Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
Ha habido una serie de avances en el campo del aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y la visión por computadora. Especialmente con la introducción de redes neuronales convolucionales muy profundas, estos modelos ayudaron a lograr resultados de vanguardia en problemas como el reconocimiento de imágenes y la clasificación de imágenes.
Entonces, a lo largo de los años, las arquitecturas de aprendizaje profundo se hicieron cada vez más profundas (agregando más capas) para resolver tareas cada vez más complejas, lo que también ayudó a mejorar el rendimiento de las tareas de clasificación y reconocimiento y también a hacerlas robustas.
Pero cuando seguimos agregando más capas a la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas..., se vuelve mucho más difícil de entrenar y la precisión del modelo comienza a saturarse y luego también se degrada. Aquí viene la ResNet para rescatarnos de ese escenario y ayuda a resolver este problema.
¿Qué es ResNet?
Residual Network (ResNet) es uno de los famosos modelos de aprendizaje profundo que introdujeron Shaoqing Ren, Kaiming He, Jian Sun y Xiangyu Zhang en su artículo. El documento se denominó «Aprendizaje residual profundo para el reconocimiento de imágenes». [1] en 2015. El modelo ResNet es uno de los modelos de aprendizaje profundo más populares y exitosos hasta ahora.
Bloques residuales
El problema de entrenar redes muy profundas se ha aliviado con la introducción de estos bloques residuales y el modelo ResNet se compone de estos bloques.
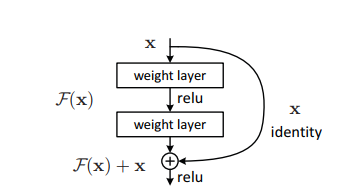
El problema de entrenar redes muy profundas se ha aliviado con la introducción de estos bloques residuales y el modelo ResNet se compone de estos bloques.
En la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior, lo primero que podemos notar es que hay una conexión directa que omite algunas capas del modelo. Esta conexión se llama «conexión de salto» y es el corazón de los bloques residuales. La salida no es la misma debido a esta conexión de salto. Sin la conexión de salto, la entrada ‘X se multiplica por los pesos de la capa seguida de agregar un término de sesgo.
Luego viene la función de activaciónLa función de activación es un componente clave en las redes neuronales, ya que determina la salida de una neurona en función de su entrada. Su propósito principal es introducir no linealidades en el modelo, permitiendo que aprenda patrones complejos en los datos. Existen diversas funciones de activación, como la sigmoide, ReLU y tanh, cada una con características particulares que afectan el rendimiento del modelo en diferentes aplicaciones...., f () y obtenemos la salida como H (x).
H (x) = f (wx + b) o H (x) = f (x)
Ahora, con la introducción de una nueva técnica de conexión de salto, la salida es H (x) se cambia a
H (x) = f (x) + x
Pero la dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... de la entrada puede variar de la de la salida, lo que podría suceder con una capa convolucionalLa capa convolucional, fundamental en las redes neuronales convolucionales (CNN), se utiliza principalmente para el procesamiento de datos con estructuras en forma de cuadrícula, como imágenes. Esta capa aplica filtros que extraen características relevantes, como bordes y texturas, permitiendo que el modelo reconozca patrones complejos. Su capacidad para reducir la dimensionalidad de los datos y mantener información esencial la convierte en una herramienta clave en tareas de visión por computadora... o capas agrupadas. Por lo tanto, este problema se puede manejar con estos dos enfoques:
· Zero está acolchado con la conexión de salto para aumentar sus dimensiones.
· Se agregan capas convolucionales 1 × 1 a la entrada para que coincidan con las dimensiones. En tal caso, la salida es:
H (x) = f (x) + w1.x
Aquí se agrega un parámetro adicional w1 mientras que no se agrega ningún parámetro adicional cuando se usa el primer enfoque.
Esta técnica de omisión de conexiones en ResNet resuelve el problema de la desaparición del gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... en las CNN profundas al permitir una ruta de acceso directo alternativa para que fluya el gradiente. Además, la conexión de omisión ayuda si alguna capa daña el rendimiento de la arquitectura, entonces se omitirá mediante la regularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones.....
Arquitectura de ResNet
Hay una red simple de 34 capas en la arquitectura que está inspirada en VGG-19 en la que se agregan la conexión de acceso directo o las conexiones de salto. Estas conexiones de salto o los bloques residuales luego convierten la arquitectura en la red residual como se muestra en la figura siguiente.
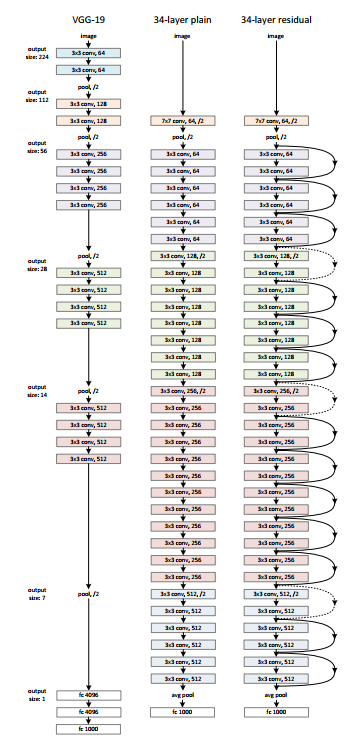
Fuente: ‘Aprendizaje residual profundo para el reconocimiento de imágenes‘ papel
Usando ResNet con Keras:
Keras es una biblioteca de aprendizaje profundo de código abierto capaz de ejecutarse sobre TensorFlow. Keras Applications proporciona las siguientes versiones de ResNet.
– ResNet50
– ResNet50V2
– ResNet101
– ResNet101V2
– ResNet152
– ResNet152V2
Construyamos ResNet desde cero:
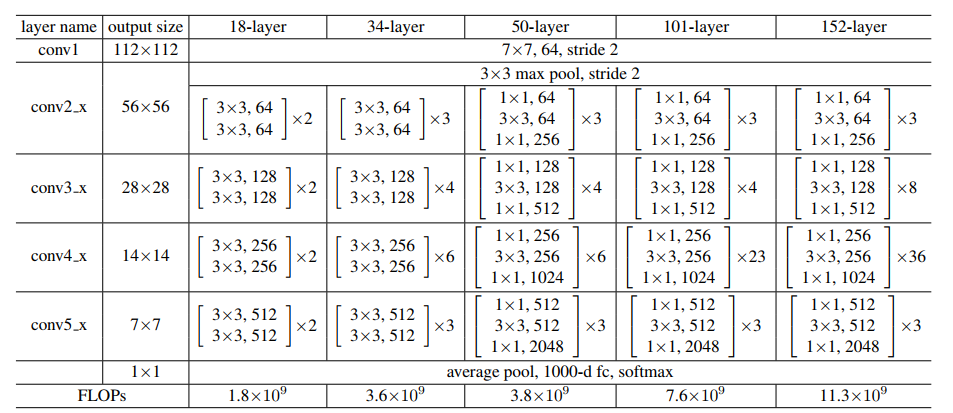
Fuente: ‘Aprendizaje residual profundo para el reconocimiento de imágenes‘ papel
Conservemos la imagen de arriba como referencia y comencemos a construir la red.
La arquitectura de ResNet usa los bloques CNN varias veces, así que creemos una clase para el bloque CNN, que toma canales de entrada y canales de salida. Hay un batchnorm2d después de cada capa de conv.
import torch import torch.nn as nn
class block(nn.Module):
def __init__(
self, in_channels, intermediate_channels, identity_downsample=None, stride=1
):
super(block, self).__init__()
self.expansion = 4
self.conv1 = nn.Conv2d(
in_channels, intermediate_channels, kernel_size=1, stride=1, padding=0, bias=False
)
self.bn1 = nn.BatchNorm2d(intermediate_channels)
self.conv2 = nn.Conv2d(
intermediate_channels,
intermediate_channels,
kernel_size=3,
stride=stride,
padding=1,
bias=False
)
self.bn2 = nn.BatchNorm2d(intermediate_channels)
self.conv3 = nn.Conv2d(
intermediate_channels,
intermediate_channels * self.expansion,
kernel_size=1,
stride=1,
padding=0,
bias=False
)
self.bn3 = nn.BatchNorm2d(intermediate_channels * self.expansion)
self.relu = nn.ReLU()
self.identity_downsample = identity_downsample
self.stride = stride
def forward(self, x):
identity = x.clone()
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
if self.identity_downsample is not None:
identity = self.identity_downsample(identity)
x += identity
x = self.relu(x)
return x
Luego, cree una clase ResNet que tome la entrada de varios bloques, capas, canales de imagen y la cantidad de clases.
En el siguiente código, la función ‘_make_layer’
crea las capas ResNet, que toma la entrada de bloques, el número de residuales
bloques, canal de salida y zancadas.
class ResNet(nn.Module):
def __init__(self, block, layers, image_channels, num_classes):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(image_channels, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Essentially the entire ResNet architecture are in these 4 lines below self.layer1 = self._make_layer( block, layers[0], intermediate_channels=64, stride=1 ) self.layer2 = self._make_layer( block, layers[1], intermediate_channels=128, stride=2 ) self.layer3 = self._make_layer( block, layers[2], intermediate_channels=256, stride=2 ) self.layer4 = self._make_layer( block, layers[3], intermediate_channels=512, stride=2 ) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(512 * 4, num_classes) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.reshape(x.shape[0], -1) x = self.fc(x) return x def _make_layer(self, block, num_residual_blocks, intermediate_channels, stride): identity_downsample = None layers = [] # Either if we half the input space for ex, 56x56 -> 28x28 (stride=2), or channels changes # we need to adapt the Identity (skip connection) so it will be able to be added # to the layer that's ahead if stride != 1 or self.in_channels != intermediate_channels * 4: identity_downsample = nn.Sequential( nn.Conv2d( self.in_channels, intermediate_channels * 4, kernel_size=1, stride=stride, bias=False ), nn.BatchNorm2d(intermediate_channels * 4), ) layers.append( block(self.in_channels, intermediate_channels, identity_downsample, stride) ) # The expansion size is always 4 for ResNet 50,101,152 self.in_channels = intermediate_channels * 4 # For example for first resnet layer: 256 will be mapped to 64 as intermediate layer, # then finally back to 256. Hence no identity downsample is needed, since stride = 1, # and also same amount of channels. for i in range(num_residual_blocks - 1): layers.append(block(self.in_channels, intermediate_channels))
return nn.Sequential (* capas)
Luego defina diferentes versiones de ResNet
– Para ResNet50, la secuencia de capas es [3, 4, 6, 3].
– Para ResNet101, la secuencia de capas es [3, 4, 23, 3].
– Para ResNet152, la secuencia de capas es [3, 8, 36, 3]. (consulte el ‘Aprendizaje residual profundo para el reconocimiento de imágenes‘ papel)
def ResNet50(img_channel=3, num_classes=1000):
return ResNet(block, [3, 4, 6, 3], img_channel, num_classes)
def ResNet101(img_channel=3, num_classes=1000): return ResNet(block, [3, 4, 23, 3], img_channel, num_classes) def ResNet152(img_channel=3, num_classes=1000): return ResNet(block, [3, 8, 36, 3], img_channel, num_classes)
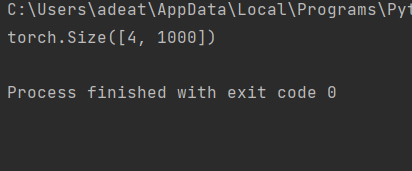
Luego, escriba un pequeño código de prueba para verificar si el modelo está funcionando bien.
def test():
net = ResNet101(img_channel=3, num_classes=1000)
device = "cuda" if torch.cuda.is_available() else "cpu"
y = net(torch.randn(4, 3, 224, 224)).to(device)
print(y.size())
test()
Para el caso de prueba anterior, la salida debe ser:
Se puede acceder al código completo aquí:
https://github.com/BakingBrains/Deep_Learning_models_implementation_from-scratch_using_pytorch_/blob/main/ResNet_.py
[1]. Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun: Aprendizaje profundo residual para el reconocimiento de imágenes, diciembre de 2015, DOI: https://arxiv.org/abs/1512.03385
Gracias.
Tus sugerencias y dudas son bienvenidas aquí en la sección de comentarios. ¡Gracias por leer mi artículo!





