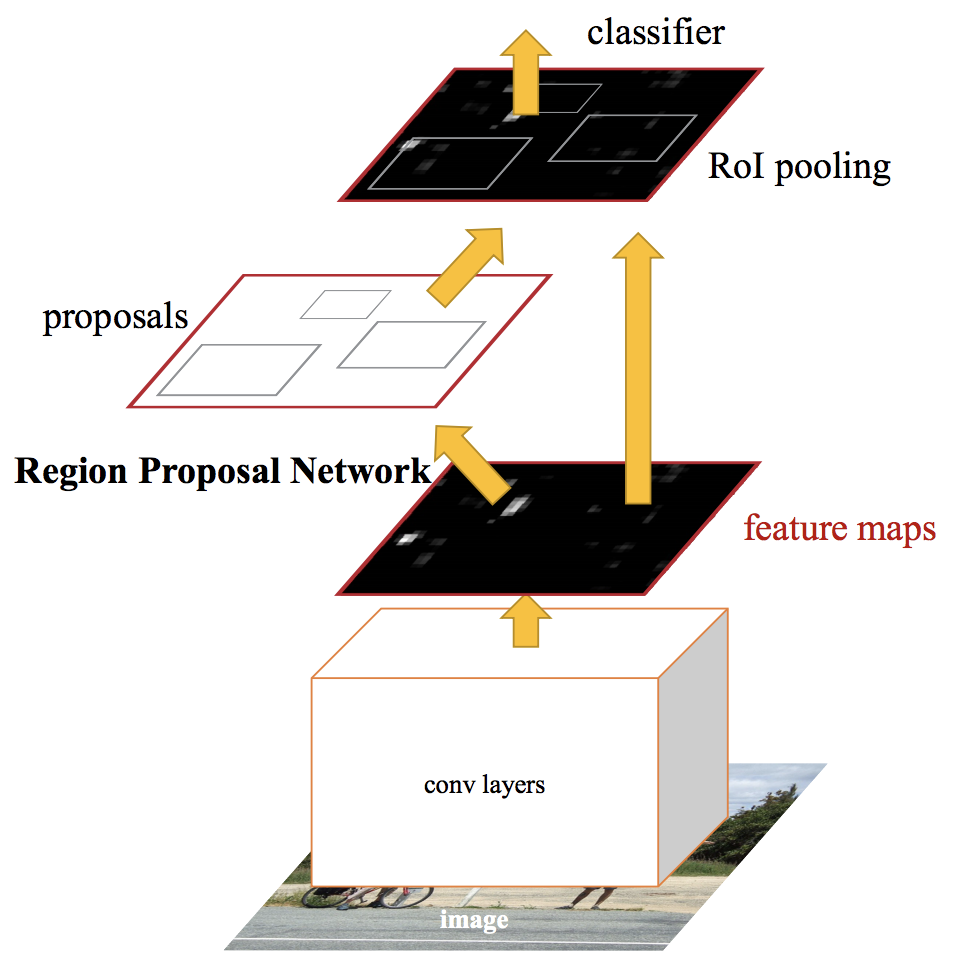
Para leer más en profundidad sobre Faster RCNN, lea este asombroso artículo – Una implementación práctica del algoritmo Faster R-CNN para la detección de objetos (Parte 2 – con códigos Python).
¿Cómo cargar el modelo?
Simplemente cambie el nombre del modelo en la parte de Detección de la API nuevamente:
Luego, haz la predicción siguiendo los mismos pasos que seguimos anteriormente. A continuación se muestra la imagen de ejemplo cuando se proporciona a un modelo RCNN más rápido:

Como puede ver, esto es mucho mejor que el modelo SSD-Mobilenet. Pero viene con una compensación: es mucho más lento que el modelo anterior. Este es el tipo de decisiones que deberá tomar cuando elija el modelo de detección de objetos adecuado para su proyecto de aprendizaje profundo y visión por computadora.
¿Qué modelo de detección de objetos debería elegir?
Dependiendo de sus requisitos específicos, puede elegir el modelo correcto de la API de TensorFlow. Si queremos un modelo de alta velocidad que pueda funcionar en la detección de la transmisión de video a un alto fps, la red de detección de disparo único (SSD) funciona mejor. Como sugiere su nombre, la red SSD determina todas las probabilidades del cuadro delimitador de una vez; por tanto, es un modelo mucho más rápido.
Sin embargo, con la detección de un solo disparo, gana velocidad a costa de la precisión. Con FasterRCNN, obtendremos alta precisión pero baja velocidad. Así que explore y en el proceso, se dará cuenta de lo poderosa que puede ser esta API de TensorFlow.





