Este artículo fue publicado como parte del Blogatón de ciencia de datos
La creación de reconocimiento facial se considera una tarea muy fácil en el campo de la visión por computadora, pero es extremadamente difícil tener una canalización que pueda predecir rostros con fondos complejos cuando tiene múltiples rostros, diferentes condiciones de iluminación y diferentes escalas de imágenes. Este blog describirá cómo creamos un modelo que puede superar a los humanos en algunos casos. Nuestro conjunto de datos consta de 3 clases (no puedo compartir los datos debido a problemas de confidencialidad, pero le mostraré cómo se ve). La clase 1 es Jesse Eisenberg (actor), la clase 2 es Mila Kunis (estrella del pop) y la clase 0, cualquier persona. Así es como se veían nuestro tren (80 imágenes) y los datos de prueba (más de 1800 imágenes).
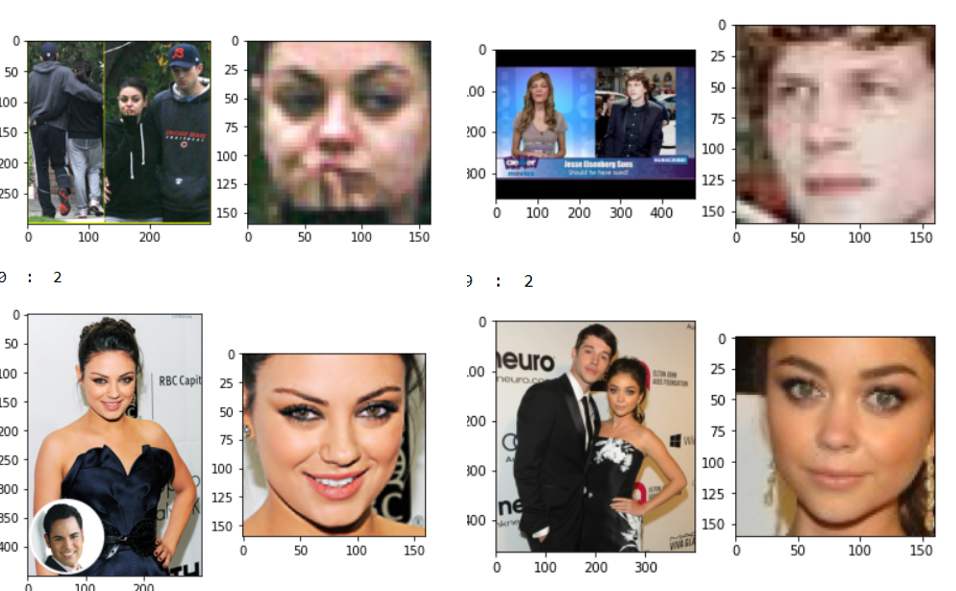
Estos son nuestros datos de prueba y los rostros extraídos de esas imágenes, estos datos tienen una complejidad extrema debido a múltiples rostros, fondos complejos y muchas imágenes pixeladas. Por otro lado, nuestros datos de trenes son extremadamente limpios como se muestra en la imagen de abajo. Tenemos muchas diferencias en la distribución de datos de prueba y de tren. Necesitamos una técnica que pueda generalizar bien independientemente de la cantidad de muestras que necesite y cuán diferentes sean los datos del tren y de la prueba.

La técnica que vamos a utilizar para esta tarea es, en primer lugar, generar la incrustación facial a partir de un modelo de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y luego aplicar un clasificador simple.
Usando FACENET
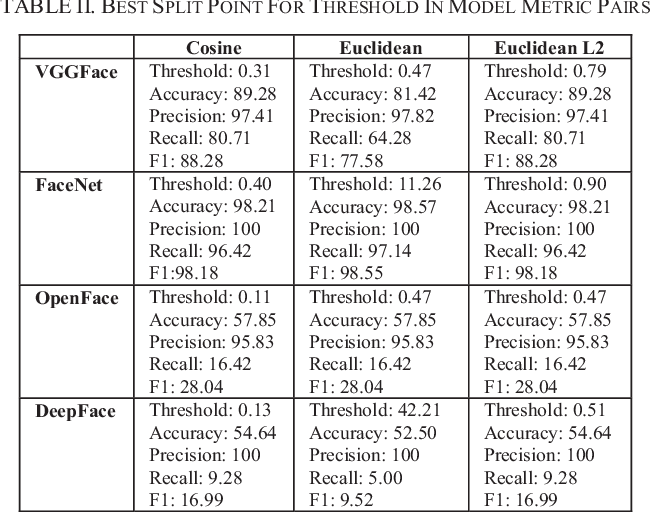
Para superar realmente los límites de la detección de rostros, veremos algunos métodos de vanguardia. Las técnicas modernas de extracción de rostros han hecho uso de Deep Convolution Networks. Como todos sabemos, las características creadas por los marcos de aprendizaje profundo modernos son realmente mejores que la mayoría de las características creadas a mano. Verificamos 4 modelos de aprendizaje profundo, a saber, FaceNet (Google), DeepFace (Facebook), VGGFace (Oxford) y OpenFace (CMU). De estos 4 modelos FaceNet nos estaba dando el mejor resultado. En general, FaceNet ofrece mejores resultados que los otros 3 modelos.
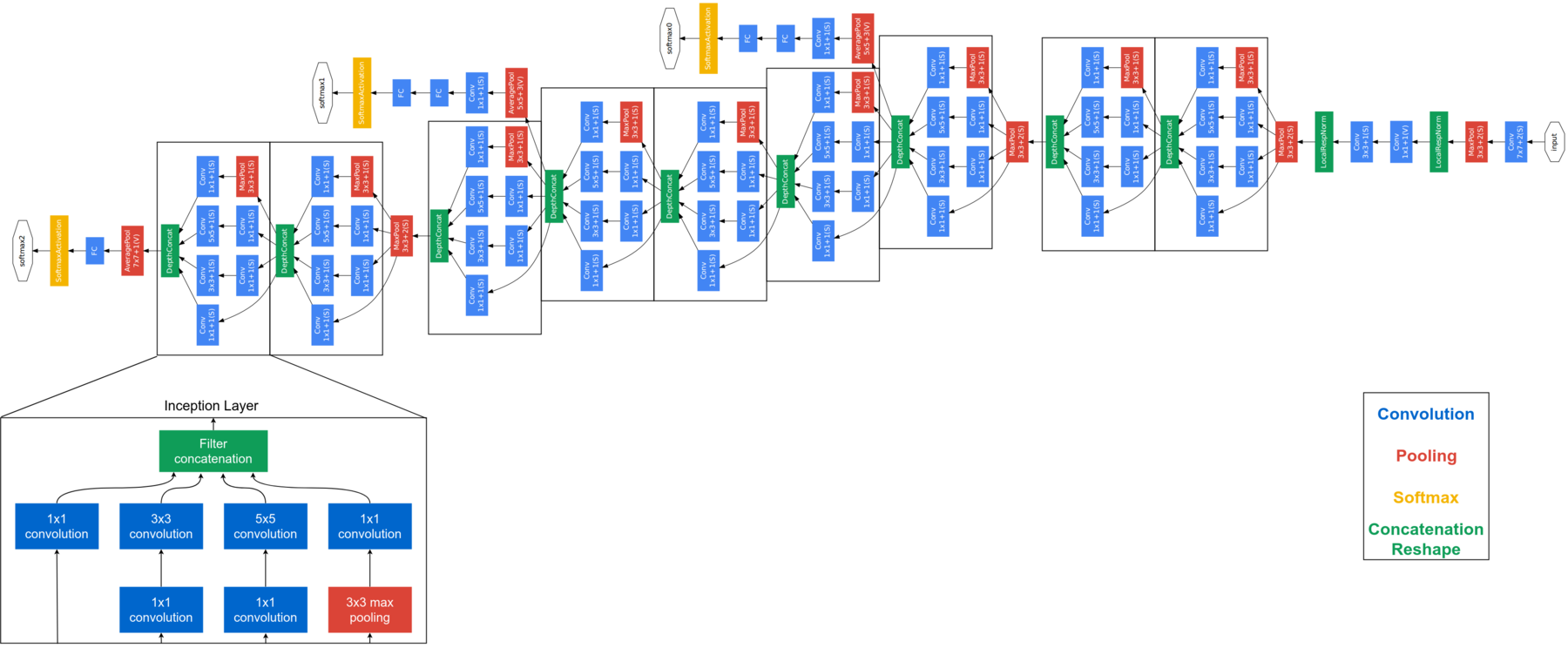
FaceNet se considera un modelo de última generación desarrollado por Google. Se basa en la capa inicial, explicar la arquitectura completa de FaceNet está más allá del alcance de este blog. A continuación se muestra la arquitectura de FaceNet. FaceNet usa módulos de inicio en bloques para reducir la cantidad de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... entrenables. Este modelo toma imágenes RGB de 160 × 160 y genera una incrustación de tamaño 128 para una imagen. Para esta implementación, necesitaremos un par de funciones adicionales. Pero antes de enviar la imagen de la cara a FaceNet, necesitamos extraer las caras de las imágenes.
detector = dlib.cnn_face_detection_model_v1("../input/pretrained-models-faces/mmod_human_face_detector.dat")
def rect_to_bb(rect):
# take a bounding predicted by dlib and convert it
# to the format (x, y, w, h) as we would normally do
# with OpenCV
x = rect.rect.left()
y = rect.rect.top()
w = rect.rect.right() - x
h = rect.rect.bottom() - y
# return a tuple of (x, y, w, h)
return (x, y, w, h)
def dlib_corrected(data, data_type="train"):
#We set the size of the image
dim = (160, 160)
data_images=[]
#If we are processing training data we need to keep track of the labels
if data_type=='train':
data_labels=[]
#Loop over all images
for cnt in range(0,len(data)):
image = data['img'][cnt]
#The large images are resized
if image.shape[0] > 1000 and image.shape[1] > 1000:
image = cv2.resize(image, (1000,1000), interpolation = cv2.INTER_AREA)
#The image is converted to grey-scales
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#Detect the faces
rects = detector(gray, 1)
sub_images_data = []
#Loop over all faces in the image
for (i, rect) in enumerate(rects):
#Convert the bounding box to edges
(x, y, w, h) = rect_to_bb(rect)
#Here we copy and crop the face out of the image
clone = image.copy()
if(x>=0 and y>=0 and w>=0 and h>=0):
crop_img = clone[y:y+h, x:x+w]
else:
crop_img = clone.copy()
#We resize the face to the correct size
rgbImg = cv2.resize(crop_img, dim, interpolation = cv2.INTER_AREA)
#In the test set we keep track of all faces in an image
if data_type == 'train':
sub_images_data = rgbImg.copy()
else:
sub_images_data.append(rgbImg)
#If no face is detected in the image we will add a NaN
if(len(rects)==0):
if data_type == 'train':
sub_images_data = np.empty(dim + (3,))
sub_images_data[:] = np.nan
if data_type=='test':
nan_images_data = np.empty(dim + (3,))
nan_images_data[:] = np.nan
sub_images_data.append(nan_images_data)
#Here we add the the image(s) to the list we will return
data_images.append(sub_images_data)
#And add the label to the list
if data_type=='train':
data_labels.append(data['class'][cnt])
#Lastly we need to return the correct number of arrays
if data_type=='train':
return np.array(data_images), np.array(data_labels)
else:
return np.array(data_images)
USANDO DLIB
DLIB es un modelo ampliamente utilizado para detectar rostros. En nuestros experimentos, descubrimos que dlib produce mejores resultados que HAAR, aunque notamos que aún se pueden realizar algunas mejoras:
- Si los límites de la cara del rectángulo se mueven fuera de la imagen, tomamos la imagen completa en lugar del recorte de la cara. Se implementa de la siguiente manera:
- si (x> = 0 y y> = 0 y w> = 0 y h> = 0):
- crop_img = clon[y:y+h, x:x+w]
- demás:
- si (x> = 0 y y> = 0 y w> = 0 y h> = 0):
- Para las imágenes de prueba, en lugar de guardar una cara por imagen, guardamos todas las caras para la predicción.
- En lugar de un detector basado en HOG, podemos usar un detector basado en CNN. Como estas mejoras están diseñadas para optimizar su uso con FaceNet, definiremos una nueva detección de rostros corregida.
El bloque de código anterior extrae las caras de la imagen, para muchas imágenes tenemos varias caras, por lo que debemos poner todas esas caras en una lista. Para extraer las caras que estamos usando dlib.cnn_face_detection_model_v1, tenga en cuenta que no debe alimentar imágenes de dimensiones muy grandes a esto, de lo contrario obtendrá un error de memoria de dlib. Si una imagen no tiene una cara, almacena NaN en esos lugares. Apliquemos FaceNet a estas imágenes de datos ahora. El procesamiento previo anterior solo es necesario para los datos de prueba, los datos del tren ya están limpios, lo que se puede ver en las imágenes anteriores. Una vez que hayamos terminado de obtener las incrustaciones de caras a partir de los datos del tren, obtenga las incrustaciones de caras para los datos de prueba, pero primero debe usar el preprocesamiento proporcionado en el bloque de código anterior para extraer caras de los datos de prueba.
def get_embedding(model, face_pixels):
# scale pixel values
face_pixels = face_pixels.astype('float32')
# standardize pixel values across channels (global)
mean, std = face_pixels.mean(), face_pixels.std()
face_pixels = (face_pixels - mean) / std
# transform face into one sample
samples = expand_dims(face_pixels, axis=0)
# make prediction to get embedding
yhat = model.predict(samples)
return yhat[0]
model = load_model('../input/pretrained-models-faces/facenet_keras.h5')
svmtrainX = []
for index, face_pixels in enumerate(newTrainX):
embedding = get_embedding(model, face_pixels)
svmtrainX.append(embedding)
Después de generar las incrustaciones para el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y la prueba, usaremos SVM para la clasificación. ¿Por qué SVM, puede preguntar? Con mucha experiencia, he llegado a saber que las funciones basadas en SVM + DL pueden superar a cualquier otro método, incluso a los métodos de aprendizaje profundo, cuando la cantidad de datos es pequeña.
from sklearn.svm import SVC from sklearn.pipeline import make_pipeline from sklearn.naive_bayes import GaussianNB from sklearn.neural_network import MLPClassifier from sklearn.preprocessing import StandardScaler, MinMaxScaler, Normalizer linear_model = make_pipeline(StandardScaler(), SVC(kernel="rbf", C=1.0, gamma=0.01, probability =True)) linear_model.fit(svmtrainX, svmtrainY)
Una vez que el SVM está entrenado, es hora de hacer algunas pruebas, pero nuestros datos de prueba tienen varias caras en una lista. Entonces, siempre que tengamos a Jesse o Mila en una imagen, ignoraremos la clase 0 y cuando tanto Jesse como Mila estén presentes en una imagen, entonces elegiremos la que nos brinde la mayor precisión.
predicitons=[]
for i in corrected_test_X:
flag=0
if(len(i)==1):
embedding = get_embedding(model, i[0])
tmp_output = linear_model.predict([embedding])
predicitons.append(tmp_output[0])
else:
tmp_sub_pred = []
tmp_sub_prob = []
for j in i:
j= j.astype(int)
embedding = get_embedding(model, j)
tmp_output = linear_model.predict([embedding])
tmp_sub_pred.append(tmp_output[0])
tmp_output_prob = linear_model.predict_log_proba([embedding])
tmp_sub_prob.append(np.max(tmp_output_prob[0]))
if 1 in tmp_sub_pred and 2 in tmp_sub_pred:
index_1 = np.where(np.array(tmp_sub_pred)==1)[0][0]
index_2 = np.where(np.array(tmp_sub_pred)==2)[0][0]
if(tmp_sub_prob[index_1] > tmp_sub_prob[index_2] ):
predicitons.append(1)
else:
predicitons.append(2)
elif 1 not in tmp_sub_pred and 2 not in tmp_sub_pred:
predicitons.append(0)
elif 1 in tmp_sub_pred and 2 not in tmp_sub_pred:
predicitons.append(1)
elif 1 not in tmp_sub_pred and 2 in tmp_sub_pred:
predicitons.append(2)
DISCUSIÓN
Observaciones finales, este es un conjunto de datos muy pequeño, por lo que los resultados pueden cambiar enormemente incluso al agregar o eliminar algunas imágenes. En nuestra prueba descubrimos que nos engañó muchas veces, había alrededor de 20 imágenes en la prueba que fueron predichas incorrectamente por nosotros pero correctamente por nuestro modelo. Confirmamos el resultado previsto buscando esas imágenes en Google.
Las redes neuronales profundas pueden extraer características más significativas que los modelos de aprendizaje automático. Sin embargo, la caída de estas grandes redes es la necesidad de una gran cantidad de datos. Logramos hacer frente a este problema utilizando un modelo previamente entrenado, un modelo que ha sido entrenado en un conjunto de datos mucho más grande para retener el conocimiento sobre cómo codificar imágenes faciales, que luego usamos para nuestros propósitos en este desafío. Además, el ajuste fino de SVM realmente nos ayudó a ir más allá de la precisión del 95%.





