Introducción
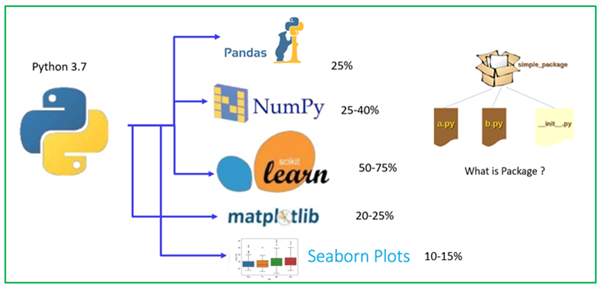
Especialmente las bibliotecas de Python para ciencia de datos, los modelos de aprendizaje automático son muy interesantes, fáciles de entender y absolutamente que puede aplicar de inmediato y puede sentir la información de los datos y darse cuenta / visualizar la naturaleza del conjunto de datos.
Incluso los algoritmos complejos se pueden implementar en dos o tres líneas de código, todos los conceptos matemáticos principales están incrustados dentro de los paquetes para el punto de vista de la implementación.
Por supuesto, esto es algo diferente e interesante que otras bibliotecas de programación que he visto hasta ahora, ¡esa es la razón principal por la que Python juega un papel vital en el espacio de la IA con esta simplicidad y robustez! ¡Yo creo que sí! Me di cuenta, entendí a fondo y lo disfruté.
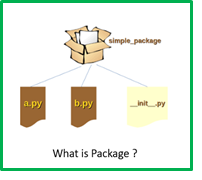
¿Qué es un paquete en Python? A paquete es una colección de Pitón módulos y ensamblados en un solo paquete. Una vez que importa en las celdas de su cuaderno, puede comenzar a usar clases, métodos, atributos, etc., pero antes de eso, debe necesitar y usar el paquete e importarlo a su archivo / paquete.
Analicemos los paquetes clave en Python para ciencia de datos y aprendizaje automático.
- Pandas
- NumPy
- Aprender Scikit
- Matplotlib
- Seaborn
Pandas

Se utiliza principalmente para operaciones y manipulaciones de datos estructurados. Pandas ofrece potentes capacidades de procesamiento de datos, nunca había visto características tan maravillosas en mi viaje de TI. Proporciona alto rendimiento, fácil de usar y se aplica en estructuras de datos y para analizar los datos.
¿Cómo podrías instalar la biblioteca de Pandas? esto es muy simple, ejecute el siguiente comando en su Jupiter Notebook.
!pip install pandas
¡La biblioteca de Pandas se instalará correctamente! ¿Qué sigue? juega con esta biblioteca.
La sintaxis para importar Scikit en su NoteBook
import pandas as pd
Entonces, su Cuaderno está listo para extraer todas las funciones dentro de los pandas. hagamos algunas cosas aquí.
Los pandas tienen las siguientes capacidades.
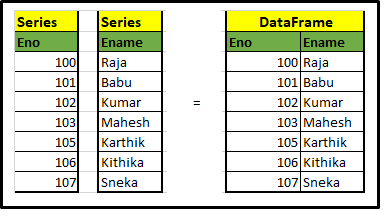
A) Series y DataFrame
Los componentes principales de los pandas son Serie y Marco de datos. Echemos un vistazo rápido a esto. Series no es más que un diccionario y una colección de series, podríamos construir el marco de datos fusionando series, eche un vistazo a la siguiente muestra. lo entenderías mejor.
Código crea series y marcos de datos
import pandas as pd
Eno=[100, 101,102, 103, 104,105]
Empname= ['Raja', 'Babu', 'Kumar','Karthik','Rajesh','xxxxx']
Eno_Series = pd.Series(Eno)
Empname_Series = pd.Series(Empname)
df = { 'Eno': Eno_Series, 'Empname': Empname_Series }
employee = pd.DataFrame(frame)
employee

B. Cargar datos en un objeto de marco de datos
cereal_df = pd.read_csv("cereal.csv")
cereal_df.head(5)
C. Soltar columna del objeto de marco de datos
cereal_df.drop(["type"], axis = 1, inplace = True)
cereal_df.head(5)

D. Seleccionar filas del objeto de marco de datos
cereal_df_filtered = cereal_df[cereal_df['rating'] >= 68] cereal_df_filtered.head()
E. Columna de grupo en el marco de datos
cereal_df_groupby = cereal_df.groupby('shelf')
#print the first entries cereal_df_groupby.first()

F.Extraer una fila del marco de datos
# return the value result = cereal_df.loc[0,'name'] result
Hasta ahora, hemos discutido múltiples funcionalidades en la biblioteca de pandas. hay muchos más.
NumPy
NumPy se considera una de las bibliotecas de aprendizaje automático más populares en Python, la mejor y más importante característica de NumPy es la interfaz y las manipulaciones de Array.
¿Tiene miedo de las matemáticas mientras implementa su modelo de ciencia de datos / aprendizaje automático? No se preocupe, NumPy hace que las complejas implementaciones matemáticas sean funciones muy simples. Pero recuerde comprender los requisitos y utilizar el paquete en consecuencia.
La sintaxis para importar NumPy en su NoteBook
import numpy as np
Analicemos algunas cosas aquí, cómo NumPy hace magia con datos dados.
A. Formación de matriz simple usando NumPy (1-D, 2-D y 3D)
import numpy as np
#1-D arrays
arr1 = np.array([1, 2, 3, 4, 5])
print("1-D Array")
print(arr1)
print("===================")
#2-D arrays
print("2-D Array")
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2)
print("===================")
#3-D arrays
print("3-D Array")
arr3 = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
print(arr3)
print("===================")
Producción
1-D Array [1 2 3 4 5] =================== 2-D Array [[1 2 3] [4 5 6]] =================== 3-D Array [[[1 2 3] [4 5 6]] [[1 2 3] [4 5 6]]] ===================
B. Array Slicing usando NumPy
#Slicing in python means taking elements from given index range [start:end-1] /[start:end:step].
arr = np.array([1, 2, 3, 4, 5, 6, 7])
print("Slicing at index 1 to 5")
print(arr[1:5])
Producción
Slicing at index 1 to 5 [2 3 4 5]
arr = np.array([1, 2, 3, 4, 5, 6, 7]) print(arr[4:]) Output [5 6 7]
También tenemos Rebanado Negativo :). Eso es tan simple, solo tenemos que mencionar [-x:-y],
¿Por qué no pruebas el tuyo propio?
C. Forma de matriz y remodelación usando NumPy
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
print("================================")
print("Shape of the array")
print(arr.shape)
print("================================")
Output
================================
Shape of the array
(2, 4)
================================
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
print("Before Reshape the array")
print(arr)
print("================================")
newarr = arr.reshape(4, 3)
print("After Reshape the array")
print(newarr)
print("================================")
output
Before Reshape the array
[ 1 2 3 4 5 6 7 8 9 10 11 12]
================================
After Reshape the array
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
================================
D. División de matrices usando NumPy
arr = np.array([1, 2, 3, 4, 5, 6])
print("Splitting NumPy Arrays into 3 Arrays")
print("================================")
newarr = np.array_split(arr, 3)
print(newarr[0])
print(newarr[1])
print(newarr[2])
print("================================")
output
Splitting NumPy Arrays into 3 Arrays
================================
[1 2]
[3 4]
[5 6]
E.Sorting Array usando NumPy
arr = np.array(['banana', 'cherry', 'apple'])
print("Splitting NumPy Arrays into 3 Arrays")
print("================================")
print(np.sort(arr))
print("================================")
output
Splitting NumPy Arrays into 3 Arrays
================================
['apple' 'banana' 'cherry']
================================
Si ha comenzado a jugar con datos usando NumPy….
Ciertamente, necesita cada vez más tiempo … para comprender los conceptos, todos son
extremadamente organizado en este paquete. ¡créeme!
Aprender Scikit

Scikit La biblioteca Learn es una de las bibliotecas más ricas de la familia Python, contiene una gran cantidad de algoritmos de aprendizaje automático y otras bibliotecas clave relacionadas con el rendimiento. Python Scikit-learn permite a los usuarios realizar varias tareas específicas de aprendizaje automático. Para funcionar, debe funcionar junto con las bibliotecas SciPy y NumPy, esto es algo interno, de todos modos, téngalo en cuenta. Pocos algoritmos aquí para sus opiniones.
- Regresión
- Clasificación
- Agrupación
- Selección de modelo
- Reducción de dimensionalidad
La sintaxis para importar Scikit en su NoteBook
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split
Paquetes de visualización de Python
Bibliotecas Matplotlib y Seaborn

Python proporciona funciones de gráficos 2D con la biblioteca Matplotlib. esto es muy simple y fácil de entender. puede lograrlo con 1 o 2 líneas. Incluso la visualización 3D también está ahí.
La sintaxis para importar Scikit en su cuaderno de notas
import matplotlib.pyplot as plt import seaborn as sns
Espero que haya trabajado en varios gráficos en la hoja de cálculo de Excel y otras herramientas de BI. Pero en Python, los paquetes de visualización internos proporcionan gráficos y tablas de muy alta calidad.
Matplotlib y Seaborn
Matplotlib es uno de los paquetes de visualización principales y básicos, que proporciona histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... (Nivel de frecuencia), Gráfica de barras (Graficado univariado y bivariado), Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas.... (Agrupación), etc.,
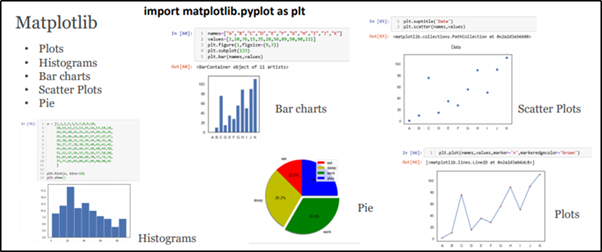
Biblioteca de visualización de datos rica y de lujo de Seaborn. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos. Diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... (Distribución de datos con diferentes cuartiles), Violin Plots (Distribución de datos y Densidad de probabilidad), Gráficos de barras (Comparaciones entre características categóricas), Mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas.... (Correlación de características en términos de representación matricial), Nube de palabras (Representación visual de datos de texto)
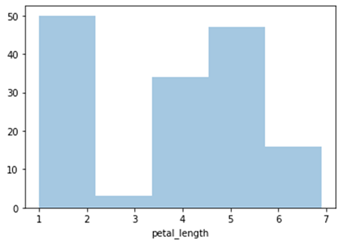
Seaborn – Histograma
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = False)
plt.show()
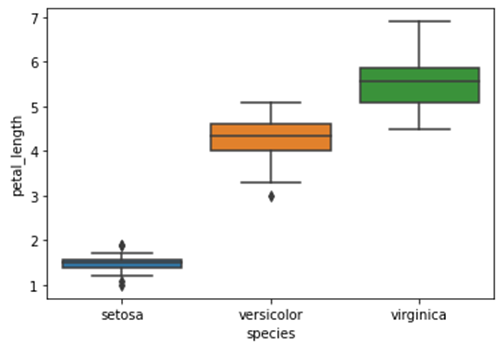
Seaborn – Diagrama de caja
df = sb.load_dataset('iris')
sb.boxplot(x = "species", y = "petal_length", data = df)
plt.show()
Seaborn – Violinplot
sdf = sb.load_dataset('tips')
sb.violinplot(x = "day", y = "total_bill", data=df)
plt.show()
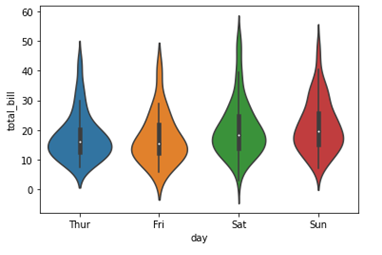
Entonces, ¡todas estas bibliotecas nos están ayudando a construir un buen modelo y a jugar con los datos!
Pero recuerde siempre, antes del uso de los paquetes induviales, debe comprender la necesidad y los requisitos del paquete y luego importarlo a su archivo / paquete y jugar con eso.

Espero que ahora tenga la sensación y cierto nivel de detalles sobre los paquetes de Python para la ciencia de datos. ¡Veremos conceptos más detallados en los próximos días! ¡Gracias por tu tiempo!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





