El código abierto se refiere a algo que las personas pueden modificar y compartir porque son accesibles para todos. Puede utilizar el trabajo de nuevas formas, integrarlo en un proyecto más grande o encontrar un nuevo trabajo basado en el original. El código abierto promueve el libre intercambio de ideas dentro de una comunidad para generar innovaciones o ideas creativas y tecnológicas. Por lo tanto, los programadores deberían considerar la posibilidad de contribuir a proyectos de código abierto por las siguientes razones:
1. Le ayuda a escribir código más limpio.
2. Obtiene una mejor comprensión de la tecnología.
3. Contribuir a proyectos de código abierto le ayuda a ganar atención, popularidad y puede aprovechar su carrera.
4. Agregar un proyecto de código abierto a su currículum aumenta su peso.
5. Mejora las habilidades de codificación
6. Mejorar el software a nivel de usuario y empresarial.
 Fuente: Imágenes de Google
Fuente: Imágenes de Google
Para comenzar a contribuir a proyectos de código abierto, existen algunos requisitos previos:
1. Aprenda un lenguaje de programación: dado que en la contribución de código abierto necesita escribir código para involucrarse en el desarrollo, necesita aprender un lenguaje de programación. Eso puede ser de cualquier elección. Es fácil aprender otro idioma en una etapa posterior dependiendo de las necesidades del proyecto.
2. Familiarícese con los sistemas de control de versiones: estas son las herramientas de software que ayudan a mantener todos los cambios en un solo lugar que se están realizando para recuperarlos en una etapa posterior si es necesario. Básicamente, realizan un seguimiento de cada modificación realizada por usted a lo largo del tiempo en el código fuente. Algunos sistemas de control de versiones populares son Git, Mercurial, CVS, etc. De todos estos, Git es el más popular y ampliamente utilizado en la industria.
Ahora veremos algunos de los increíbles proyectos de código abierto en los que puede contribuir.
¡Entonces empecemos!
1. Caliban
Fuente: Imágenes de Google
Este es un proyecto de aprendizaje automático del gigante tecnológico Google. Se utiliza para desarrollar portátiles y flujos de trabajo de investigación de aprendizaje automático en un entorno informático aislado y reproducible. Resuelve un gran problema. Cuando los desarrolladores están creando proyectos de ciencia de datos, muchas veces es difícil crear un entorno de prueba que pueda mostrar su proyecto en una situación de la vida real. No es posible predecir todos los casos extremos. Entonces, Caliban es una posible solución para este problema. Caliban facilita el desarrollo de cualquier modelo de aprendizaje automático localmente, ejecuta código en su máquina y luego prueba exactamente el mismo código en un entorno de nube para ejecutarlo en máquinas grandes. Por lo tanto, los flujos de trabajo de investigación de Dockerized se simplifican, tanto a nivel local como en la nube.
Enlace de Github: https://github.com/google/caliban
2. Kornia

Fuente: Imágenes de Google
Kornia es una biblioteca de visión por computadora para PyTorch. Se utiliza para resolver algunos problemas genéricos de visión por computadora. Kornia se basa en PyTorch y depende de su eficiencia y potencia de la CPU para poder calcular funciones complejas. Kornia es un paquete de bibliotecas que se utiliza para entrenar modelos de redes neuronales y realizar transformación de imágenes, filtrado de imágenes, detección de bordes, geometría epipolar, estimación de profundidad, etc.
Enlace de Github: https://github.com/kornia/kornia
3. Zoológico de análisis
![]()
Fuente: Imágenes de Google
Analytics Zoo es una plataforma unificada de análisis de datos e inteligencia artificial que une los programas TensorFlow, Keras, PyTorch, Spark, Flink y Ray en una canalización integrada. Esto puede escalar de manera eficiente desde una computadora portátil a un gran clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... para procesar la producción de big data. Este proyecto es mantenido por Intel-analítica.
Analytics Zoo ayuda a una solución de IA de las siguientes formas:
- Le ayuda a crear prototipos de modelos de IA fácilmente.
- El escalado se gestiona de forma eficiente.
- Ayuda a agregar procesos de automatización a su canal de ML como ingeniería de características, selección de modelos, etc.
Enlace de Github: https://github.com/intel-analytics/analytics-zoo
4. Aprendizaje automático automatizado MLJAR para humanos

Fuente: Imágenes de Google
Mljar es una plataforma para crear modelos de prototipos y servicios de implementación. Para encontrar el mejor modelo, Mljar busca diferentes algoritmos y realiza ajustes de hiperparámetros. Proporciona resultados rápidos interesantes al ejecutar todos los cálculos en la nube y finalmente crear modelos de conjunto. Luego, crea un informe para usted a partir del entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de AutoML. ¿No es esto genial?
Mljar entrena eficientemente modelos para clasificación binaria, clasificación de clases múltiples, regresión.
Proporciona dos tipos de interfaces:
- Puede ejecutar modelos de aprendizaje automático en su navegador web
- Proporciona un contenedor de Python sobre la API de Mljar.
El informe recibido de Mljar contiene la tabla con información sobre la puntuación de cada modelo y el tiempo necesario para entrenar cada modelo. El rendimiento se muestra como diagramas de dispersión y de caja, por lo que es fácil comprobar visualmente qué algoritmos funcionan mejor entre todos. Mira esto:
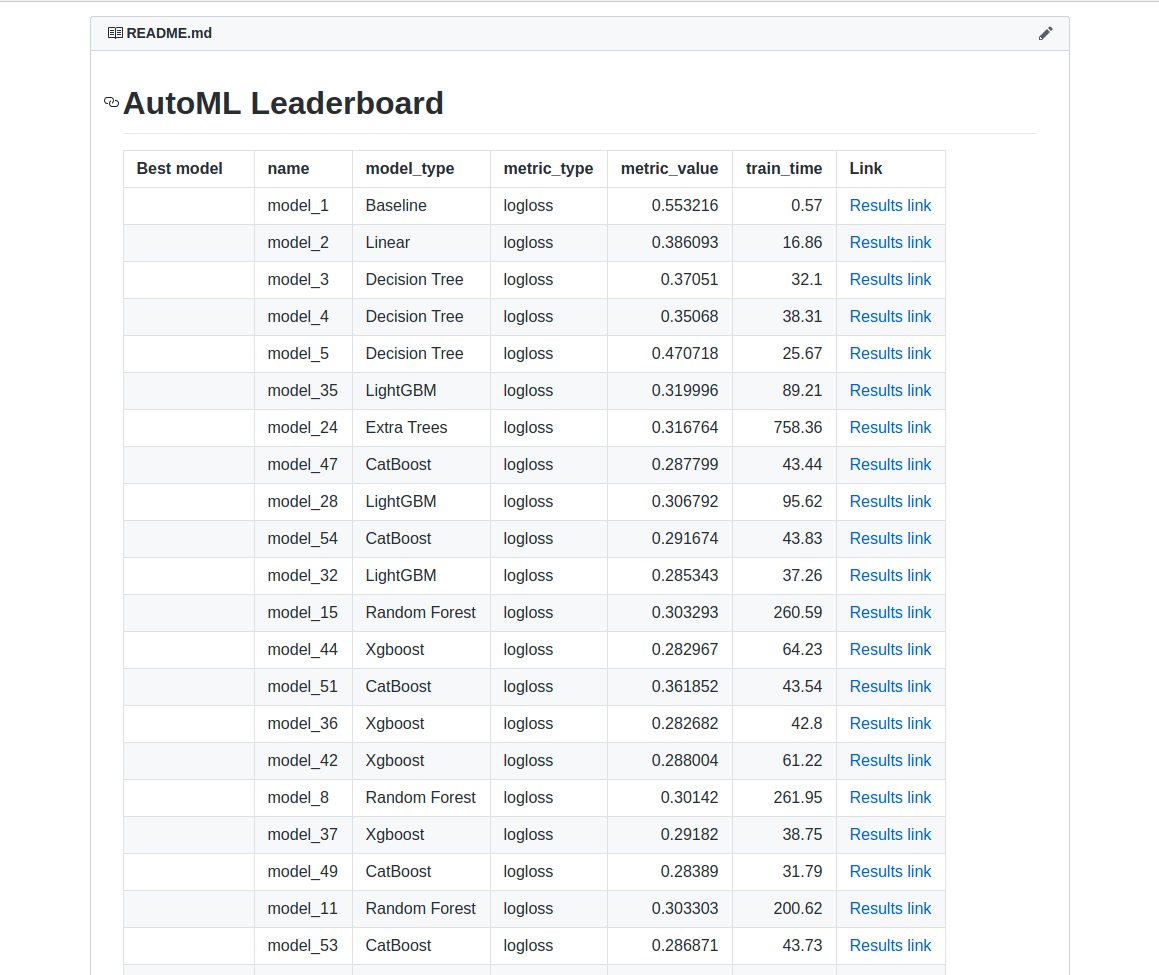
Fuente: Imágenes de Google
Documentación: https://supervised.mljar.com/
Código fuente: https://github.com/mljar/mljar-supervised
5.DeepDetect
Fuente: Imágenes de Google
DeepDetect es una API de aprendizaje automático y un servidor escrito en C ++. Si desea trabajar con algoritmos de aprendizaje automático de última generación y desea integrarlos en aplicaciones existentes, DeepDetect es para usted. DeepDetect admite una amplia variedad de tareas como clasificación, segmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo...., regresión, detección de objetos, codificadores automáticos. Admite el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... supervisado y no supervisado de imágenes, series de tiempo, texto y algunos tipos más de datos. Pero DeepDetect depende de bibliotecas externas de aprendizaje automático como:
- Bibliotecas de aprendizaje profundo: Tensorflow, Caffe2, Torch.
- Biblioteca de aumento de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en...: XGBoost.
- Agrupación con T-SNE.
Enlace de Github: https://github.com/jolibrain/deepdetect
6. Dopamina

Fuente: Imágenes de Google
La dopamina es un proyecto de código abierto del gigante tecnológico Google. Está escrito en Python. Es un marco de investigación para la creación rápida de prototipos de algoritmos de aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas.....
Los principios de diseño de la dopamina son:
- Experimento sencillo: la dopamina facilita a los nuevos usuarios la realización de experimentos.
- Es compacto y confiable.
- También facilita la reproducibilidad de los resultados.
- Es flexible, por lo tanto, facilita que los nuevos usuarios prueben nuevas ideas de investigación.
Nota: Mira estos Cuadernos Colaboratorios para aprender a usar la dopamina.
Enlace de Github: https://github.com/google/dopamine
7. TensorFlow

Fuente: Imágenes de Google
Tensorflow es el más famoso, popular y uno de los mejores proyectos de código abierto de aprendizaje automático en GitHub. Es una biblioteca de software de código abierto para el cálculo numérico utilizando gráficos de flujo de datos. Tiene una interfaz Python muy fácil de usar y no tiene interfaces no deseadas en otros lenguajes para construir y ejecutar gráficos computacionales. TensorFlow proporciona API estables de Python y C ++. Tensorflow tiene algunos casos de uso sorprendentes como:
- En reconocimiento de voz / sonido
- Aplicaciones de bases de texto
- Reconocimiento de imagen
- Detección de video
…¡y muchos más!
Enlace de GitHub: https://github.com/tensorflow/tensorflow
8. PredicciónIO

Fuente: Imágenes de Google
Está construido sobre una pila de código abierto de última generación. Este servidor de aprendizaje automático está diseñado para que los científicos de datos creen motores predictivos para cualquier tarea de aprendizaje automático. Algunas de sus características sorprendentes son:
- Ayuda a construir e implementar rápidamente un motor como un servicio web en plantillas de producción que son personalizables.
- Una vez implementado como servicio web, responda a consultas dinámicas en tiempo real.
- Admite bibliotecas de procesamiento de datos y aprendizaje automático como OpenNLP, Spark MLLib.
- También simplifica la gestión de la infraestructura de datos
Enlace de GitHub: https://github.com/apache/predictionio
9.Scikit-aprender
Fuente: Imágenes de Google
Es una biblioteca de herramientas de aprendizaje automático de software libre basada en Python. Proporciona varios algoritmos para clasificación, regresión, algoritmos de agrupación en clústeres, incluidos bosques aleatorios, aumento de gradiente, DBSCAN. Esto se basa en SciPy que debe estar preinstalado para que pueda usar sci-kit learn. También proporciona modelos para:
- Métodos de conjunto
- Extracción de características
- Ajuste de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto....
- Aprendizaje múltiple
- Selección de características
- Reducción de dimensionalidad
Nota: Para aprender scikit-learn, siga la documentación: https://scikit-learn.org/stable/
Enlace de GitHub: https://github.com/scikit-learn
10. Pylearn2
Pylearn2 es la biblioteca de aprendizaje automático más común entre todos los desarrolladores de Python. Está basado en Theano. Puede usar expresiones matemáticas para escribir su complemento mientras Theano toma o optimización y estabilización. Tiene algunas características asombrosas como:
- Un «algoritmo de entrenamiento predeterminado» para entrenar el modelo en sí
-
- Criterios de estimación del modelo
-
- Puntuación coincidente
- Entropía cruzada
- Probabilidad logarítmica
- Preprocesamiento del conjunto de datos
- NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... de contraste
- Blanqueamiento ZCA
- Extracción de parches (para implementar algoritmos de tipo convolución)
Enlace de GitHub: https://github.com/lisa-lab/pylearn2
Notas finales:
Contribuir al código abierto conlleva demasiados pros. Entonces, estos son algunos buenos proyectos de código abierto para contribuir.
Gracias por leer si llegaste aquí 🙂
Vamos a conectarnos LinkedIn.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





