Este artículo fue publicado como parte del Blogatón de ciencia de datos
Las máquinas que comprenden el lenguaje me fascinan, y a menudo reflexiono sobre qué algoritmos a los que Aristóteles se habría acostumbrado a construir una máquina de análisis retórico si hubiera tenido la posibilidad. Si es nuevo en la ciencia de datos, ingresar a la PNL puede parecer complicado, especialmente porque hay muchos avances recientes en el campo. es difícil entender por dónde empezar.
Tabla de contenido
1. ¿Qué pueden entender las máquinas?
2.Proyecto 1: Nube de palabras
3.Proyecto 2: Detección de spam
4.Proyecto 3: Análisis de sentimientos
5. Conclusión
¿Qué pueden entender las máquinas?
Si bien una computadora puede ser bastante buena para encontrar patrones y resumir documentos, debe transformar palabras en números antes de darles sentido. Esta transformación es muy necesaria porque las matemáticas no funcionan muy bien con las palabras y las máquinas «aprenden» gracias a las matemáticas. Antes de la transformación de las palabras en números, se requiere la limpieza de datos. La limpieza de datos incluye la eliminación de caracteres especiales y puntuación y la modificación en formas que los hacen más uniformes e interpretables.
Proyecto 1: Nube de palabras
1.Importación de dependencias y datos
Empiece por importar las dependencias y los datos. Los datos se almacenan como un archivo de valores separados por comas (CSV), por lo que usaré pandas ‘ read_csv () función para abrirlo en un DataFrame.
import pandas as pd
import sqlite3
import regex as re
import matplotlib.pyplot as plt
from wordcloud import WordCloud
#create dataframe from csv
df = pd.read_csv('emails.csv')
df.head()
df.head()


2.Análisis exploratorio
Para eliminar filas duplicadas y establecer algunos recuentos de línea de base, es mejor hacer un análisis rápido de los datos. Aquí usamos pandas drop_duplicates para eliminar las filas duplicadas.
print("spam count: " +str(len(df.loc[df.spam==1])))
print("not spam count: " +str(len(df.loc[df.spam==0])))
print(df.shape)
df['spam'] = df['spam'].astype(int)
df = df.drop_duplicates()
df = df.reset_index(inplace = False)[['text','spam']]
print(df.shape)
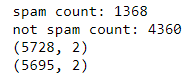
Recuentos y forma antes / después de la eliminación de duplicados
¿Qué es una nube de palabras?
Las nubes de palabras facilitan la comprensión de las frecuencias de las palabras, por lo que es una forma útil de visualizar datos de texto. Las palabras que aparecen más grandes en la nube son las que aparecen con mayor frecuencia en el texto del correo electrónico. Las nubes de palabras facilitan la identificación de «palabras clave».
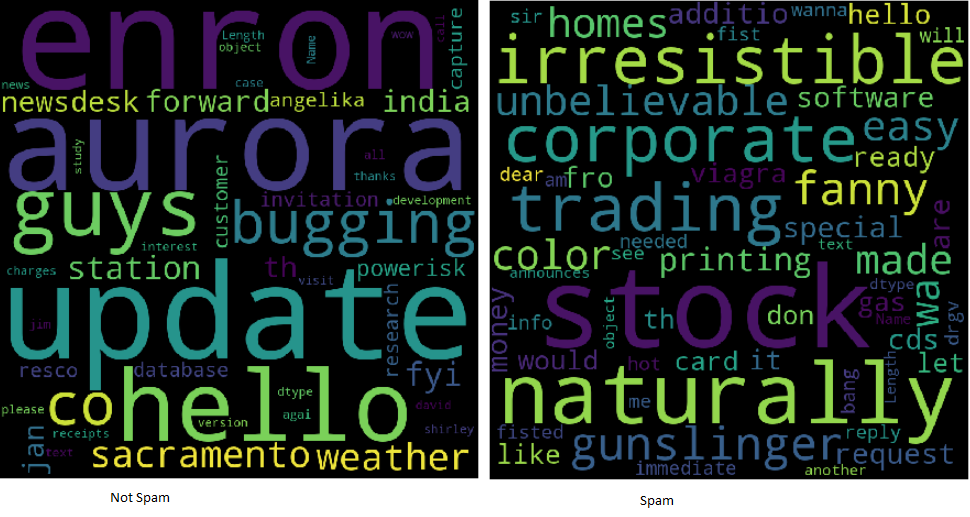
Ejemplos de nube de palabras
Todo el texto está en minúsculas en la imagen de nube de palabras. No contiene signos de puntuación ni caracteres especiales. El texto ahora se llama limpio y listo para su análisis. Con la ayuda de expresiones regulares, es fácil limpiar el texto usando un bucle:
clean_desc = []
for w in range(len(df.text)):
desc = df['text'][w].lower()
#remove punctuation
desc = re.sub('[^a-zA-Z]', ' ', desc)
#remove tags
desc=re.sub("</?.*?>"," <> ",desc)
#remove digits and special chars
desc=re.sub("(d|W)+"," ",desc)
clean_desc.append(desc)
#assign the cleaned descriptions to the data frame
df['text'] = clean_desc
df.head(3)

Observe que aquí creamos una lista vacía clean_desc, luego usamos un en bucle para revisar el texto línea por línea, configurándolo en minúsculas, eliminando la puntuación y los caracteres especiales y agregándolo a la lista. Luego reemplazamos la columna de texto con los datos en la lista clean_desc.
Para las palabras
Las palabras vacías son las palabras más comunes como «el» y «de». Eliminarlos del texto del correo electrónico permite que las palabras frecuentes más relevantes se cuadren. ¡Eliminar las palabras vacías puede ser una técnica común! Algunas bibliotecas de Python como NLTK vienen precargadas con una lista de palabras vacías, pero es fácil formar una desde cero.
stop_words = ['is','you','your','and', 'the', 'to', 'from', 'or', 'I', 'for', 'do', 'get', 'not', 'here', 'in', 'im', 'have', 'on', 're', 'new', 'subject']
Tenga en cuenta que incluyo algunas palabras relacionadas con el correo electrónico, como «re» y «asunto». Depende del analista ver qué palabras deben incluirse o excluirse. ¡A veces es beneficioso incorporar todas las palabras!
Construir la palabra podría
Convenientemente, hay una biblioteca de Python para crear nubes de palabras. Se instalará usando pip.
pip install wordcloud
Al construir la nube de palabras, es posible alinear varios parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... como alto y ancho, palabras vacías y palabras máximas. incluso es posible darle forma en lugar de mostrar el rectángulo predeterminado.
wordcloud = WordCloud(width = 800, height = 800, background_color="black", stopwords = stop_words, max_words = 1000
, min_font_size = 20).generate(str(df1['text']))
#plot the word cloud
fig = plt.figure(figsize = (8,8), facecolor = None)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
Para guardar y mostrar la nube de palabras. Se utilizan matplotlib y show (). Independientemente de que sea spam, es el resultado de todos los registros.

Empuje el ejercicio aún más dividiendo el marco de información y creando nubes de dos palabras para ayudar a analizar la diferencia entre las palabras clave empleadas en el correo electrónico no deseado y no en el correo electrónico no deseado.
Proyecto 2: Detección de spam
Considérelo como un problema de clasificación binaria, ya que un correo electrónico puede ser spam indicado por «1» o no spam indicado por «0». Me gustaría crear un modelo de aprendizaje automático que pueda identificar si un correo electrónico puede ser spam o no. Estoy visitando el uso de la biblioteca de Python Scikit-Learn para explorar los algoritmos de tokenización, vectorización y clasificación estadística.

Importar dependencias
Importe la funcionalidad de Scikit-Learn que nos gustaría modificar y modelar la información. Usaré CountVectorizer, train_test_split, modelos de conjunto y un par de métricas.
from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split from sklearn import ensemble from sklearn.metrics import classification_report, accuracy_score
Transformar texto en números
En el proyecto 1, se limpió el texto. una vez que eche un vistazo a una nube de palabras, observe que se trata principalmente de palabras sueltas. Cuanto más grande sea la palabra, mayor será su frecuencia. Para evitar que la nube de palabras genere oraciones, el texto pasa por un proceso llamado tokenización. es el método de dividir una oración en palabras individuales. Las palabras individuales se llaman tokens.
Con CountVectorizer () de SciKit-Learn, es fácil volver a trabajar el cuerpo del texto en una matriz dispersa de números que la computadora puede pasar a los algoritmos de aprendizaje automático. Para simplificar el concepto de vectorización de conteo, imagina que tienes dos oraciones:
El perro es blanco
El gato es negro
Convertir las oraciones a un modelo de espacio vectorial las transformaría de tal manera que mira las palabras en todas las oraciones y luego representa las palabras en la oración con un número.
El perro gato es blanco negro
The dog is white = [1,1,0,1,1,0] The cat is black = [1,0,1,1,0,1] We can show this using code as well. I’ll add a third sentence to show that it counts the tokens. #list of sentences text = ["the dog is white", "the cat is black", "the cat and the dog are friends"] #instantiate the class cv = CountVectorizer() #tokenize and build vocab cv.fit(text) print(cv.vocabulary_) #transform the text vector = cv.transform(text) print(vector.toarray())
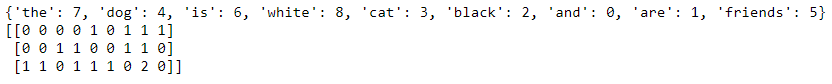
La escasa matriz de recuentos de palabras.
Observe que dentro del último vector, podrá ver un 2 ya que la palabra «the» aparece dos veces. CountVectorizer cuenta los tokens y me permite construir la matriz dispersa que contiene las palabras transformadas en números.
Método de la bolsa de palabras
Debido a que el modelo no tiene en cuenta la ubicación de las palabras y, en su lugar, las mezcla como si fueran fichas en un juego de scrabble, esto a menudo se llama el método de la bolsa de palabras. Estoy de visita para crear la matriz dispersa, luego dividir la información usando SK-learn train_test_split ().
text_vec = CountVectorizer().fit_transform(df['text']) X_train, X_test, y_train, y_test = train_test_split(text_vec, df['spam'], test_size = 0.45, random_state = 42, shuffle = True)
Observe que configuré la matriz dispersa text_vec en X y el df[‘spam’] columna a Y. Barajo y tomo un tamaño de prueba del 45%.
El clasificador
Es muy recomendable experimentar con varios clasificadores y determinar cuál funciona mejor para este escenario. durante este ejemplo, estoy usando el modelo GradientBoostingClassifier () de la colección Scikit-Learn Ensemble.
classifier = ensemble.GradientBoostingClassifier( n_estimators = 100, #how many decision trees to build learning_rate = 0.5, #learning rate max_depth = 6 )
Cada algoritmo tendrá su propio conjunto de parámetros que podrá modificar. eso se llama ajuste de hiperparámetros. someterse a la documentación para obtener más información sobre cada uno de los parámetros utilizados en los modelos.
Generar predicciones
Finalmente, ajustamos la información, llamamos a predecir y generamos el informe de clasificación. Al usar clasificación_report (), es fácil crear un informe de texto que muestre la mayoría de las métricas de clasificación.
classifier.fit(X_train, y_train) predictions = classifier.predict(X_test) print(classification_report(y_test, predictions))
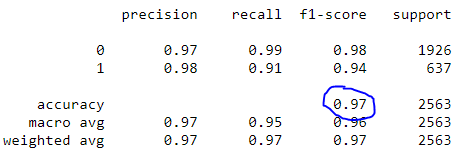
Informe de clasificación
Observe que nuestro modelo logró una precisión del 97%.
Proyecto 3: Análisis de sentimiento
El análisis de sentimiento es, además, una especie de problema de clasificación. El texto es básicamente de visita para reflejar un sentimiento positivo, neutral o negativo. eso se nota debido a la polaridad del texto. ¡también es posible determinar y dar cuenta de la subjetividad del texto! Hay muchos recursos excelentes que cubren la especulación detrás del análisis de sentimientos.
En lugar de construir otro modelo, este proyecto utiliza una herramienta sencilla y lista para usar para investigar el sentimiento llamada TextBlob. Usaré TextBlob para presentar columnas de opinión en el DataFrame para que se analicen a menudo.

¿Qué es TextBlob?
Construida sobre NLTK y patrón, la biblioteca TextBlob para Python 2 y tres intenta simplificar varias tareas de procesamiento de texto. Proporciona herramientas para clasificación, etiquetado de parte del discurso, extracción de frases, análisis de sentimientos y más. Instálelo usando pip.
pip install -U textblob python -m textblob.download_corpora
Sentimiento de TextBlob
Usando la propiedad de sentimiento, TextBlob devuelve una tupla con nombre de la forma Sentiment (polaridad, subjetividad). La polaridad puede flotar dentro del rango [-1.0, 1.0] donde -1 es el más negativo y 1 es el más positivo. La subjetividad podría flotar dentro del rango [0.0, 1.0] donde 0.0 es extremadamente objetivo y 1.0 es extremadamente subjetivo.
blob = TextBlob("This is a good example of a TextBlob")
print(blob)blob.sentiment
#Sentiment(polarity=0.7, subjectivity=0.6000000000000001)
Aplicar TextBlob
Al usar listas de comprensión, es fácil cargar la columna de texto como TextBlob, así que cree dos nuevas columnas para almacenar la polaridad y la subjetividad.
#load the descriptions into textblob email_blob = [TextBlob(text) for text in df['text']] #add the sentiment metrics to the dataframe df['tb_Pol'] = [b.sentiment.polarity for b in email_blob] df['tb_Subj'] = [b.sentiment.subjectivity for b in email_blob] #show dataframe df.head(3)

TextBlob hace que sea muy simple llegar a una puntuación de sentimiento de referencia para la polaridad y subjetividad. Para impulsar a este usuario aún más, vea si podrá agregar estas nuevas funciones al modelo de detección de spam para ampliar la precisión.
Conclusión:
Aunque el procesamiento de la comunicación lingüística puede parecer un tema intimidante, las piezas fundamentales no parecen ser tan difíciles de entender. Muchas bibliotecas facilitan el inicio de la exploración de la ciencia de datos y la PNL. Completando estos tres proyectos:
Nube de palabras
Detección de spam
Análisis de los sentimientos
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





