Introducción
La mayoría de ustedes habría escuchado cosas emocionantes que suceden usando el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... Además habría escuchado que Deep Learning necesita mucho hardware. He visto a personas entrenar un modelo simple de aprendizaje profundo durante días en sus computadoras portátiles (de forma general sin GPU), lo que da la impresión de que el aprendizaje profundo necesita grandes sistemas para ejecutarse.
A pesar de esto, esto es solo parcialmente cierto y crea un mito en torno al aprendizaje profundo que crea un estorbo para los principiantes. Numerosas personas me han preguntado qué tipo de hardware sería mejor para realizar un aprendizaje profundo. Con este post espero darles respuesta.
Nota: Supongo que tiene un conocimiento fundamental de los conceptos de aprendizaje profundo. Si no es así, debería leer este post.
Tabla de contenido
- Hecho # 101: DL necesita
muchohardware - Entrenando un modelo de aprendizaje profundo
- ¿Cómo entrenar tu modelo más rápido?
- CPU vs GPU
- Breve historia de las GPU: ¿cómo llegamos aquí?
- ¿Qué GPU utilizar hoy?
- El futuro parece emocionante
Hecho # 101: El aprendizaje profundo necesita mucho hardware
Cuando me presentaron por primera vez con el aprendizaje profundo, pensé que el aprendizaje profundo necesariamente necesita un gran centro de datos para ejecutarse, y los «expertos en aprendizaje profundo» se sentaban en sus salas de control para operar estos sistemas.

Esto se debe a que en cada libro que mencioné o en cada charla que escuché, el autor o el orador siempre comentan que el aprendizaje profundo necesita una gran cantidad de poder computacional para ejecutarse. Pero cuando construí mi primer modelo de aprendizaje profundo en mi pequeña máquina, ¡me sentí aliviado! No tengo que hacerse cargo el control de Google para ser un experto en aprendizaje profundo 😀
Este es un error común que todos los principiantes enfrentan cuando se sumergen en el aprendizaje profundo. Aunque es cierto que el aprendizaje profundo necesita un hardware considerable para ejecutarse de manera eficiente, no necesita que sea infinito para realizar su tarea. ¡Inclusive puede ejecutar modelos de aprendizaje profundo en su computadora portátil!
Solo un pequeño descargo de responsabilidad; cuanto más pequeño sea su sistema, más tiempo necesitará para obtener un modelo entrenado que funcione lo suficientemente bien. Simplemente, puede verse así:

Hagámonos una pregunta sencilla; ¿Por qué necesitamos más hardware para el aprendizaje profundo?
La solución es simple, el aprendizaje profundo es un algoritmo – una construcción de software. Definimos una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... artificial en nuestro lenguaje de programación favorito que posteriormente se convertiría en un conjunto de comandos que se ejecutan en la computadora.
Si tuviera que adivinar qué componentes de la red neuronal cree que requerirían recursos de hardware intensos, ¿cuál sería su respuesta?
Algunos de los candidatos que tengo en mente son:
- Procesamiento previo de datos de entrada
- Entrenando el modelo de aprendizaje profundo
- Almacenamiento del modelo de aprendizaje profundo entrenado
- Despliegue del modelo
Entre todos estos, entrenar el modelo de aprendizaje profundo es la tarea más intensiva. Veamos en detalle por qué es así.
Entrenando un modelo de aprendizaje profundo
Cuando entrena un modelo de aprendizaje profundo, se realizan dos operaciones principales:
- Pase adelantado
- Pase hacia atrás
En el paso hacia adelante, la entrada se pasa por medio de la red neuronal y, después de procesar la entrada, se genera una salida. Mientras que en el pase hacia atrás, actualizamos los pesos de la red neuronal sobre la base del error que obtenemos en el pase hacia adelante.
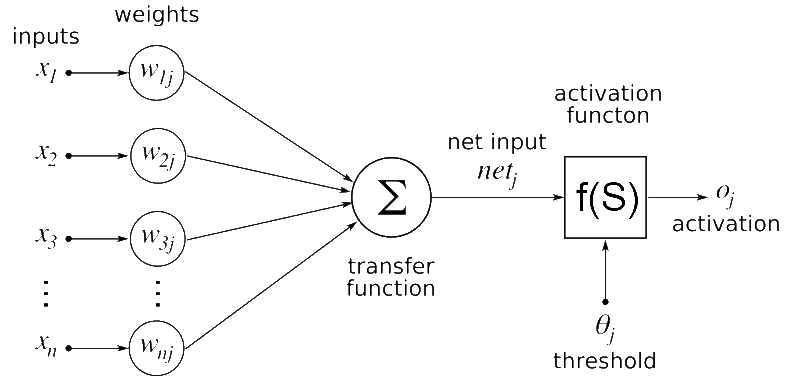
Ambas operaciones son esencialmente multiplicaciones de matrices. Una simple multiplicación de matrices se puede representar con la próxima imagen
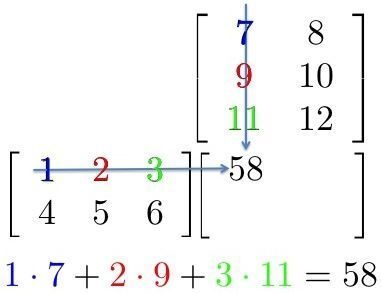
Aquí, podemos ver que cada elemento en una fila de la primera matriz se multiplica por una columna de la segunda matriz. Entonces, en una red neuronal, podemos considerar la primera matriz como entrada a la red neuronal, y la segunda matriz se puede considerar como pesos de la red.
Esta parece ser una tarea sencilla. Ahora, solo para darle una idea de qué tipo de aprendizaje profundo de escala: VGG16 (una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... de 16 capas ocultas que se utiliza a menudo en aplicaciones de aprendizaje profundo) tiene ~ 140 millones de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto....; además conocido como pesos y sesgos. ¡Ahora piense en todas las multiplicaciones de matrices que tendría que hacer para pasar solo una entrada a esta red! Se necesitarían años para entrenar este tipo de sistemas si adoptamos enfoques tradicionales.
¿Cómo entrenar tu red neuronal más rápido?
Vimos que la parte computacionalmente intensiva de la red neuronal se compone de múltiples multiplicaciones de matrices. Entonces, ¿cómo podemos hacerlo más rápido?
Simplemente podemos hacer esto haciendo todas las operaciones al mismo tiempo en lugar de hacerlo una tras otra. Resumidamente, esta es el motivo por la que usamos GPU (unidades de procesamiento de gráficos) en lugar de una CPU (unidad de procesamiento central) para entrenar una red neuronal.
Para darle un poco de intuición, volvemos a la historia cuando probamos que las GPU eran mejores que las CPU para la tarea.
Antes del boom del aprendizaje profundo, Google tenía un sistema extremadamente poderoso para hacer su procesamiento, que habían construido especialmente para entrenar redes enormes. Este sistema era monstruoso y tenía un costo total de $ 5 mil millones, con múltiples grupos de CPU.
Ahora, los investigadores de Stanford construyeron el mismo sistema en términos de computación para entrenar sus redes profundasLas redes profundas, también conocidas como redes neuronales profundas, son estructuras computacionales inspiradas en el funcionamiento del cerebro humano. Estas redes están compuestas por múltiples capas de nodos interconectados que permiten aprender representaciones complejas de datos. Son fundamentales en el ámbito de la inteligencia artificial, especialmente en tareas como el reconocimiento de imágenes, procesamiento de lenguaje natural y conducción autónoma, mejorando así la capacidad de las máquinas para comprender y... usando GPU. Y adivina qué; ¡redujeron los costos a solo $ 33K! Este sistema se construyó con GPU y proporcionaba la misma potencia de procesamiento que el sistema de Google. Bastante impresionante, ¿verdad?
| Stanford | ||
| Numero de nucleos | CPU de 1K = núcleos de 16K | 3GPU = 18K núcleos |
| Costo | $ 5 mil millones | $ 33 mil |
| Tiempo de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... | semana | semana |
Podemos ver que gobiernan las GPU. Pero, ¿cuál es exactamente la diferencia entre una CPU y una GPU?
Diferencia entre CPU y GPU
Para comprender la diferencia, tomamos una analogía clásica que explica la diferencia de manera intuitiva.
Suponga que tiene que transferir mercancías de un lugar a otro. Tiene la opción de seleccionar entre un Ferrari y un camión de carga.
Ferrari sería extremadamente rápido y lo ayudaría a transferir un lote de mercancías en poco tiempo. Pero la cantidad de bienes que puede transportar es pequeña y el uso de combustible sería muy alto.
Un camión de carga sería lento y llevaría mucho tiempo transferir mercancías. Pero la cantidad de mercancías que puede transportar es mayor en comparación con Ferrari. Al mismo tiempo, es más eficiente en el consumo de combustible, por lo que el uso es menor.
Entonces, ¿cuál elegirías para tu trabajo?
Evidentemente, primero verá cuál es la tarea; Si tiene que recoger a su novia con urgencia, definitivamente elegiría un Ferrari en lugar de un camión de carga. Pero si va a mudar su casa, usaría un camión de carga para transferir los muebles.
Así es como diferenciarías técnicamente los dos:

Aquí hay otro video que aclararía aún más su concepto.
Nota: La GPU se utiliza principalmente para juegos y simulaciones complejas. Estas tareas y principalmente cálculos gráficos, por lo que GPU es una unidad de procesamiento de gráficos. Si la GPU se utiliza para procesamiento no gráfico, se denominan GPGPU: unidad de procesamiento de gráficos de propósito general
Breve historia de las GPU: ¿cómo llegamos aquí?
Ahora, es factible que se esté preguntando por qué las GPU están tan de moda en este momento. Viajemos por medio de una breve historia del desarrollo de las GPU.
Simplemente, una GPGPU es una configuración de programación paralela que involucra GPU y CPU que pueden procesar y analizar datos de manera equivalente a una imagen u otra manera gráfica. Las GPGPU se crearon para un procesamiento gráfico mejor y más general, pero posteriormente se descubrió que se adaptaban bien a la informática científica. Esto se debe a que la mayor parte del procesamiento gráfico implica la aplicación de operaciones en matrices grandes.
El uso de GPGPU para la computación científica comenzó en 2001 con la implementación de la multiplicación de matrices. Uno de los primeros algoritmos comunes que se implementó en GPU de manera más rápida fue la factorización LU en 2005. Pero, en este momento, los investigadores tenían que codificar todos los algoritmos en una GPU y tenían que comprender el procesamiento gráfico de bajo nivel.
En 2006, Nvidia presentó un lenguaje CUDA de alto nivel, que le ayuda a escribir programas desde procesadores gráficos en un lenguaje de alto nivel. Este fue probablemente uno de los cambios más significativos en la forma en que los investigadores interactúan con las GPU.
¿Qué GPU utilizar hoy?
Aquí le daré rápidamente algunos conocimientos técnicos antes de comprar una GPU para el aprendizaje profundo.
Escenario 1:
Lo primero que debe determinar es qué tipo de recurso requieren sus tareas. Si sus tareas van a ser pequeñas o pueden caber en un procesamiento secuencial complejo, no necesita un gran sistema para trabajar. Inclusive podría omitir el uso de GPU por completo. Por eso, si planea trabajar principalmente en “otras” áreas / algoritmos de ML, no necesita necesariamente una GPU.
Escenario 2:
Si su tarea es un poco intensiva y tiene datos manejables, una GPU razonable sería una mejor opción para usted. De forma general uso mi computadora portátil para trabajar en problemas de juguetes, que dispone de una GPU un poco desactualizada (una Nvidia GT 740M de 2GB). Tener una computadora portátil con GPU me ayuda a ejecutar las cosas donde sea que vaya. Hay algunas computadoras portátiles de gama alta (y se espera que sean pesadas) con Nvidia GTX 1080 (una VRAM de 8 GB) que puede consultar en el extremo.
Escenario 3:
Si trabaja regularmente en problemas complejos o es una compañía que aprovecha el aprendizaje profundo, probablemente sería mejor que creara un sistema de aprendizaje profundo o utilizara un servicio en la nubeEl "servicio en la nube" se refiere a la entrega de recursos informáticos a través de Internet, permitiendo a los usuarios acceder a almacenamiento, procesamiento y aplicaciones sin necesidad de infraestructura física local. Este modelo ofrece flexibilidad, escalabilidad y ahorro de costos, ya que las empresas solo pagan por lo que utilizan. Además, facilita la colaboración y el acceso a datos desde cualquier lugar, mejorando la eficiencia operativa en diversas... como AWS o FloydHub. En DataPeaker creamos un sistema de aprendizaje profundo para nosotros, para el cual compartimos nuestras especificaciones. Aquí está el post.
Escenario 4:
Si eres Google, probablemente necesites otro centro de datos para mantener. Bromas aparte, si su tarea es de una escala mayor de lo frecuente y tiene suficiente dinero de bolsillo para cubrir los costos; puede elegir por un clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... de GPU y hacer computación con múltiples GPU. Además hay algunas opciones que pueden estar disponibles en un futuro cercano, como TPU y FPGA más rápidos, que le facilitarían la vida.
El futuro parece emocionante
Como se mencionó previamente, hay mucha investigación y trabajo activo para pensar en alternativas para acelerar la computación. Se espera que Google presente las Unidades de procesamiento de Tensorflow (TPU) a finales de este año, lo que promete una aceleración por encima de las GPU actuales.
De manera equivalente, Intel está trabajando para crear FPGA más rápidas, que pueden otorgar una mayor flexibilidad en los próximos días. Al mismo tiempo, las ofertas de los proveedores de servicios en la nube (a modo de ejemplo, AWS) además están aumentando. Veremos a cada uno de ellos emerger en los próximos meses.
Notas finales
En este post, cubrimos las motivaciones de utilizar una GPU para aplicaciones de aprendizaje profundo y vimos cómo elegirlas para su tarea. Espero que este post te haya sido útil. Si tiene alguna duda específica sobre el tema, no dude en comentar a continuación o preguntar en portal de discusión.





