Visión general
- La ingeniería de características en PNL consiste en comprender el contexto del texto.
- En este blog, veremos algunas de las características de ingeniería comunes en PNL.
- Compararemos los resultados de una tarea de clasificación con y sin realizar ingeniería de características.
Tabla de contenidos
- Introducción
- Descripción general de la tarea de PNL
- Lista de características con código
- Implementación
- Comparación de resultados con y sin ingeniería de funciones
- Conclusión
Introducción
«Si el 80 por ciento de nuestro trabajo es la preparación de datos, garantizar la calidad de los datos es el trabajo importante de un equipo de aprendizaje automático». – Andrew Ng
La ingeniería de funciones es uno de los pasos más importantes del aprendizaje automático. Es el proceso de utilizar el conocimiento de dominio de los datos para crear características que hacen que los algoritmos de aprendizaje automático funcionen. Piense en el algoritmo de aprendizaje automático como un niño que aprende; cuanto más precisa sea la información que proporcione, más podrán interpretar bien la información. Enfocarnos primero en nuestros datos nos dará mejores resultados que enfocarnos solo en modelos. La ingeniería de características nos ayuda a crear mejores datos que ayudan al modelo a comprenderlos bien y proporcionar resultados razonables.
La PNL es un subcampo de la inteligencia artificial en el que entendemos la interacción humana con las máquinas que utilizan lenguajes naturales. Para comprender un lenguaje natural, es necesario comprender cómo escribimos una oración, cómo expresamos nuestros pensamientos utilizando diferentes palabras, signos, caracteres especiales, etc., básicamente debemos comprender el contexto de la oración para interpretar su significado.
Si podemos usar estos contextos como características y alimentarlos a nuestro modelo, entonces el modelo podrá comprender mejor la oración. Algunas de las características comunes que podemos extraer de una oración son el número de palabras, el número de palabras en mayúscula, el número de puntuación, el número de palabras únicas, el número de palabras vacías, la longitud promedio de la oración, etc. Podemos definir estas características en función de nuestra conjunto de datos que estamos usando. En este blog, usaremos un conjunto de datos de Twitter para que podamos agregar algunas otras características como la cantidad de hashtags, la cantidad de menciones, etc. Las discutiremos en detalle en las próximas secciones.
Descripción general de la tarea de PNL
Para comprender la tarea de ingeniería de funciones en PNL, la implementaremos en un conjunto de datos de Twitter. Nosotros usaremos Conjunto de datos de noticias falsas COVID-19. La tarea es clasificar el tweet como Falso o Verdadero. El conjunto de datos se divide en tren, validación y conjunto de prueba. A continuación se muestra la distribución,
| Separar | Verdadero | Falso | Total |
| Tren | 3360 | 3060 | 6420 |
| Validación | 1120 | 1020 | 2140 |
| Prueba | 1120 | 1020 | 2140 |
Lista de características
Enumeraré un total de 15 características que podemos usar para el conjunto de datos anterior, el número de características depende totalmente del tipo de conjunto de datos que esté utilizando.
1. Número de caracteres
Cuente la cantidad de caracteres presentes en un tweet.
def count_chars(text):
return len(text)
2. Número de palabras
Cuente el número de palabras presentes en un tweet.
def count_words(text):
return len(text.split())
3. Número de letras mayúsculas
Cuente el número de caracteres en mayúscula presentes en un tweet.
def count_capital_chars(text):
count=0
for i in text:
if i.isupper():
count+=1
return count
4. Número de palabras en mayúscula
Cuente la cantidad de palabras mayúsculas presentes en un tweet.
def count_capital_words(text):
return sum(map(str.isupper,text.split()))
5. Cuente el número de puntuaciones
En esta función, devolvemos un diccionario de 32 signos de puntuación con los recuentos, que se pueden usar como características independientes, que discutiré en la siguiente sección.
def count_punctuations(text):
punctuations="!"#$%&"()*+,-./:;<=>[email protected][]^_`{|}~'
d=dict()
for i in punctuations:
d[str(i)+' count']=text.count(i)
return d
6. Número de palabras entre comillas
El número de palabras entre comillas simples y comillas dobles.
def count_words_in_quotes(text):
x = re.findall("'.'|"."", text)
count=0
if x is None:
return 0
else:
for i in x:
t=i[1:-1]
count+=count_words
return count
7. Número de sentencias
Cuente el número de oraciones en un tweet.
def count_sent(text):
return len(nltk.sent_tokenize(text))
8. Cuente el número de palabras únicas.
Cuente el número de palabras únicas en un tweet.
def count_unique_words(text):
return len(set(text.split()))
9. Recuento de hashtags
Dado que estamos usando el conjunto de datos de Twitter, podemos contar la cantidad de veces que los usuarios usaron el hashtag.
def count_htags(text):
x = re.findall(r'(#w[A-Za-z0-9]*)', text)
return len(x)
10. Recuento de menciones
En Twitter, la mayoría de las veces las personas responden o mencionan a alguien en su tweet, contar el número de menciones también puede tratarse como una característica.
def count_mentions(text):
x = re.findall(r'(@w[A-Za-z0-9]*)', text)
return len(x)
11. Recuento de palabras vacías
Aquí contaremos el número de palabras vacías utilizadas en un tweet.
def count_stopwords(text):
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(text)
stopwords_x = [w for w in word_tokens if w in stop_words]
return len(stopwords_x)
12. Calcular la longitud media de las palabras
Esto se puede calcular dividiendo el número de caracteres por el número de palabras.
df['avg_wordlength'] = df['char_count']/df['word_count']
13. Cálculo de la duración media de las sentencias
Esto se puede calcular dividiendo el recuento de palabras por el recuento de oraciones.
df['avg_sentlength'] = df['word_count']/df['sent_count']
14. palabras únicas vs función de recuento de palabras
Esta característica es básicamente la relación de palabras únicas a un número total de palabras.
df['unique_vs_words'] = df['unique_word_count']/df['word_count']
15. Función de recuento de palabras vacías frente a recuento de palabras
Esta característica también es la relación entre el número de palabras vacías y el número total de palabras.
df['stopwords_vs_words'] = df['stopword_count']/df['word_count']
Implementación
Puede descargar el conjunto de datos desde aquí. Después de la descarga, podemos comenzar a implementar todas las funciones que definimos anteriormente. Nos centraremos más en la ingeniería de funciones, para ello mantendremos el enfoque simple, utilizando TF-IDF y un preprocesamiento simple. Todo el código estará disponible en mi repositorio de GitHub https://github.com/ahmadkhan242/Feature-Engineering-in-NLP.
-
Lectura de tren, validación y conjunto de pruebas con pandas.
train = pd.read_csv("train.csv") val = pd.read_csv("validation.csv") test = pd.read_csv(testWithLabel.csv") # For this task we will combine the train and validation dataset and then use # simple train test split from sklern. df = pd.concat([train, val]) df.head()
-
Aplicar la extracción de características definidas anteriormente en el tren y el conjunto de prueba.
df['char_count'] = df["tweet"].apply(lambda x:count_chars(x)) df['word_count'] = df["tweet"].apply(lambda x:count_words(x)) df['sent_count'] = df["tweet"].apply(lambda x:count_sent(x)) df['capital_char_count'] = df["tweet"].apply(lambda x:count_capital_chars(x)) df['capital_word_count'] = df["tweet"].apply(lambda x:count_capital_words(x)) df['quoted_word_count'] = df["tweet"].apply(lambda x:count_words_in_quotes(x)) df['stopword_count'] = df["tweet"].apply(lambda x:count_stopwords(x)) df['unique_word_count'] = df["tweet"].apply(lambda x:count_unique_words(x)) df['htag_count'] = df["tweet"].apply(lambda x:count_htags(x)) df['mention_count'] = df["tweet"].apply(lambda x:count_mentions(x)) df['punct_count'] = df["tweet"].apply(lambda x:count_punctuations(x)) df['avg_wordlength'] = df['char_count']/df['word_count'] df['avg_sentlength'] = df['word_count']/df['sent_count'] df['unique_vs_words'] = df['unique_word_count']/df['word_count'] df['stopwords_vs_words'] = df['stopword_count']/df['word_count'] # SIMILARLY YOU CAN APPLY THEM ON TEST SET
-
dding algunas características adicionales usando el recuento de puntuación
Crearemos un DataFrame a partir del diccionario devuelto por la función “punct_count” y luego lo fusionaremos con el conjunto de datos principal.
df_punct = pd.DataFrame(list(df.punct_count)) test_punct = pd.DataFrame(list(test.punct_count)) # Merging pnctuation DataFrame with main DataFrame df = pd.merge(df, df_punct, left_index=True, right_index=True) test = pd.merge(test, test_punct,left_index=True, right_index=True)
# We can drop "punct_count" column from both df and test DataFrame df.drop(columns=['punct_count'],inplace=True) test.drop(columns=['punct_count'],inplace=True) df.columns
-
reprocesamiento
Realizamos un simple paso previo al procesamiento, como eliminar enlaces, eliminar nombre de usuario, números, doble espacio, puntuación, minúsculas, etc.
def remove_links(tweet): '''Takes a string and removes web links from it''' tweet = re.sub(r'httpS+', '', tweet) # remove http links tweet = re.sub(r'bit.ly/S+', '', tweet) # rempve bitly links tweet = tweet.strip('https://www.analyticsvidhya.com/blog/2021/04/a-guide-to-feature-engineering-in-nlp/ ') # remove [links] return tweet def remove_users(tweet): '''Takes a string and removes retweet and @user information''' tweet = re.sub('([email protected][A-Za-z]+[A-Za-z0-9-_]+)', '', tweet) # remove retweet tweet = re.sub('(@[A-Za-z]+[A-Za-z0-9-_]+)', '', tweet) # remove tweeted at return tweet my_punctuation = '!"$%&'()*+,-./:;<=>?[]^_`{|}~•@' def preprocess(sent): sent = remove_users(sent) sent = remove_links(sent) sent = sent.lower() # lower case sent = re.sub('['+my_punctuation + ']+', ' ', sent) # strip punctuation sent = re.sub('s+', ' ', sent) #remove double spacing sent = re.sub('([0-9]+)', '', sent) # remove numbers sent_token_list = [word for word in sent.split(' ')] sent=" ".join(sent_token_list) return sent df['tweet'] = df['tweet'].apply(lambda x: preprocess(x)) test['tweet'] = test['tweet'].apply(lambda x: preprocess(x))
-
Codificación de texto
Codificaremos nuestros datos de texto usando TF-IDF. Primero ajustamos transform en nuestra columna de tweets de tren y conjunto de prueba y luego la fusionamos con todas las columnas de características.
vectorizer = TfidfVectorizer() train_tf_idf_features = vectorizer.fit_transform(df['tweet']).toarray() test_tf_idf_features = vectorizer.transform(test['tweet']).toarray() # Converting above list to DataFrame train_tf_idf = pd.DataFrame(train_tf_idf_features) test_tf_idf = pd.DataFrame(test_tf_idf_features) # Saparating train and test labels from all features train_Y = df['label'] test_Y = test['label'] #Listing all features features = ['char_count', 'word_count', 'sent_count', 'capital_char_count', 'capital_word_count', 'quoted_word_count', 'stopword_count', 'unique_word_count', 'htag_count', 'mention_count', 'avg_wordlength', 'avg_sentlength', 'unique_vs_words', 'stopwords_vs_words', '! count', '" count', '# count', '$ count', '% count', '& count', '' count', '( count', ') count', '* count', '+ count', ', count', '- count', '. count', '/ count', ': count', '; count', '< count', '= count', '> count', '? count', '@ count', '[ count', ' count', '] count', '^ count', '_ count', '` count', '{ count', '| count', '} count', '~ count'] # Finally merging all features with above TF-IDF. train = pd.merge(train_tf_idf,df[features],left_index=True, right_index=True) test = pd.merge(test_tf_idf,test[features],left_index=True, right_index=True) -
Capacitación
Para el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., usaremos el algoritmo de bosque aleatorio de la biblioteca de aprendizaje de sci-kit.
X_train, X_test, y_train, y_test = train_test_split(train, train_Y, test_size=0.2, random_state = 42) # Random Forest Classifier clf_model = RandomForestClassifier(n_estimators = 1000, min_samples_split = 15, random_state = 42) clf_model.fit(X_train, y_train) _RandomForestClassifier_prediction = clf_model.predict(X_test) val_RandomForestClassifier_prediction = clf_model.predict(test)
Comparación de resultados
A modo de comparación, primero entrenamos nuestro modelo en el conjunto de datos anterior usando técnicas de ingeniería de características y luego sin usar técnicas de ingeniería de características. En ambos enfoques, preprocesamos el conjunto de datos utilizando el mismo método descrito anteriormente y TF-IDF se utilizó en ambos enfoques para codificar los datos de texto. Puede utilizar cualquier técnica de codificación que desee, como word2vec, glove, etc.
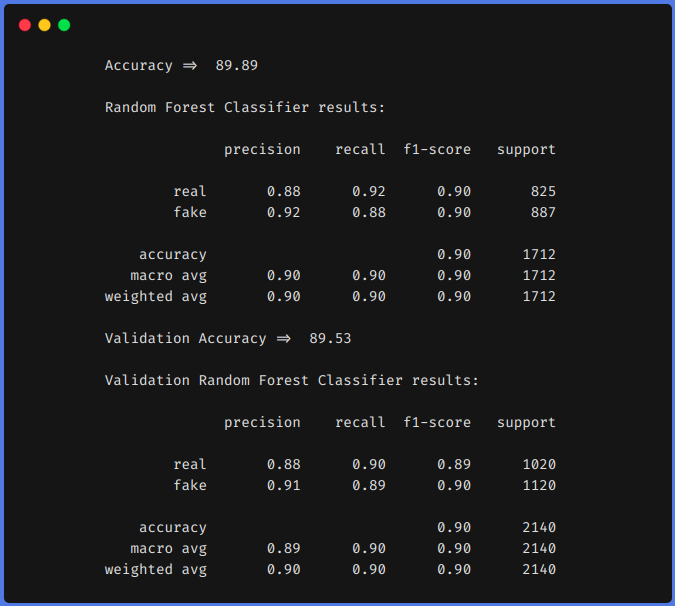
1. Sin utilizar técnicas de ingeniería de funciones
2. Uso de técnicas de ingeniería de funciones
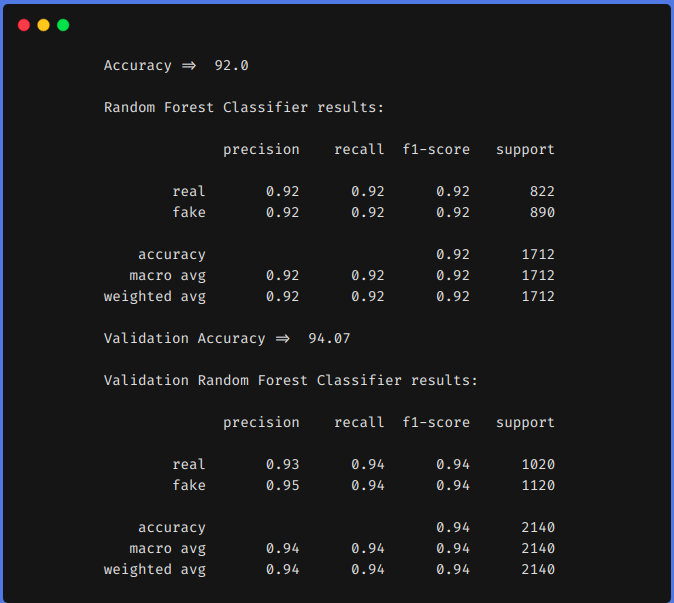
De los resultados anteriores, podemos ver que las técnicas de ingeniería de características nos ayudaron a aumentar nuestra f1 de 0,90 hasta 0,92 en el tren y desde 0,90 hasta 0,94 en el equipo de prueba.
Conclusión
Los resultados anteriores muestran que si realizamos ingeniería de funciones, podemos lograr una mayor precisión utilizando algoritmos clásicos de aprendizaje automático. El uso de un modelo basado en transformadores es un algoritmo que requiere mucho tiempo y recursos. Si realizamos la ingeniería de funciones de la manera correcta, es decir, después de analizar nuestro conjunto de datos, podemos obtener resultados comparables.
También podemos hacer alguna otra ingeniería de características, como contar el número de emojis usados, el tipo de emojis usados, qué frecuencias de palabras únicas, etc. Podemos definir nuestras características analizando el conjunto de datos. Espero que hayas aprendido algo de este blog, compártelo con los demás. Consulte mi blog personal de aprendizaje automático (https://code-ml.com/) para obtener contenido nuevo y emocionante en diferentes dominios de ML e IA.
Sobre el Autor
Mohammad Ahmad (B.Tech) LinkedIn - https://www.linkedin.com/in/mohammad-ahmad-ai/ Personal Blog - https://code-ml.com/ GitHub - https://github.com/ahmadkhan242 Twitter - https://twitter.com/ahmadkhan_242
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





