Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Los humanos deberían estar preocupados por la amenaza que representa la inteligencia artificial. – Bill Gates
Estoy seguro de que la cita anterior quiere transmitirnos algún mensaje, definitivamente deberíamos pensarlo. Qué piensas «¿Estoy en lo cierto?», por favor comparta su opinión en el cuadro de comentarios, definitivamente los leeré, lo que me ayudará a entender que «¿Hay algún impacto negativo de estas tecnologías en las especies humanas o no?» o “¿Será esta tecnología la responsable de la extinción de la especie humana?”.
Empecemos, hoy nuestra agenda es que vamos a discutir “¿Existe realmente alguna necesidad de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud...?”.

En los últimos años probablemente hemos escuchado mucho sobre el aprendizaje profundo, pero ¿de qué se trata realmente? Aquí hay otra pregunta curiosa que nos viene a la mente: «¿Por qué el aprendizaje profundo recién ahora acaba de ser el centro de atención?». Primero entendamos qué es realmente la Inteligencia Artificial.
Inteligencia artificial
Inteligencia artificial es un término genérico para una rama de la informática. Su objetivo es que la máquina imite la cognición humana, centrándose en la resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... de problemas complejos. El único objetivo de la IA es que la Máquina pueda tener inteligencia similar a la humana en el futuro. Se refiere a la simulación de la inteligencia humana en máquinas que están programadas para que la máquina sea capaz de pensar como humanos e imitar sus acciones.
El aprendizaje automático es un subconjunto de la inteligencia artificial que básicamente se centra en cómo hacer que una computadora sea capaz de aprender por sí misma sin la necesidad de instrucciones codificadas a mano. Los sistemas de aprendizaje automático analizan una gran cantidad de datos y aprenden de errores anteriores. Los resultados se generan a partir de algoritmos que completan su tarea de manera eficiente.
El aprendizaje profundo es un subconjunto dentro del aprendizaje automático, esta tecnología intenta imitar la actividad de las neuronas en el cerebro humano mediante la multiplicación de matrices. Esta disposición se llama red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas.... En realidad, el concepto de redes neuronales entró en escena en 1957 y se probó por primera vez en 1980, pero no resultó útil. La red profunda solo se vuelve factible por solo dos razones, la primera es un aumento en la potencia de cómputo y la segunda es una gran cantidad de datos. Después de leer hasta este punto, definitivamente dudará de que siempre que hablemos de Deep Learning cada vez que “gran cantidad de datos” este término venga con Deep Learning. En realidad, ¿por qué las redes neuronales necesitan tanta cantidad de datos?
La respuesta a la pregunta anterior es, en realidad, cuanto más datos, más robusta será su red. Debido a su robustez, su red dará resultados mejores y más precisos que cualquier otro algoritmo. Pongámonos en la piel del Deep Learning😁. Suponga que ha visto 3 fotografías del gato, tomadas desde diferentes ángulos. Pero por otro lado, has visto miles de gatos diferentes, ahora te resulta mucho más fácil reconocer uno. Esto es importante para los datos. En Deep Learning, los datos son la esencia que permite que la máquina aprenda.
Nacimiento de la red neuronal
El verdadero campo del Deep Learning comenzó en 2012, antes de 2012, la mayoría de los expertos creían que Neural Network era inútil. En 2012, Deep Learning se convierte en el centro de atención. En 2012, se utilizó por primera vez la red neuronal en la competencia para reconocer el conjunto de datos de imágenes más grande del mundo y, de hecho, superó todos los tipos de algoritmos anteriores. En este movimiento, el mundo se da cuenta del poder real de las redes neuronales. Este fue el nacimiento de la Red Neural.
Mi opinión sobre «¿Existe alguna necesidad de aprendizaje profundo🤔?»
Antes de mi opinión, veamos un gráfico investigado por google.
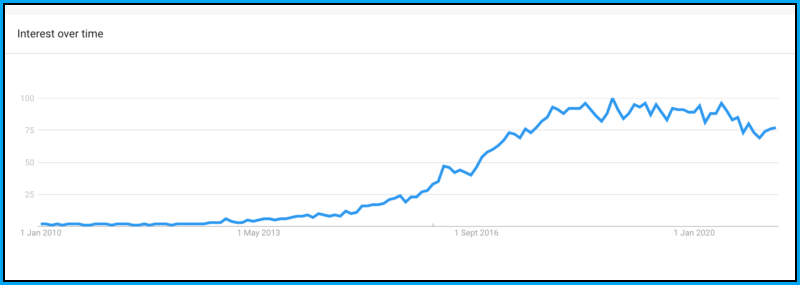
Según la búsqueda de Google después de 2013, la gente en su mayoría investigaba mucho sobre Deep Learning. El gráfico anterior muestra el interés de las personas en el campo del Deep Learning. El gráfico ha ido aumentando mucho después de 2013, entonces, ¿qué ha llevado a este alza en tendencia que entenderemos en este artículo?
Según algunos expertos, hay muchas razones detrás de esta tendencia o el crecimiento exponencial del interés de las personas en el campo del Deep Learning. Veámoslos uno por uno.
1. Lo primero es que después de 2013 la mayoría de las personas conocen los teléfonos inteligentes y comienzan a usarlos. La gente comienza a usar varias plataformas de redes sociales como Facebook, Instagram o WhatsApp, que en realidad generan una gran cantidad de datos. Al usar esta gran cantidad de datos, definitivamente podemos hacer muchas cosas, resolver diferentes tipos de casos de uso. Ex. sistema de recomendación y muchas cosas.
Los datos son la principal razón específica por la que el aprendizaje profundo entra en escena. Según una encuesta cada día aprox. 2,5 trillones de bytes de datos generados. Veamos un hermoso gráfico compartido por Sir Andrew Ng.
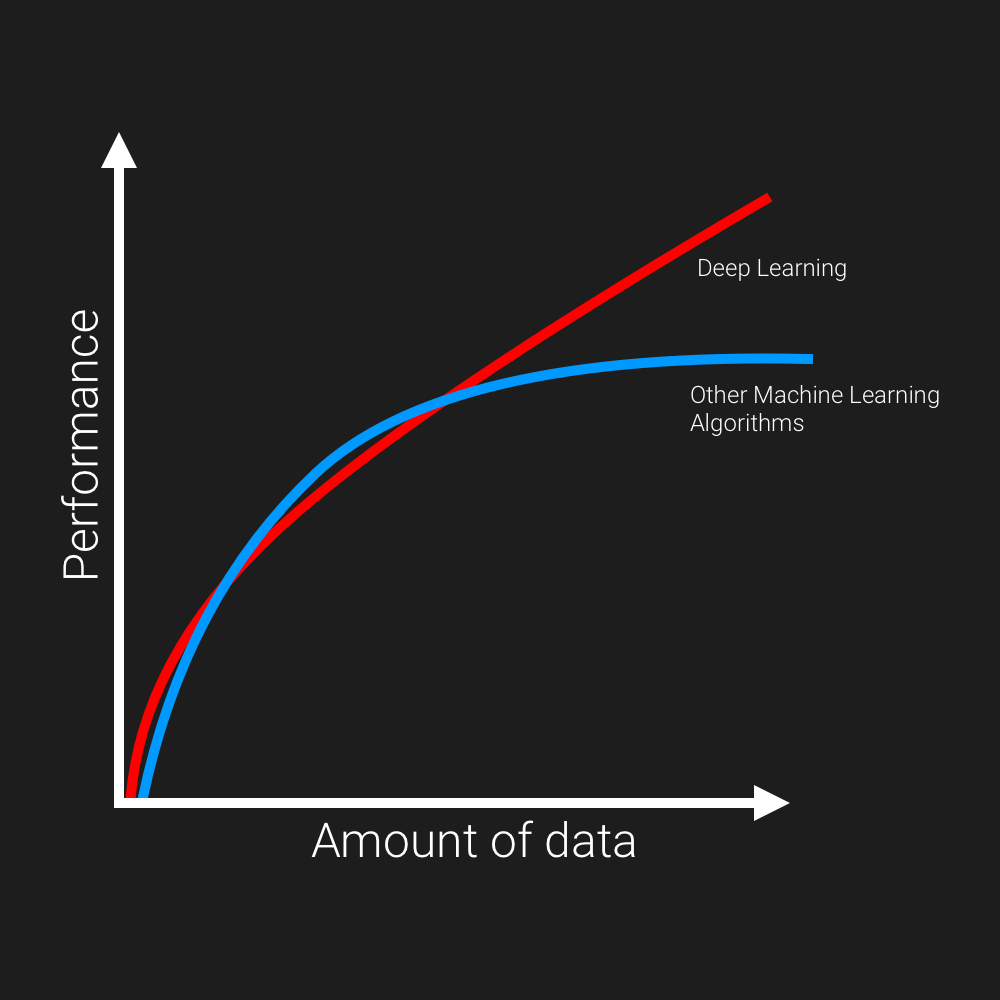
Aquí arriba, podemos ver este gráfico específico donde en el eje x tenemos la cantidad de datos y en el eje y tenemos el rendimiento del algoritmo. Como vemos, a medida que aumentamos la cantidad de datos con respecto a los algoritmos de aprendizaje más antiguos (cualquier tipo de algoritmo de aprendizaje automático), el rendimiento después de un punto específico de tiempo, comenzó a degradarse y permanece casi constante, no aumentó. Pero en el caso del Deep Learning, a medida que aumentamos la cantidad de datos, el rendimiento también aumenta. Significa que este crecimiento exponencial de datos nos llevó a crear algunos modelos asombrosos de aprendizaje profundo en términos de precisión y diversas métricas de rendimiento.
2. La tecnología es otra razón que nos anima a investigar sobre el aprendizaje profundo porque, junto con una gran cantidad de datos, el aprendizaje profundo también requería hardware de buena calidad. Aquí estoy hablando de GPU (Unidad de procesamiento de gráficos) y TPU (Unidad de procesamiento de tensorLos tensores son estructuras matemáticas que generalizan conceptos como scalars y vectores. Se utilizan en diversas disciplinas, incluyendo física, ingeniería y aprendizaje automático, para representar datos multidimensionales. Un tensor puede ser visualizado como una matriz de múltiples dimensiones, lo que permite modelar relaciones complejas entre diferentes variables. Su versatilidad y capacidad para manejar grandes volúmenes de información los convierten en herramientas fundamentales en el análisis y procesamiento de datos....). Debido a la mejora de la tecnología, ahora obtenemos fácilmente un buen hardware a un precio muy inferior. A medida que la tecnología aumenta día a día, el costo del hardware disminuye drásticamente día a día.
3. En realidad, el aprendizaje profundo combina la extracción de características y la parte de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... del modelo. Estas dos técnicas las realizamos por separado en el caso del Machine Learning pero aquí ambas técnicas se incluyen dentro de las técnicas de deep learning. Aquí la extracción de características y la construcción de modelos, que lo hacemos por separado en el caso de Machine Learning, se combinan por completo en proyectos de Deep Learning. Debido a esto, el Deep Learning realmente puede resolver problemas complejos como la clasificación de imágenes, la detección de objetos o la tarea de PNL. El aprendizaje profundo en realidad utiliza la red neuronal profunda, ya que la red neuronal se vuelve profunda y se extrae información y características cada vez más complejas dentro de una declaración de problema.
¡Vamos a terminar😅!
En los puntos anteriores, hemos discutido que la tecnología nos apoya continuamente, así que ¿por qué no tomar su mano y avanzar un paso? Pero esta tecnología tiene un conjunto de desventajas importantes a pesar de todos sus beneficios. Según mi, el modelo de Deep Learning es incapaz de proporcionar argumentos de por qué llegó a una determinada conclusión. Creo que puede causar algunos problemas y puede ser un desafío para el modelo de aprendizaje profundo. Está bien que se requiera mucho tiempo y un buen hardware para entrenar el modelo.
Creo que los modelos de aprendizaje profundo también deberían dar una conclusión específica sobre su salida, supongamos que cada vez que alguien nos pregunta que «¿es un gato?», La forma en que usamos para explicarle que por qué es un gato, creo que el Modelo de Aprendizaje Profundo también debería idear la misma estrategia que siempre que dé algún resultado también nos dará una conclusión adecuada. No creo que sea posible o no, solo estoy compartiendo mis puntos de vista😅.
Y mi opinión final es que, en realidad, deberíamos seguir adelante con las tendencias y tecnologías, que de hecho nos ayudan a mantenernos actualizados y crecer más. Lo que piensas, deja un comentario a continuación.
Notas finales!
Espero que hayas disfrutado de este artículo. ¿Cualquier pregunta? ¿Me he perdido algo? Por favor comuníquese conmigo en mi LinkedIn. Y finalmente, … no hace falta decir,
¡Gracias por leer!
¡Nos vemos!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





