Reflejos
- La tokenización es un aspecto clave (y obligatorio) de trabajar con datos de texto
- Discutiremos los diversos matices de la tokenización, incluido cómo manejar palabras fuera del vocabulario (OOV)
Introducción
El lenguaje es algo bello. Pero dominar un nuevo idioma desde cero es una perspectiva bastante abrumadora. Si alguna vez aprendió un idioma que no era su lengua materna, ¡se identificará con esto! Hay tantas capas que quitar y sintaxis que considerar, es todo un desafío.
Y así es exactamente con nuestras máquinas. Para que nuestra computadora entienda cualquier texto, necesitamos descomponer esa palabra de una manera que nuestra máquina pueda entender. Ahí es donde entra el concepto de tokenización en el procesamiento del lenguaje natural (NLP).
En pocas palabras, no podemos trabajar con datos de texto si no realizamos la tokenización. ¡Sí, es realmente tan importante!

Y aquí está lo intrigante de la tokenización: no es solo sobre desglosar el texto. La tokenización juega un papel importante en el manejo de datos de texto. Entonces, en este artículo, exploraremos las profundidades de la tokenización en el procesamiento del lenguaje natural y cómo puede implementarlo en Python.
Recomiendo tomarse un tiempo para revisar el siguiente recurso si es nuevo en PNL:
Tabla de contenido
- Un resumen rápido de la tokenización
- Las verdaderas razones detrás de la tokenización
- ¿Qué tokenización (palabra, carácter o subpalabra) deberíamos usar?
- Implementación de tokenización: codificación de pares de bytes en Python
Un resumen rápido de la tokenización
La tokenización es una tarea común en el procesamiento del lenguaje natural (NLP). Es un paso fundamental en los métodos tradicionales de PNL como Count Vectorizer y arquitecturas basadas en Advanced Deep Learning como Transformers.
Los tokens son los componentes básicos del lenguaje natural.
La tokenización es una forma de separar un fragmento de texto en unidades más pequeñas llamadas tokens. Aquí, los tokens pueden ser palabras, caracteres o subpalabras. Por lo tanto, la tokenización se puede clasificar ampliamente en 3 tipos: tokenización de palabra, carácter y subpalabra (caracteres n-grama).
Por ejemplo, considere la oración: «Nunca te rindas».
La forma más común de formar tokens se basa en el espacio. Suponiendo que el espacio es un delimitador, la tokenización de la oración da como resultado 3 tokens: Nunca te rindas. Como cada token es una palabra, se convierte en un ejemplo de tokenización de Word.
De manera similar, los tokens pueden ser caracteres o subpalabras. Por ejemplo, consideremos «más inteligente»:
- Fichas de personaje: más inteligente
- Fichas de subpalabras: más inteligente
¿Pero entonces es esto necesario? ¿Realmente necesitamos la tokenización para hacer todo esto?
Nota: Si es nuevo en PNL, consulte nuestra Curso de PNL en línea
Las verdaderas razones detrás de la tokenización
Dado que los tokens son los componentes básicos de Natural Language, la forma más común de procesar el texto sin formato ocurre a nivel del token.
Por ejemplo, los modelos basados en Transformer, las arquitecturas de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... de vanguardia (SOTA) en NLP, procesan el texto sin procesar a nivel de token. De manera similar, las arquitecturas de aprendizaje profundo más populares para NLP como RNN, GRU y LSTM también procesan el texto sin procesar a nivel de token.
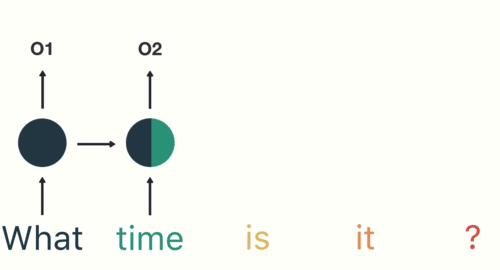
Funcionamiento de la red neuronal recurrenteLas redes neuronales recurrentes (RNN) son un tipo de arquitectura de redes neuronales diseñadas para procesar secuencias de datos. A diferencia de las redes neuronales tradicionales, las RNN utilizan conexiones internas que permiten recordar información de entradas anteriores. Esto las hace especialmente útiles en tareas como el procesamiento de lenguaje natural, la traducción automática y el análisis de series temporales, donde el contexto y la secuencia son fundamentales para la...
Como se muestra aquí, RNN recibe y procesa cada token en un paso de tiempo particular.
Por lo tanto, la tokenización es el paso más importante al modelar datos de texto. La tokenización se realiza en el corpus para obtener tokens. Las siguientes fichas se utilizan luego para preparar un vocabulario. El vocabulario se refiere al conjunto de tokens únicos en el corpus. Recuerde que el vocabulario se puede construir considerando cada token único en el corpus o considerando las K palabras más frecuentes.
La creación de vocabulario es el objetivo final de la tokenización.
Uno de los trucos más simples para mejorar el rendimiento del modelo de PNL es crear un vocabulario a partir de las K palabras más frecuentes..
Ahora, comprendamos el uso del vocabulario en los métodos de PNL tradicionales y avanzados basados en el aprendizaje profundo.
- Los enfoques tradicionales de PNL, como Count Vectorizer y TF-IDF, utilizan vocabulario como características. Cada palabra del vocabulario se trata como una característica única:
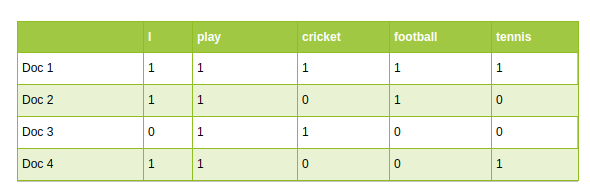
PNL tradicional: Vectorizador de conteo
- En las arquitecturas de PNL basadas en aprendizaje profundo avanzado, el vocabulario se utiliza para crear las oraciones de entrada tokenizadas. Finalmente, los tokens de estas oraciones se pasan como entradas al modelo.
¿Qué tokenización debería utilizar?
Como se mencionó anteriormente, la tokenización se puede realizar a nivel de palabra, carácter o subpalabra. Es una pregunta común: ¿qué tokenización deberíamos usar al resolver una tarea de PNL? Abordemos esta pregunta aquí.
Tokenización de palabras
La tokenización de palabras es el algoritmo de tokenización más utilizado. Divide un fragmento de texto en palabras individuales según un delimitador determinado. Dependiendo de los delimitadores, se forman diferentes tokens de nivel de palabra. Las incrustaciones de palabras previamente entrenadas como Word2Vec y GloVe se incluyen en la tokenización de palabras.
Pero esto tiene algunos inconvenientes.
Inconvenientes de la tokenización de palabras
Uno de los principales problemas con los tokens de palabras es lidiar con Palabras sin vocabulario (OOV). Las palabras OOV se refieren a las nuevas palabras que se encuentran en las pruebas. Estas nuevas palabras no existen en el vocabulario. Por lo tanto, estos métodos fallan en el manejo de palabras OOV.
Pero espera, ¡no saques conclusiones precipitadas todavía!
- Un pequeño truco puede rescatar los tokenizadores de palabras de las palabras OOV. El truco consiste en formar el vocabulario con las K palabras frecuentes más frecuentes y reemplazar las palabras raras en los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... con desconocido tokens (UNK). Esto ayuda al modelo a aprender la representación de palabras OOV en términos de tokens UNK
- Por lo tanto, durante el tiempo de prueba, cualquier palabra que no esté presente en el vocabulario se asignará a un token UNK. Así es como podemos abordar el problema de OOV en tokenizadores de palabras.
- El problema con este enfoque es que toda la información de la palabra se pierde cuando estamos mapeando OOV a tokens UNK. La estructura de la palabra puede ser útil para representarla con precisión. Y otro problema es que cada palabra OOV tiene la misma representación

Otro problema con los tokens de palabras está relacionado con el tamaño del vocabulario. Generalmente, los modelos entrenados previamente se entrenan en un gran volumen del corpus de texto. Entonces, imagínese construir el vocabulario con todas las palabras únicas en un corpus tan grande. ¡Esto explota el vocabulario!
Esto abre la puerta a la tokenización de personajes.
Tokenización de personajes
La tokenización de caracteres divide cada texto en un conjunto de caracteres. Supera los inconvenientes que vimos anteriormente sobre la tokenización de palabras.
- Los tokenizadores de caracteres manejan las palabras OOV de manera coherente al preservar la información de la palabra. Divide la palabra OOV en caracteres y representa la palabra en términos de estos caracteres.
- También limita el tamaño del vocabulario. ¿Quieres adivinar el tamaño del vocabulario? 26 ya que el vocabulario contiene un conjunto único de caracteres
Inconvenientes de la tokenización de personajes
Las fichas de caracteres resuelven el problema OOV, pero la longitud de las oraciones de entrada y salida aumenta rápidamente a medida que representamos una oración como una secuencia de caracteres. Como resultado, se vuelve un desafío aprender la relación entre los personajes para formar palabras significativas.
Esto nos lleva a otra tokenización conocida como tokenización de subpalabras, que se encuentra entre una tokenización de palabras y caracteres.
Tokenización de subpalabras
La tokenización de subpalabras divide el fragmento de texto en subpalabras (o caracteres n-gramo). Por ejemplo, palabras como más bajo se pueden segmentar como más bajo, más inteligente como más inteligente, etc.
Los modelos basados en transformados, el SOTA en NLP, se basan en los algoritmos de tokenización de subpalabras para preparar el vocabulario. Ahora, discutiré uno de los algoritmos de tokenización de subpalabras más populares conocido como Codificación de pares de bytes (BPE).
Bienvenido a Byte Pair Encoding (BPE)
La codificación de pares de bytes (BPE) es un método de tokenización ampliamente utilizado entre los modelos basados en transformadores. BPE aborda los problemas de los tokenizadores de caracteres y palabras:
- BPE aborda OOV de manera efectiva. Segmenta OOV como subpalabras y representa la palabra en términos de estas subpalabras.
- La longitud de las oraciones de entrada y salida después de BPE es más corta en comparación con la tokenización de caracteres
BPE es un algoritmo de segmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo.... de palabras que fusiona los caracteres o secuencias de caracteres que ocurren con más frecuencia de forma iterativa. Aquí hay una guía paso a paso para aprender BPE.
Pasos para aprender BPE
- Divida las palabras del corpus en caracteres después de agregar
- Inicializar el vocabulario con caracteres únicos en el corpus.
- Calcule la frecuencia de un par de caracteres o secuencias de caracteres en el corpus
- Fusionar el par más frecuente en corpus
- Guarde la mejor pareja en el vocabulario
- Repita los pasos 3 a 5 para un cierto número de iteraciones
Entenderemos los pasos con un ejemplo.
Considere un corpus: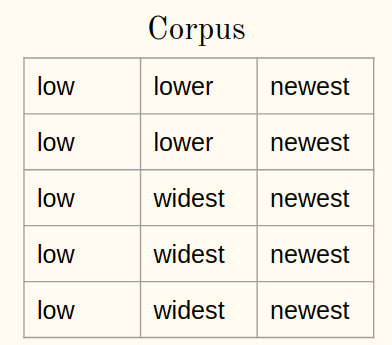
1a) Agregue el símbolo del final de la palabra (diga ) a cada palabra del corpus:
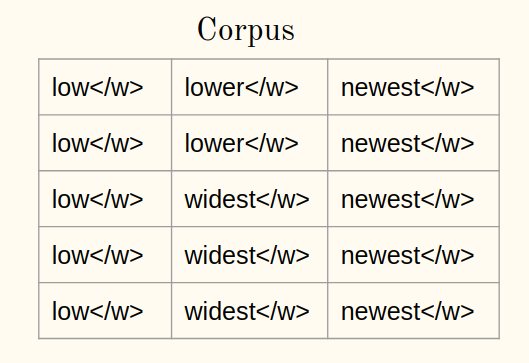
1b) Tokenice las palabras de un corpus en caracteres:
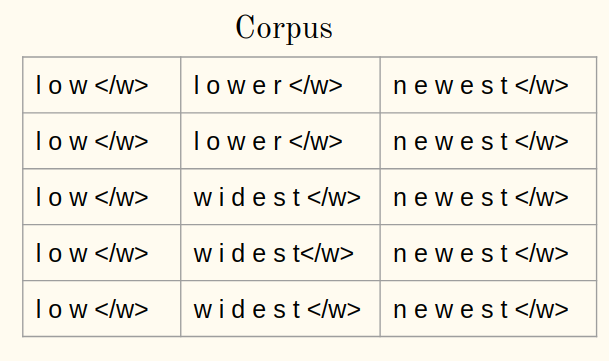
2. Inicialice el vocabulario:

Iteración 1:
3. Calcular la frecuencia:

4. Fusionar el par más frecuente:
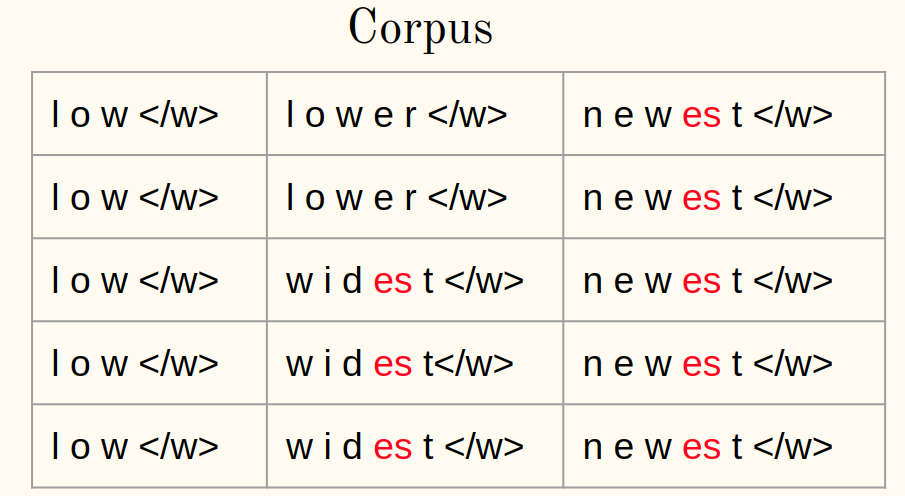
5. Guarde el mejor par:

Repita los pasos 3-5 para cada iteración a partir de ahora. Permítanme ilustrar una iteración más.
Iteración 2:
3. Calcular la frecuencia:

4. Fusionar el par más frecuente:
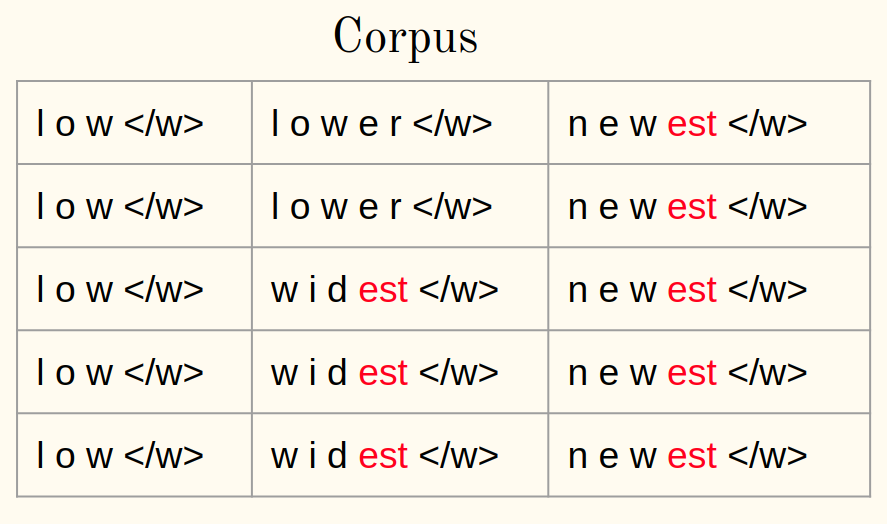
5. Guarde el mejor par:

Después de 10 iteraciones, las operaciones de combinación de BPE se ven así:

Bastante sencillo, ¿verdad?
Aplicar BPE a palabras OOV
Pero, ¿cómo podemos representar la palabra OOV en el momento de la prueba usando operaciones aprendidas BPE? ¿Algunas ideas? Respondamos esta pregunta ahora.
En el momento de la prueba, la palabra OOV se divide en secuencias de caracteres. Luego, las operaciones aprendidas se aplican para fusionar los caracteres en símbolos conocidos más grandes.
– Traducción automática neuronal de palabras raras con unidades de subpalabras, 2016
A continuación, se muestra un procedimiento paso a paso para representar palabras OOV:
- Divida la palabra OOV en caracteres después de agregar
- Calcular un par de caracteres o secuencias de caracteres en una palabra
- Seleccionar los pares presentes en las operaciones aprendidas
- Fusionar el par más frecuente
- Repita los pasos 2 y 3 hasta que sea posible fusionar
¡Veamos todo esto en acción a continuación!
Implementación de tokenización: codificación de pares de bytes en Python
Ahora somos conscientes de cómo funciona BPE: aprender y aplicar las palabras OOV. Entonces, es hora de implementar nuestro conocimiento en Python.
El código de Python para BPE ya está disponible en el documento original (Traducción automática neuronal de palabras raras con unidades de subpalabras, 2016)
Corpus de lectura
Consideraremos un corpus simple para ilustrar la idea de BPE. Sin embargo, la misma idea se aplica también a otro corpus:
Preparación de textos
Tokenice las palabras en caracteres en el corpus y agregue al final de cada palabra:
Aprendiendo BPE
Calcule la frecuencia de cada palabra en el corpus:
Producción:
![]()
Definamos una función para calcular la frecuencia de un par de caracteres o secuencias de caracteres. Acepta el corpus y devuelve el par con su frecuencia:
Ahora, la siguiente tarea es fusionar el par más frecuente del corpus. Definiremos una función que acepta el corpus, mejor par y devuelve el corpus modificado:
A continuación, es hora de aprender las operaciones de BPE. Como BPE es un procedimiento iterativo, realizaremos y comprenderemos los pasos para una iteración. Calculemos la frecuencia de los bigramas:
Producción:
Encuentra el par más frecuente:
Producción: (‘e’, ‘s’)
Finalmente, combine el mejor par y guárdelo en el vocabulario:
Producción:![]()
Seguiremos pasos similares para ciertas iteraciones:
Producción:![]()
¡La parte más interesante está por venir! Eso es aplicar BPE a palabras OOV.
Aplicar BPE a la palabra OOV
Ahora, veremos cómo segmentar la palabra OOV en subpalabras usando operaciones aprendidas. Considere la palabra OOV como «más baja»:
La aplicación de BPE a una palabra OOV también es un proceso iterativo. Implementaremos los pasos discutidos anteriormente en el artículo:
Producción:
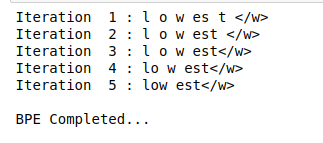
Como puede ver aquí, la palabra desconocida «más baja» está segmentada como más baja.
Notas finales
La tokenización es una forma poderosa de tratar con datos de texto. Vimos un vistazo de eso en este artículo y también implementamos la tokenización usando Python.
Continúe y pruebe esto en cualquier conjunto de datos basado en texto que tenga. Cuanto más practique, mejor será su comprensión de cómo funciona la tokenización (y por qué es un concepto de PNL tan crítico). No dude en comunicarse conmigo en los comentarios a continuación si tiene alguna pregunta o idea sobre este artículo.





