Tablas dinámicas: la navaja suiza del análisis de datos
Me encanta lo rápido que puedo analizar datos usando tablas dinámicas. Con un clic de mi mouse, puedo profundizar en los detalles granulares sobre una determinada categoría de producto, o alejarme y obtener una descripción general de alto nivel de los datos disponibles.
Las tablas dinámicas me ofrecen mucha flexibilidad como científico de datos. Seré honesto: confío mucho en ellos durante la fase de análisis de datos exploratorios en un proyecto de ciencia de datos.
Los usuarios de Excel estarán íntimamente familiarizados con estas tablas dinámicas. Son la característica más utilizada de Excel, ¡y es fácil ver por qué! ¿Pero sabías que puedes construir estas tablas dinámicas usando Pandas en Python?

¡Eso es correcto! La maravillosa biblioteca Pandas ofrece una función llamada pivot_table que resume los valores de una característica en una ordenada tabla bidimensional. Veremos cómo construir una tabla dinámicaLa tabla dinámica es una herramienta poderosa en programas de hoja de cálculo, como Microsoft Excel y Google Sheets. Permite resumir, analizar y visualizar grandes volúmenes de datos de manera eficiente. A través de su interfaz intuitiva, los usuarios pueden reorganizar la información, aplicar filtros y crear informes personalizados, facilitando la toma de decisiones informadas en diversos contextos, desde el ámbito empresarial hasta la investigación académica.... de este tipo en Python aquí.
Créame, muy pronto utilizará estas tablas dinámicas en sus propios proyectos. Tenga en cuenta que este tutorial asume conocimientos básicos de Pandas y Python. Si es nuevo en estos temas, puede recogerlos en los cursos gratuitos a continuación:
Tabla de contenido
- Explorando el conjunto de datos Titanic con Pandas en Python
- Construye una tabla dinámica usando Pandas
- ¿Cómo agrupar datos usando el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... en la tabla dinámica?
- ¿Cómo ejecutar un pivote con un índice múltiple?
- Función de agregación diferente para diferentes características.
- Agregue características específicas con parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de valores
- Encuentre la relación entre las características con el parámetro de columnas
- Manejo de datos faltantes
Explorando el conjunto de datos Titanic usando Pandas en Python
Estoy seguro de que se ha encontrado con el conjunto de datos del Titanic en su viaje por la ciencia de datos. Es uno de los primeros conjuntos de datos que recopilamos cuando estamos listos para explorar un proyecto. Lo usaré para mostrarte la eficacia del tabla dinámica función.
Importamos las bibliotecas relevantes:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
Para todos aquellos que olvidaron cómo se ve el conjunto de datos del Titanic, ¡les presento el conjunto de datos!
df = pd.read_csv('drive/My Drive/AV/train.csv')
df.head()

Dejaré algunas funciones para facilitar el análisis de los datos y demostrar las capacidades del tabla dinámica función:
df.drop(['PassengerId','Ticket','Name'],inplace=True,axis=1)
¡Es hora de construir una tabla dinámica en Python usando la increíble biblioteca Pandas! Exploraremos las diferentes facetas de una tabla dinámica en este artículo y crearemos una tabla dinámica increíble y flexible desde cero.
¿Cómo agrupar datos usando índice en una tabla dinámica?
- tabla dinámica requiere un datos y un índice parámetro
- datos es el marco de datos de Pandas que pasa a la función
- índice es la función que le permite agrupar sus datos. La función de índice aparecerá como un índice en la tabla resultante.
Estaré usando el ‘Sexo’ columna como el índice por ahora:
#a single index table = pd.pivot_table(data=df,index=['Sex']) table

Podemos comparar instantáneamente todos los valores de características para ambos sexos. Ahora, visualicemos el hallazgo:

Bueno, las pasajeras pagaron notablemente más por los billetes que los varones.
Puede obtener más información sobre cómo visualizar sus datos aquí.
¿Cómo ejecutar un pivote con un índice múltiple?
Incluso puede utilizar más de una función como índice para agrupar sus datos. Esto aumenta el nivel de granularidad en la tabla resultante y puede ser más específico con sus hallazgos:
#multiple indexes table = pd.pivot_table(df,index=['Sex','Pclass']) table

El uso de múltiples índices en el conjunto de datos nos permite estar de acuerdo en que la disparidad en la tarifa del boleto para mujer y masculino pasajeros era válido en todos los Pclass en el Titanic.
Función de agregación diferente para diferentes características.
Los valores que se muestran en la tabla son el resultado del resumen que aggfunc se aplica a los datos de la función. aggfunc es una función agregadaLa función agregada es un concepto clave en economía que representa la relación entre la producción total de bienes y servicios en una economía y el nivel de precios. Esta función ayuda a entender cómo varían la oferta y la demanda agregadas en respuesta a cambios en factores como la política fiscal y monetaria. Su análisis es fundamental para la formulación de estrategias económicas y la predicción de ciclos económicos.... que tabla dinámica se aplica a sus datos agrupados.
Por defecto, es np.mean (), ¡pero también puede usar diferentes funciones agregadas para diferentes características! Simplemente proporcione un diccionario como entrada al aggfunc parámetro con el nombre de la función como clave y la función agregada correspondiente como valor.
Yo usaré np.mean () Para el ‘La edad’ característica y np.sum () Para el ‘Sobrevivió’ característica:
#different aggregate functions
table = pd.pivot_table(df,index=['Sex','Pclass'],aggfunc={'Age':np.mean,'Survived':np.sum})
table

La tabla resultante tiene más sentido al usar diferentes funciones de agregación para diferentes características.
Agregue características específicas con parámetros de valores
Pero, ¿en qué estás agregando? Puede decirle a Pandas las características en las que aplicar la función agregada, en el valor parámetro.
valor El parámetro es donde le dice a la función en qué características agregar. Es un campo opcional y si no especifica este valor, la función agregará todas las características numéricas del conjunto de datos:
table = pd.pivot_table(df,index=['Sex','Pclass'],values=['Survived'], aggfunc=np.mean) table
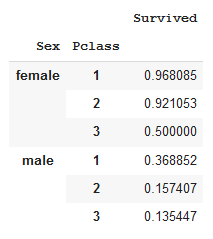
table.plot(kind='bar');
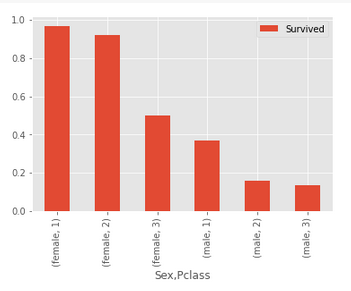
La tasa de supervivencia de los pasajeros a bordo del Titanic disminuyó con una clase P degradante entre ambos sexos. Además, la tasa de supervivencia de los pasajeros masculinos fue más baja que la de las mujeres en cualquier clase P determinada.
Encuentre la relación entre las características con el parámetro de columnas
El uso de múltiples funciones como índices está bien, pero el uso de algunas funciones como columnas le ayudará a comprender intuitivamente la relación entre ellas. Además, la tabla resultante siempre se puede ver mejor incorporando el columnas parámetro de la tabla dinámica.
Esta columnas El parámetro es opcional y muestra los valores horizontalmente en la parte superior de la tabla resultante.
Ambos columnas y el índice Los parámetros son opcionales, pero su uso eficaz le ayudará a comprender intuitivamente la relación entre las funciones.
#columns table = pd.pivot_table(df,index=['Sex'],columns=['Pclass'],values=['Survived'],aggfunc=np.sum) table

Utilizando Pclass como columna es más fácil de entender que usarla como índice:
table.plot(kind='bar');
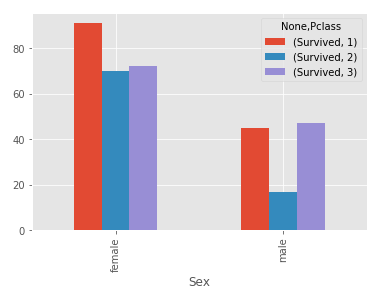
tabla dinámica incluso le permite lidiar con los valores perdidos a través de los parámetros dropna y fill_value:
- dropna le permite eliminar los valores nulos en la tabla agrupada cuyos valores son nulos
- fill_value El parámetro se puede utilizar para reemplazar los valores de NaN en la tabla agrupada con los valores que proporcione aquí.
#display null values table = pd.pivot_table(df,index=['Sex','Survived','Pclass'],columns=['Embarked'],values=['Age'],aggfunc=np.mean) table

Reemplazaré los valores de NaN con el valor medio del ‘La edad’ columna:
#handling null values table = pd.pivot_table(df,index=['Sex','Survived','Pclass'],columns=['Embarked'],values=['Age'],aggfunc=np.mean,fill_value=np.mean(df['Age'])) table

En este artículo, exploramos los diferentes parámetros de la increíble tabla dinámica función y cómo le permite resumir fácilmente las características en su conjunto de datos a través de una sola línea de código.
Si es nuevo en la programación de Python y desea obtener más información sobre el análisis de datos con Python, le recomiendo que explore nuestro Python para la ciencia de datos y Pandas para análisis de datos en Python cursos.





