Las métricas de distancia son una parte clave de varios algoritmos de aprendizaje automático. Estas métricas de distancia se utilizan tanto en el aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... como no supervisado, generalmente para calcular la similitud entre los puntos de datos.
Una métrica de distancia efectiva mejora el rendimiento de nuestro modelo de aprendizaje automático, ya sea para tareas de clasificación o agrupación.
Digamos que queremos crear conglomerados usando el algoritmo de Clustering de K-Means o el de vecino más cercano para resolver un problema de clasificación o regresión. ¿Cómo definiría aquí la similitud entre diferentes observaciones? ¿Cómo podemos decir que dos puntos son similares entre sí?
Esto sucederá si sus características son similares, ¿verdad? Cuando tracemos estos puntos, estarán más cerca uno del otro en la distancia.
Por lo tanto, podemos calcular la distancia entre puntos y luego definir la similitud entre ellos. Aquí está la pregunta del millón de dólares: ¿cómo calculamos esta distancia y cuáles son las diferentes métricas de distancia en el aprendizaje automático?
Eso es lo que pretendemos responder en este artículo. Analizaremos 4 tipos de métricas de distancia en aprendizaje automático y entender cómo funcionan en Pitón.
4 tipos de métricas de distancia en el aprendizaje automático
- Distancia euclidiana
- Distancia de Manhattan
- Distancia de Minkowski
- Distancia de Hamming
Comencemos con la métrica de distancia más utilizada: la distancia euclidiana.
1. Distancia euclidiana
La distancia euclidiana representa la distancia más corta entre dos puntos.
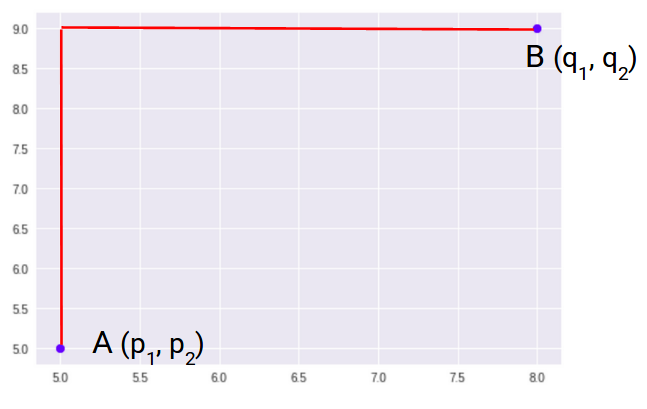
La mayoría de los algoritmos de aprendizaje automático, incluidos K-Means, utilizan esta métrica de distancia para medir la similitud entre las observaciones. Digamos que tenemos dos puntos como se muestra a continuación:
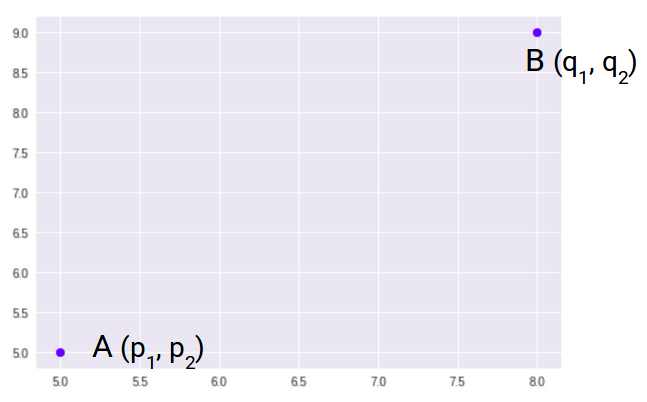
Entonces, la distancia euclidiana entre estos dos puntos A y B será:
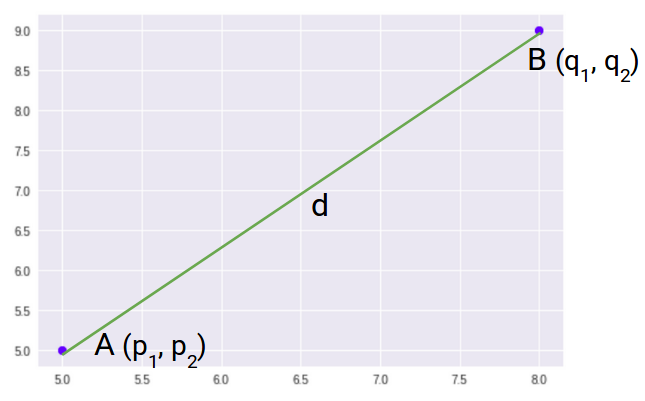
Aquí está la fórmula para la distancia euclidiana:
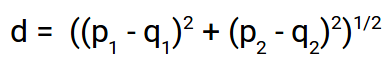
Usamos esta fórmula cuando se trata de 2 dimensiones. Podemos generalizar esto para un espacio n-dimensional como:
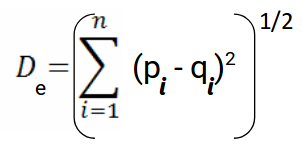
Dónde,
- n = número de dimensiones
- pi, qi = puntos de datos
Codifiquemos la distancia euclidiana en Pitón. Esto le dará una mejor comprensión de cómo funciona esta métrica de distancia.
Primero importaremos las bibliotecas necesarias. Usaré la biblioteca SciPy que contiene códigos preescritos para la mayoría de las funciones de distancia utilizadas en Python:
![]()
Estos son los dos puntos de muestra que usaremos para calcular las diferentes funciones de distancia. Calculemos ahora la distancia euclidiana entre estos dos puntos:
![]()
Así es como podemos calcular la distancia euclidiana entre dos puntos en Python. Entendamos ahora la métrica de la segunda distancia, la distancia de Manhattan.
2. Distancia de Manhattan
La distancia de Manhattan es la suma de las diferencias absolutas entre puntos en todas las dimensiones.
Podemos representar la distancia de Manhattan como:
Dado que la representación anterior es bidimensional, para calcular la distancia de Manhattan, tomaremos la suma de las distancias absolutas en las direcciones x e y. Entonces, la distancia de Manhattan en un espacio bidimensional se da como:
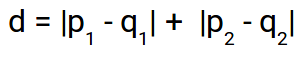
Y la fórmula generalizada para un espacio n-dimensional se da como:
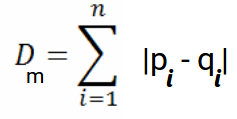
Dónde,
- n = número de dimensiones
- pi, qi = puntos de datos
Ahora, calcularemos la distancia de Manhattan entre los dos puntos:
![]()
Tenga en cuenta que La distancia de Manhattan también se conoce como distancia de cuadra de la ciudad. SciPy tiene una función llamada Manzana de la ciudad que devuelve la distancia de Manhattan entre dos puntos.
Veamos ahora la siguiente métrica de distancia: la distancia de Minkowski.
3. Distancia de Minkowski
La distancia de Minkowski es la forma generalizada de la distancia euclidiana y de Manhattan.
La fórmula para la distancia de Minkowski se da como:
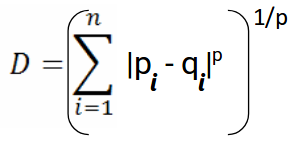
Aquí, p representa el orden de la norma. Calculemos la Distancia de Minkowski del orden 3:
![]()
El parámetro p de la métrica de distancia de Minkowski de SciPy representa el orden de la norma. Cuando el orden (p) es 1, representará la Distancia de Manhattan y cuando el orden en la fórmula anterior es 2, representará la Distancia euclidiana.
Verifiquemos eso en Python:
![]()
Aquí, puede ver que cuando el orden es 1, tanto Minkowski como Manhattan Distance son iguales. Verifiquemos también la distancia euclidiana:

Cuando el orden es 2, podemos ver que las distancias de Minkowski y Euclidean son las mismas.
Hasta ahora, hemos cubierto las métricas de distancia que se utilizan cuando se trata de variables continuas o numéricas. Pero ¿y si tenemos variables categóricas? ¿Cómo podemos decidir la similitud entre variables categóricas? Aquí es donde podemos hacer uso de otra métrica de distancia llamada Distancia de Hamming.
4. Distancia de Hamming
La distancia de Hamming mide la similitud entre dos cuerdas de la misma longitud. La distancia de Hamming entre dos cuerdas de la misma longitud es el número de posiciones en las que los caracteres correspondientes son diferentes.
Entendamos el concepto con un ejemplo. Digamos que tenemos dos cadenas:
«Euclidiana» y «Manhattan»
Dado que la longitud de estas cuerdas es igual, podemos calcular la distancia de Hamming. Iremos personaje a personaje y uniremos las cadenas. El primer carácter de ambas cadenas (eym respectivamente) es diferente. De manera similar, el segundo carácter de ambas cadenas (uya) es diferente. etcétera.
Mire con atención: siete caracteres son diferentes, mientras que dos caracteres (los dos últimos caracteres) son similares:

Por lo tanto, la Distancia de Hamming aquí será 7. Tenga en cuenta que cuanto mayor sea la Distancia de Hamming entre dos cuerdas, más diferentes serán esas cuerdas (y viceversa).
Veamos cómo podemos calcular la distancia de Hamming de dos cadenas en Python. Primero, definiremos dos cadenas que usaremos:
Estas son las dos cadenas «euclidiana» y «manhattan» que también hemos visto en el ejemplo. Calculemos ahora la distancia de Hamming entre estas dos cuerdas:
![]()
Como vimos en el ejemplo anterior, la distancia de Hamming entre “euclidiana” y “manhattan” es 7. También vimos que la distancia de Hamming solo funciona cuando tenemos cuerdas de la misma longitud.
Veamos qué sucede cuando tenemos cadenas de diferentes longitudes:
![]()
Puede ver que las longitudes de ambas cadenas son diferentes. Veamos qué pasará cuando intentemos calcular la distancia de Hamming entre estas dos cuerdas:
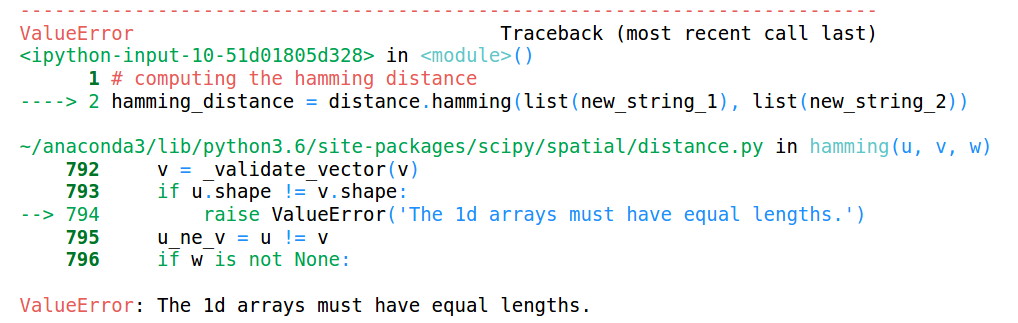
Esto arroja un error que dice que las longitudes de las matrices deben ser las mismas. Por eso, La distancia de Hamming solo funciona cuando tenemos cadenas o matrices de la misma longitud.
Estas son algunas de las medidas de similitud o las matrices de distancia que se utilizan generalmente en Machine Learning.





