Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
cómo rehabilitar a las personas mediante el uso de datos e información pertinentes.
En este proyecto, vamos a predecir los sentimientos de los tweets de COVID-19. Los datos recopilados del Tweeter y voy a usar el entorno Python para implementar este proyecto.
Planteamiento del problema
El desafío dado es construir un modelo de clasificación para predecir el sentimiento de los tweets Covid-19. Los tweets se han extraído de Twitter y se ha realizado el etiquetado manual. Recibimos información como Ubicación, Tuitear en, Tuit original y Sentimiento.
Enfoque para analizar varios sentimientos
Antes de continuar, conviene saber qué se entiende por análisis de sentimiento. El análisis de sentimientos es el proceso de identificar y categorizar computacionalmente las opiniones expresadas en un texto, especialmente para determinar si la actitud del escritor hacia un tema en particular es Positiva, Negativa o Neutral. (Diccionario de Oxford)
A continuación se muestra el procedimiento operativo estándar para abordar el tipo de proyecto de análisis de sentimiento. ¡Pasaremos por este procedimiento para predecir lo que se supone que debemos predecir!
-
Análisis exploratorio de datos.
-
Preprocesamiento de datos.
-
Vectorización.
-
Modelos de clasificación.
-
Evaluación.
-
Conclusión.
Adivinemos algunos tweets
Leeré el tweet y ¿puede decirme el sentimiento de ese tweet si es positivo, negativo o neutral? Entonces el primer tweet es “Todavía me sorprende la cantidad de empleados del supermercado #Toronto que trabajan sin algún tipo de máscara. Todos sabemos a estas alturas que los empleados pueden estar asintomáticos mientras transmiten el #coronavirus ”. ¿Cuál es tu conjetura? Sí, tienes razón. Este es un tweet negativo porque contiene palabras negativas como «sorprendido».
Si no puede adivinar el tweet anterior, no se preocupe, tengo otro tweet para usted. Adivinemos este tweet-“Debido a la situación de Covid-19, hemos aumentado la demanda de todos los productos alimenticios. El tiempo de espera puede ser más largo para todos los pedidos en línea, especialmente los paquetes para congelar y compartir carne de res. Les agradecemos su paciencia durante este tiempo ”. Esta vez tienes toda la razón al predecir este tweet como «Positivo». Las palabras como «gracias», «mayor demanda» son de naturaleza optimista, por lo que estas palabras categorizaron el tweet en positivo.
Resumen de datos
El conjunto de datos original tiene 6 columnas y 41157 filas. Para analizar varios sentimientos, solo necesitamos dos columnas denominadas Tweet original y Sentiment. Hay cinco tipos de sentimientos: Extremadamente negativo, negativo, neutral, positivo y extremadamente positivo como puede ver en la siguiente imagen.
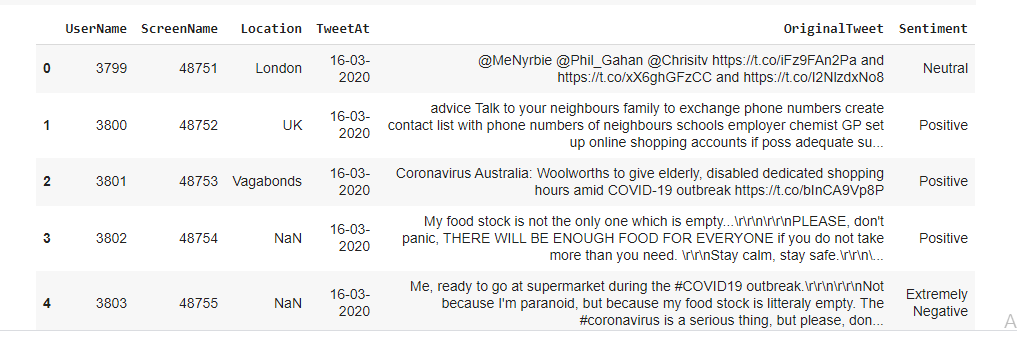
Resumen del conjunto de datos
Análisis de datos exploratorios básicos
Las columnas como «Nombre de usuario» y «Nombre de pantalla”No brindan información significativa para nuestro análisis. Por lo tanto, no utilizamos estas funciones para la construcción de modelos. Todos los datos de tweets recopilados de los meses de marzo y abril de 2020. El siguiente diagrama de barras nos muestra el número de valores únicos en cada columna.
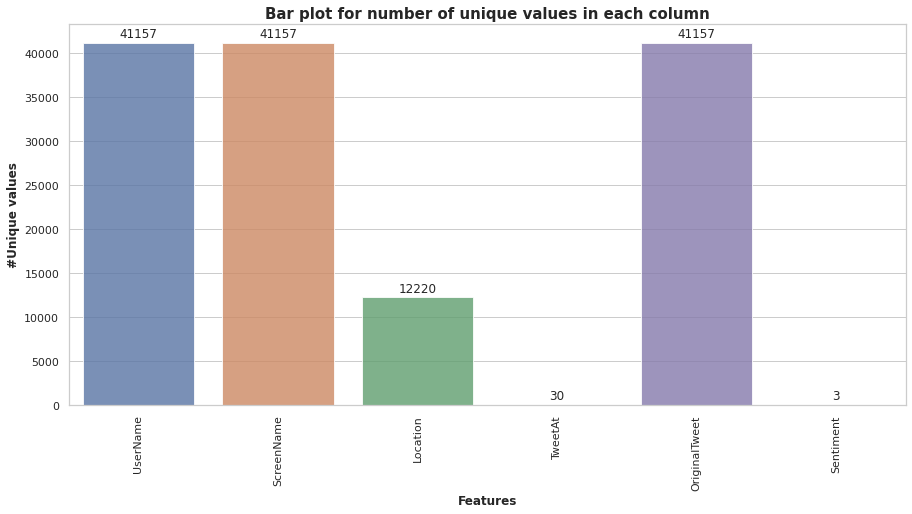
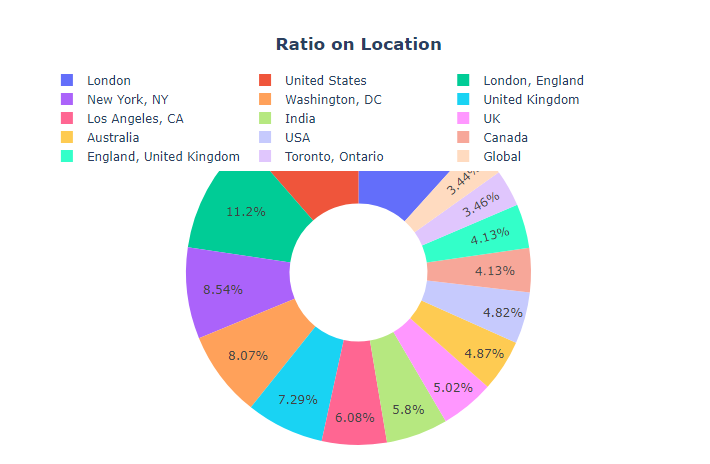
Hay algunos valores nulos en la columna de ubicación, pero no es necesario que nos ocupemos de ellos, ya que solo usaremos dos columnas, es decir, «Sentimiento» y «Tweet original”. El máximo de tweets provino de la ubicación de Londres (11,7%), como se desprende de la siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.....
Hay algunas palabras como ‘coronavirus’, ‘tienda de comestibles’, que tienen la frecuencia máxima en nuestro conjunto de datos. Lo podemos ver en la siguiente nube de palabras. Hay varios #hashtags en la columna de tweets. Pero son casi iguales en todos los sentimientos, por lo que no nos brindan información completa y significativa.
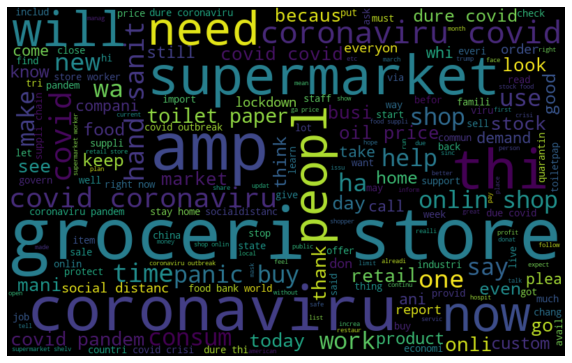
World Cloud mostrando las palabras que tienen una frecuencia máxima en nuestra columna Tweet
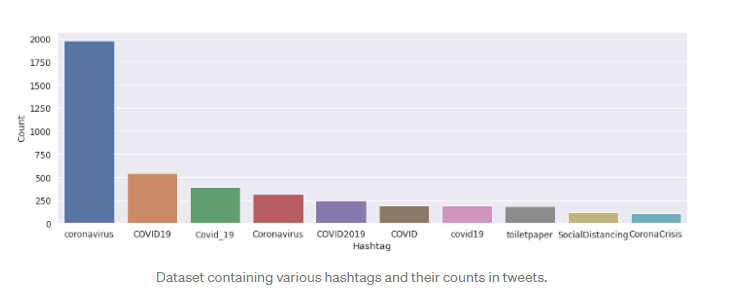
Cuando intentamos explorar la columna ‘Sentimiento’, nos dimos cuenta de que la mayoría de las personas tienen sentimientos positivos sobre varios temas, lo que nos muestra su optimismo durante los tiempos de pandemia. Muy pocas personas tienen pensamientos extremadamente negativos sobre Covid-19.
Preprocesamiento de datos
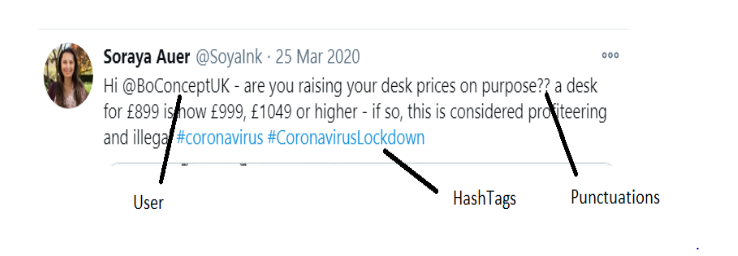
El preprocesamiento de los datos de texto es un paso esencial, ya que hace que el texto sin formato esté listo para la minería. El objetivo de este paso es limpiar los ruidos menos relevantes para encontrar el sentimiento de tweets como puntuación(.,?, ”Etc.), caracteres especiales(@,%, &, $, etc.), números(1,2,3, etc.), mango de tweeter, enlaces(HTTPS: / HTTP:) y términos que no tienen mucho peso en el contexto del texto.
Además, debemos eliminar las palabras vacías de los tweets. Las palabras vacías son aquellas palabras en lenguaje natural que tienen muy poco significado, como «es», «una», «el», etc. Para eliminar las palabras vacías de una oración, puede dividir el texto en palabras y luego eliminar la palabra si existe en la lista de palabras vacías proporcionada por NLTK.
Luego, necesitamos normalizar los tweets usando Stemming o Lemmatization. «Stemming ”es un proceso basado en reglas para eliminar los sufijos (“ ing ”,“ ly ”,“ es ”,“ ed ”,“ s ”, etc.) de una palabra. Por ejemplo, «jugar», «jugador», «jugado», «juega» y «jugar» son las diferentes variaciones de la palabra – «jugar».

La derivación no convertirá las palabras originales en palabras significativas. Como puede ver, «considerado» se deriva en «condit», que no tiene significado y también es un error de ortografía. La mejor forma es utilizar la lematización en lugar del proceso de derivación.
La lematización es una operación más poderosa y toma en consideración el análisis morfológico de las palabras. Devuelve el lema, que es la forma base de todas sus formas flexivas.

Aquí, en el proceso de Lematización, estamos convirtiendo la palabra «levantar» a su forma básica «levantar». También necesitamos convertir todos los tweets a minúsculas antes de realizar el proceso de normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.....
Podemos incluir el proceso de tokenización. En la tokenización, convertimos un grupo de oraciones en tokens. También se denomina segmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo.... de texto o análisis léxico. Básicamente, se trata de dividir los datos en una pequeña cantidad de palabras. La tokenización en Python puede ser realizada por Python NLTK función word_tokenize () de la biblioteca.
Vectorización
Podemos utilizar un vectorizador de conteo o un vectorizador TF-IDF. Count Vectorizer creará una matriz dispersa de todas las palabras y el número de veces que están presentes en un documento.
TFIDF, corto para término frecuencia-frecuencia inversa del documento, es una estadística numérica que pretende reflejar la importancia de una palabra para un documento en una colección o corpus. El valor TF – IDF aumenta proporcionalmente al número de veces que aparece una palabra en el documento y se compensa con el número de documentos del corpus que contienen la palabra, lo que ayuda a ajustar el hecho de que algunas palabras aparecen con mayor frecuencia en general. (wiki)
Modelos de clasificación de edificios
El problema dado es la clasificación ordinal multiclase. Hay cinco tipos de sentimientos, por lo que tenemos que entrenar nuestros modelos para que puedan darnos la etiqueta correcta para el conjunto de datos de prueba. Voy a construir diferentes modelos como Bayes ingenuo, regresión logística, bosque aleatorio, XGBoost, máquinas de vectores de soporte, CatBoost y descenso de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... estocástico.
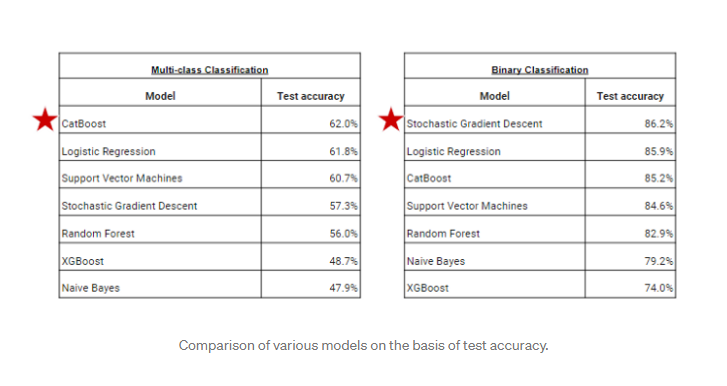
He usado el problema dado de Clasificación multiclase que es una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente que tiene los valores -Positivo, Extremadamente Positivo, Neutral, Negativo, Extremadamente Negativo. También convierto este problema en una clasificación binaria, es decir, clasifiqué todos los tweets en solo dos tipos Positivo y Negativo. También puede optar por la clasificación de tres clases, es decir, Positivo, Negativo y Neutral para lograr una mayor precisión. En la fase de evaluación, compararemos los resultados de estos algoritmos.
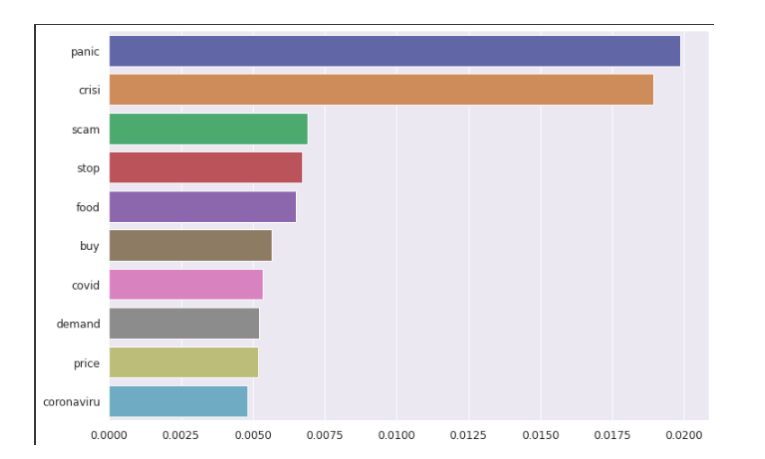
Importancia de la característica
los importancia de la característica (importancia variable) describe cual características es relevante. Puede ayudar a comprender mejor el problema resuelto y, a veces, conducir a mejoras en el modelo al emplear característica selección. Las tres principales palabras destacadas son pánico, crisis y estafa, como podemos ver en el siguiente gráfico.
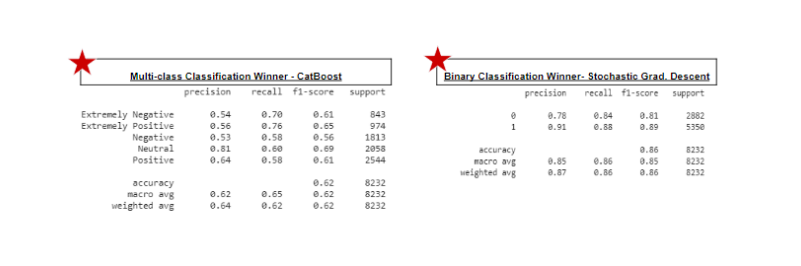
Conclusión
De esta manera, podemos explorar más a partir de varios tweets y datos textuales. Nuestros modelos intentarán predecir correctamente los distintos sentimientos. He utilizado varios modelos para entrenar nuestro conjunto de datos, pero algunos modelos muestran una mayor precisión mientras que otros no. Para la clasificación multiclase, el mejor modelo para este conjunto de datos sería CatBoost. Para la clasificación binaria, el mejor modelo para este conjunto de datos sería Descenso de gradiente estocástico.
(Puede acceder al código Python de este proyecto desde este enlace-https://github.com/rajeshmore1/Capstone-Project-2 )
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





