Impulsar el algoritmo en el aprendizaje automático
Impulso puede denominarse un conjunto de algoritmos cuya función principal es convertir a los estudiantes débiles en estudiantes fuertes. Se han vuelto en la corriente principal Industria de la ciencia de datos debido a que han estado en el comunidad de aprendizaje automático durante años. El impulso fue ingresado por primera vez por Freund y Schapire en el año 1997 con su Algoritmo AdaBoost, y desde entonces, el impulso ha sido una técnica predominante para solucionar problemas de clasificación binaria.
¿Por qué los algoritmos de impulso son tan populares?
Para saber esto, en palabras más simples. impulsar algoritmos puede superar a algoritmos más simples como Bosque aleatorio, árboles de decisión o regresión logística. Es una de las principales razones del aumento en la promoción de algoritmos por parte de muchos competidores de aprendizaje automático debido a que los algoritmos de impulso son poderosos. Aún así, pueden mejorar la precisión de predicción de su modelo por una cantidad considerable de factores. Muchos competidores de aprendizaje automático usan un solo algoritmo de impulso o múltiples algoritmos de impulso para solucionar los problemas respectivos.
Explicación del algoritmo de impulso
Impulso combina a los estudiantes débiles para formar un estudiante fuerte, donde un aprendiz débil establece un clasificador ligeramente correlacionado con la clasificación real. A diferencia de un alumno débil, un alumno fuerte es un clasificador asociado con las categorías correctas.
Para saber esto, asumamos un escenario:
Suponga que construye un Modelo de bosque aleatorio que te da una precisión de 75% en el conjunto de datos de validación y, a continuación, decide probar algún otro modelo en el mismo conjunto de datos. Suponga que intenta lineal modelo de regresión y kNN en el mismo conjunto de datos de validación, y ahora su modelo le brinda una precisión de 69% y 92%, respectivamente. Es claro que los tres modelos funcionan de formas absolutamente diferentes y proporcionan resultados absolutamente diferentes en el mismo conjunto de datos.
¿Alguna vez ha pensado, en lugar de simplemente utilizar uno de estos modelos, qué pasa si usamos una combinación de todos estos modelos para hacer las predicciones finales?
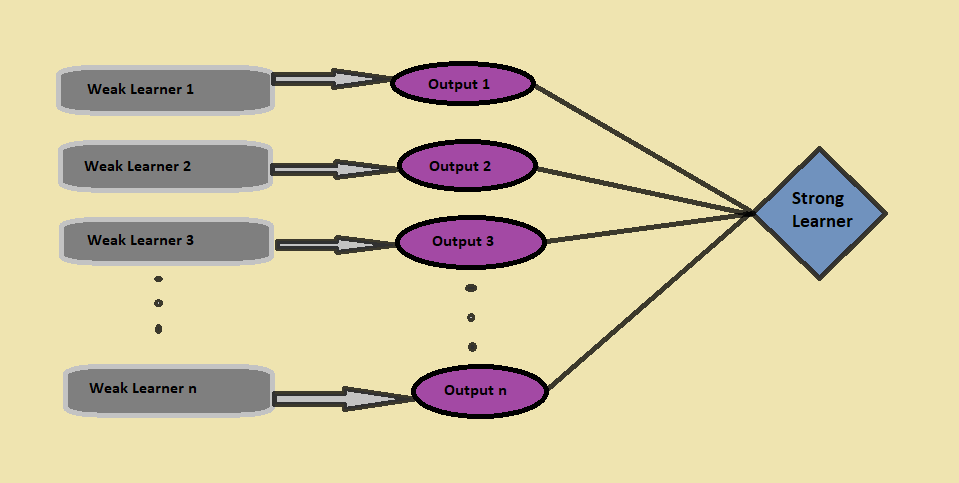
Capturaremos más información de los datos tomando el promedio de predicciones de estos modelos; De manera equivalente, el algoritmo de impulso combina varios modelos más simples (además llamados estudiantes débiles) para generar el resultado final (además llamado estudiante fuerte).
¿Ahora pensaría en cómo identificar a los estudiantes débiles?
Para identificar a los estudiantes débiles, usamos algoritmos de aprendizaje automático con una distribución distinto para cada iteración y para cada algoritmo, genera una nueva regla de predicción débil. Después de muchas iteraciones, el algoritmo de impulso combina a todos los alumnos vulnerables para formar una sola regla de predicción de cadena.
Otra cosa esencial a prestar atención aquí es, ‘¿Cómo determinamos una distribución distinto para cada ronda?’
Hay tres pasos que debemos considerar para seleccionar la distribución correcta:
- El alumno débil considera todas las distribuciones y después asigna el mismo peso a cada observación, después
- Si el error es generado por el pronóstico del primer algoritmo de aprendizaje débil, se presta más atención al error de predicción de las observaciones. Se aplica el siguiente algoritmo de aprendizaje débil.
- Por último, repita el segundo paso hasta que el algoritmo de aprendizaje base alcance su límite o se logre la precisión deseada.
Por fin, como consecuencia, el algoritmo de impulso combina todas las salidas de los estudiantes débiles. Se presenta con un alumno más poderoso y fuerte, que eventualmente mejora la precisión de el pronóstico del modelo (como se ve en la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior).
Al impulsar, en lugar de simplemente combinar los clasificadores aislados, utiliza el mecanismo de elevar los pesos de los puntos de datos mal clasificados en los clasificadores anteriores.
Tipos de algoritmo de impulsos
Es hora de analizar algunos de los tipos esenciales de algoritmos de impulso ahora
1. Aumento de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en...
En el aumento de gradiente algoritmo, entrenamos múltiples modelos secuencialmente, y para cada nuevo modelo, el modelo minimiza gradualmente la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... usando el método Gradient Descent. los Algoritmo de aumento de árbol de degradado acepta árboles de decisión como los débiles delgados debido a que los nodos en un árbol de decisión consideran una rama distinto de características para elegir la mejor división, lo que significa que todos los árboles no son iguales. Por eso, pueden capturar diferentes salidas de los datos todo el tiempo.
El algoritmo de aumento del árbol de gradiente se construye secuencialmente debido a que, para cada árbol nuevo, el modelo considera los errores del último árbol, y la decisión de cada árbol sucesivo se basa en los errores cometidos por el árbol anterior.
Los algoritmos de Gradient Boosting se usan principalmente para problemas de clasificación y regresión.
Código Python:
de sklearn.ensemble importar GradientBoostingClassifier #Para clasificación
de sklearn.ensemble importar GradientBoostingRegressor #Para regresión
cl = GradientBoostingClassifier (n_estimators = 100, learning_rate = 1.0, max_depth = 1)
cl.fit (Xtrain, ytrain)
dónde:
n_estimators El parámetro se utiliza para controlar el número de estudiantes débiles,
tasa de aprendizaje El parámetro controla la contribución de todos los alumnos vulnerables en el resultado final,
máxima profundidad El parámetro es para la profundidad máxima de los estimadores de regresión individuales para limitar el número de nodos en el árbol.
2. AdaBoost (refuerzo adaptativo)
El algoritmo AdaBoost, abreviatura de Impulso adaptativo, es una técnica de impulso en el aprendizaje automático que se utiliza como Método de conjunto. En Impulso adaptativo, todas las ponderaciones se reasignan a cada instancia en la que se asignan mayores ponderaciones a los modelos clasificados incorrectamente, y se ajusta a la secuencia de estudiantes débiles en diferentes ponderaciones.
Adaboost comienza por hacer predicciones sobre el conjunto de datos original en un lenguaje sencillo, y después da la misma ponderación a cada observación. Si el pronóstico realizada con el primer alumno es incorrecta, asigna la mayor relevancia para la declaración predicha incorrectamente y un procedimiento iterativo. Continúa agregando nuevos alumnos hasta que se cumple el límite en el modelo.
Podemos utilizar cualquier algoritmo de aprendizaje automático con Adaboost como estudiantes débiles si acepta pesos en el conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y se utiliza tanto para problemas de regresión como de clasificación.
Código Python:
de sklearn.ensemble importar AdaBoostClassifier #Para clasificación
desde sklearn.ensemble importar AdaBoostRegressor #For Regression
de sklearn.tree importar DecisionTreeClassifier
dtree = DecisionTreeClassifier ()
cl = AdaBoostClassifier (n_estimators = 100, base_estimator = dtree, learning_rate = 1)
cl.fit (xtrain, ytrain)
dónde:
n_estimators y el parámetro learning_rate tiene el mismo propósito que en el caso del algoritmo Gradient Boosting,
estimador_base El parámetro ayuda a especificar diferentes algoritmos de aprendizaje automático.
3. XGBoost
El algoritmo XGBoost, abreviatura de Extreme Gradient Boosting, es simplemente una versión improvisada del algoritmo de aumento de gradiente, y el procedimiento de trabajo de ambos es casi el mismo. Un punto crucial en XGBoost es eso Implementa procesamiento paralelo a nivel de nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos...., haciéndolo más potente y rápido que el algoritmo de aumento de gradiente.. XGBoost reduce el sobreajuste y mejora el rendimiento general a través de la inclusión de varias técnicas de regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones.... a través de el establecimiento de los hiperparámetros del algoritmo XGBoost.
Un punto importante a prestar atención sobre XGBoost es eso no necesita preocuparse por los valores perdidos en el conjunto de datos debido a que, a lo largo del procedimiento de entrenamiento, el modelo mismo aprende dónde encajar los valores perdidos, dicho de otra forma, el nodo izquierdo o el nodo correcto.
XGBoost se utiliza principalmente para problemas de clasificación, pero se puede usar para problemas de regresión.
Código Python:
importar xgboost como xgb
xgb_model = xgb.XGBClassifier (tasa_de_aprendizaje = 0,001, profundidad_máxima = 1, n_estimadores_100)
xbg_model.fit (x_train, y_train)
NOTAS FINALES
Este post analizó los algoritmos de impulso en el aprendizaje automático, explicó qué son los algoritmos de impulso y los tipos de algoritmos de impulso: Adaboost, Gradient Boosting y XGBoost. Además miramos sus respectivos códigos y parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de Python involucrados.
Si tiene alguna duda, puede comunicarse conmigo en mi LinkedIn @mrinalwalia.
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





