Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
El primer paso en un proyecto de ciencia de datos es resumir, describir y visualizar los datos. Trate de conocer diferentes aspectos de los datos y sus atributos. Los mejores modelos son creados por aquellos que entienden sus datos.
Explore las características de los datos y sus atributos utilizando estadísticas descriptivas. Los conocimientos y el resumen numérico que obtiene de las estadísticas descriptivas lo ayudan a comprender mejor o estar en condiciones de manejar los datos de manera más eficiente para las tareas de aprendizaje automático.
La estadística descriptiva es el proceso predeterminado en el análisis de datos. El análisis de datos exploratorios (EDA) no está completo sin un análisis estadístico descriptivo.
Entonces, en este artículo, explicaré los atributos del conjunto de datos usando Estadística descriptiva. Se divide en dos partes: Medida de puntos de datos centrales y Medida de dispersión. Antes de comenzar con nuestro análisis, debemos completar el proceso de recolección y limpieza de datos.
Recolección de datos y limpieza de datos
Recopilaremos datos de aquí. Solo usaré datos de prueba para análisis. Puede combinar datos de prueba y de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... para su análisis. Aquí hay un código para el proceso de limpieza de datos de los datos del tren.
Quitar del código
- La columna Item_Weight y Outlet_Size tienen valores nulos. Estas son las opciones:
-
- eliminar las filas que contienen valores nulos
- eliminar las columnas que contienen valores nulos
- o reemplace los valores nulos.
- Las primeras 2 opciones son factibles cuando los datos tienen filas en millones o el recuento de valores es pequeño. Entonces, elegiré la tercera opción para resolver el problema del valor nulo.
- Primero, busque el Item_Identifier y su Item_Weight correspondiente. Luego reemplace lo que falta / nulo en Item_Weight con el Item_weight conocido del respectivo item_identifier.
- Como sabemos, la visibilidad de los artículos en una tienda puede ser cercana a cero pero no cero. Entonces, consideramos 0 como un valor nulo y seguimos el paso anterior para Item_Visibility.
- Outlet_Size no tiene mucha importancia en nuestro análisis y predicción de modelos. Entonces, dejo caer esta columna.
- Reemplace LF y reg en la columna Item_fat_content con Low Fat y Regular Fat.
- Calcule la antigüedad de las tiendas y guarde estos valores en la columna Outlet_years y suelte la columna Outlet_Establishment_year.
Comencemos con el análisis de datos de Estadística descriptiva.
La medida del punto de datos central
Encontrar el centro de datos numéricos y categóricos utilizando la media, la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... y la moda se conoce como Medida del punto de datos central. El cálculo de los valores centrales de los datos de la columna por media, mediana y moda son diferentes entre sí.
Bien, entonces, calculemos la media, la mediana, el recuento y la moda de los atributos del conjunto de datos usando Python.
- Contar
El recuento no ayuda directamente a encontrar el centro de los atributos del conjunto de datos. Pero se utiliza en el cálculo de la media, la mediana y la moda. Calculamos el recuento total en cada categoría de las variables categóricas. También calcula el recuento total de datos de columnas numéricas.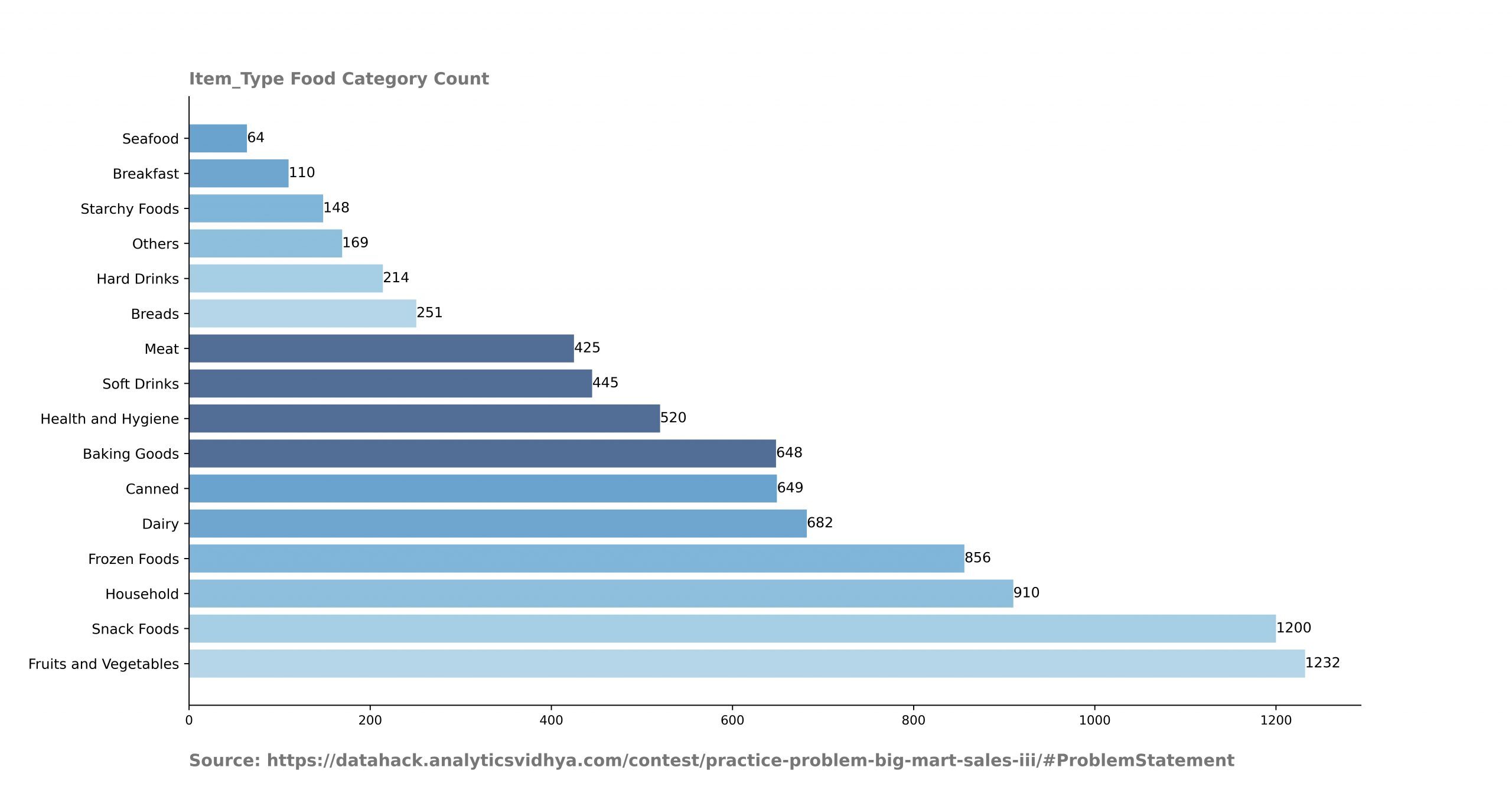
Quite del código.
- Recorra las columnas categóricas para trazar la categoría y su recuento.
Análisis de la salida.
- Estos recuentos le ayudan a averiguar si los datos están equilibrados o no. A partir de este gráfico, puedo decir que las filas de la categoría de frutas y verduras son mucho más que la categoría de mariscos.
- También podemos asumir que las ventas en la categoría de frutas y verduras son mucho más que en la categoría de mariscos.
-
Significar
La suma de los valores presentes en la columna dividida por el total de filas de esa columna se conoce como media. También se conoce como promedio.
Usar train.mean () para calcular el valor medio de las columnas numéricas del conjunto de datos del tren.
Aquí hay un código para columnas categóricas del conjunto de datos de trenes.
print(train[['Item_Outlet_Sales','Outlet_Type']].groupby(['Outlet_Type']).agg({'Item_Outlet_Sales':'mean'}))Análisis de la salida
- La edad promedio de salida es de 15 años.
- Las ventas medias de outlet son 2100.
- La categoría de supermercado tipo 3 de Outlet_Type tiene muchas más ventas que la categoría de tienda de comestibles.
- También podemos suponer que la categoría de supermercado es más popular que la categoría de tienda de comestibles.
-
Mediana
El valor central de un atributo se conoce como mediana. ¿Cómo calculamos el valor mediano? Primero, ordene los datos de la columna en orden ascendente o descendente. Luego encuentra el total de filas y luego divídelo entre 2.
Ese valor de salida es la mediana de esa columna.
El valor mediano divide los puntos de datos en dos partes. Eso significa que el 50% de los puntos de datos están presentes por encima de la mediana y el 50% por debajo.
Generalmente, los valores de la mediana y la media son diferentes para los mismos datos.
La mediana no se ve afectada por los valores atípicos. Debido a los valores atípicos, la diferencia entre los valores medios y medianos aumenta.
Usar train.median () para calcular el valor medio de las columnas numéricas del conjunto de datos del tren.
Aquí hay un código para columnas categóricas del conjunto de datos de trenes.
print(train[['Item_Outlet_Sales','Outlet_Type']].groupby(['Outlet_Type']).agg({'Item_Outlet_Sales':'median'}))Análisis de salida
- La mayoría de las observaciones son las mismas que las del valor medio.
- La diferencia en el valor medio y mediano se debe a valores atípicos. También puede observar esta diferencia en variables categóricas.
- Modo
La moda es ese punto de datos cuyo recuento es el máximo en una columna. Solo hay un valor medio y mediano para cada columna. Pero los atributos pueden tener más de un valor de modo. Usar train.mode () para calcular el valor medio de las columnas numéricas del conjunto de datos del tren. Aquí hay un código para las columnas categóricas del conjunto de datos del tren.print(train[['Item_Outlet_Sales', 'Outlet_Type', 'Outlet_Identifier', 'Item_Identifier']].groupby(['Outlet_Type']).agg(lambda x:x.value_counts().index[0]))
Análisis de salida
- Outlet_Type tiene un valor de modo. Tipo de supermercado 1. La categoría de tipo de supermercado 1 artículo más vendido o el valor de modo es FDZ15.
- Item_Identifier FDH50 es el artículo más vendido entre la categoría Outlet_Type.
Medidas de dispersión
Una medida de dispersión explica cuán diversos son los valores de los atributos en el conjunto de datos. También se conoce como medida de propagación. A partir de esta estadística, llega a saber cómo y por qué los datos se propagan de un punto a otro.
Estas son las estadísticas que entran en la medida de dispersión.
- Distancia
- Percentiles o cuartiles
- Desviación Estándar
- Diferencia
- Oblicuidad
-
Distancia
La diferencia entre el valor máximo y el valor mínimo en una columna se conoce como rango.
Aquí hay un código para calcular el rango.
for i in num_col: print(f"Column: {i} Max_Value: {max(train[i])} Min_Value: {min(train[i])} Range: {round(max(train[i]) - min(train[i]),2)}")También puede calcular el rango de columnas categóricas. Aquí hay un código para averiguar los valores mínimos y máximos en cada categoría de salida.
Análisis de salida
- El rango de Item_MRP y Item_Outlet_sales es alto y puede necesitar transformación.
- Existe una gran variación en Item_MRP en la categoría de supermercado tipo 3.
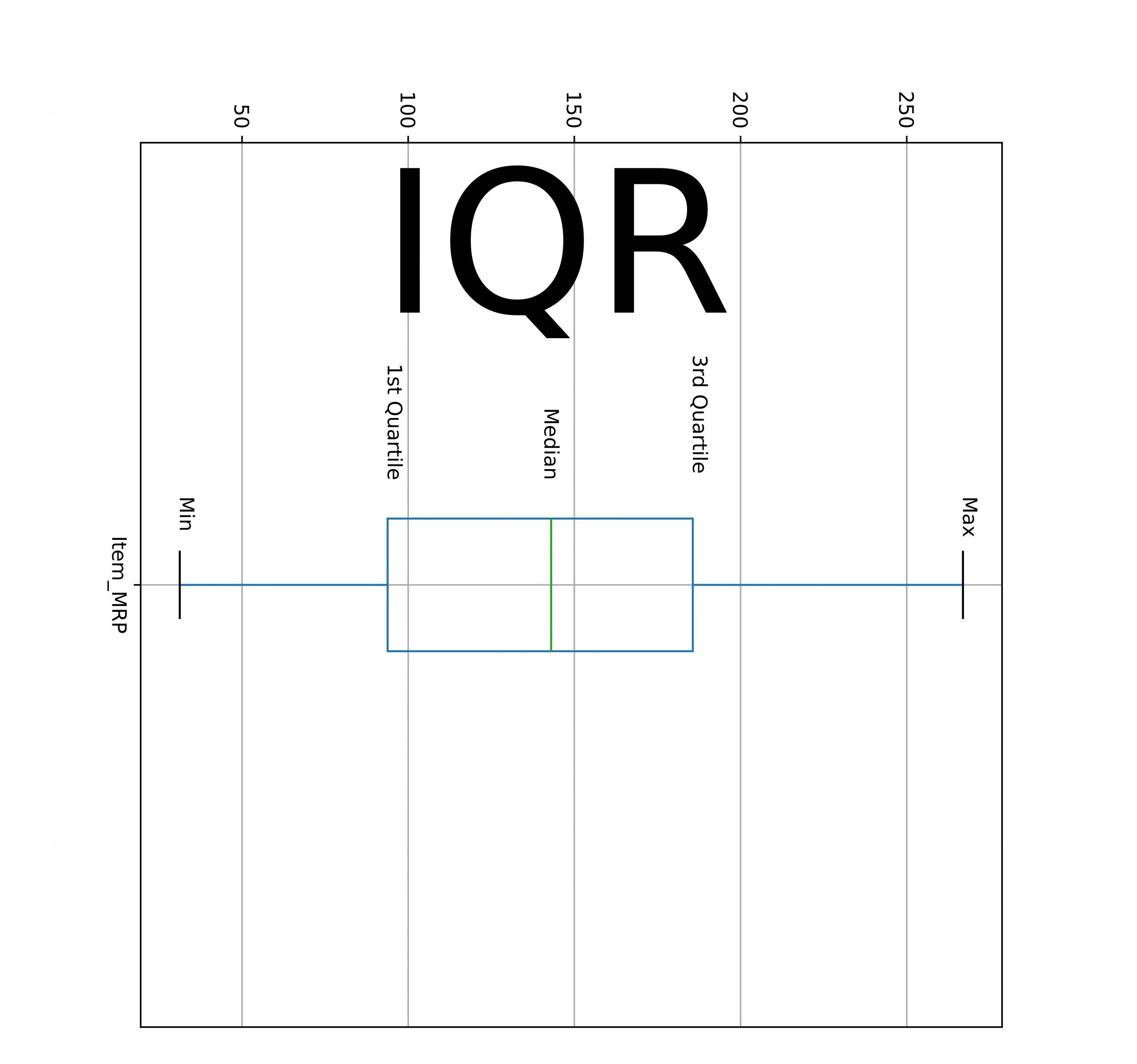
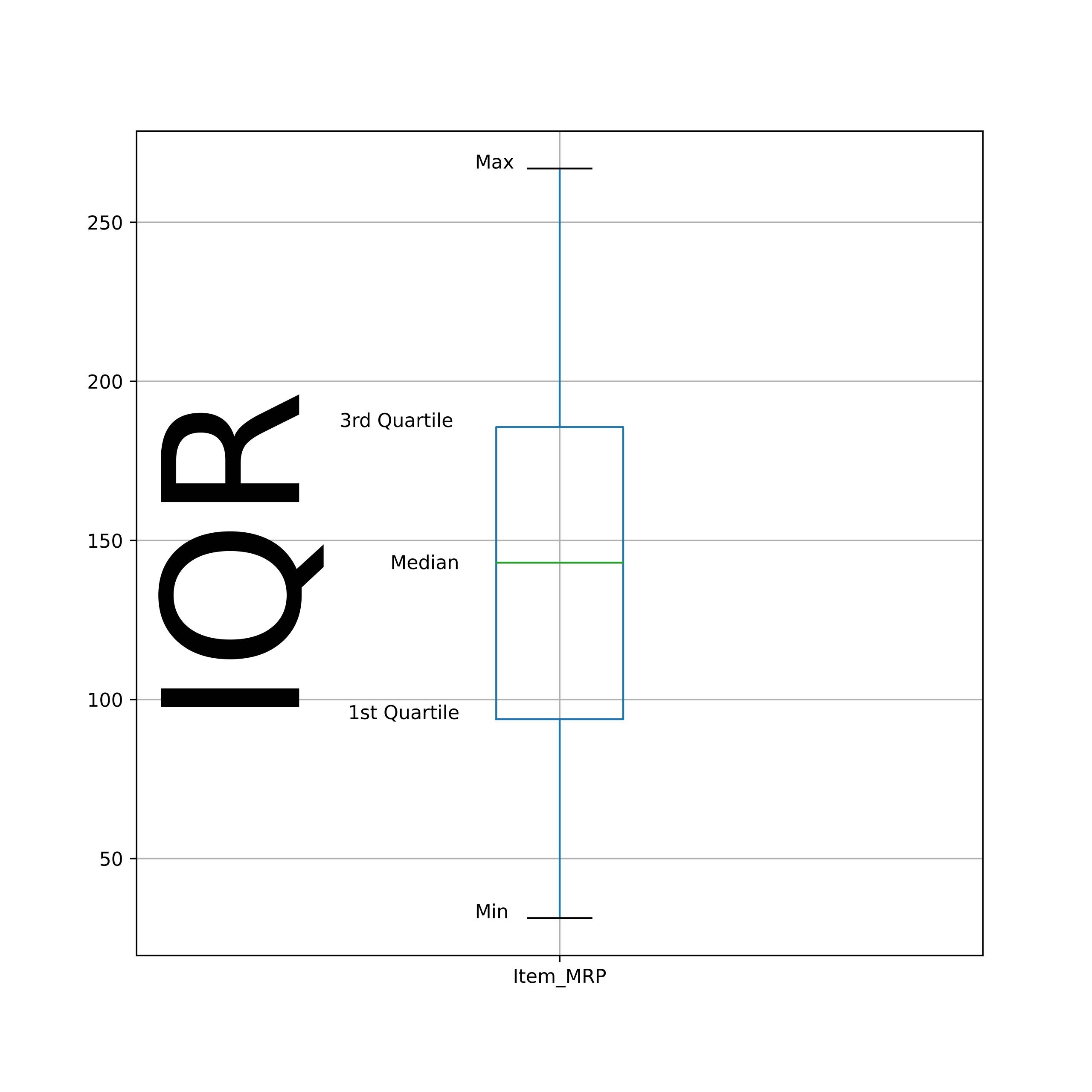
- Percentiles o cuartilesPodemos describir la distribución de los valores de las columnas calculando el resumen de varios percentiles. La mediana también se conoce como el percentil 50 de los datos. Aquí hay un percentil diferente.
- El valor mínimo es igual al percentil 0.
- El valor máximo equivale al percentil 100.
- El primer cuartil equivale al percentil 25.
- El tercer cuartil equivale al percentil 75.
Aquí hay un código para calcular los cuartiles.
La diferencia entre los 3rd y el 1S t El cuartil también se conoce como intercuartil (IQR). Además, los puntos de datos máximos se incluyen en IQR.
-
Desviación Estándar
El valor de la desviación estándar nos dice cuánto se desvían todos los puntos de datos del valor medio. La desviación estándar se ve afectada por los valores atípicos porque utiliza la media para su cálculo.
Aquí hay un código para calcular la desviación estándar.
for i in num_col: print(i , round(train[i].std(),2))Los pandas también tienen un atajo para calcular todos los valores estadísticos anteriores.
Train.describe()
- DiferenciaLa varianza es el cuadrado de la desviación estándar. En el caso de valores atípicos, el valor de la varianza se vuelve grande y notable. Por lo tanto, también se ve afectado por valores atípicos. Aquí hay un código para calcular la varianza
for i in num_col: print(i , round(train[i].var(),2))Análisis de salida.
- Las columnas Item_MRP y Item_Outlet_sales tienen una gran variación debido a valores atípicos.
-
Oblicuidad
Idealmente, la distribución de datos debería tener la forma de Gauss (curva de campana). Pero prácticamente, las formas de los datos están sesgadas o tienen asimetría. Esto se conoce como asimetría en los datos.
Puede calcular la asimetría de los datos del tren mediante train.skew (). El valor de sesgo puede ser negativo (izquierda) o positivo (derecha). Su valor debe ser cercano a cero.
Notas finales
Estas son las estadísticas a las que recurrimos cuando realizamos análisis de datos exploratorios en el conjunto de datos. Debe prestar atención a los valores generados por estas estadísticas y preguntar por qué este número. Estas estadísticas nos ayudan a determinar los atributos para la transformación de datos y la eliminación de variables del procesamiento posterior.
La biblioteca Pandas tiene funciones realmente buenas que lo ayudan a obtener valores de Estadísticas descriptivas en una línea de código.





