Introducción
GraphLab supuso un avance inesperado en mi plan de aprendizaje. Después de todo, ‘Suceden cosas buenas cuando se espera que sucedan menos’. Todo empezó con el final de Hack de datos de Black Friday. De 1200 participantes, obtuvimos nuestros ganadores y sus interesantes soluciones.
Los leí y los analicé. Me di cuenta de que me había perdido una increíble herramienta de aprendizaje automático. Una exploración rápida me dijo que esta herramienta tiene un inmenso potencial para reducir nuestros dolores de modelado de aprendizaje automático. Entonces, decidí explorarlo más a fondo. Ahora he dedicado unos días a comprender su ciencia y sus métodos lógicos de uso. Para mi sorpresa, no fue difícil de entender.
¿Estabas intentando mejorar tu modelo de aprendizaje automático? ¿Pero falló en su mayoría? Pruebe esta herramienta avanzada de aprendizaje automático. Un mes de prueba es gratuito y la suscripción de 1 año está disponible GRATIS para uso académico. Luego, puede comprar una suscripción para los años siguientes.
Para comenzar rápidamente, aquí hay una guía para principiantes sobre GraphLab en Python. Para facilitar la comprensión, he intentado explicar estos conceptos de la manera más sencilla posible.
Tópicos cubiertos
- Cómo empezó todo ?
- ¿Qué es GraphLab?
- Beneficios y limitaciones de GraphLab
- ¿Cómo instalar GraphLab?
- Empezando con GraphLab
Cómo empezó todo ?
GraphLab tiene una historia interesante de sus inicios. Déjame contarte brevemente.
GraphLab, conocido como Dato es fundado por Carlos Guestrin. Carlos tiene un doctorado en Ciencias de la Computación de la Universidad de Stanford. Sucedió hace unos 7 años. Carlos era profesor en la Universidad Carnegie Mellon. Dos de sus estudiantes estaban trabajando en algoritmos de aprendizaje automático distribuidos a gran escala. Ejecutaron su modelo sobre Hadoop y descubrieron que se tardaba bastante en calcular. Las situaciones ni siquiera mejoraron después de usar MPI (biblioteca informática de alto rendimiento).
Entonces, decidieron construir un sistema para escribir más artículos rápidamente. Con esto, GraphLab nació.
PD – GraphLab Create es un software comercial de GraphLab. Se accede a GraphLab Create en Python usando la biblioteca «graphlab». Por lo tanto, en este artículo, ‘GraphLab’ connota GraphLab Create. No se confunda.
¿Qué es GraphLab?
GraphLab es un nuevo marco paralelo para el aprendizaje automático escrito en C ++. Es un proyecto de código abierto y ha sido diseñado considerando la escala, variedad y complejidad de los datos del mundo real. Incorpora varios algoritmos de alto nivel como Stochastic Gradient Descent (SGD), Gradient Descent & Locking para ofrecer una experiencia de alto rendimiento. Ayuda a los científicos y desarrolladores de datos a crear e instalar fácilmente aplicaciones a gran escala.
Pero, ¿qué lo hace asombroso? Es la presencia de bibliotecas ordenadas para la transformación, manipulación y visualización de modelos de datos. Además, se compone de kits de herramientas de aprendizaje automático escalables que tienen todo (casi) necesario para mejorar los modelos de aprendizaje automático. El kit de herramientas incluye implementación para aprendizaje profundo, máquinas de factores, modelado de temas, agrupación en clústeres, vecinos más cercanos y más.
Aquí está la arquitectura completa de GraphLab Create.
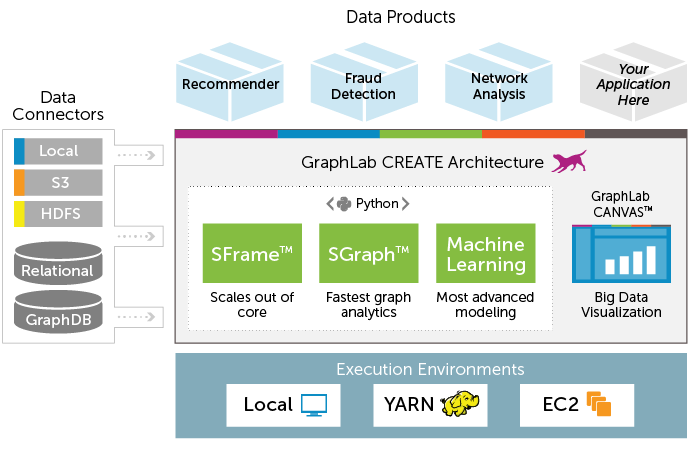
¿Cuáles son los beneficios de usar GraphLab?
Existen múltiples beneficios de usar GraphLab como se describe a continuación:
- Maneja datos grandes: La estructura de datos de GraphLab puede manejar grandes conjuntos de datos que dan como resultado un aprendizaje automático escalable. Veamos la estructura de datos de Graph Lab:
-
- SFrame: Es una estructura de datos tabulares basada en disco eficiente que no está limitada por la RAM. Ayuda a escalar el análisis y el procesamiento de datos para manejar grandes conjuntos de datos (Tera byte), incluso en su computadora portátil. Tiene una sintaxis similar a la de pandas o marcos de datos R. Cada columna es una SArray, que es una serie de elementos almacenados en disco. Esto hace que SFrames se base en disco. He discutido los métodos para trabajar con “SFrames” en las siguientes secciones.
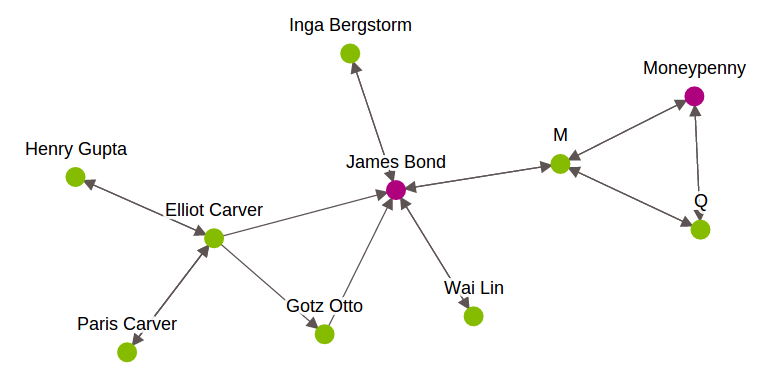
- SGraph: Graph nos ayuda a comprender las redes analizando las relaciones entre pares de elementos. Cada artículo está representado por un vértice en el gráfico. La relación entre elementos está representada por bordes. En GraphLab, para realizar un análisis de datos orientado a gráficos, utiliza SGraph objeto. Es una estructura de datos de gráfico escalable que almacena vértices y aristas en SFrames. Para saber más sobre esto, consulte este Enlace. A continuación se muestra una representación gráfica de los personajes de James Bond.

-
- Integración con varias fuentes de datos: GraphLab admite varias fuentes de datos como S3, ODBC, JSON, CSV, HDFS y muchas más.
- Exploración y visualización de datos con GraphLab Canvas. GraphLab Canvas es una GUI interactiva basada en navegador que le permite explorar datos tabulares, estadísticas resumidas y gráficos bivariados. Con esta función, dedica menos tiempo a codificar la exploración de datos. Esto le ayudará a concentrarse más en comprender la relación y distribución de las variables. He hablado de esta parte en las siguientes secciones.
- Ingeniería de funciones: GraphLab tiene una opción incorporada para crear nuevas funciones útiles para mejorar el rendimiento del modelo. Se compone de varias opciones como transformación, agrupamiento, imputación, una codificación en caliente, tf-idf, etc.
- Modelado: GraphLab tiene varios conjuntos de herramientas para ofrecer una solución fácil y rápida para los problemas de ML. Le permite realizar varios ejercicios de modelado (regresión, clasificación, agrupamiento) en menos líneas de código. Puede trabajar en problemas como el sistema de recomendación, la predicción de abandono, el análisis de sentimientos, el análisis de imágenes y muchos más.
- Automatización de la producción: Las canalizaciones de datos le permiten ensamblar tareas de código reutilizables en trabajos. Luego, ejecútelos automáticamente en entornos de ejecución comunes (por ejemplo, Amazon Web Services, Hadoop).
- GraphLab Create SDK: Los usuarios avanzados pueden ampliar las capacidades de GraphLab Create utilizando GraphLab Creat SDK. Puede definir nuevos modelos / programas de aprendizaje automático e integrarlos con el resto del paquete. Ver el repositorio de GitHub aquí.
- Licencia: Tiene limitación de uso. Puede optar por un período de prueba gratuito de 30 días o una licencia de un año para la edición académica. Para extender su suscripción, se le cobrará (ver estructura de suscripción aquí).
¿Cómo instalar GraphLab?
También puede utilizar GraphLab una vez que haya hecho uso de su licencia. Sin embargo, también puede comenzar con la prueba gratuita o la edición académica con suscripción de 1 año. Por lo tanto, antes de la instalación, su máquina debe cumplir con los requisitos del sistema para ejecutar GraphLab.
Requisitos del sistema para GraphLab:

Si su sistema no cumple con los requisitos anteriores, puede usar GraphLab Create en la capa gratuita de AWS además.
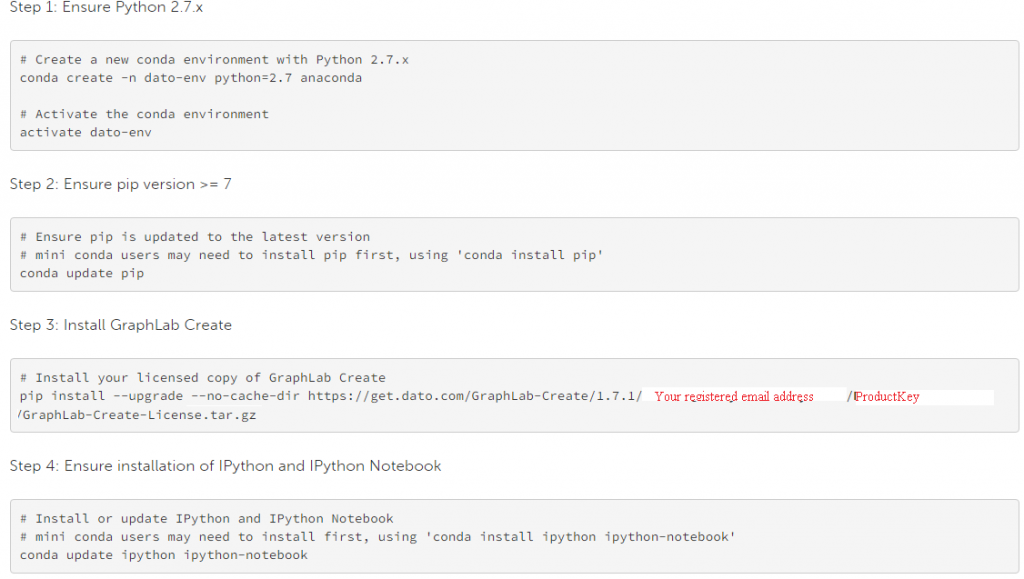
Pasos para la instalación:
- Registrarse para sendero libre. Después del registro, recibirá una clave de producto.
- Seleccione su sistema operativo (la selección automática está activada) y siga las instrucciones dadas
- A continuación se muestran las instrucciones de instalación de la línea de comandos (para «Anaconda Python Environment»).
Empezando con Graphlab
Una vez que haya instalado GraphLab correctamente, puede acceder a él usando «importar ”.
import graphlab or import graphlab as gl
Aquí, demostraré el uso de GraphLab resolviendo un desafío de ciencia de datos. Tengo el conjunto de datos tomado de Hack de datos de Black Friday.
-
-
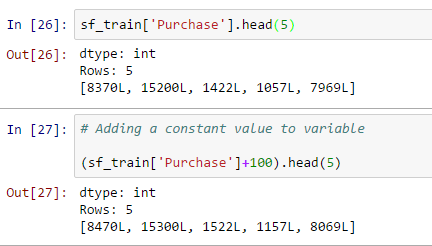
- Manipulación de datos: También puede realizar una operación de manipulación de datos con SFrame, como agregar un valor constante a todos los valores, concatenar dos o más variables, crear una nueva variable de salida basada en una variable como se muestra a continuación:
- Agregue un valor constante a la variable:

- Concatenar dos cadenas y almacenarlas en una nueva variable:

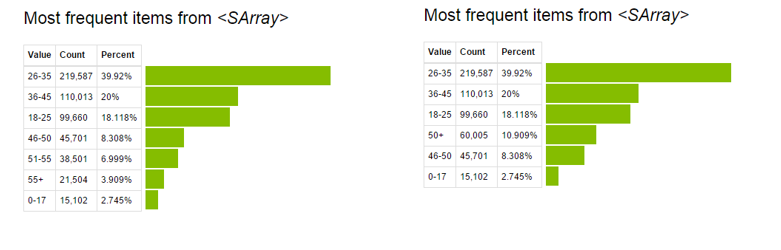
- Actualizar valores de variables existentes: esto se puede hacer usando la función de aplicación. En este conjunto de datos, he combinado grupos de edad mayores a 50 usando el siguiente código:
# Make a change to existing variable # Combine all bins of age greater than 50
def combine_age(age): if age=='51-55': return '50+' elif age=='55+': return '50+' else: return age
sf['Age']=sf['Age'].apply(combine_age)
Ahora, observe la visualización previa y posterior de la variable «Edad».
 Para obtener más detalles sobre la manipulación de datos con GraphLab, consulte este Enlace.
Para obtener más detalles sobre la manipulación de datos con GraphLab, consulte este Enlace.
- Agregue un valor constante a la variable:
- Ingeniería de funciones: La ingeniería de características es un método eficaz para mejorar el rendimiento del modelo. Con esta técnica, podemos crear nuevas variables después de la transformación o manipulación de las variables existentes. De hecho, GraphLab ha automatizado este proceso. Tienen varias opciones de transformación para características numéricas, categóricas, de texto e imagen. Además, encontrará opciones directas para agrupamiento de funciones, imputación, una codificación en caliente, umbral de recuento, TF-IDF, Hasher, Tokenzing y otros. Veamos la imputación de característica categórica «Product_Category_2» Residencia en «La edad» y «Género”Del conjunto de datos“ Black Friday ”.
# Create the data # Variables based on which we want to perform imputation and variable to impute # You can look at the algorithms behind the imputation here. sf_impute = sf_train['Age','Gender','Product_Category_2']
imputer = graphlab.feature_engineering.CategoricalImputer(feature="Product_Category_2") # Fit and transform on the same data transformed_sf = imputer.fit_transform(sf_impute)
#Retrieve the imputed values transformed_sf

Finalmente, puede llevar esta variable de entrada al conjunto de datos original.
sf_train['Predicted_Product_Category_2']=transformed_sf['predicted_feature_Product_Category_2']
De manera similar, puede aplicar otras operaciones de ingeniería de características al conjunto de datos según sus requisitos. Puedes referir esto Enlace para más detalles.
- Modelado: En esta etapa, hacemos predicciones a partir de datos pasados. GraphLab crea fácilmente modelos para tareas comunes, como:
A) Predicción de cantidades numéricas
B) Sistemas de recomendación de edificios
C) Agrupar datos y documentos
D) Análisis de gráficos
- Manipulación de datos: También puede realizar una operación de manipulación de datos con SFrame, como agregar un valor constante a todos los valores, concatenar dos o más variables, crear una nueva variable de salida basada en una variable como se muestra a continuación:
-
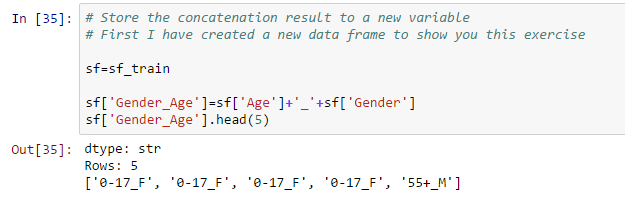
 Para obtener más detalles sobre la manipulación de datos con GraphLab, consulte este
Para obtener más detalles sobre la manipulación de datos con GraphLab, consulte este 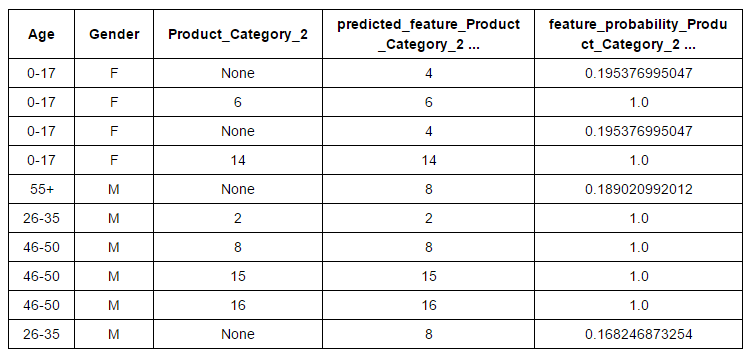
En el desafío del Viernes Negro, estamos obligados a predecir las cantidades numéricas «Compra», es decir, necesitamos un modelo de regresión para predecir la «Compra».
En GraphLab, tenemos tres tipos de modelos de regresión:
A) Regresión lineal
B) Regresión de bosque aleatorio
C) Regresión impulsada por gradientes
Si tiene alguna confusión en la selección del algoritmo, GraphLab se encarga de eso. No te preocupes. Selecciona el modelo de regresión correcto automáticamente.
# Make a train-test split train_data, validate_data = sf_train.random_split(0.8)
# Automatically picks the right model based on your data. model = graphlab.regression.create(train_data, target="Purchase", features = ['Gender','Age','Occupation','City_Category','Stay_In_Current_City_Years', 'Marital_Status','Product_Category_1'])
# Save predictions to an SArray predictions = model.predict(validate_data)
# Evaluate the model and save the results into a dictionary results = model.evaluate(validate_data) results
Producción:
{'max_error': 13377.561969523947, 'rmse': 3007.1225949345117}
#Do prediction on test data set final_predictions = model.predict(sf_test)
Para saber más sobre otras técnicas de modelado como agrupamiento, clasificación, sistema de recomendación, análisis de texto, análisis de gráficos, sistemas de recomendación, puede consultar este Enlace. Alternativamente, aquí está el completo guía del usuario por Dato.
Notas finales
En este artículo, aprendimos sobre «GraphLab Create», que ayuda a manejar un gran conjunto de datos mientras se crean modelos de aprendizaje automático. También analizamos la estructura de datos de Graphlab que le permite manejar grandes conjuntos de datos como “SFrame” y “SGraph”. Te recomiendo que uses GraphLab. Le encantarán sus funciones automatizadas como la exploración de datos (Canvas, herramienta de exploración de datos web interactiva), la ingeniería de funciones, la selección de los modelos adecuados y la implementación.
Para una mejor comprensión, también demostré un ejercicio de modelado usando GraphLab. En mi próximo artículo sobre GraphLab, me centraré en el análisis de gráficos y el sistema de recomendación.
Le ha resultado útil este artículo ? Comparta con nosotros su experiencia con GraphLab.





