Visión general:
- Aprenda qué es Big Data y cómo es relevante en el mundo actual
- Conozca las características del Big Data
Introducción
El término «Big Data» es un nombre poco apropiado, ya que implica que los datos preexistentes son de alguna manera pequeños (no lo son) o que el único desafío es su gran tamaño (el tamaño es uno de ellos, pero a menudo hay más ).
En resumen, el término Big Data se aplica a la información que no se puede procesar o analizar mediante procesos o herramientas tradicionales.

Cada vez más, las organizaciones de hoy se enfrentan a más y más desafíos de Big Data. Tienen acceso a una gran cantidad de información, pero no saben cómo sacarle valor porque se encuentra en su forma más cruda o en un formato semiestructurado o no estructurado; y como resultado, ni siquiera saben si vale la pena conservarlo (o incluso si pueden conservarlo).
En este artículo, analizamos el concepto de big data y de qué se trata.
Tabla de contenido
- ¿Qué es Big Data?
- Características de Big Data
- El volumen de datos
- La variedad de datos
- La velocidad de los datos
¿Qué es Big Data?
¡Somos parte de ello, todos los días!
Una encuesta de IBM encontró que más de la mitad de los líderes empresariales de hoy se dan cuenta de que no tienen acceso a la información que necesitan para hacer su trabajo. Las empresas se enfrentan a estos desafíos en un clima en el que tienen la capacidad de almacenar cualquier cosa y están generando datos como nunca antes en la historia; combinado, esto presenta un verdadero desafío de información.

Es un enigma: las empresas de hoy tienen más acceso a información potencial que nunca, sin embargo, a medida que se acumula esta mina de oro potencial de datos, el porcentaje de datos que la empresa puede procesar se reduce rápidamente. En pocas palabras, la era de Big Data está en plena vigencia hoy porque el mundo está cambiando.
A través de la instrumentación, podemos sentir más cosas y, si podemos sentirlo, tendemos a intentar almacenarlo (o al menos parte de él). A través de los avances en la tecnología de las comunicaciones, las personas y las cosas están cada vez más interconectadas, y no solo algunas veces, sino todo el tiempo. Esta tasa de interconectividad es un tren fuera de control. Generalmente conocida como máquina a máquina (M2M), la interconectividad es responsable de tasas de crecimiento de datos de dos dígitos año tras año (YoY).
Finalmente, debido a que los circuitos integrados pequeños ahora son tan económicos, podemos agregar inteligencia a casi todo. Incluso algo tan mundano como un vagón de tren tiene cientos de sensores. En un vagón de ferrocarril, estos sensores rastrean cosas como las condiciones experimentadas por el vagón, el estado de las piezas individuales y los datos basados en GPS para el seguimiento y la logística de envíos. Después de descarrilamientos de trenes que se cobraron grandes pérdidas de vidas, los gobiernos introdujeron regulaciones para que este tipo de datos se almacenen y analicen para prevenir futuros desastres.
Los vagones de ferrocarril también se están volviendo más inteligentes: se han agregado procesadores para interpretar los datos de los sensores en las partes propensas al desgaste, como los rodamientos, para identificar las partes que necesitan reparación antes de que fallen y causen más daños, o peor aún, un desastre. Pero no son solo los vagones de ferrocarril los que son inteligentes, los rieles reales tienen sensores cada pocos pies. Además, los requisitos de almacenamiento de datos son para todo el ecosistema: automóviles, rieles, sensores de cruces de ferrocarril, patrones climáticos que causan movimientos ferroviarios, etc.
Ahora agregue esto para rastrear la carga de un vagón de tren, los tiempos de llegada y salida, y podrá ver muy rápidamente que tiene un problema de Big Data en sus manos. Incluso si cada bit de estos datos fuera relacional (y no lo es), todos serán sin procesar y tendrán formatos muy diferentes, lo que hace que procesarlos en un sistema relacional tradicional sea poco práctico o imposible. Los vagones son solo un ejemplo, pero dondequiera que miremos, vemos dominios con velocidad, volumen y variedad que se combinan para crear el problema de Big Data.
¿Cuáles son las características del Big Data?
Tres características definen el Big Data: volumen, variedad y velocidad.
Juntas, estas características definen “Big Data”. Han creado la necesidad de una nueva clase de capacidades para aumentar la forma en que se hacen las cosas hoy para proporcionar una mejor línea de visión y control sobre nuestros dominios de conocimiento existentes y la capacidad de actuar sobre ellos.
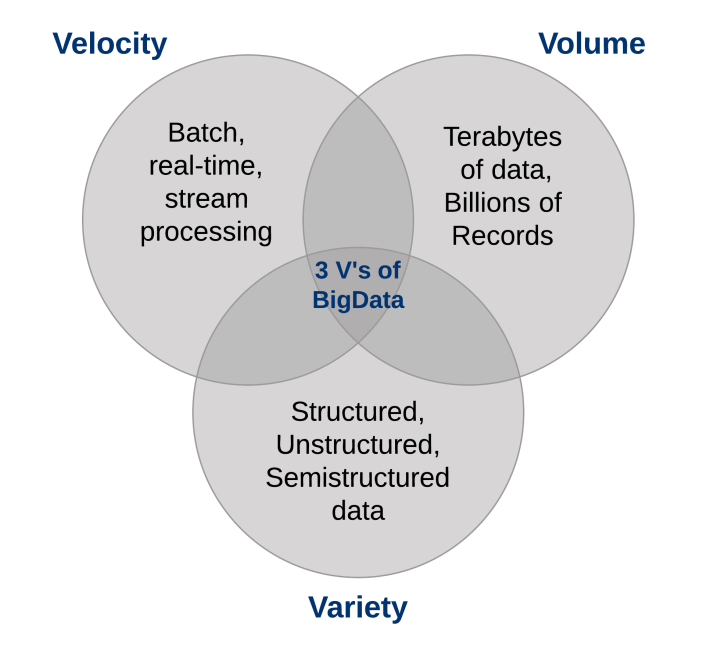
1. El volumen de datos
El gran volumen de datos que se almacenan en la actualidad se está disparando. En el año 2000, se almacenaron 800.000 petabytes (PB) de datos en el mundo. Por supuesto, muchos de los datos que se crean hoy en día no se analizan en absoluto y ese es otro problema que debe tenerse en cuenta. Se espera que este número alcance los 35 zettabytes (ZB) para 2020. Twitter solo genera más de 7 terabytes (TB) de datos todos los días, Facebook 10 TB y algunas empresas generan terabytes de datos cada hora de todos los días del año. Ya no es extraño que las empresas individuales tengan clústeres de almacenamiento que contengan petabytes de datos.

Cuando te detienes y lo piensas, es un poco extraño que estemos ahogados en datos. Almacenamos todo: datos medioambientales, datos financieros, datos médicos, datos de vigilancia y la lista sigue y sigue. Por ejemplo, sacar su teléfono inteligente de su funda genera un evento; cuando la puerta de su tren de cercanías se abre para abordar, es un evento; registrarse para tomar un avión, ingresar al trabajo, comprar una canción en iTunes, cambiar el canal de televisión, tomar una ruta de peaje electrónico: cada una de estas acciones genera datos.
De acuerdo, entiendes el punto: hay más datos que nunca y todo lo que tienes que hacer es mirar la tasa de penetración de terabytes para las computadoras personales en el hogar como señal reveladora. Solíamos mantener una lista de todos los almacenes de datos que conocíamos que superaron el terabyte hace casi una década; basta con decir que las cosas han cambiado en lo que respecta al volumen.
Como implica el término «Big Data», las organizaciones se enfrentan a enormes volúmenes de datos. Las organizaciones que no saben cómo administrar estos datos se ven abrumadas por ellos. Pero existe la oportunidad, con la plataforma tecnológica adecuada, de analizar casi todos los datos (o al menos más de ellos identificando los datos que son útiles para usted) para obtener una mejor comprensión de su negocio, sus clientes y el mercado. Y esto conduce al enigma actual al que se enfrentan las empresas actuales en todas las industrias.
A medida que aumenta la cantidad de datos disponibles para la empresa, el porcentaje de datos que puede procesar, comprender y analizar está disminuyendo, creando así la zona ciega.
¿Qué hay en esa zona ciega?
No lo sabes: puede ser algo grandioso o tal vez nada en absoluto, pero el “no sé” es el problema (o la oportunidad, dependiendo de cómo lo mires). La conversación sobre los volúmenes de datos ha cambiado de terabytes a petabytes con un cambio inevitable a zettabytes, y todos estos datos no se pueden almacenar en sus sistemas tradicionales.
2. La variedad de datos
El volumen asociado con el fenómeno de Big Data trae consigo nuevos desafíos para los centros de datos que intentan lidiar con él: su variedad.
Con la explosión de sensores y dispositivos inteligentes, así como las tecnologías de colaboración social, los datos en una empresa se han vuelto complejos, porque incluyen no solo datos relacionales tradicionales, sino también datos sin procesar, semiestructurados y no estructurados de páginas web, weblog archivos (incluidos datos de flujo de clics), índices de búsqueda, foros de redes sociales, correo electrónico, documentos, datos de sensores de sistemas activos y pasivos, etc.
Además, los sistemas tradicionales pueden tener dificultades para almacenar y realizar los análisis necesarios para comprender el contenido de estos registros porque gran parte de la información que se genera no se presta a las tecnologías de bases de datos tradicionales. En mi experiencia, aunque algunas empresas están avanzando en el camino, en general, la mayoría apenas está comenzando a comprender las oportunidades de Big Data.
En pocas palabras, la variedad representa todos los tipos de datos: un cambio fundamental en los requisitos de análisis de los datos estructurados tradicionales para incluir datos sin procesar, semiestructurados y no estructurados como parte del proceso de toma de decisiones y conocimiento. Las plataformas analíticas tradicionales no pueden manejar la variedad. Sin embargo, el éxito de una organización dependerá de su capacidad para extraer conocimientos de los diversos tipos de datos disponibles, que incluyen tanto los tradicionales como los no tradicionales.
Cuando miramos hacia atrás en nuestras carreras de bases de datos, a veces es humillante ver que pasamos más de nuestro tiempo en solo el 20 por ciento de los datos: el tipo relacional que está perfectamente formateado y encaja muy bien en nuestros esquemas estrictos. Pero la verdad del asunto es que el 80 por ciento de los datos del mundo (y cada vez más de estos datos son responsables de establecer nuevos récords de velocidad y volumen) no están estructurados o, en el mejor de los casos, semiestructurados. Si miras un feed de Twitter, verás la estructura en su formato JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software..., pero el texto real no está estructurado y comprender eso puede ser gratificante.
Las imágenes de video e imágenes no se almacenan fácil o eficientemente en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... relacional, cierta información de eventos puede cambiar dinámicamente (como los patrones climáticos), lo que no es adecuado para esquemas estrictos, y más. Para capitalizar la oportunidad de Big Data, las empresas deben poder analizar todo tipo de datos, tanto relacionales como no relacionales: texto, datos de sensores, audio, video, transaccionales y más.
3. La velocidad de los datos
Así como ha cambiado el volumen y la variedad de datos que recopilamos y la tienda, también ha cambiado la velocidad a la que se generan y deben manejarse. Una comprensión convencional de la velocidad generalmente considera qué tan rápido llegan y almacenan los datos, y sus tasas de recuperación asociadas. Si bien administrar todo eso rápidamente es bueno, y los volúmenes de datos que estamos viendo son una consecuencia de la rapidez con la que llegan los datos.
Para adaptarse a la velocidad, una nueva forma de pensar sobre un problema debe comenzar en el punto de inicio de los datos. En lugar de limitar la idea de velocidad a las tasas de crecimiento asociadas con sus repositorios de datos, le sugerimos que aplique esta definición a los datos en movimiento: la velocidad a la que fluyen los datos.
Después de todo, estamos de acuerdo en que las empresas de hoy están tratando con petabytes de datos en lugar de terabytes, y el aumento de sensores RFID y otros flujos de información ha llevado a un flujo constante de datos a un ritmo que lo ha hecho imposible para los sistemas tradicionales. manejar. A veces, obtener una ventaja sobre la competencia puede significar identificar una tendencia, problema u oportunidad solo segundos, o incluso microsegundos, antes que otra persona.
Además, cada vez más datos que se producen en la actualidad tienen una vida útil muy corta, por lo que las organizaciones deben poder analizar estos datos casi en tiempo real si esperan encontrar información valiosa en estos datos. En el procesamiento tradicional, puede pensar en ejecutar consultas con datos relativamente estáticos: por ejemplo, la consulta «Muéstrame todas las personas que viven en la zona de inundación ABC» daría como resultado un único conjunto de resultados que se usaría como una lista de advertencia de un clima entrante. patrón. Con la computación de flujos, puede ejecutar un proceso similar a una consulta continua que identifica a las personas que se encuentran actualmente «en las zonas de inundación ABC», pero obtiene resultados continuamente actualizados porque la información de ubicación de los datos del GPS se actualiza en tiempo real.
Tratar con eficacia Big Data requiere que realice análisis contra el volumen y la variedad de datos mientras todavía están en movimiento, no solo después de que están en reposo. Considere ejemplos desde el seguimiento de la salud neonatal hasta los mercados financieros; en todos los casos, requieren manejar el volumen y la variedad de datos de nuevas formas.
Notas finales
No puede permitirse el lujo de examinar todos los datos que están disponibles para usted en sus procesos tradicionales; son demasiados datos con muy poco valor conocido y demasiado costo apostado. Las plataformas de Big Data le brindan una manera de almacenar y procesar económicamente todos esos datos y descubrir qué es valioso y qué vale la pena explotar. Además, dado que hablamos de análisis de datos en reposo y datos en movimiento, los datos reales a partir de los cuales puede encontrar valor no solo son más amplios, sino que también pueden usarlos y analizarlos más rápidamente en tiempo real.
Le recomiendo que lea estos artículos para familiarizarse con las herramientas para big data:
Háganos saber sus pensamientos en los comentarios a continuación.
Referencia
Entendiendo Big Data: Análisis para datos de transmisión y Hadoop de clase empresarial.





