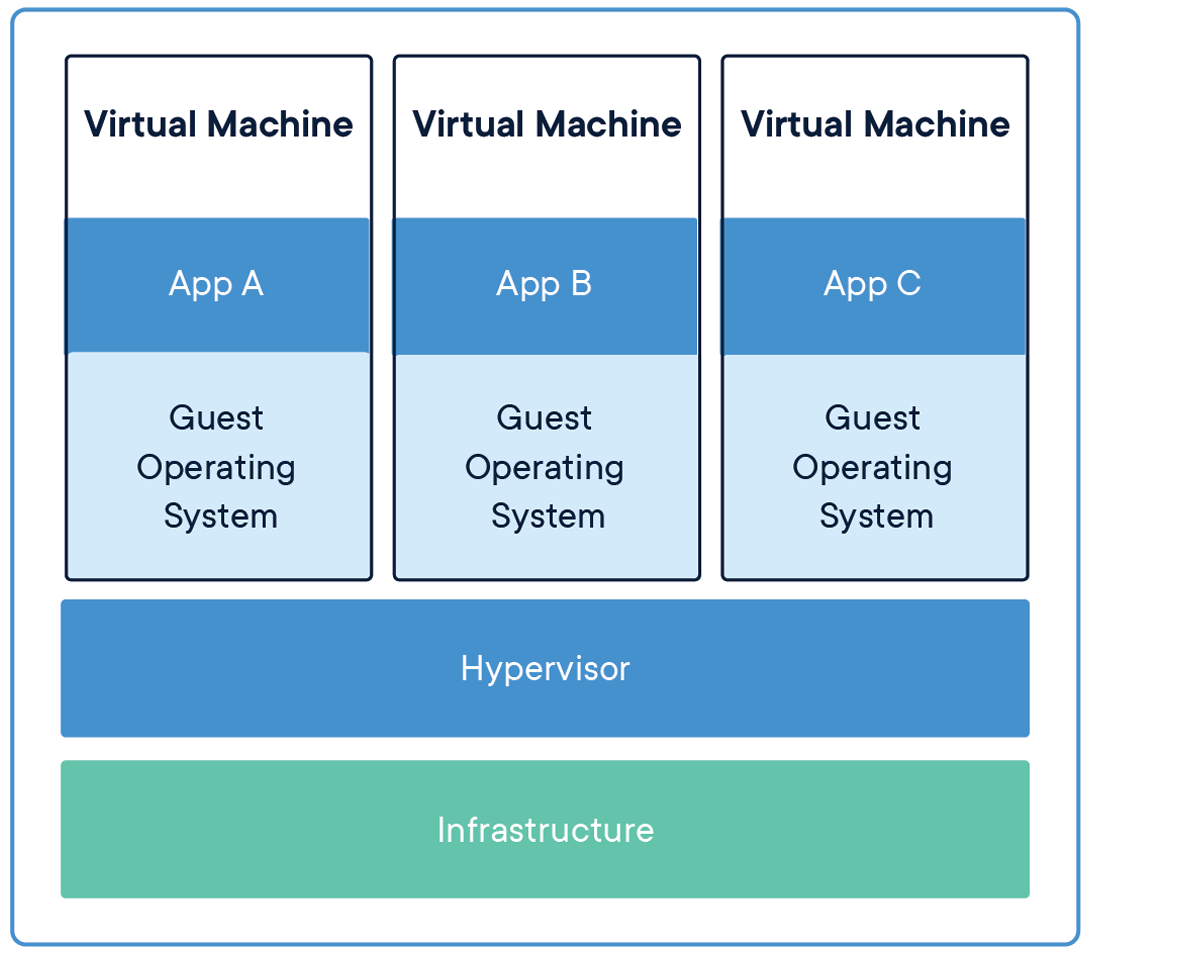
Hace años, las máquinas virtuales (VM) eran la herramienta principal para alojar una aplicación, ya que encapsula el código y los archivos de configuración junto con las dependencias necesarias para ejecutar una aplicación. Proporciona la misma funcionalidad que la de un sistema físico.
Para ejecutar múltiples aplicaciones, tenemos que poner en marcha múltiples máquinas virtuales y para administrar un conjunto de máquinas virtuales, necesitamos un hipervisor.
Fuente: Infraestructura de intercambio de aplicaciones
Pasar de máquinas virtuales a contenedores
La limitación de este mecanismo (máquinas virtuales) es que no es eficiente, ya que ejecutar múltiples aplicaciones replicará sus propios sistemas operativos, lo que consume una gran cantidad de recursos y, a medida que aumentan las aplicaciones en ejecución, necesitamos más espacio para asignar los recursos.
Otra desventaja de esto es, supongamos que tenemos que compartir nuestra aplicación con otros, y cuando intentan ejecutar la aplicación la mayor parte del tiempo no se ejecuta debido a problemas de dependencias y para eso, solo tenemos que decir que “Funciona en mi computadora portátil / sistema“. Entonces, para que otros ejecuten las aplicaciones, deben configurar el mismo entorno en el que se ejecutó en el lado del host, lo que significa mucha configuración manual e instalación de componentes.
La solución a estas limitaciones es una tecnología llamada Contenedores.
La creación de modelos de aprendizaje automático en Jupyter Notebooks no es la solución final para ningún POC / proyecto, debemos llevarlo a producción para resolver problemas de la vida real en tiempo real.
Entonces, el primer paso es empaquetar / empaquetar nuestra aplicación para que podamos ejecutar nuestra aplicación en cualquier plataforma en la nube para obtener ventajas de servicios administrados y autoescalado y confiabilidad, y muchos más.
Para empaquetar nuestra aplicación necesitamos herramientas como Docker. Así que pongámonos a trabajar en herramientas increíbles y veamos la magia.
Contenedores
Un contenedor es una unidad estándar de software que empaqueta el código y todas sus dependencias para que la aplicación se ejecute de forma rápida y confiable de un entorno informático a otro.
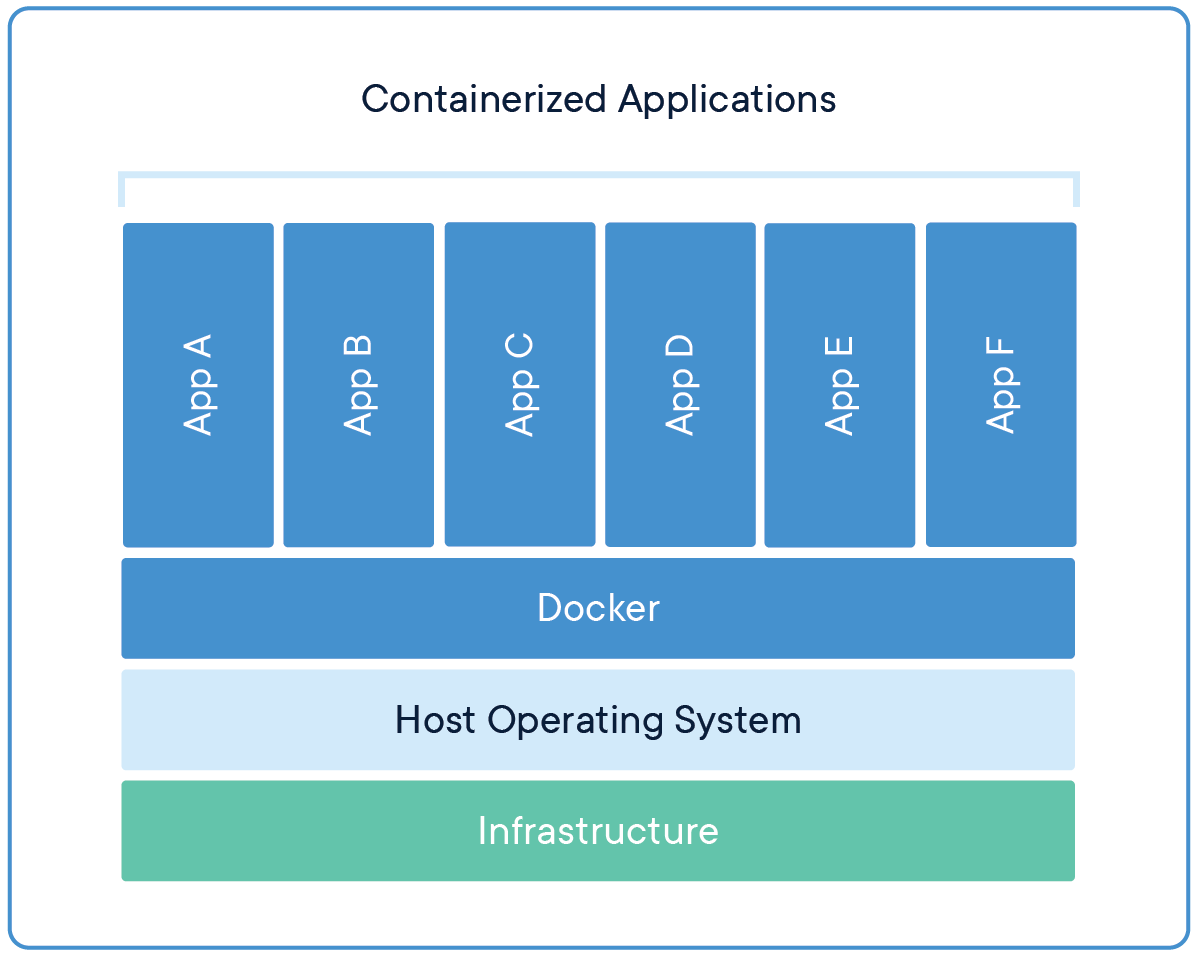
Ahora, varias máquinas virtuales se reemplazan con varios contenedores que se ejecutan en un único sistema operativo host. Las aplicaciones que se ejecutan en contenedores están completamente aisladas y tienen acceso al sistema de archivos, los recursos y los paquetes del sistema operativo. Para la creación y ejecución de contenedores, necesitamos herramientas de gestión de contenedores, como Estibador.
Fuente: Aplicaciones que comparten el sistema operativo
Estibador
Docker es una herramienta de administración de contenedores que empaqueta el código de la aplicación, la configuración y las dependencias en una imagen portátil que se puede compartir y ejecutar en cualquier plataforma o sistema. Con Docker, podemos contener múltiples aplicaciones y ejecutarlas en la misma máquina / sistema, ya que todas compartirán los mismos servicios del kernel del sistema operativo, usan menos recursos que las máquinas virtuales (VM).
Una imagen de contenedor de Docker es un paquete de software ligero, independiente y ejecutable que incluye todo lo necesario para ejecutar una aplicación: código, tiempo de ejecución, herramientas del sistema, bibliotecas del sistema y configuraciones.
Las imágenes de contenedor se convierten en contenedores en tiempo de ejecución y, en el caso de los contenedores de Docker, las imágenes se convierten en contenedores cuando se ejecutan en Docker Engine.
Motor de Docker
Docker Engine es el tiempo de ejecución del contenedor que se ejecuta en varios sistemas operativos Linux (CentOS, Debian, Fedora, Oracle Linux, RHEL, SUSE y Ubuntu) y Windows Server.
Docker Engine permite que las aplicaciones en contenedores se ejecuten en cualquier lugar de forma coherente en cualquier infraestructura, resolviendo el «infierno de la dependencia» para los desarrolladores y equipos de operaciones, y eliminando el «¡Funciona en mi computadora portátil!» problema.
Los contenedores de Docker que se ejecutan en Docker Engine son:
- Estándar: Docker creó el estándar de la industria para contenedores, por lo que podrían ser portátiles en cualquier lugar.
- Ligero: Los contenedores comparten el kernel del sistema operativo de la máquina y, por lo tanto, no requieren un sistema operativo por aplicación, lo que genera una mayor eficiencia del servidor y reduce los costos del servidor y las licencias.
- Seguro: Las aplicaciones son más seguras en contenedores y Docker proporciona las capacidades de aislamiento predeterminadas más sólidas de la industria.
Instalación de Docker
Docker es una plataforma abierta para desarrollar, enviar y ejecutar aplicaciones. Docker nos permite separar nuestras aplicaciones de nuestra infraestructura para que podamos entregar software rápidamente.
Podemos descargar e instalar Docker en múltiples plataformas. Consulte el Docker oficial página para instalar Docker según el sistema operativo de su sistema local.
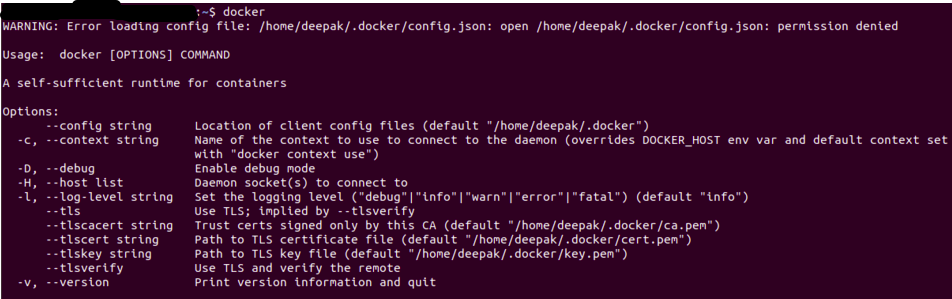
Una vez que haya instalado Docker, puede verificar que la instalación se haya realizado correctamente ejecutando el estibador comando en el terminal / símbolo del sistema.
La salida será similar a la siguiente, si obtiene un error de permiso, intente ejecutarlo en el modo de usuario root (en Linux se usa Sudo Docker).
Fuente: Autor
Dockerfile
Un archivo simple que consta de instrucciones para crear una imagen de Docker. Cada instrucción en un archivo docker es un comando / operación, por ejemplo, qué sistema operativo usar, qué dependencias instalar o cómo compilar el código, y muchas de esas instrucciones que actúan como una capa.
La mejor parte es que todas las capas se almacenan en caché y si modificamos algunas instrucciones en el Dockerfile, durante el proceso de compilación, simplemente se reconstruirá la capa modificada.
Un Dockerfile de muestra se verá como a continuación
FROM ubuntu:18.04 WORKDIR /app COPY . /app RUNpip install -r requirements.txtEXPOSE 5000 CMD python app.py
Cada instrucción crea una capa:
- DE crea una capa a partir de la imagen base, aquí hemos usado ubuntu: 18.04 Docker image
- WORKDIR especifica el directorio de trabajo
- COPIAR agrega archivos del directorio actual de su cliente Docker o sistema host, aquí estamos agregando archivos de directorio actual al directorio de la aplicación del contenedor
- CORRER especifica qué comandos ejecutar dentro del contenedor, aquí ejecutando el comando pip para instalar las dependencias del archivo requirements.txt
- EXPONER especifica qué puerto exponer nuestra aplicación, aquí es 5000
- CMD especifica qué comando ejecutar al inicio del contenedor
Imagen de Docker
Una vez que se crea un archivo de la ventana acoplable, podemos crear una imagen de la ventana acoplable a partir de él. Docker Image proporciona el entorno de ejecución para una aplicación, que incluye todo el código, los archivos de configuración y las dependencias necesarios.
Una imagen de Docker consta de capas de solo lectura, cada una de las cuales representa una instrucción de Dockerfile. Las capas se apilan y cada una es un delta de los cambios de la capa anterior.
Podemos construir una imagen de la ventana acoplable con un archivo de la ventana acoplable usando el compilación de docker mando.
Una vez que se crea la imagen de la ventana acoplable, podemos probarla usando el Docker ejecutar comando, que creará un contenedor utilizando la imagen de la ventana acoplable y ejecutará la aplicación.
Registro de Docker
Una vez que la imagen de la ventana acoplable está construida y probada, podemos compartirla con otros para que puedan usar nuestra aplicación. Para eso, necesitamos enviar la imagen de la ventana acoplable al registro de imágenes de la ventana acoplable pública, como DockerHub, Google Container Registry (GCR) o cualquier otra plataforma de registro.
También podemos enviar nuestras imágenes de la ventana acoplable a registros privados para restringir el acceso de la imagen de la ventana acoplable.
Aplicación de aprendizaje automático
La aplicación de aprendizaje automático constará de un flujo de trabajo completo desde el procesamiento de la entrada, la ingeniería de funciones hasta la generación de resultados. Veremos una aplicación de Análisis de Sentimiento simple, que pondremos en contenedor usando Docker y enviaremos esa aplicación al DockerHub para que esté disponible para otros.
Análisis de los sentimientos
No entraremos en detalles acerca de las aplicaciones de aprendizaje automático, solo una descripción general, pondremos en contenedor una aplicación de análisis de sentimientos de Twitter. Los archivos de código y datos se pueden encontrar en Github.
Puede clonar esta aplicación o puede contener su propia aplicación, el proceso será el mismo.
El repositorio de git tendrá los siguientes archivos
- app.py: Aplicación principal
- train.py: Script para entrenar y guardar el modelo entrenado
- sentiment.tsv: archivo de datos
- requirements.txt: contiene los paquetes / dependencias requeridos
- Dockerfile: para crear la imagen de la ventana acoplable
- Carpeta de plantillas: contiene nuestra página web para la aplicación
- carpeta modelo: contiene nuestro modelo entrenado
A continuación se muestra cómo requirements.txt se verá, también podemos especificar la versión para cada biblioteca que necesitamos instalar
numpy pandas scikit-learn flask nltk regex
En nuestro app.py, cargaremos nuestro modelo entrenado y haremos el mismo preprocesamiento que hicimos en el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.....
La aplicación Flask servirá para dos puntos finales, hogar, y predecir
@app.route('/')
def home():
return render_template('home.html')
@app.route('/predict',methods=['POST'])
def predict():
if request.method == 'POST':
message = request.form['message']
clean_test = remove_pattern(test,"@[w]*")
tokenized_clean_test = clean_test.split()
stem_tokenized_clean_test = [stemmer.stem(i) for i in tokenized_clean_test]
message=" ".join(stem_tokenized_clean_test)
data = [message]
data = cv.transform(data)
my_prediction = clf.predict(data)
return render_template('result.html',prediction = my_prediction)
Tenemos que cargar el modelo entrenado, el vectorizador y el lematizador (utilizado en el entrenamiento) y también hemos configurado para recibir solicitudes en el puerto 5000 en localhost (0.0.0.0)





