Introducción
Aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas...., parece intrigante, ¿verdad? Aquí, en este artículo, veremos qué es y por qué se habla tanto en estos días. Esto actúa como una guía para el aprendizaje por refuerzo para principiantes. El aprendizaje por refuerzo es definitivamente una de las áreas de investigación evidentes en la actualidad que tiene un buen auge para emerger en el futuro próximo y su popularidad está aumentando día a día. Vamos a ponerlo en marcha.
Básicamente es el concepto en el que las máquinas pueden aprender a sí mismas dependiendo de los resultados de sus propias acciones. Sin más demora, comencemos.
¿Qué es el aprendizaje por refuerzo?
El aprendizaje por refuerzo es parte del aprendizaje automático. Aquí, los agentes se capacitan por sí mismos sobre los mecanismos de recompensa y castigo. Se trata de tomar la mejor acción o camino posible para obtener las recompensas máximas y el castigo mínimo a través de observaciones en una situación específica. Actúa como una señal de comportamientos positivos y negativos. Esencialmente se construye un agente (o varios) que puede percibir e interpretar el entorno en el que se encuentra, además, puede tomar acciones e interactuar con él.
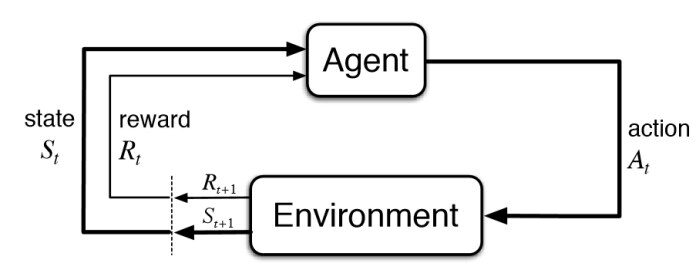
Diagrama básico de aprendizaje por refuerzo – KDNuggets
Para conocer el significado del aprendizaje por refuerzo, repasemos la definición formal.
Aprendizaje reforzado, un tipo de aprendizaje automático, en el que los agentes toman acciones en un entorno destinado a maximizar sus recompensas acumulativas – NVIDIA
El aprendizaje por refuerzo (RL) se basa en recompensar los comportamientos deseados o castigar los no deseados. En lugar de que una entrada produzca una salida, el algoritmo produce una variedad de salidas y está capacitado para seleccionar la correcta en función de ciertas variables: Gartner
Es un tipo de técnica de aprendizaje automático en la que un agente informático aprende a realizar una tarea a través de interacciones repetidas de prueba y error con un entorno dinámico. Este enfoque de aprendizaje permite al agente tomar una serie de decisiones que maximizan una métrica de recompensa para la tarea sin la intervención humana y sin estar programado explícitamente para lograr la tarea: Mathworks
Sin embargo, las definiciones anteriores son proporcionadas técnicamente por expertos en ese campo para alguien que está comenzando con el aprendizaje por refuerzo, pero estas definiciones pueden parecer un poco difíciles. Como esta es una guía de aprendizaje por refuerzo para principiantes, creemos nuestra definición de aprendizaje por refuerzo de una manera más fácil.
Definición simplificada de aprendizaje por refuerzo
A través de una serie de métodos de prueba y error, un agente sigue aprendiendo continuamente en un entorno interactivo de sus propias acciones y experiencias. El único objetivo es encontrar un modelo de acción adecuado que aumente la recompensa acumulada total del agente. Aprende a través de la interacción y la retroalimentación.
Bueno, esa es la definición de aprendizaje por refuerzo. Ahora, cómo llegamos a esta definición, cómo aprende una máquina y cómo puede resolver problemas complejos en el mundo a través del aprendizaje por refuerzo, es algo que veremos más a fondo.
Explicación del aprendizaje por refuerzo
¿Cómo funciona el aprendizaje por refuerzo? Bueno, déjame explicarte con un ejemplo.
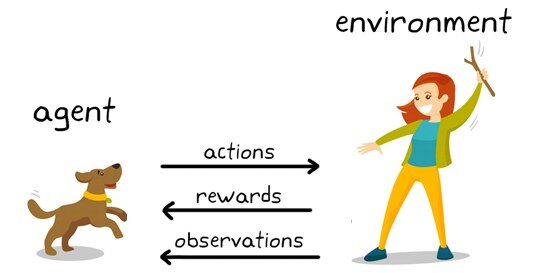
Ejemplo de aprendizaje por refuerzo: KDNuggets
¿Aquí que ves?
Puedes ver un perro y un amo. Imaginemos que está entrenando a su perro para que coja el palo. Cada vez que el perro consigue un palo con éxito, le ofreces un festín (un hueso, digamos). Eventualmente, el perro comprende el patrón, que cada vez que el maestro lanza un palo, debe obtenerlo lo antes posible para obtener una recompensa (un hueso) de un maestro en un tiempo menor.
Terminologías utilizadas en el aprendizaje por refuerzo
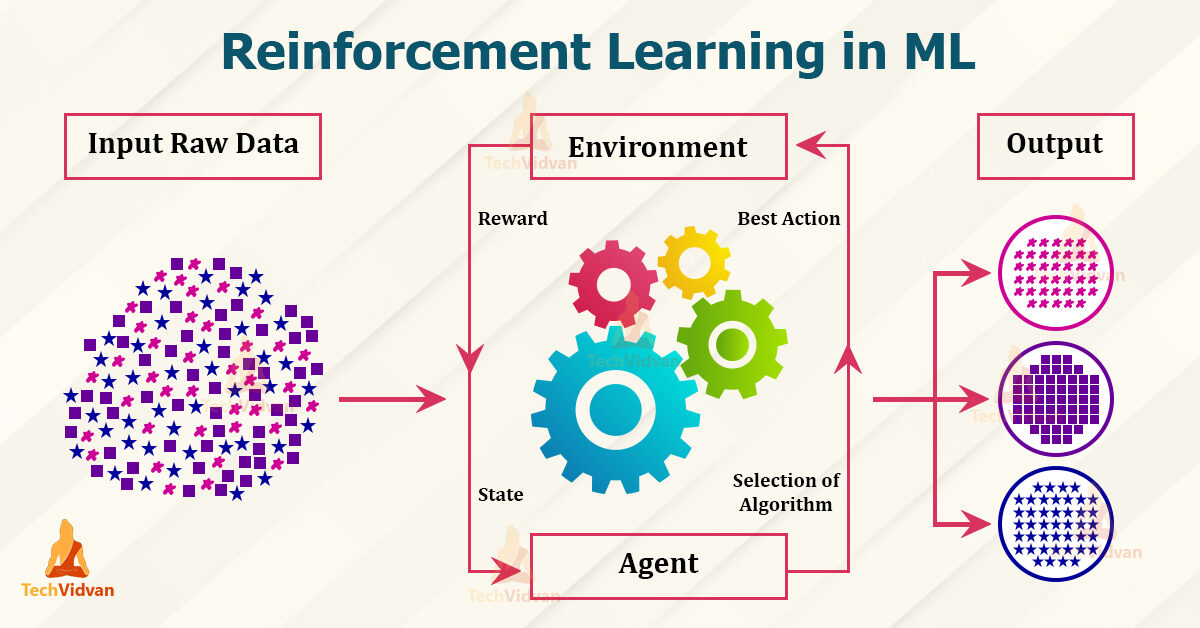
Terminologías en RL – Techvidvan
Agente – es el único que toma las decisiones y aprende
Medio ambiente – un mundo físico donde un agente aprende y decide las acciones a realizar
Acción – una lista de acciones que puede realizar un agente
Estado – la situación actual del agente en el medio ambiente
Recompensa – Por cada acción seleccionada por el agente, el entorno da una recompensa. Por lo general, es un valor escalar y nada más que comentarios del entorno.
Política – el agente prepara la estrategia (toma de decisiones) para asignar situaciones a acciones.
Función de valor – El valor del estado muestra la recompensa lograda a partir del estado hasta que se ejecuta la política.
Modelo – Cada agente de RL no usa un modelo de su entorno. La vista del agente mapea distribuciones de probabilidad de pares estado-acción sobre los estados
Flujo de trabajo de aprendizaje por refuerzo
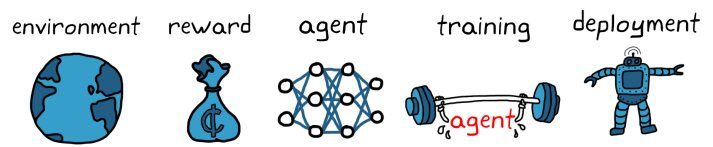
Flujo de trabajo de aprendizaje reforzado – KDNuggets
– Crea el medio ambiente
– Definir la recompensa
– Crea el agente
– Capacitar y validar al agente
– Implementar la política
¿En qué se diferencia el aprendizaje por refuerzo del aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en...?
En el aprendizaje supervisado, el modelo se entrena con un conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... que tiene una clave de respuesta correcta. La decisión se toma sobre la base de la entrada inicial dada, ya que tiene todos los datos necesarios para entrenar la máquina. Las decisiones son independientes entre sí, por lo que cada decisión se representa a través de una etiqueta. Ejemplo: reconocimiento de objetos
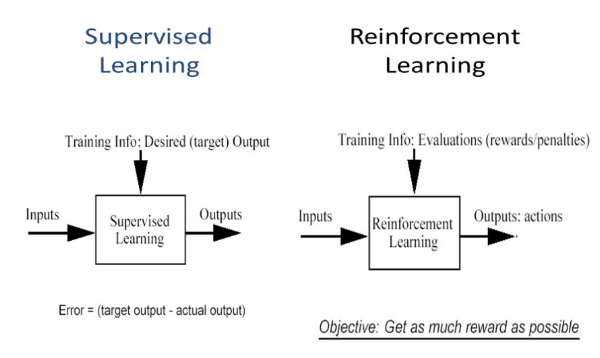
Diferencia entre aprendizaje supervisado y reforzado – purestudy
En el aprendizaje por refuerzo, no hay ninguna respuesta y el agente de refuerzo decide qué hacer para realizar la tarea requerida. Como el conjunto de datos de entrenamiento no está disponible, el agente tuvo que aprender de su experiencia. Se trata de recopilar las decisiones de forma secuencial. Para decirlo en palabras más simples, la salida se basa en el estado de entrada actual y la siguiente entrada se basa en la salida de la entrada anterior. Damos etiquetas a la secuencia de decisiones dependientes. Las decisiones dependen. Ejemplo: juego de ajedrez
Características del aprendizaje por refuerzo
– Sin supervisión, solo un valor real o una señal de recompensa
– La toma de decisiones es secuencial
– El tiempo juega un papel importante en los problemas de refuerzo.
– La retroalimentación no es rápida sino demorada
– Los siguientes datos que recibe están determinados por las acciones del agente
Algoritmos de aprendizaje por refuerzo
Hay 3 enfoques para implementar algoritmos de aprendizaje por refuerzo
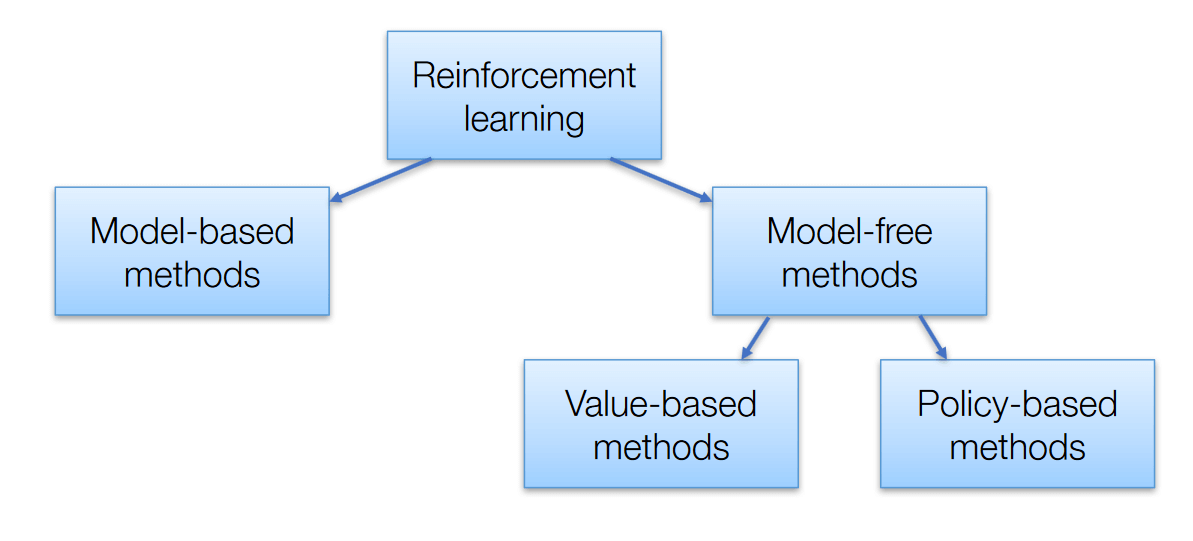
Algoritmos de aprendizaje por refuerzo – AISummer
Basado en valor – El objetivo principal de este método es maximizar una función de valor. Aquí, un agente a través de una póliza espera un retorno a largo plazo de los estados actuales.
Basado en políticas – En las políticas basadas en políticas, permite idear una estrategia que ayude a obtener las máximas recompensas en el futuro a través de las posibles acciones realizadas en cada estado. Dos tipos de métodos basados en políticas son deterministas y estocásticos.
Basado en modelos – En este método, necesitamos crear un modelo virtual para que el agente ayude a aprender a desempeñarse en cada entorno específico.
Tipos de aprendizaje por refuerzo
Hay dos tipos :
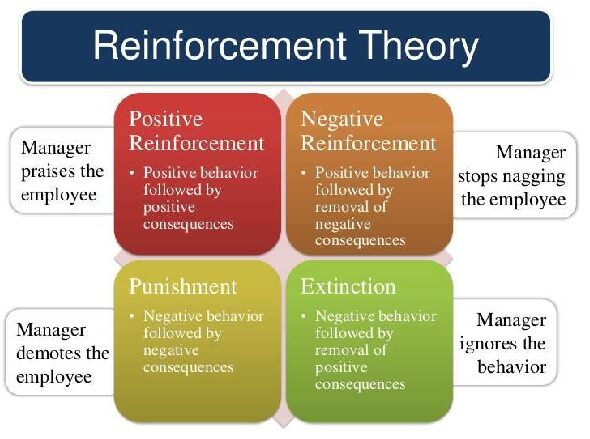
Ejemplo de teoría de refuerzo – Tutorialspoint
1. Refuerzo positivo
El refuerzo positivo se define como cuando un evento, debido a un comportamiento específico, aumenta la fuerza y la frecuencia del comportamiento. Tiene un impacto positivo en el comportamiento.
Ventajas
– Maximiza el rendimiento de una acción.
– Mantener el cambio durante un período más largo
Desventaja
– El exceso de refuerzo puede conducir a una sobrecarga de estados que minimizaría los resultados.
2. Refuerzo negativo
El refuerzo negativo se representa como el fortalecimiento de una conducta. De otras formas, cuando se prohíbe o evita una condición negativa, intenta detener esta acción en el futuro.
Ventajas
– Comportamiento maximizado
– Proporcionar un estándar de desempeño decente al mínimo
Desventaja
– Simplemente se limita lo suficiente para cumplir con un comportamiento mínimo.
Modelos ampliamente utilizados para el aprendizaje por refuerzo.
1. Proceso de decisión de Markov (MDP) – son marcos matemáticos para soluciones de mapeo en RL. El conjunto de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... que incluye Conjunto de estados finitos – S, Conjunto de posibles acciones en cada estado – A, Recompensa – R, Modelo – T, Política – π. El resultado de implementar una acción en un estado no depende de acciones o estados anteriores, sino de la acción y el estado actuales.
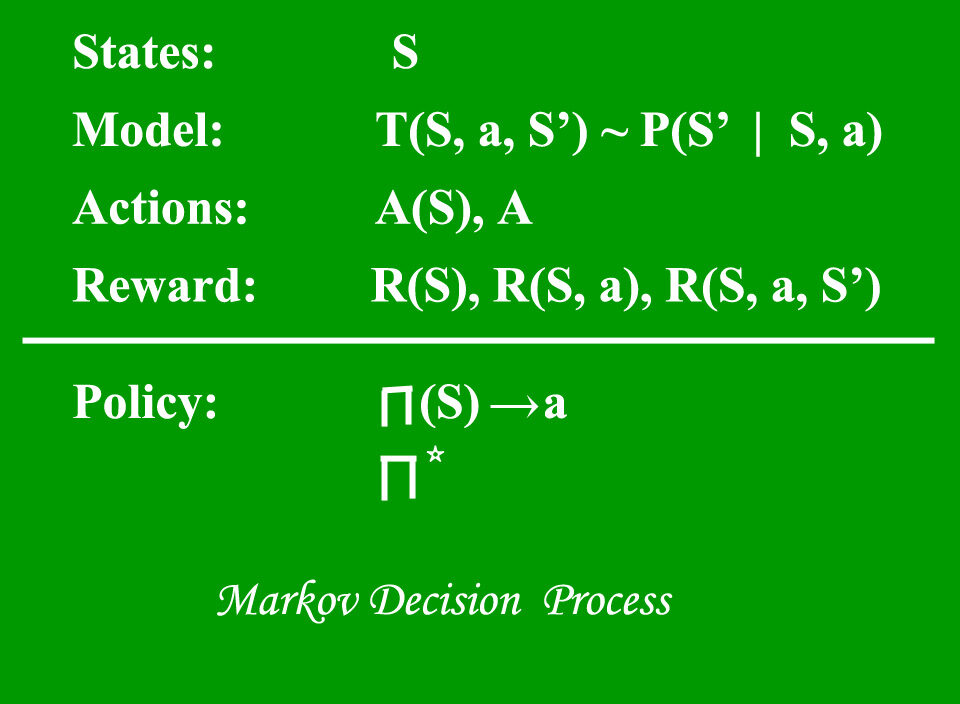
Proceso de decisión de Markov – Geeks4geeks
2. Q aprendizaje – Es un enfoque libre de modelos basado en valores para proporcionar información para indicar qué acción debe realizar un agente. Gira en torno a la noción de actualizar los valores de Q que muestra el valor de realizar la acción A en el estado S. La regla de actualización de valores es el aspecto principal del algoritmo de Q-learning.
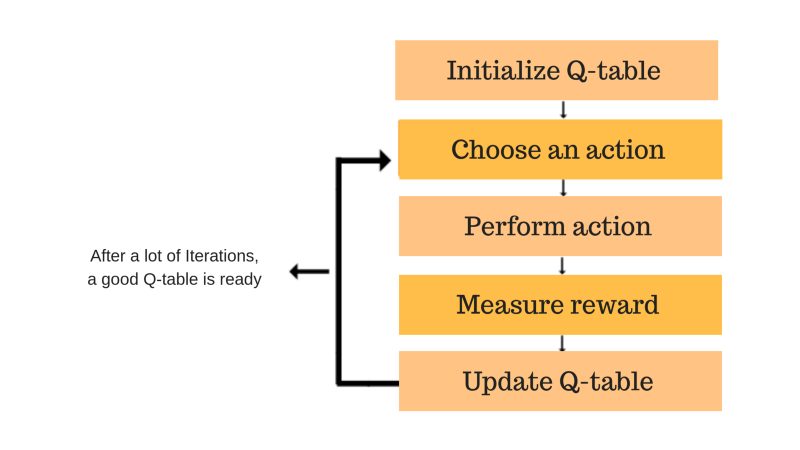
QLearning – Freecodecamp
Aplicaciones prácticas del aprendizaje por refuerzo
– Robótica para automatización industrial
– Motores de resumen de texto, agentes de diálogo (texto, voz), juegos
– Automóviles autónomos autónomos
– Aprendizaje automático y procesamiento de datos
– Sistema de formación que emitiría instrucciones y materiales personalizados con respecto a los requisitos de los estudiantes.
– Kits de herramientas de IA, fabricación, automoción, sanidad y bots
– Control de aeronaves y control de movimiento de robots
– Construcción de inteligencia artificial para juegos de computadora.
Conclusión
La conclusión de este tema no es más que ayudarnos a descubrir qué acción podría producir la mayor recompensa durante más tiempo. Los entornos realistas pueden tener una observabilidad parcial y también ser no estacionarios. No es muy útil aplicar cuando tiene suficientes datos prácticos para resolver el problema mediante el aprendizaje supervisado. El principal desafío de este método es que los parámetros pueden afectar la velocidad del aprendizaje.
Espero que ahora conozcas y entiendas cierto nivel de la descripción del aprendizaje por refuerzo. Gracias por tu tiempo.
Sobre mí
Soy Prathima Kadari, un ex ingeniero integrado que trabaja para aprovechar mis conocimientos y mejorar mis habilidades.
Por favor, siéntete libre de conectarte conmigo en https://www.linkedin.com/in/prathima-kadari
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





