Visión general
- Aprenda web scraping en Python usando la biblioteca BeautifulSoup
- Web Scraping es una técnica útil para convertir datos no estructurados en la web en datos estructurados
- BeautifulSoup es una biblioteca eficiente disponible en Python para realizar raspados web que no sean urllib
- Se necesita un conocimiento básico de HTML y etiquetas HTML para hacer web scraping en Python
Introducción
La necesidad y la importancia de extraer datos de la web es cada vez más fuerte y clara. Cada pocas semanas, me encuentro en una situación en la que necesitamos extraer datos de la web para construir un modelo de aprendizaje automático.
Por ejemplo, la semana pasada estábamos pensando en crear un índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de picor y sentimiento sobre varios cursos de ciencia de datos disponible en internet. ¡Esto no solo requeriría encontrar nuevos cursos, sino también buscar en la web sus revisiones y luego resumirlas en algunas métricas!
Este es uno de los problemas / productos cuya eficacia depende más del web scraping y la extracción de información (recopilación de datos) que de las técnicas utilizadas para resumir los datos.
Nota: También hemos creado un curso gratuito para este artículo: Introducción al web scraping con Python. Este formato estructurado te ayudará a aprender mejor.
Formas de extraer información de la web
Hay varias formas de extraer información de la web. Uso de APIs siendo probablemente la mejor manera de extraer datos de un sitio web. Casi todos los sitios web grandes como Twitter, Facebook, Google, Twitter, StackOverflow proporcionan API para acceder a sus datos de una manera más estructurada. Si puede obtener lo que necesita a través de una API, casi siempre es el enfoque preferido sobre el web scraping. Esto se debe a que si obtiene acceso a datos estructurados del proveedor, ¿por qué querría crear un motor para extraer la misma información?
Lamentablemente, no todos los sitios web proporcionan una API. Algunos lo hacen porque no quieren que los lectores extraigan gran cantidad de información de forma estructurada, mientras que otros no proporcionan API por falta de conocimientos técnicos. ¿Qué haces en estos casos? Bueno, necesitamos raspar el sitio web para obtener la información.
Puede haber algunas otras formas como las fuentes RSS, pero su uso es limitado y, por lo tanto, no las incluiré en la discusión aquí.

¿Qué es Web Scraping?
Web scraping es una técnica de software de computadora para extraer información de sitios web. Esta técnica se centra principalmente en la transformación de datos no estructurados (formato HTML) en la web en datos estructurados (base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... u hoja de cálculo).
Puede realizar raspado web de varias formas, incluido el uso de Google Docs en casi todos los lenguajes de programación. Recurriría a Python por su facilidad y su rico ecosistema. Tiene una biblioteca conocida como ‘BeautifulSoup’ que ayuda en esta tarea. En este artículo, le mostraré la forma más fácil de aprender a raspar web usando la programación de Python.
Para aquellos de ustedes que necesitan una forma que no sea de programación para extraer información de las páginas web, también pueden mirar import.io . Proporciona una interfaz guiada por GUI para realizar todas las operaciones básicas de raspado web. ¡Los piratas informáticos pueden seguir leyendo este artículo!
Bibliotecas necesarias para web scraping
Tal como lo conocemos, Pitón es un lenguaje de programación de código abierto. Puede encontrar muchas bibliotecas para realizar una función. Por lo tanto, es necesario encontrar la mejor biblioteca para usar. yo prefiero Hermosa Sopa (Biblioteca de Python), ya que es fácil e intuitivo trabajar en él. Precisamente, usaré dos módulos de Python para raspar datos:
- Urllib2: Es un módulo de Python que se puede utilizar para buscar URL. Define funciones y clases para ayudar con las acciones de URL (autenticación básica y resumida, redirecciones, cookies, etc.). Para obtener más detalles, consulte la página de documentación. Nota: urllib2 es el nombre de la biblioteca incluida en Python 2. En su lugar, puede usar la biblioteca urllib.request incluida con Python 3. La biblioteca urllib.request funciona de la misma manera que urllib.request funciona en Python 2. Porque es ya incluido no es necesario instalarlo.
- BeautifulSoup: Es una herramienta increíble para extraer información de una página web. Puedes usarlo para extraer tablas, listas, párrafo y también puedes poner filtros para extraer información de páginas web. En este artículo, usaremos la última versión de BeautifulSoup 4. Puede consultar las instrucciones de instalación en su página de documentación.
BeautifulSoup no busca la página web por nosotros. Por eso, utilizo urllib2 en combinación con la biblioteca BeautifulSoup.
Pitón tiene varias otras opciones para el raspado HTML además de BeatifulSoup. Aquí hay algunos otros:
Conceptos básicos: familiarizarse con HTML (etiquetas)
Mientras realizamos el escarpado web, nos ocupamos de las etiquetas html. Por lo tanto, debemos comprenderlos bien. Si ya conoce los conceptos básicos de HTML, puede omitir esta sección. A continuación se muestra la sintaxis básica de HTML: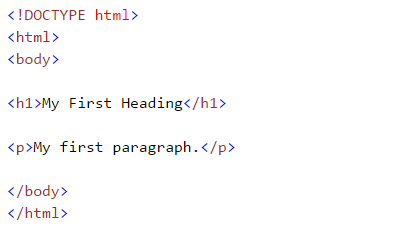 Esta sintaxis tiene varias etiquetas que se detallan a continuación:
Esta sintaxis tiene varias etiquetas que se detallan a continuación:
- : Los documentos HTML deben comenzar con una declaración de tipo
- El documento HTML está contenido entre y
- La parte visible del documento HTML se encuentra entre y
- Los encabezados HTML se definen con el
para etiquetas - Los párrafos HTML se definen con la etiqueta
Otras etiquetas HTML útiles son:
- Los enlaces HTML se definen con el etiqueta, «<a href =«Http://www.test.com»>Este es un enlace para test.com</a> ”
- Las tablas HTML se definen con
, la fila como
y las filas se dividen en datos como 
- La lista HTML comienza con
- (desordenada) y
- Importe las bibliotecas necesarias:
- (ordenada). Cada elemento de la lista comienza con
Si es nuevo en estas etiquetas HTML, también le recomendaría que consulte Tutorial HTML de W3schools. Esto le dará una comprensión clara de las etiquetas HTML.
Raspando una página web usando BeautifulSoup
Aquí, estoy extrayendo datos de un Página de Wikipedia. Nuestro objetivo final es extraer una lista de capitales estatales y territoriales de la unión en la India. Y algunos detalles básicos como el establecimiento, la antigua capital y otros forman este página de wikipedia. Aprendamos haciendo este proyecto paso a paso:
#import the library used to query a website import urllib2 #if you are using python3+ version, import urllib.request
#specify the url wiki = "https://en.wikipedia.org/wiki/List_of_state_and_union_territory_capitals_in_India"
#Query the website and return the html to the variable 'page' page = urllib2.urlopen(wiki) #For python 3 use urllib.request.urlopen(wiki)
#import the Beautiful soup functions to parse the data returned from the website from bs4 import BeautifulSoup
#Parse the html in the 'page' variable, and store it in Beautiful Soup format soup = BeautifulSoup(page)
- Utilice la función «embellecer» para ver la estructura anidada de la página HTML
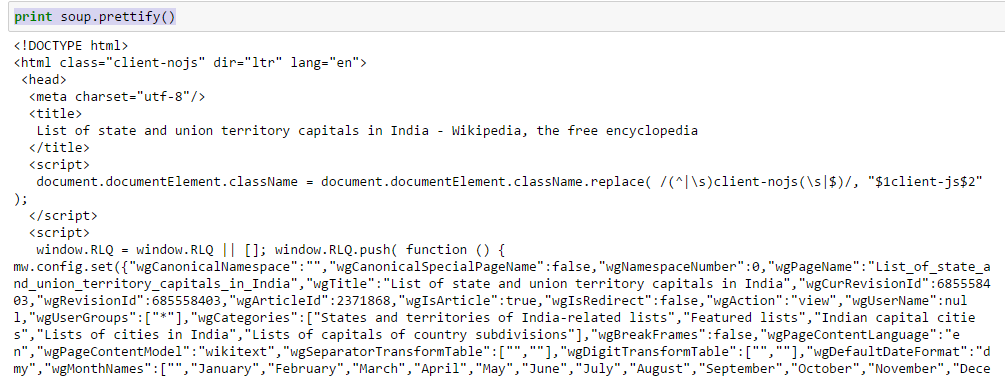 Arriba, puede ver esa estructura de las etiquetas HTML. Esto le ayudará a conocer las diferentes etiquetas disponibles y cómo puede jugar con ellas para extraer información.
Arriba, puede ver esa estructura de las etiquetas HTML. Esto le ayudará a conocer las diferentes etiquetas disponibles y cómo puede jugar con ellas para extraer información.
- Trabajar con etiquetas HTML
- sopa. : Devuelve el contenido entre la etiqueta de apertura y cierre, incluida la etiqueta.
In[30]:soup.title Out[30]:<title>List of state and union territory capitals in India - Wikipedia, the free encyclopedia</title>
- sopa. .string: Devolver cadena dentro de la etiqueta dada
In [38]:soup.title.string Out[38]:u'List of state and union territory capitals in India - Wikipedia, the free encyclopedia'
- Encuentre todos los enlaces dentro de las etiquetas de la página :: Sabemos eso, podemos etiquetar un enlace usando la etiqueta ««. Entonces, deberíamos ir con la opción sopa. a y debe devolver los enlaces disponibles en la página web. Vamos a hacerlo.
In [40]:soup.a Out[40]:<a id="top"></a>
Arriba, puede ver que solo tenemos una salida. Ahora, para extraer todos los enlaces dentro de , usaremos «encuentra todos().
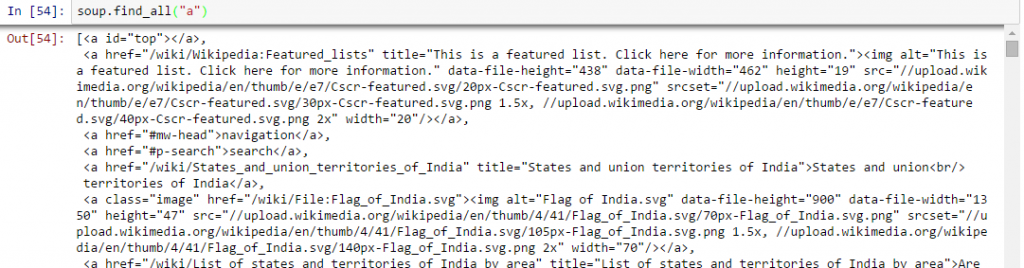
Arriba, muestra todos los enlaces, incluidos títulos, enlaces y otra información. Ahora, para mostrar solo los enlaces, debemos iterar sobre cada etiqueta a y luego devolver el enlace usando el atributo «href» con obtener.
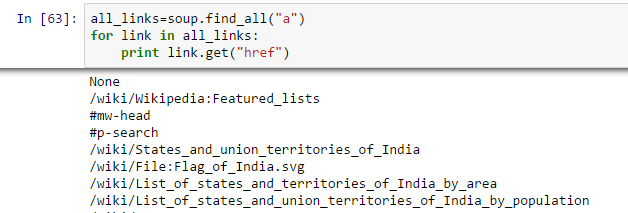
- Encuentra la mesa adecuada: Como buscamos una tabla para extraer información sobre las capitales de los estados, primero debemos identificar la tabla correcta. Escribamos el comando para extraer información dentro de todos mesa etiquetas.
all_tables=soup.find_all('table')Ahora, para identificar la tabla correcta, usaremos el atributo «clase» de la tabla y lo usaremos para filtrar la tabla correcta. En Chrome, puede verificar el nombre de la clase haciendo clic derecho en la tabla requerida de la página web -> Inspeccionar elemento -> Copie el nombre de la clase O vaya a la salida del comando anterior y busque el nombre de clase de la tabla derecha.
right_table=soup.find('table', class_='wikitable sortable plainrowheaders') right_table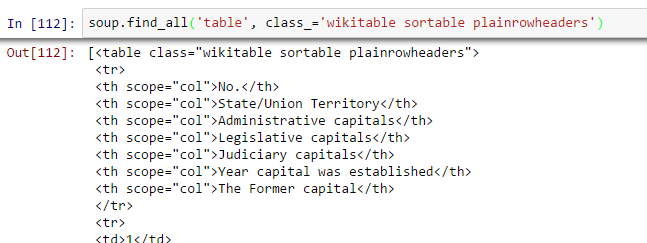 Above, we are able to identify right table.
Above, we are able to identify right table. - Extraiga la información a DataFrame: Aquí, necesitamos iterar a través de cada fila (tr) y luego asignar cada elemento de tr (td) a una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... y agregarlo a una lista. Primero veamos la estructura HTML de la tabla (no voy a extraer información para el encabezado de la tabla
) 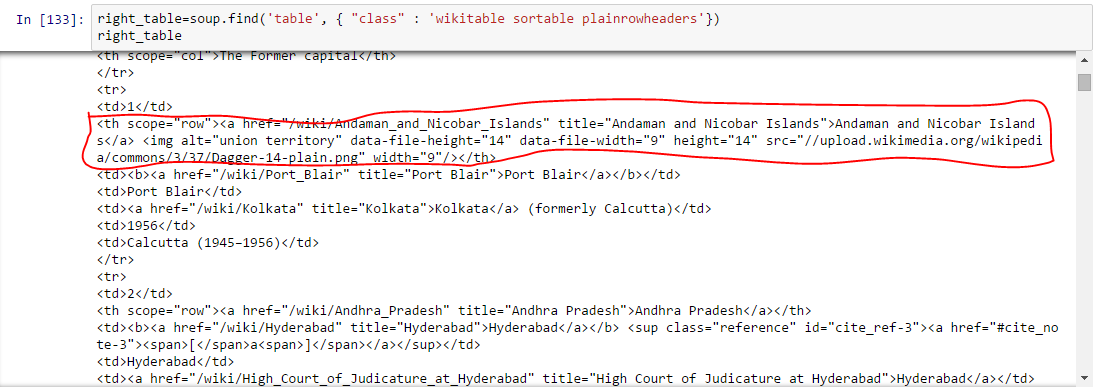 Arriba, puede notar que el segundo elemento de
Arriba, puede notar que el segundo elemento de
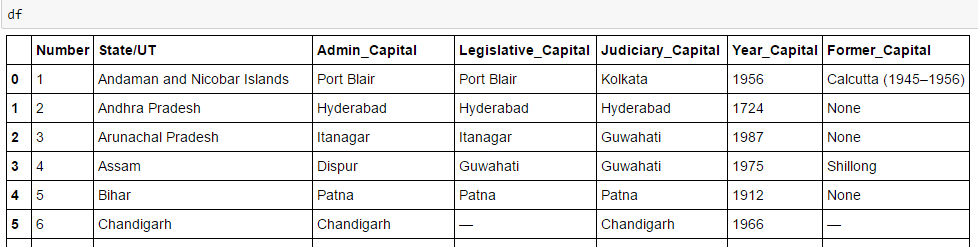
está dentro de la etiqueta , no , por lo que debemos ocuparnos de esto. Ahora, para acceder al valor de cada elemento, usaremos la opción «buscar (texto = Verdadero)» con cada elemento. Veamos el código: #Generate lists A=[] B=[] C=[] D=[] E=[] F=[] G=[] for row in right_table.findAll("tr"): cells = row.findAll('td') states=row.findAll('th') #To store second column data if len(cells)==6: #Only extract table body not heading A.append(cells[0].find(text=True)) B.append(states[0].find(text=True)) C.append(cells[1].find(text=True)) D.append(cells[2].find(text=True)) E.append(cells[3].find(text=True)) F.append(cells[4].find(text=True)) G.append(cells[5].find(text=True))#import pandas to convert list to data frame import pandas as pd df=pd.DataFrame(A,columns=['Number']) df['State/UT']=B df['Admin_Capital']=C df['Legislative_Capital']=D df['Judiciary_Capital']=E df['Year_Capital']=F df['Former_Capital']=G df
Finalmente, tenemos datos en el marco de datos:
Del mismo modo, puede realizar otros tipos de raspado web utilizando «Hermosa Sopa“. Esto reducirá sus esfuerzos manuales para recopilar datos de páginas web. También puede mirar los otros atributos como .parent, .contents, .descendants y .next_sibling, .prev_sibling y varios atributos para navegar usando el nombre de la etiqueta. Estos le ayudarán a eliminar las páginas web de forma eficaz.Pero, ¿por qué no puedo usar expresiones regulares?
Ahora, si conoce las expresiones regulares, podría estar pensando que puede escribir código usando expresiones regulares que pueden hacer lo mismo por usted. Definitivamente tenía esta pregunta. En mi experiencia con BeautifulSoup y las expresiones regulares para hacer lo mismo, descubrí:
- El código escrito en BeautifulSoup suele ser más robusto que el escrito con expresiones regulares. Los códigos escritos con expresiones regulares deben modificarse con cualquier cambio en las páginas. Incluso BeautifulSoup necesita eso en algunos casos, es solo que BeautifulSoup es relativamente mejor.
- Las expresiones regulares son mucho más rápidas que BeautifulSoup, generalmente por un factor de 100 para dar el mismo resultado.
Por lo tanto, se reduce a la velocidad frente a la robustez del código y aquí no hay un ganador universal. Si la información que está buscando se puede extraer con simples declaraciones de expresiones regulares, debe continuar y usarlas. Para casi cualquier trabajo complejo, generalmente recomiendo BeautifulSoup más que expresiones regulares.
Nota final
En este artículo, analizamos los métodos de raspado web que utilizan «BeautifulSoup» y «urllib2» en Python. También analizamos los conceptos básicos de HTML y realizamos el raspado web paso a paso mientras resolvíamos un desafío. Te recomiendo que practiques esto y lo utilices para recopilar datos de páginas web.
¿Le ha resultado útil este artículo? Comparta sus opiniones / pensamientos en la sección de comentarios a continuación.
Nota: También hemos creado un curso gratuito para este artículo: Introducción al web scraping con Python. Este formato estructurado te ayudará a aprender mejor.
Si le gusta lo que acaba de leer y desea continuar con su aprendizaje sobre análisis, suscríbete a nuestros correos electrónicos, Síguenos en Twitter o como nuestro pagina de Facebook.
Relacionado







- La lista HTML comienza con

