Introducción
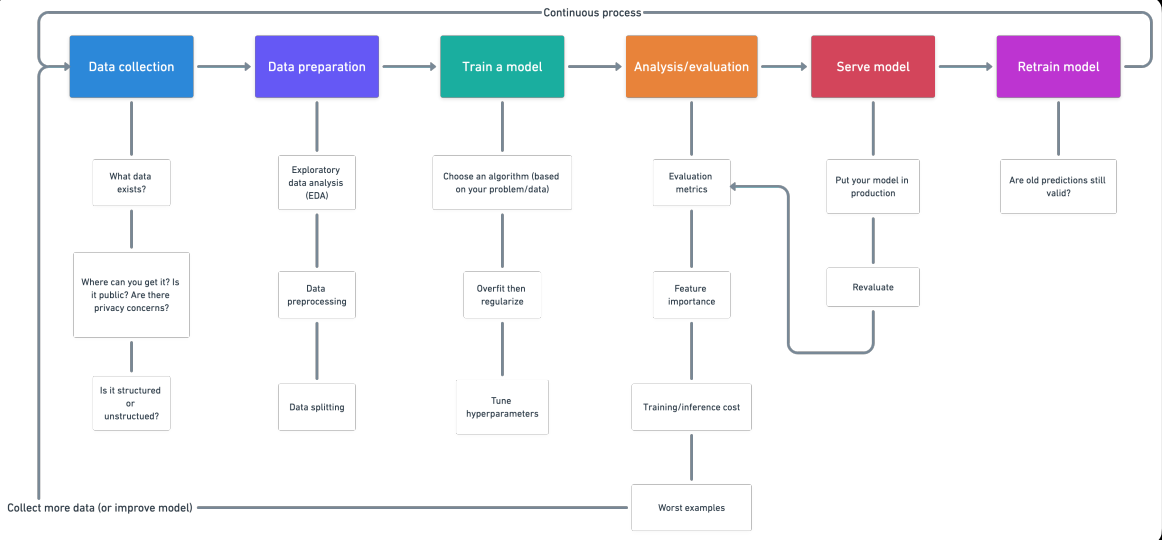
1. Recopilación de datos
- ¿Qué tipo de problema estamos tratando de resolver?
- ¿Qué fuentes de datos ya existen?
- ¿Qué problemas de privacidad existen?
- ¿Son públicos los datos?
- ¿Dónde debemos almacenar los archivos?
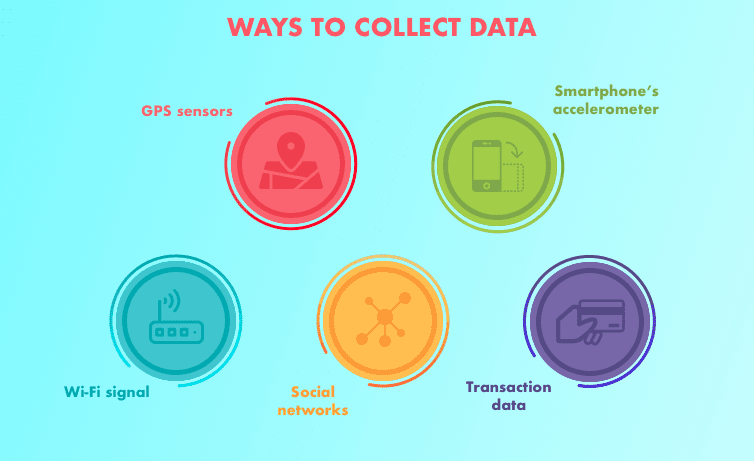
- Datos estructurados: aparecen en formato tabulado (estilo de filas y columnas, como lo que encontraría en una hoja de cálculo de Excel). Contiene diferentes tipos de datos, por ejemplo, series de tiempo numéricas, categóricas.
- · Nominal / categórico – Una cosa u otra (mutuamente excluyentes). Por ejemplo, para las básculas de automóviles, el color es una categoría. Un automóvil puede ser azul pero no blanco. No importa un pedido.
- Numérico: Cualquier valor continuo donde la diferencia entre ellos importa. Por ejemplo, al vender casas, $ 107,850 es más de $ 56,400.
- Ordinal: Datos que tienen orden pero se desconoce la distancia entre valores. Por ejemplo, una pregunta como, ¿cómo calificaría su salud del 1 al 5? 1 siendo pobre, 5 saludable. Puede responder 1, 2, 3, 4, 5, pero la distancia entre cada valor no significa necesariamente que una respuesta de 5 sea cinco veces más buena que una respuesta de 1. Serie temporalUna serie temporal es un conjunto de datos recogidos o medidos en momentos sucesivos, generalmente en intervalos de tiempo regulares. Este tipo de análisis permite identificar patrones, tendencias y ciclos en los datos a lo largo del tiempo. Su aplicación es amplia, abarcando áreas como la economía, la meteorología y la salud pública, facilitando la predicción y la toma de decisiones basadas en información histórica....: datos a lo largo del tiempo. Por ejemplo, los valores históricos de venta de las topadoras de 2012 a 2018.
- Series de tiempo: Datos a lo largo del tiempo. Por ejemplo, los valores históricos de venta de las topadoras de 2012 a 2018.
- Datos no estructurados: Datos sin estructura rígida (imágenes, video, voz, natural
texto de idioma)
2. Preparación de datos
- Análisis exploratorio de datos (EDA), aprender sobre los datos con los que está trabajando
- ¿Cuáles son las variables de características (entrada) y la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de destino (salida)? Por ejemplo, para predecir una enfermedad cardíaca, las variables características pueden ser la edad, el peso, la frecuencia cardíaca promedio y el nivel de actividad física de una persona. Y la variable objetivo será si tienen o no una enfermedad.
- ¿Qué tipo de tienes? Series temporales estructuradas, no estructuradas, numéricas. ¿Faltan valores? En caso de que los elimine o los complete, la función de imputación.
- ¿Dónde están los valores atípicos? Cuantos de ellos hay? ¿Por qué están ellos ahí? ¿Hay alguna pregunta que pueda hacerle a un experto en el dominio sobre los datos? Por ejemplo, ¿podría un médico especialista en enfermedades cardíacas arrojar algo de luz sobre su conjunto de datos de enfermedades cardíacas?
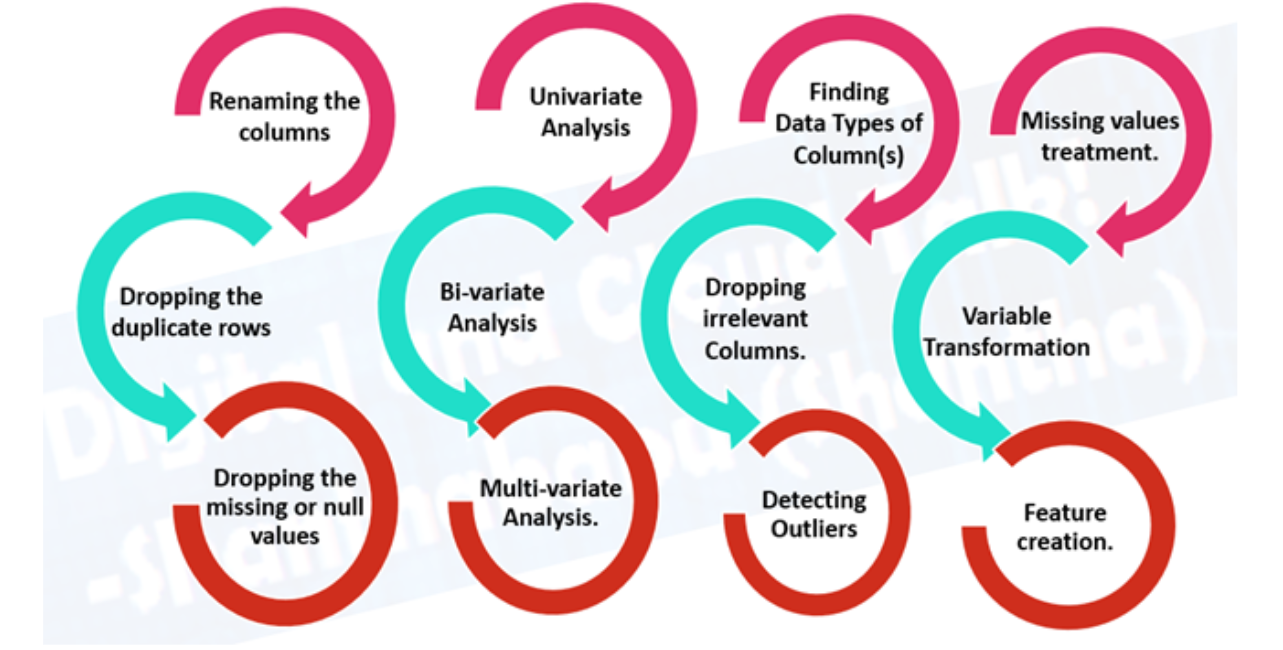
- Preprocesamiento de datos, preparación de sus datos para modelarlos.
- Función de imputación: completar los valores faltantes (un modelo de aprendizaje automático no puede aprender
en datos que no están ahí)
- Imputación única: Llenar con media, una mediana de la columna.
- Múltiples imputaciones: Modele otros valores perdidos y con lo que encuentre su modelo.
- KNN (k vecinos más cercanos): Complete los datos con un valor de otro ejemplo que sea similar.
- Muchos más, como la imputación aleatoria, la última observación llevada adelante (para series de tiempo), la ventana móvil y las más frecuentes.
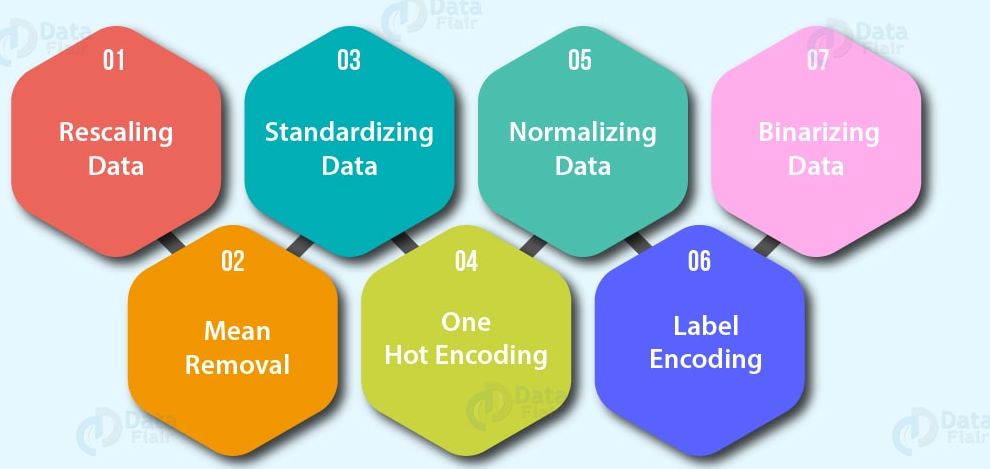
- Codificación de funciones (convertir valores en números). Un modelo de aprendizaje automático
requiere que todos los valores sean numéricos)
- Una codificación en caliente: Convierta todos los valores únicos en listas de ceros y unos donde el valor objetivo es 1 y el resto son ceros. Por ejemplo, cuando un automóvil colorea verde, rojo, azul, verde, el futuro del color del automóvil se representaría como [1, 0, and 0] y una roja seria [0, 1, and 0].
- Codificador de etiquetas: Convierta las etiquetas en valores numéricos distintos. Por ejemplo, si sus variables objetivo son animales diferentes, como perro, gato, pájaro, estos podrían convertirse en 0, 1 y 2, respectivamente.
- Codificación de incrustación: Aprenda una representación entre todos los diferentes puntos de datos. Por ejemplo, un modelo de lenguaje es una representación de cómo diferentes palabras se relacionan entre sí. La incrustación también está cada vez más disponible para datos estructurados (tabulares).
- NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... de funciones (escalado) o estandarización: Cuando las variables numéricas están en diferentes escalas (por ejemplo, el número_de_bathroom está entre 1 y 5 y el tamaño_of_land entre 500 y 20000 pies cuadrados), algunos algoritmos de aprendizaje automático no funcionan muy bien. El escalado y la estandarización ayudan a solucionar este problema.
- Ingeniería de funciones: transformar los datos en una representación (potencialmente) más significativa al agregar conocimiento del dominio
- Descomponer
- Discretización: convertir grupos grandes en grupos más pequeños
- Funciones de cruce e interacción: combinación de dos o más funciones
- Las características del indicador: usar otras partes de los datos para indicar algo potencialmente significativo
- Selección de características: seleccionando
las características más valiosas de su conjunto de datos para modelar. Potencialmente reduciendo el tiempo de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y sobreajuste (menos datos generales y menos datos redundantes para entrenar) y mejorando la precisión.
- Reducción de dimensionalidad: Un método común de reducción de dimensionalidad, PCA o análisis de componentes principales toma una gran cantidad de dimensiones (características) y usa álgebra lineal para reducirlas a menos dimensiones. Por ejemplo, supongamos que tiene 10 funciones numéricas, podría ejecutar PCA para reducirlo a 3.
- Importancia de la función (modelado posterior): Ajuste un modelo a un conjunto de datos, luego inspeccione qué características fueron más importantes para los resultados, elimine las menos importantes.
- Métodos de envoltura como los algoritmos genéticos y la eliminación de características recursivas implican crear grandes subconjuntos de opciones de características y luego eliminar las que no importan.
- Hacer frente a los desequilibrios: ¿Sus datos tienen 10,000 ejemplos de una clase pero solo 100 ejemplos de otra?
- Recopile más datos (si puede)
- Utilice el paquete scikit-learn-contrib imbalanced- learn
- Utilice SMOTE: técnica sintética de sobremuestreo de minorías. Crea muestras sintéticas de tu clase menor para intentar nivelar el campo de juego.
- Un artículo útil para mirar es «Aprendiendo de los datos desequilibrados».
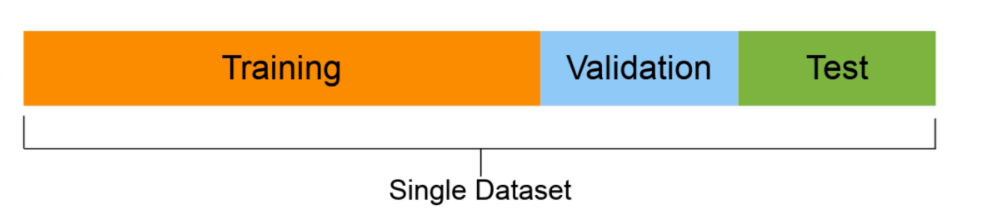
- Conjunto de entrenamiento (generalmente 70-80% de los datos): el modelo aprende sobre esto.
- Conjunto de validación (normalmente del 10 al 15% de los datos): los hiperparámetros del modelo se ajustan a este
- Conjunto de prueba (normalmente entre el 10% y el 15% de los datos): el rendimiento final de los modelos se evalúa sobre esta base. Si lo ha hecho bien, es de esperar que los resultados del conjunto de prueba den una buena indicación de cómo debería funcionar el modelo en el mundo real. No utilice este conjunto de datos para ajustar el modelo.
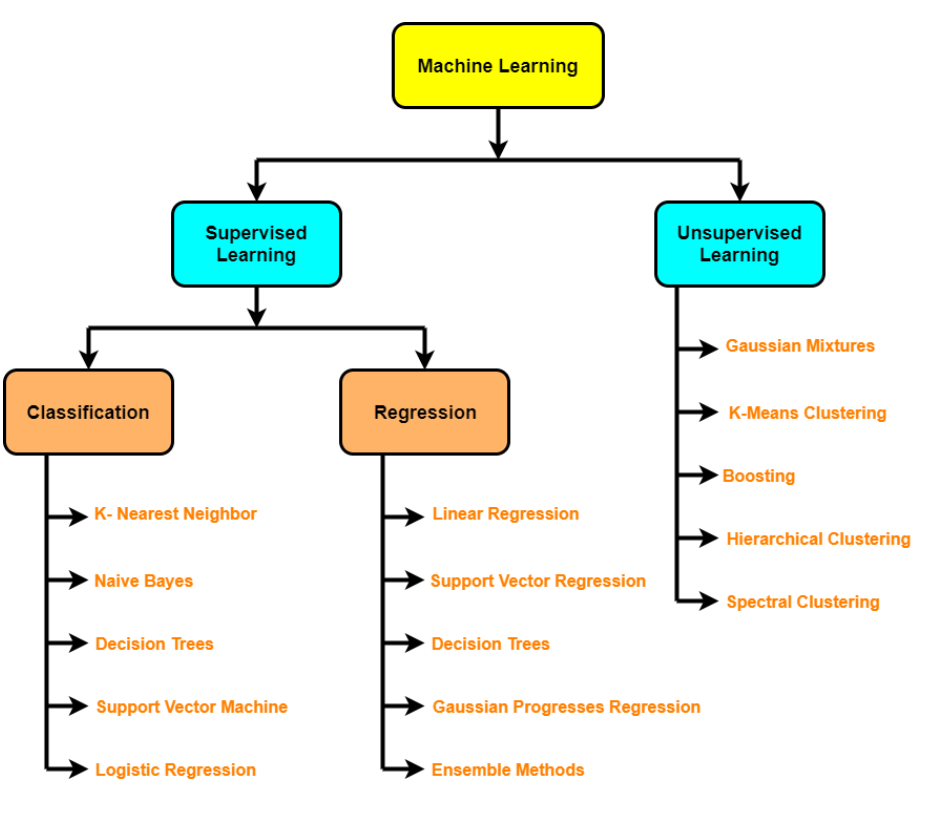
3. Entrene el modelo sobre los datos (3 pasos: elija un algoritmo, ajuste el modelo, reduzca el ajuste con regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones....)
- Algoritmos supervisados: regresión lineal, regresión logística, KNN, SVM, árbol de decisiones y bosques aleatorios, AdaBoost / Gradient Boosting Machine (impulso)
- Algoritmos no supervisados: agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo..., reducción de dimensionalidad (PCA, codificadores automáticos, t-SNE), detección de anomalías
- Aprendizaje por lotes
- Aprender en línea
- Transferir aprendizaje
- Aprendizaje activo
- Ensamblaje
- Desajuste – ocurre cuando su modelo no funciona tan bien como le gustaría en sus datos. Intente entrenar para un modelo más largo o más avanzado.
- Sobreajuste– ocurre cuando la pérdida de validación comienza a aumentar o cuando el modelo funciona mejor en el conjunto de entrenamiento que en el de prueba.
- Regularización: una colección de tecnologías para prevenir / reducir el sobreajuste (por ejemplo, L1, L2, Abandono, Parada anticipada, Aumento de datos, Normalización de lotes)
- Ajuste de hiperparámetros – Ejecute un montón de experimentos con diferentes configuraciones y vea cuál funciona mejor
4. Análisis / Evaluación
- Clasificación: precisión, precisión, recuperación, F1, matriz de confusión, precisión media media (detección de objetos)
- Regresión – MSE, MAE, R ^ 2
- Métrica basada en tareas: por ejemplo, para el automóvil autónomo, es posible que desee saber el número de desconexiones
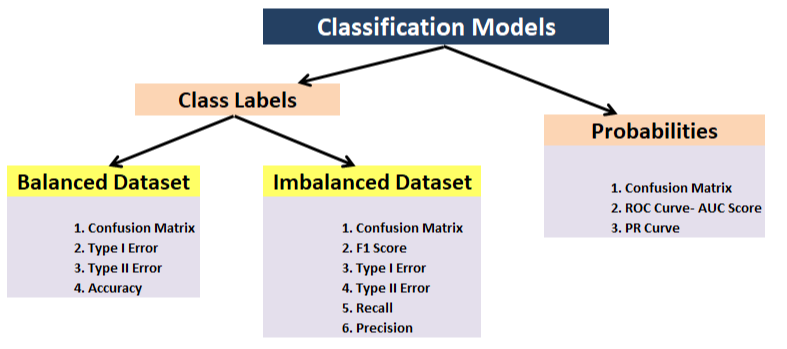
- Importancia de la característica
- Capacitación / tiempo de inferencia / costo
- ¿Qué pasa si la herramienta: cómo se compara mi modelo con otros modelos?
- Ejemplos menos seguros: ¿en qué se equivoca el modelo?
- Compensación de sesgo / varianza
5. Modelo de servicio (implementación de un modelo)
- Pon el modelo en producción y mira como te va.
- Instrumentos que puede utilizar: TensorFlow Servinf, PyTorch Serving, Google AI Platform, Sagemaker
- MLOps: donde la ingeniería de software se encuentra con el aprendizaje automático, esencialmente toda la tecnología requerida en torno a un modelo de aprendizaje automático para que funcione en producción

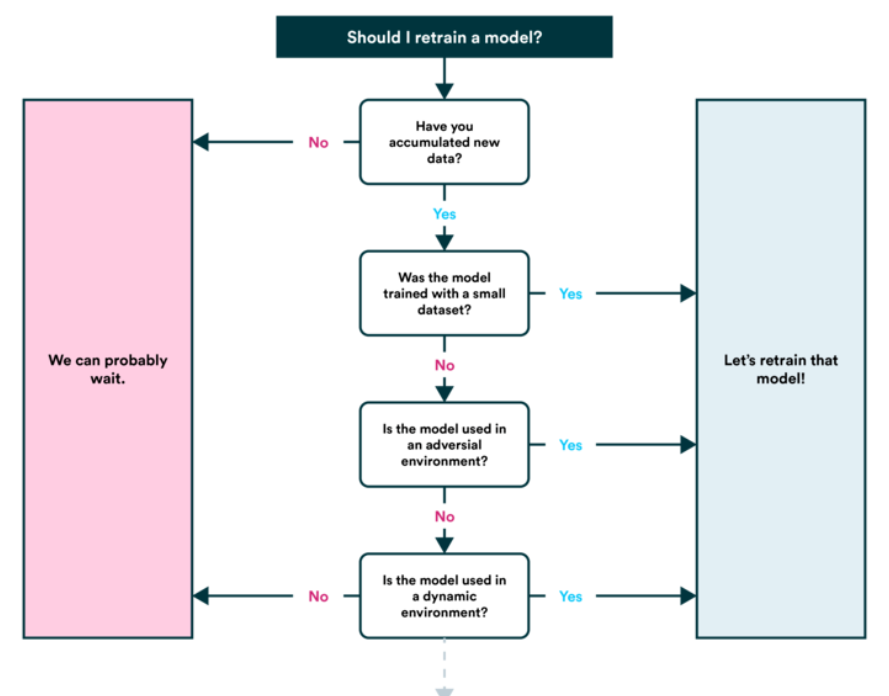
6. Volver a entrenar modelo
- Vea cómo funciona el modelo después de la publicación (o antes de la publicación) en función de varias métricas de evaluación y vuelva a consultar los pasos anteriores según sea necesario (recuerde, el aprendizaje automático es muy experimental, por lo que aquí es donde querrá realizar un seguimiento de sus datos y experimentos.
- También encontrará que las predicciones de su modelo comienzan a ‘envejecer’ (generalmente no en un estilo elegante) o ‘derivar’, como cuando las fuentes de datos cambian o se actualizan (nuevo hardware, etc.). Aquí es cuando querrás volver a entrenarlo.
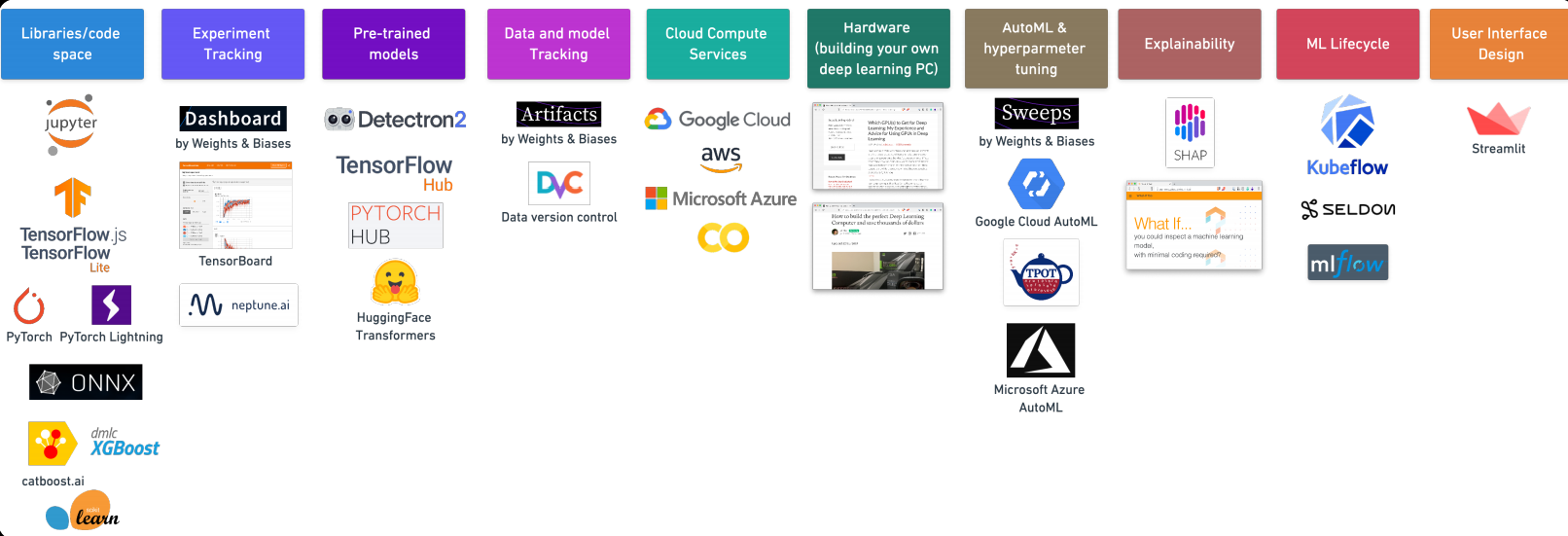
7. Herramientas de aprendizaje automático
Gracias por leer esto. Si te gusta este artículo, compártelo con tus amigos. En caso de cualquier sugerencia / duda, comente a continuación.
Identificación de correo: [email protected]
Sígueme en LinkedIn: LinkedIn
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





