Visión general
- Hadoop se encuentra entre las herramientas más populares en la ingeniería de datos y el espacio de Big Data
- Aquí hay una introducción a todo lo que necesita saber sobre el ecosistema de Hadoop.
Introducción
En la actualidad, tenemos más de 4 mil millones de usuarios en Internet. En términos de datos puros, así es como se ve la imagen:
9.176 Tweets por segundo
1.023 imágenes de Instagram subidas por segundo
5.036 llamadas de Skype por segundo
86,497 búsquedas de Google por segundo
86,302 videos de YouTube vistos por segundo
2.957.983 Correos electrónicos enviados por segundo
y mucho más…
Esa es la cantidad de datos con la que estamos tratando en este momento: ¡increíble! Se estima que a finales de 2020 habremos producido 44 zettabytes de datos. ¡Eso es 44 * 10 ^ 21!
Esta enorme cantidad de datos generados a un ritmo feroz y en todo tipo de formatos es lo que hoy llamamos Big Data. Pero no es factible almacenar estos datos en los sistemas tradicionales que llevamos usando más de 40 años. Para manejar estos datos masivos, necesitamos un marco mucho más complejo que consista no solo en uno, sino en múltiples componentes que manejan diferentes operaciones.

Nos referimos a este marco como Hadoop y junto con todos sus componentes, lo llamamos Ecosistema HadoopEl ecosistema Hadoop es un marco de trabajo de código abierto diseñado para el procesamiento y almacenamiento de grandes volúmenes de datos. Se compone de varios componentes clave, como Hadoop Distributed File System (HDFS) para almacenamiento y MapReduce para procesamiento. Además, incluye herramientas complementarias como Hive, Pig y HBase, que facilitan la gestión, análisis y consulta de datos. Este ecosistema es fundamental en el ámbito del Big Data y la.... Pero debido a que hay tantos componentes dentro de este ecosistema de Hadoop, a veces puede resultar realmente desafiante comprender y recordar realmente lo que hace cada componente y dónde encaja en este gran mundo.
Entonces, en este artículo, intentaremos comprender este ecosistema y desglosar sus componentes.
Tabla de contenido
- Problema con los sistemas tradicionales
- ¿Qué es Hadoop?
- Componentes del ecosistema Hadoop
- HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información... (sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... Hadoop)
- Mapa reducido
- HILO
- HBaseHBase es una base de datos NoSQL diseñada para manejar grandes volúmenes de datos distribuidos en clústeres. Basada en el modelo de columnas, permite un acceso rápido y escalable a la información. HBase se integra fácilmente con Hadoop, lo que la convierte en una opción popular para aplicaciones que requieren almacenamiento y procesamiento de datos masivos. Su flexibilidad y capacidad de crecimiento la hacen ideal para proyectos de big data....
- Cerdo
- Colmena
- SqoopSqoop es una herramienta de código abierto diseñada para facilitar la transferencia de datos entre bases de datos relacionales y el ecosistema Hadoop. Permite la importación de datos desde sistemas como MySQL, PostgreSQL y Oracle a HDFS, así como la exportación de datos desde Hadoop a estas bases de datos. Sqoop optimiza el proceso mediante la paralelización de las operaciones, lo que lo convierte en una solución eficiente para el...
- Canal artificial
- Kafka
- Guardián del zoológico
- Chispa – chispear
- Etapas del procesamiento de Big Data
Problema con los sistemas tradicionales
Por sistemas tradicionales, me refiero a sistemas como bases de datos relacionales y almacenes de datos. Las organizaciones los han estado utilizando durante los últimos 40 años para almacenar y analizar sus datos. Pero los datos que se generan hoy no pueden ser manejados por estas bases de datos por las siguientes razones:
- La mayoría de los datos generados en la actualidad son semiestructurados o no estructurados. Pero los sistemas tradicionales se han diseñado para manejar solo datos estructurados que tienen filas y columnas bien diseñadas
- Las bases de datos de relaciones son escalables verticalmente, lo que significa que debe agregar más procesamiento, memoria y almacenamiento al mismo sistema. Esto puede resultar muy caro
- Los datos almacenados hoy se encuentran en diferentes silos. Reunirlos y analizarlos en busca de patrones puede ser una tarea muy difícil.
Entonces, ¿cómo manejamos Big Data? ¡Aquí es donde entra Hadoop!
¿Qué es Hadoop?
Las personas en Google también enfrentaron los desafíos mencionados anteriormente cuando querían clasificar páginas en Internet. Descubrieron que las bases de datos relacionales eran muy caras e inflexibles. Entonces, se les ocurrió su propia solución novedosa. Ellos crearon el Sistema de archivos de Google (GFS).
GFS es un sistema de archivos distribuido que supera los inconvenientes de los sistemas tradicionales. Se ejecuta en hardware económico y proporciona paralelización, escalabilidad y confiabilidad. Esto sentó el trampolín para la evolución de Apache Hadoop.
Apache Hadoop es un marco de código abierto basado en el sistema de archivos de Google que puede manejar big data en un entorno distribuido. Este entorno distribuido está formado por un grupo de máquinas que trabajan en estrecha colaboración para dar la impresión de una sola máquina en funcionamiento.
Estas son algunas de las propiedades importantes de Hadoop que debe conocer:
- Hadoop es altamente escalable porque maneja los datos de manera distribuida
- En comparación con el escalado vertical en RDBMS, Hadoop ofrece escala horizontal
- Crea y guarda réplicas de datos haciéndolo tolerante a fallos
- Está económico ya que todos los nodos del clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... son hardware básico que no es más que máquinas económicas
- Hadoop utiliza el concepto de localidad de datos para procesar los datos en los nodos en los que están almacenados en lugar de mover los datos a través de la red, reduciendo así el tráfico
- Puede manejar cualquier tipo de datos: estructurado, semiestructurado y no estructurado. Esto es extremadamente importante en la actualidad porque la mayoría de nuestros datos (correos electrónicos, Instagram, Twitter, dispositivos IoT, etc.) no tienen un formato definido.
Ahora, veamos los componentes del ecosistema Hadoop.
Componentes del ecosistema Hadoop
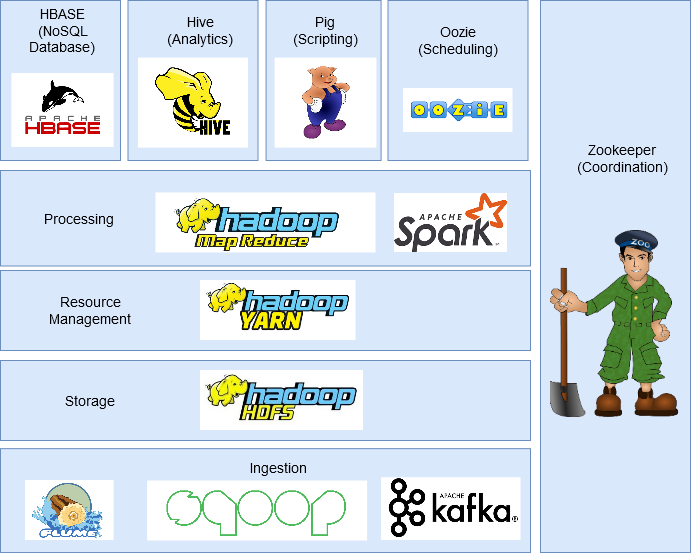
En esta sección, discutiremos los diferentes componentes del ecosistema de Hadoop.
HDFS (sistema de archivos distribuido Hadoop)

Es el componente de almacenamiento de Hadoop que almacena datos en forma de archivos.
Cada archivo se divide en bloques de 128 MB (configurables) y los almacena en diferentes máquinas del clúster.
Tiene una arquitectura maestro-esclavo con dos componentes principales: NodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... de nombre y Nodo de datos.
- Nodo de nombre es el nodo principal y solo hay uno por clúster. Su tarea es saber dónde se encuentra cada bloque que pertenece a un archivo en el clúster.
- Nodo de datos es el nodo esclavoEl "nodo esclavo" es un concepto utilizado en redes y sistemas distribuidos que se refiere a un dispositivo o componente que opera bajo la dirección de un nodo principal o "nodo maestro". Este tipo de arquitectura permite una gestión centralizada, donde el nodo esclavo ejecuta tareas específicas, recopilando datos o ejecutando procesos, mientras el nodo maestro coordina las operaciones de todo el sistema para optimizar el rendimiento y la eficiencia.... que almacena los bloques de datos y hay más de uno por clúster. Su tarea es recuperar los datos cuando sea necesario. Se mantiene en contacto constante con el nodo Nombre a través de latidos.
Mapa reducido

Para manejar Big Data, Hadoop se basa en Algoritmo MapReduce introducido por Google y facilita la distribución de un trabajo y su ejecución en paralelo en un clúster. Básicamente, divide una sola tarea en múltiples tareas y las procesa en diferentes máquinas.
En términos simples, funciona de una manera de divide y vencerás y ejecuta los procesos en las máquinas para reducir el tráfico en la red.
Tiene dos fases importantes: Mapa y Reducir.
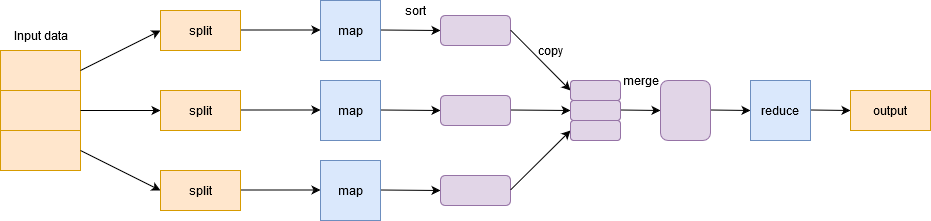
Fase cartográfica filtra, agrupa y ordena los datos. Los datos de entrada se dividen en múltiples divisiones. Cada tarea de mapa trabaja en una división de datos en paralelo en diferentes máquinas y genera un par clave-valor. La salida de esta fase es actuada por el reducir la tarea y es conocido como el Reducir fase. Agrega los datos, resume el resultado y lo almacena en HDFS.
HILO

YARNYARN es un gestor de paquetes para JavaScript que permite la instalación y gestión eficiente de dependencias en proyectos de desarrollo. Desarrollado por Facebook, se caracteriza por su rapidez y seguridad en comparación con otros gestores. YARN utiliza un sistema de caché para optimizar las instalaciones y proporciona un archivo de bloqueo para garantizar la consistencia de las versiones de las dependencias en diferentes entornos de desarrollo.... o Yet Another Resource Negotiator administra los recursos en el clúster y administra las aplicaciones a través de Hadoop. Permite que los datos almacenados en HDFS sean procesados y ejecutados por varios motores de procesamiento de datos, como procesamiento por lotes, procesamiento de flujo, procesamiento interactivo, procesamiento de gráficos y muchos más. Esto aumenta la eficiencia con el uso de YARN.
HBase

HBase es una base de datos NoSQLLas bases de datos NoSQL son sistemas de gestión de datos que se caracterizan por su flexibilidad y escalabilidad. A diferencia de las bases de datos relacionales, utilizan modelos de datos no estructurados, como documentos, clave-valor o gráficos. Son ideales para aplicaciones que requieren manejo de grandes volúmenes de información y alta disponibilidad, como en el caso de redes sociales o servicios en la nube. Su popularidad ha crecido en... basada en columnas. Se ejecuta sobre HDFS y puede manejar cualquier tipo de datos. Permite el procesamiento en tiempo real y operaciones de lectura / escritura aleatorias que se realizan en los datos.
Cerdo

PigEl cerdo, un mamífero domesticado de la familia Suidae, es conocido por su versatilidad en la agricultura y la producción de alimentos. Originario de Asia, su cría se ha extendido por todo el mundo. Los cerdos son omnívoros y poseen una alta capacidad de adaptación a diversos hábitats. Además, juegan un papel importante en la economía, proporcionando carne, cuero y otros productos derivados. Su inteligencia y comportamiento social también son... fue desarrollado para analizar grandes conjuntos de datos y supera la dificultad de escribir mapas y reducir funciones. Consta de dos componentes: Pig Latin y Pig Engine.
Pig Latin es el lenguaje de secuencias de comandos similar a SQL. Pig Engine es el motor de ejecución en el que se ejecuta Pig Latin. Internamente, el código escrito en Pig se convierte en funciones de MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data.... y lo hace muy fácil para los programadores que no dominan Java.
Colmena

HiveHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.... es un sistema de almacenamiento de datos distribuido desarrollado por Facebook. Permite una fácil lectura, escritura y administración de archivos en HDFS. Tiene su propio lenguaje de consulta para el propósito conocido como Hive Querying Language (HQL), que es muy similar a SQL. Esto hace que sea muy fácil para los programadores escribir funciones de MapReduce usando consultas HQL simples.
Sqoop

Muchas aplicaciones aún almacenan datos en bases de datos relacionales, lo que las convierte en una fuente de datosUna "fuente de datos" se refiere a cualquier lugar o medio donde se puede obtener información. Estas fuentes pueden ser tanto primarias, como encuestas y experimentos, como secundarias, como bases de datos, artículos académicos o informes estadísticos. La elección adecuada de una fuente de datos es crucial para garantizar la validez y la fiabilidad de la información en investigaciones y análisis.... muy importante. Por lo tanto, Sqoop juega un papel importante en traer datos de bases de datos relacionales a HDFS.
Los comandos escritos en Sqoop se convierten internamente en tareas de MapReduce que se ejecutan en HDFS. Funciona con casi todas las bases de datos relacionales como MySQL, Postgres, SQLite, etc. También se puede utilizar para exportar datos de HDFS a RDBMS.
Canal artificial

FlumeFlume es un software de código abierto diseñado para la recolección y transporte de datos. Utiliza un enfoque basado en flujos, lo que permite mover datos de diversas fuentes hacia sistemas de almacenamiento como Hadoop. Su arquitectura modular y escalable facilita la integración con múltiples orígenes de datos, lo que lo convierte en una herramienta valiosa para el procesamiento y análisis de grandes volúmenes de información en tiempo real.... es un servicio de código abierto, confiable y disponible que se utiliza para recopilar, agregar y mover de manera eficiente grandes cantidades de datos de múltiples fuentes de datos a HDFS. Puede recopilar datos en tiempo real y en modo por lotes. Tiene una arquitectura flexible y es tolerante a fallas con múltiples mecanismos de recuperación.
Kafka

Hay muchas aplicaciones que generan datos y una cantidad proporcional de aplicaciones que consumen esos datos. Pero conectarlos individualmente es una tarea difícil. Ahí es donde entra Kafka. Se encuentra entre las aplicaciones que generan datos (productores) y las aplicaciones que consumen datos (consumidores).
Kafka está distribuido y tiene particionado, replicaciónLa replicación es un proceso fundamental en biología y ciencia, que se refiere a la duplicación de moléculas, células o información genética. En el contexto del ADN, la replicación asegura que cada célula hija reciba una copia completa del material genético durante la división celular. Este mecanismo es crucial para el crecimiento, desarrollo y mantenimiento de los organismos, así como para la transmisión de características hereditarias en las generaciones futuras.... y tolerancia a fallas incorporados. Puede manejar datos de transmisión y también permite a las empresas analizar datos en tiempo real.
Oozie

OozieOozie es un sistema de gestión de trabajos orientado a flujos de datos, diseñado para coordinar trabajos en Hadoop. Permite a los usuarios definir y programar trabajos complejos, integrando tareas de MapReduce, Pig, Hive y otros. Oozie utiliza un enfoque basado en XML para describir los flujos de trabajo y su ejecución, facilitando la orquestación de procesos en entornos de big data. Su funcionalidad mejora la eficiencia en el procesamiento... es un sistema de programación de flujo de trabajo que permite a los usuarios vincular trabajos escritos en varias plataformas como MapReduce, Hive, Pig, etc. Con Oozie puede programar un trabajo por adelantado y puede crear una canalización de trabajos individuales para que se ejecuten secuencialmente o en paralelo a lograr una tarea más grande. Por ejemplo, puede usar Oozie para realizar operaciones ETL en datos y luego guardar la salida en HDFS.
Guardián del zoológico

En un clúster de Hadoop, coordinar y sincronizar nodos puede ser una tarea desafiante. Por tanto, Zookeeper"Zookeeper" es un videojuego de simulación lanzado en 2001, donde los jugadores asumen el rol de un cuidador de zoológico. La misión principal consiste en gestionar y cuidar diversas especies de animales, asegurando su bienestar y la satisfacción de los visitantes. A lo largo del juego, los usuarios pueden diseñar y personalizar su zoológico, enfrentando desafíos que incluyen la alimentación, el hábitat y la salud de los animales.... es la herramienta perfecta para resolver el problema.
Es un servicio de código abierto, distribuido y centralizado para mantener la información de configuración, nombrar, proporcionar sincronización distribuida y proporcionar servicios de grupo en todo el clúster.
Chispa – chispear

Spark es un marco alternativo a Hadoop construido en Scala, pero admite diversas aplicaciones escritas en Java, Python, etc. En comparación con MapReduce, proporciona procesamiento en memoria que representa un procesamiento más rápido. Además del procesamiento por lotes que ofrece Hadoop, también puede manejar el procesamiento en tiempo real.
Además, Spark tiene su propio ecosistema:

- Spark Core es el motor de ejecución principal para Spark y otras API construidas sobre él
- API de Spark SQL permite consultar datos estructurados almacenados en DataFrames o tablas de Hive
- API de transmisión permite que Spark maneje datos en tiempo real. Se puede integrar fácilmente con una variedad de fuentes de datos como Flume, Kafka y Twitter.
- MLlib es una biblioteca de aprendizaje automático escalable que le permitirá realizar tareas de ciencia de datos mientras aprovecha las propiedades de Spark al mismo tiempo
- GraphX es un motor de cálculo de gráficos que permite a los usuarios construir, transformar y razonar de forma interactiva sobre datos estructurados en gráficos a escala y viene con una biblioteca de algoritmos comunes
Etapas del procesamiento de Big Data
Con tantos componentes dentro del ecosistema de Hadoop, puede resultar bastante intimidante y difícil entender lo que hace cada componente. Por lo tanto, es más fácil agrupar algunos de los componentes en función de dónde se encuentran en la etapa de procesamiento de Big Data.
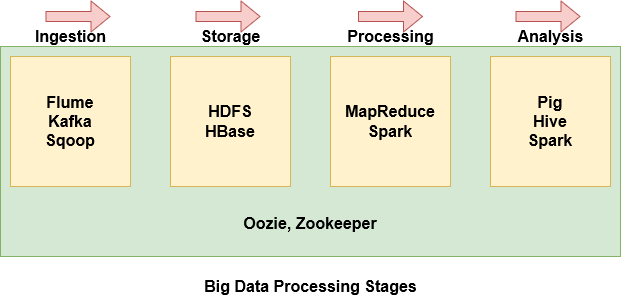
- Flume, Kafka y Sqoop se utilizan para ingerir datos de fuentes externas en HDFS
- HDFS es la unidad de almacenamiento de Hadoop. Incluso los datos importados de Hbase se almacenan en HDFS
- MapReduce y Spark se utilizan para procesar los datos en HDFS y realizar varias tareas
- Pig, Hive y Spark se utilizan para analizar los datos.
- Oozie ayuda a programar tareas. Dado que funciona con varias plataformas, se utiliza en todas las etapas.
- Zookeeper sincroniza los nodos del clúster y también se utiliza en todas las etapas.
Notas finales
Espero que este artículo haya sido útil para comprender Big Data, por qué los sistemas tradicionales no pueden manejarlo y cuáles son los componentes importantes del ecosistema Hadoop.
Le animo a que consulte algunos artículos más sobre Big Data que pueden resultarle útiles:





