Este artículo fue publicado como parte del Blogatón de ciencia de datos
1. Introducción
En este trabajo, presentamos la relación del rendimiento del modelo con un tamaño de conjunto de datos variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... y un número variable de clases de destino. Hemos realizado nuestros experimentos en reseñas de productos de Amazon.
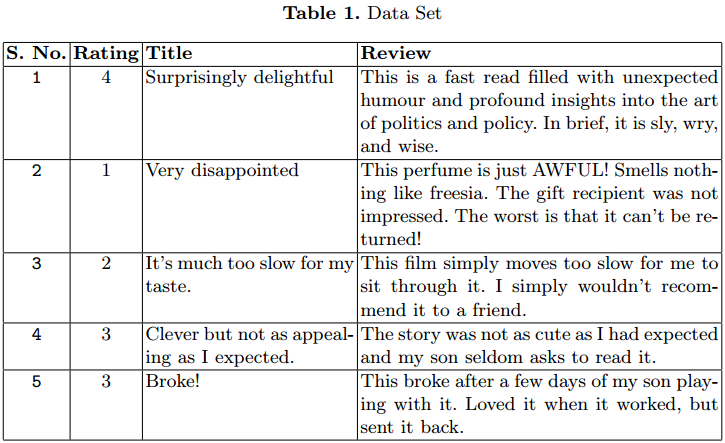
El conjunto de datos contiene el título de la reseña, el texto de la reseña y las calificaciones. Hemos considerado las calificaciones como nuestra clase de salida. Además, hemos realizado tres experimentos (polaridad 0/1), tres clases (positivo, negativo, neutral) y cinco clases (calificación de 1 a 5). Hemos incluido tres modelos tradicionales y tres de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
Modelos de aprendizaje automático
1. Regresión logística (LR)
2. Máquina de vectores de soporte (SVM)
3. Naive-Bayes (NB)
Modelos de aprendizaje profundo
1. Red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... de convolución (CNN)
2. Memoria a corto plazo (LSTM)
3. Unidad recurrente cerrada (GRU)
2. El conjunto de datos
Usamos el conjunto de datos de revisión de productos de Amazon para nuestro experimento. El conjunto de datos contiene 3,6 millones de instancias de la revisión del producto en forma de texto.
Se han proporcionado archivos separados de tren (3M) y de prueba (0,6M) en formato CSV. Cada instancia tiene 3 atributos. El primer atributo es el clasificación entre 1 y 5. El segundo atributo es el título de la revisión. El último es el texto de revisión.
En la Tabla 1 se dan algunos casos. Hemos considerado solo 1,5 M.
3. Experimento para análisis
Ya hemos mencionado que todo el experimento se realizó para clasificación binaria, de tres clases y de cinco clases. Hemos realizado algunos pasos de procesamiento previo en el conjunto de datos antes de pasarlo a los modelos de clasificación. Cada experimento se realizó de forma incremental.
Comenzamos nuestra capacitación con 50000 instancias y aumentamos a 1,5 millones de instancias para capacitación. Por fin, registramos los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de rendimiento de cada modelo.
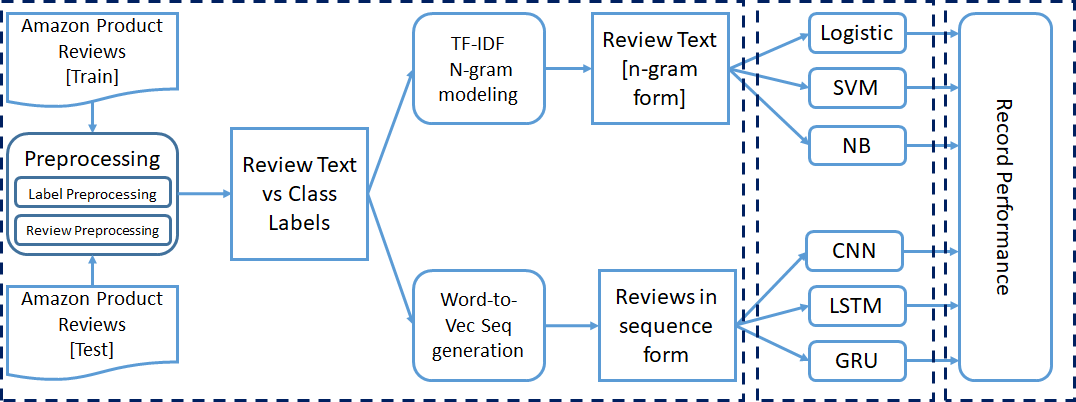
3.1 Preprocesamiento
3.1.1 Mapeo de etiquetas:
Hemos considerado las calificaciones como la clase para el texto de revisión. El rango del atributo de calificación está entre 1 y 5. Necesitamos asignar estas calificaciones al número de clases, consideradas para el experimento en particular.
a) Clasificación binaria: –
Aquí, asignamos la calificación 1 y 2 a la clase 0 y calificación 4 y 5 a clase 1. Esta forma de clasificación puede tratarse como un problema de clasificación de sentimientos, donde las reseñas con 1 y 2 calificaciones están en clase negativa y 4 y 5 están en clase positiva.
No hemos considerado las revisiones con una calificación de 3 para el experimento de clasificación binaria. Por lo tanto, obtenemos menos instancias para el entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... en comparación con los otros dos experimentos.
b) Clasificación de tres clases: –
Aquí, ampliamos nuestro experimento de clasificación anterior. Ahora consideramos la calificación 3 como una nueva clase separada. La nueva asignación de calificaciones a clases es la siguiente: Calificación 1 y 2 asignada a la clase 0 (Negativo), Clasificación 3 asignada a la clase 1 (Neutral) y calificación 4 y 5 asignados a la clase 2 (Positivo).
Instancias para clase 1 son muy inferiores a la clase 0 y 2, lo que crea un problema de desequilibrio de clases. Por lo tanto, usamos micropromedio al calcular las medidas de rendimiento.
c) Clasificación de cinco clases: –
Aquí, consideramos cada calificación como una clase separada. La asignación es la siguiente: Clasificación 1 asignada a la clase 0, Clasificación 2 asignada a la clase 1, Clasificación 3 asignada a la clase 2, Clasificación 4 asignada a la clase 3y la clasificación 5 asignada a la clase 4.
3.1.2 Revisar el procesamiento previo de texto:
Las reseñas de productos de Amazon están en formato de texto. Necesitamos convertir los datos de texto a un formato numérico, que se puede utilizar para entrenar los modelos.
Para los modelos de aprendizaje automático, convertimos el texto de revisión en formato vectorial TF-IDF con la ayuda de el sklearn Biblioteca. En lugar de tomar cada palabra individualmente, consideramos el modelo de n-gramas mientras creamos los vectores TF IDF. El rango de N-gramos se establece en 2 – 3, y el valor de función máxima se establece en 5000.
Para los modelos de aprendizaje profundo, necesitamos convertir los datos de secuencia de texto en datos de secuencia numérica. Aplicamos el palabra a vector modelado para convertir cada palabra en el vector equivalente.
El conjunto de datos contiene una gran cantidad de palabras; por lo tanto, la codificación en caliente 1- es muy ineficaz. Aquí hemos utilizado un pre-entrenado word2Vec modelo para representar cada palabra con un vector de columna de tamaño 300. Establecemos la longitud máxima de la secuencia igual a 70.
Las reseñas con una longitud de palabra inferior a 70 se rellenan con ceros al principio. Para las reseñas con una longitud de palabra superior a 70, seleccionamos las primeras 70 palabras para el procesamiento de word2Vec.
3.2 Entrenamiento del modelo de clasificación
Hemos mencionado anteriormente que hemos tomado tres modelos tradicionales de aprendizaje automático (LR, SVM, NB) y tres modelos de aprendizaje profundo (CNN, LSTM, GRU). El texto preprocesado con la información de la etiqueta se pasa a modelos para su entrenamiento.
Al principio, entrenamos los seis modelos con 50000 instancias y los probamos con 5000 instancias. Para la próxima iteración, agregamos 50000 y 5000 instancias más en el tren y el conjunto de prueba, respectivamente. Realizamos 30 iteraciones; por lo tanto, consideramos 1.5 M, 150000 instancias para el tren y el conjunto de prueba en la última iteración.
La formación mencionada anteriormente se realiza para los tres tipos de experimentos de clasificación.
3.3 Configuraciones del modelo
Hemos utilizado la configuración predeterminada de hiperparámetros de todos los clasificadores tradicionales utilizados en este experimento. En CNN, el tamaño de entrada es 70 con un tamaño de incrustación de 300. La omisión de la capa de incrustación se establece en 0.3. Se ha aplicado una convolución 1-D en la entrada, con el tamaño de salida de la convolución establecido en 100. El tamaño del kernel se mantiene en 3. ReluLa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción... La función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones.... se ha utilizado en la capa de convolución. Para el proceso de agrupación, se utiliza la agrupación máxima. El Optimizador de Adam se utiliza con una función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... de entropía cruzada.
LSTM y GRU también tienen la misma configuración de hiperparámetros. El tamaño de la capa de salidaLa "capa de salida" es un concepto utilizado en el ámbito de la tecnología de la información y el diseño de sistemas. Se refiere a la última capa de un modelo de software o arquitectura que se encarga de presentar los resultados al usuario final. Esta capa es crucial para la experiencia del usuario, ya que permite la interacción directa con el sistema y la visualización de datos procesados.... cambia con el experimento en ejecución.
3.4 Medidas de desempeño

Fórmula de puntuación F
Hemos tomado la puntuación F1 para analizar el rendimiento de los modelos de clasificación con diferentes etiquetas de clase y recuento de instancias. Existe una compensación entre Precision y Recall si intentamos mejorar Recall, Precision se vería comprometida, y lo mismo se aplica a la inversa.
La puntuación F1 combina precisión y recuerdo en forma de media armónica.
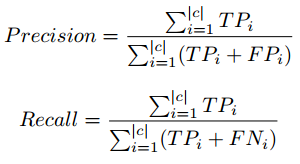
Precisión, fórmula de recuperación en micropromedio
En la clasificación de tres y cinco clases, observamos que el recuento de instancias con calificación 3 es muy inferior en la comparación de otras calificaciones, lo que crea el problema de desequilibrio de clases.
Por lo tanto, utilizamos el concepto de micropromedio al calcular los parámetros de rendimiento. El micropromedio se encarga del desequilibrio de clases al calcular la precisión y la recuperación. Para obtener información detallada sobre Precision, Recall, visite el siguiente enlace: enlace wiki.
4 Resultados y observación
En esta sección, hemos presentado los resultados de nuestros experimentos con diferentes tamaños de conjuntos de datos y el número de etiquetas de clase. Se ha presentado un gráfico separado para cada experimento. Los gráficos se trazan entre el tamaño del conjunto de pruebas y la puntuación F1.
Además, proporcionamos la Figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... 5, que contiene seis subparcelas. Cada subparcela corresponde a un clasificador. Hemos presentado la tasa de cambio entre las puntuaciones de rendimiento de dos experimentos con respecto al tamaño variable del conjunto de pruebas.
Figura 2
La Figura 2 presenta el desempeño de los clasificadores en la tarea de clasificación binaria. En este caso, el tamaño real de la prueba es menor que los datos que hemos tomado para la prueba porque se eliminaron las reseñas con calificación 3.
Los clasificadores de aprendizaje automático (LR, SVM, NB) funcionan de manera constante excepto por ligeras variaciones en los puntos de partida.
El clasificador de aprendizaje profundo (GRU y CNN) comienza con menos rendimiento en comparación con SVM y LR. Después de tres iteraciones iniciales, GRU y CNN dominan continuamente los clasificadores de aprendizaje automático.
El LSTM realiza el aprendizaje más eficaz. LSTM comenzó con el rendimiento más bajo. A medida que el conjunto de entrenamiento cruza 0.3 M, LSTM ha mostrado un crecimiento continuo y terminó con GRU.
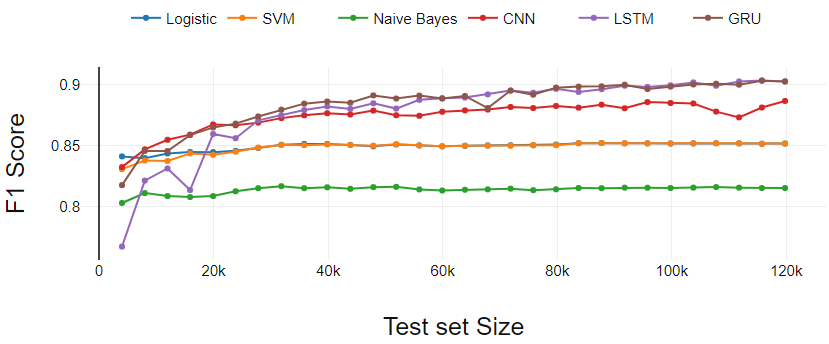
Fig 2. Análisis de rendimiento de clasificación binaria
figura 3
La Figura 3 presenta los resultados del experimento de clasificación de tres clases. El rendimiento de todos los clasificadores se degrada a medida que aumentan las clases. El rendimiento es similar a la clasificación binaria si comparamos un clasificador en particular con otros.
La única diferencia está en el rendimiento de LSTM. Aquí, LSTM ha aumentado continuamente el rendimiento a diferencia de la clasificación binaria. LR funcionó un poco mejor en comparación con SVM. Tanto LR como SVM se desempeñaron por igual en el experimento de clasificación binaria.
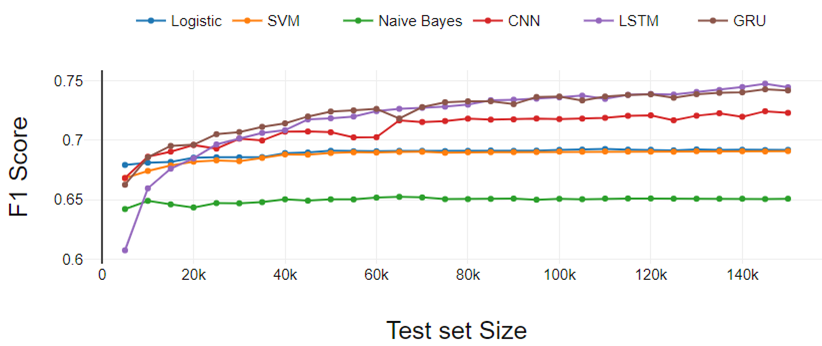
Fig 3. Análisis de rendimiento de clasificación de tres clases
Figura 4
La Figura 4 representa los resultados del experimento de clasificación de cinco clases. Los resultados siguen las mismas tendencias que aparecieron en el experimento de clasificación binaria y de tres clases. Aquí la diferencia de rendimiento entre LR y SVM aumentó un poco más.
Por lo tanto, podemos concluir que la brecha de desempeño de LR y SVM aumenta a medida que aumenta el número de clases.
A partir del análisis general, los clasificadores de aprendizaje profundo funcionan mejor a medida que aumenta el tamaño del conjunto de datos de entrenamiento y los clasificadores tradicionales muestran un rendimiento constante.
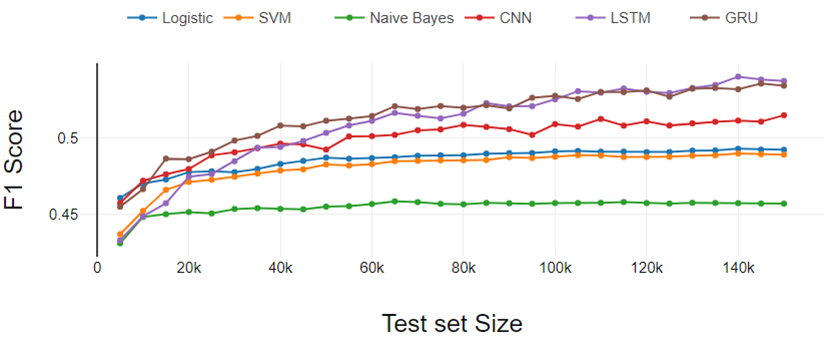
Fig 4. Análisis de rendimiento de clasificación de cinco clases
Figura 5
La Figura 5 representa la relación de rendimiento con respecto al cambio en el número de clases y el tamaño del conjunto de datos. La figura contiene seis subparcelas, una para cada clasificador. Cada subtrama tiene dos líneas; una línea muestra la relación de rendimiento entre la clasificación de tres clases y la clase binaria en diferentes tamaños de conjuntos de datos.
Otra línea representa la relación de rendimiento entre la clasificación de cinco clases y la de tres clases en diferentes tamaños de conjuntos de datos. Hemos encontrado que los clasificadores tradicionales tienen una tasa de cambio constante. Para clasificadores tradicionales, ritmo de cambio es independiente del tamaño del conjunto de datos. No podemos comentar sobre el comportamiento de los modelos de aprendizaje profundo con respecto al cambio en las clases numéricas y el tamaño del conjunto de datos debido al patrón variable en la tasa de cambio.
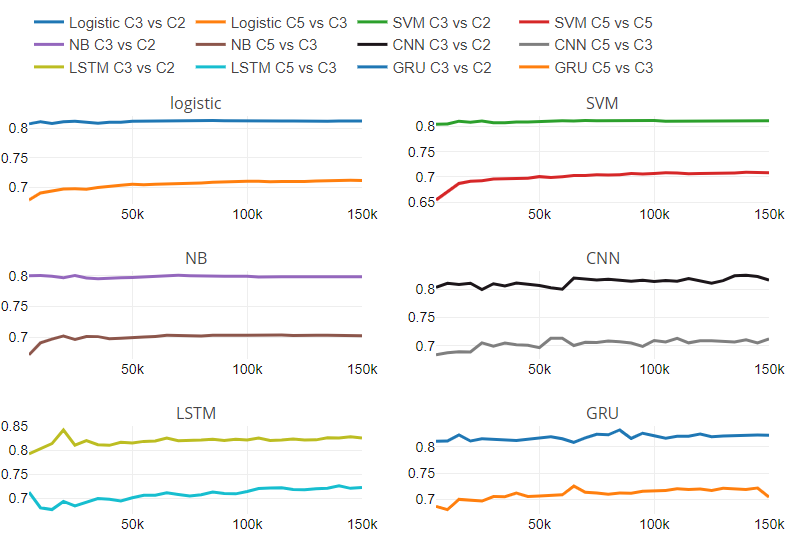
Además del análisis experimental mencionado anteriormente, hemos analizado los datos de texto clasificados erróneamente. Encontramos observaciones interesantes que afectaron la clasificación.
Palabras sarcásticas: –
Los clientes escribieron reseñas sarcásticas sobre los productos. Le han dado la calificación 1 o 2, pero usaron muchas palabras de polaridad positiva. Por ejemplo, un cliente calificó a 1 y escribió la siguiente reseña: “¡Oh! ¡¡Qué cargador tan fantástico tengo !! ”. El clasificador se confundió con este tipo de palabras y frases de polaridad.
Uso de palabras de alta polaridad: –
Los clientes han otorgado una calificación promedio (3) pero utilizaron palabras muy polarizadas en sus reseñas. Por ejemplo, fantástico, tremendo, notable, patético, etc.
Uso de palabras raras: –
Teniendo un conjunto de datos de tamaño 3.6M, todavía encontramos muchas palabras poco comunes, que afectaron el desempeño de la clasificación. Los errores ortográficos, los acrónimos, las palabras de formas cortas utilizadas por los revisores también son factores importantes.
5. Nota final
Hemos analizado el rendimiento de los modelos tradicionales de aprendizaje automático y aprendizaje profundo con diferentes tamaños de conjuntos de datos y el número de la clase objetivo.
Hemos descubierto que los clasificadores tradicionales pueden aprender mejor que los clasificadores de aprendizaje profundo si el conjunto de datos es pequeño. Con el aumento en el tamaño del conjunto de datos, los modelos de aprendizaje profundo obtienen un impulso en el rendimiento.
Hemos investigado la tasa de cambio en el desempeño del clasificador de binario a tres clases y tres clases a cinco clases problema con el tamaño variable del conjunto de datos.
Hemos usado Keras biblioteca de aprendizaje profundo para la experimentación. Los resultados y los scripts de Python están disponibles en el siguiente enlace: Enlace de GitHub.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





