Introducción
Hoy en día, las organizaciones manejan una gran cantidad y una amplia variedad de datos: llamadas de clientes, sus correos electrónicos, tweets, datos de aplicaciones móviles y demás. Se necesita mucho esfuerzo y tiempo para que estos datos sean útiles. Una de las habilidades básicas para extraer información de datos de texto es el procesamiento del lenguaje natural (PNL).
El procesamiento del lenguaje natural (PNL) es el arte y la ciencia que nos ayuda a extraer información del texto y usarla en nuestros cálculos y algoritmos. Dado el aumento de contenido en Internet y las redes sociales, es uno de los imprescindibles para todos los científicos de datos.
Ya sea que conozca la PNL o no, esta guía debería ayudarlo como una referencia lista para usted. A través de esta guía, le proporcioné recursos y códigos para ejecutar las tareas más comunes en PNL.
Una vez que haya leído esta guía, no dude en echar un vistazo a nuestra curso de vídeo sobre procesamiento del lenguaje natural (PNL).

¿Por qué creé esta guía?
Después de haber estado trabajando en problemas de PNL durante algún tiempo, me he encontrado con varias situaciones en las que necesitaba consultar cientos de fuentes diferentes para estudiar los últimos desarrollos en forma de artículos de investigación, blogs y concursos para algunas de las tareas comunes de PNL. .
Entonces, decidí reunir todos estos recursos en un solo lugar y convertirlo en una solución integral para los recursos más recientes e importantes para estas tareas comunes de PNL. A continuación se muestra la lista de tareas cubiertas en este artículo junto con sus recursos relevantes. Empecemos.
Tabla de contenido
- Derivado
- Lematización
- Incrustaciones de palabras
- Etiquetado de parte del discurso
- Desambiguación de entidad nombrada
- Reconocimiento de entidad nombrada
- Análisis de los sentimientos
- Similitud de texto semántico
- Identificación del idioma
- Resumen de texto
1. Derivado
¿Qué es Stemming ?: La derivación es el proceso de reducir las palabras (generalmente modificadas o derivadas) a su raíz o raíz de la palabra. El objetivo de la raíz es reducir las palabras relacionadas a la misma raíz, incluso si la raíz no es una palabra del diccionario. Por ejemplo, en el idioma inglés-
- hermosa y hermosamente se derivan de beauti
- mejor y mejor se derivan de mejor y mejor respectivamente
Papel: los artículo original de Martin Porter en el algoritmo de Porter para derivar.
Algoritmo: Aquí está la implementación de Python del algoritmo de derivación de Porter2.
Implementación: Así es como puede derivar una palabra usando el algoritmo Porter2 de la derivando Biblioteca.
2. Lematización
¿Qué es la lematización ?: La lematización es el proceso de reducir un grupo de palabras a su forma de lema o diccionario. Tiene en cuenta cosas como POS (Partes del habla), el significado de la palabra en la oración, el significado de la palabra en las oraciones cercanas, etc. antes de reducir la palabra a su lema. Por ejemplo, en el idioma inglés-
- hermosa y hermosamente están lematizados a hermosa y hermosamente respectivamente.
- bien, mejor y mejor están lematizados a bien, bien y bien respectivamente.
Documento 1: Este papel analiza los diferentes métodos para realizar la lematización con gran detalle. Una lectura obligada si quieres saber cómo funcionan los lematizadores tradicionales.
Documento 2: Este es un excelente trabajo que aborda el problema de la lematización para lenguajes ricos en variaciones utilizando Deep Learning.
Conjunto de datos: Este es el enlace para el conjunto de datos Treebank-3 que puede utilizar si desea crear su propio Lemmatiser.
Implementación: A continuación se muestra una implementación de un Lemmatizador inglés usando spacy.
#!pip install spacy#python -m spacy download enimport spacynlp=spacy.load("en")doc="good better best"
for token in nlp(doc): print(token,token.lemma_)
3. Incrustaciones de palabras
¿Qué son las incrustaciones de palabras ?: Word Embeddings es el nombre de las técnicas que se utilizan para representar el lenguaje natural en forma vectorial de números reales. Son útiles debido a la incapacidad de las computadoras para procesar el lenguaje natural. Entonces, estas incrustaciones de palabras capturan la esencia y la relación entre las palabras en un lenguaje natural usando números reales. En Word Embeddings, una palabra o frase se representa en un vector de dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... fija de longitud, digamos 100.
Así por ejemplo-
Una palabra «hombre» puede representarse en un vector de 5 dimensiones como
![]()
donde cada uno de estos números es la magnitud de la palabra en una dirección particular.
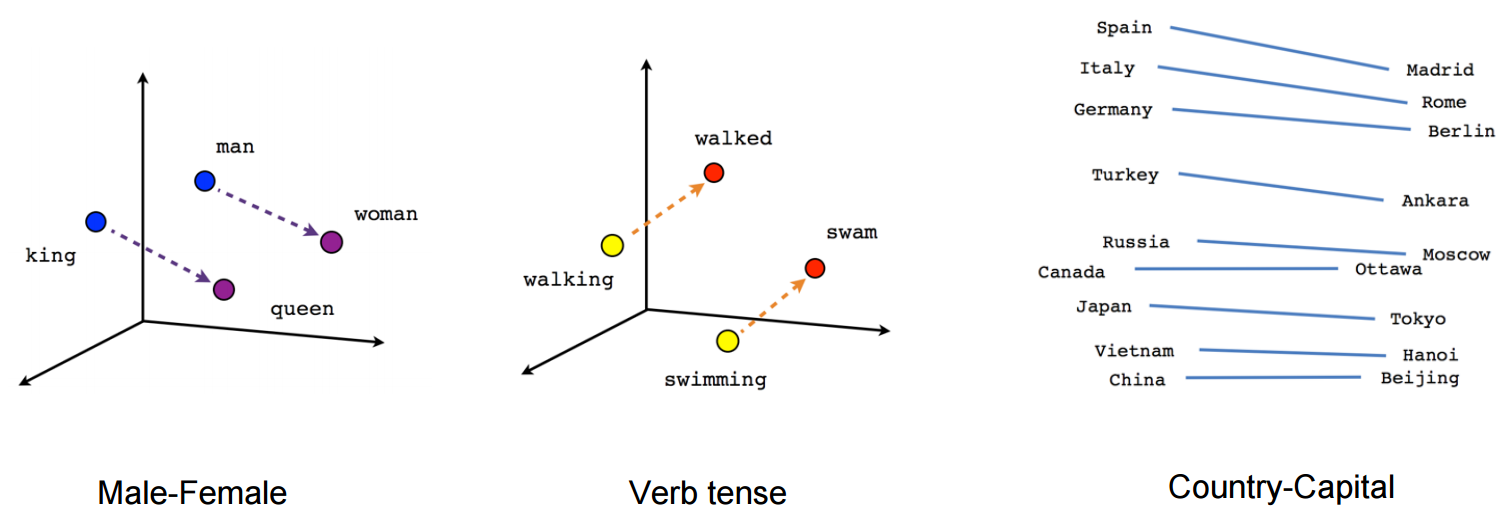
Blog: Aquí hay un artículo que explica las incrustaciones de Word en gran detalle.
Papel: Un muy buen papel que explica los vectores de palabras en detalle. Una lectura obligada para una comprensión profunda de los vectores de palabras.
Herramienta: Un navegador basado herramienta para visualizar vectores de palabras.
Vectores de Word previamente entrenados: Aquí hay una lista exhaustiva de Vectores de Word pre-entrenados en 294 idiomas por facebook.
Implementación: Así es como puede obtener Word Vector de una palabra previamente entrenado usando el paquete gensim.
Descargar el Vectores de Word previamente entrenados en Google News desde aquí.
#!pip install gensimfrom gensim.models.keyedvectors import KeyedVectorsword_vectors=KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)word_vectors['human']
Implementación: Así es como puede entrenar sus propios vectores de palabras usando gensim
sentence=[['first','sentence'],['second','sentence']]model = gensim.models.Word2Vec(sentence, min_count=1,size=300,workers=4)
4. Etiquetado de parte del discurso
¿Qué es el etiquetado de parte del discurso ?: En términos simplistas, el etiquetado de parte del discurso es el proceso de marcar palabras en una oración como sustantivos, verbos, adjetivos, adverbios, etc.. Por ejemplo, en la oración-
«Ashok mató a la serpiente con un palo»
Las partes del discurso se identifican como:
Ashok PROPN
delicado VERBO
los DET
serpiente SUSTANTIVO
con ADP
a DET
palo SUSTANTIVO
. PUNCT
Prueba 1: Esta papel de choi apropiadamente titulado La última esencia del estado de la técnica presenta un método novedoso llamado Dynamic Feature Induction que logra el estado del arte en la tarea de etiquetado POS
Documento 2: Este papel presenta la realización de etiquetado POS sin supervisión utilizando modelos Anchor Hidden Markov.
Implementación: Así es como podemos realizar el etiquetado de POS usando spacy.
#!pip install spacy#!python -m spacy download en nlp=spacy.load('en')sentence="Ashok killed the snake with a stick"for token in nlp(sentence): print(token,token.pos_)
5. Desambiguación de entidades nombradas
¿Qué es la desambiguación de entidades nombradas ?: La desambiguación de entidades nombradas es el proceso de identificar las menciones de entidades en una oración. Por ejemplo, en la oración-
«Apple obtuvo unos ingresos de 200 mil millones de dólares en 2016»
Es tarea de Designación de entidades nombradas inferir que Apple en la oración es la empresa Apple y no una fruta.
Entidad nombrada, en general, requiere una base de conocimiento de entidades que puede usar para vincular entidades en la oración a la base de conocimiento.
Documento 1: Este artículo de Huang hace uso de modelos de relación semántica profunda basados en redes neuronales profundas junto con la base de conocimientos para lograr un resultado de vanguardia en desambiguación de entidades nombradas.
Documento 2: Este artículo de Ganea y Hofmann hacer uso de la atención neuronal local junto con las incrustaciones de Word y sin funciones creadas manualmente.
6. Reconocimiento de entidad nombrada
¿Qué es el reconocimiento de entidad nombrada ?: El reconocimiento de entidades nombradas es la tarea de identificar entidades en una oración y clasificarlas en categorías como una persona, organización, fecha, ubicación, hora, etc. Por ejemplo, una NER tomaría una oración como:
«Ram of Apple Inc. viajó a Sydney el 5 de octubre de 2017»
y devuelve algo como
RAM
de
manzana ORG
C ª. ORG
viajado
para
Sydney GPE
sobre
Quinto FECHA
octubre FECHA
2017 FECHA
Aquí, ORG significa Organización y GPE significa ubicación.
El problema con las NER actuales es que incluso las NER de última generación tienden a tener un rendimiento deficiente cuando se utilizan en un dominio de datos que es diferente de los datos en los que se entrenó la NER.

Papel: Este excelente papel utiliza LSTM bidireccionales y combina métodos de aprendizaje supervisados y no supervisados para lograr un resultado de vanguardia en el reconocimiento de entidades nombradas en 4 idiomas.
Implementación: A continuación, se explica cómo puede realizar el reconocimiento de entidad con nombre utilizando spacy.
import spacynlp=spacy.load('en')sentence="Ram of Apple Inc. travelled to Sydney on 5th October 2017"for token in nlp(sentence): print(token, token.ent_type_)
7. Análisis de sentimiento
¿Qué es el análisis de sentimiento ?: El análisis de sentimientos es una amplia gama de análisis subjetivos que utiliza técnicas de procesamiento de lenguaje natural para realizar tareas como identificar el sentimiento de una reseña de un cliente, sentimiento positivo o negativo en una oración, juzgar el estado de ánimo mediante análisis de voz o análisis de texto escrito, etc. Por ejemplo:
“No me gustó el helado de chocolate” – es una experiencia negativa del helado.
«No odié el helado de chocolate»: puede considerarse una experiencia neutra
Existe una amplia gama de métodos que se utilizan para realizar análisis de sentimientos, desde contar las palabras negativas y positivas en una oración hasta usar LSTM con incrustaciones de palabras.
Blog 1: Este artículo se centra en realizar análisis de sentimiento en tweets de películas
Blog 2: Este artículo se centra en realizar un análisis de sentimientos de los tweets durante la inundación de Chennai.
Documento 1: Este papel adopta el enfoque del método de aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... con el método Naive Bayes para clasificar las revisiones de IMDB.
Documento 2: Este papel utiliza el método de aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la... con LDA para identificar aspectos y sentimientos de las opiniones generadas por los usuarios. Este documento es sobresaliente en el sentido de que aborda el problema de la escasez de reseñas comentadas.
Repositorio: Este es un repositorio impresionante de los trabajos de investigación e implementación del análisis de sentimientos en varios idiomas.
Conjunto de datos 1: Conjunto de datos de opinión de varios dominios, versión 2.0
Conjunto de datos 2: Conjunto de datos de análisis de sentimiento de Twitter
Realice el análisis de opinión de Twitter usted mismo.
8. Similitud de texto semántico
¿Qué es la similitud semántica de texto ?: La similitud semántica del texto es el proceso de analizar la similitud entre dos fragmentos de texto con respecto al significado y la esencia del texto en lugar de analizar la sintaxis de los dos fragmentos de texto. Además, la similitud es diferente a la relación.
Por ejemplo –
El automóvil y el autobús son similares, pero el automóvil y el combustible están relacionados.
Documento 1: Este papel presenta los diferentes enfoques para medir la similitud de texto en detalle. Un artículo de lectura obligada para conocer los enfoques existentes en un solo lugar.
Documento 2: Este papel presenta las CNN para clasificar un par de dos textos breves
Documento 3: Este papel hace uso de Tree-LSTM que logran un resultado de vanguardia en relación semántica de textos y clasificación semántica.
9. Identificación del idioma
¿Qué es la identificación del idioma ?: La identificación del idioma es la tarea de identificar el idioma en el que se encuentra el contenido. Hace uso de las propiedades estadísticas y sintácticas del idioma para realizar esta tarea. También puede considerarse como un caso especial de clasificación de texto.
Blog: En esta publicación de blog de fastText, introducen una nueva herramienta que puede identificar 170 idiomas con 1 MB de uso de memoria.
Documento 1: Este papel analiza 7 métodos de identificación de idiomas de 285 idiomas.
Documento 2: Este papel describe cómo se pueden utilizar las redes neuronales profundas para lograr resultados de vanguardia en la identificación automática de idiomas.
10. Resumen de texto
¿Qué es el resumen de texto ?: El resumen de texto es el proceso de acortar un texto identificando los puntos importantes del texto y creando un resumen utilizando estos puntos. El objetivo del resumen de texto es retener la máxima información junto con el máximo acortamiento del texto sin alterar el significado del texto.
Documento 1: Este papel describe un enfoque basado en el modelo de atención neuronal para el resumen de oraciones abstractas.
Documento 2: Este papel describe cómo se pueden utilizar los RNN secuencia a secuencia para lograr resultados de vanguardia en el resumen de texto.
Repositorio: Este repositorio de Google Brain El equipo tiene los códigos para usar un modelo secuencia a secuencia personalizado para el resumen de texto. El modelo está entrenado en un conjunto de datos Gigaword.
Solicitud: El robot autotldr de Reddit utiliza el resumen de texto para resumir artículos en los comentarios de una publicación. Esta característica resultó ser muy famosa entre los usuarios de Reddit.
Implementación: así es como puede resumir rápidamente su texto usando el paquete gensim.
from gensim.summarization import summarizesentence="Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.Automatic data summarization is part of machine learning and data mining. The main idea of summarization is to find a subset of data which contains the information of the entire set. Such techniques are widely used in industry today. Search engines are an example; others include summarization of documents, image collections and videos. Document summarization tries to create a representative summary or abstract of the entire document, by finding the most informative sentences, while in image summarization the system finds the most representative and important (i.e. salient) images. For surveillance videos, one might want to extract the important events from the uneventful context.There are two general approaches to automatic summarization: extraction and abstraction. Extractive methods work by selecting a subset of existing words, phrases, or sentences in the original text to form the summary. In contrast, abstractive methods build an internal semantic representation and then use natural language generation techniques to create a summary that is closer to what a human might express. Such a summary might include verbal innovations. Research to date has focused primarily on extractive methods, which are appropriate for image collection summarization and video summarization."summarize(sentence)
Notas finales
Así que se trataba de las tareas más comunes de PNL junto con sus recursos relevantes en forma de blogs, artículos de investigación, repositorios y aplicaciones, etc. Si lo cree, hay un gran recurso sobre cualquiera de estas 10 tareas que me he perdido o usted desea sugerir agregar otra tarea, entonces no dude en comentar sus sugerencias y comentarios.
También tenemos un gran curso, PNL usando Python, para ti si quieres convertirte en practicante de PNL.
¡Feliz aprendizaje!





