Todo va a estar conectado a la nube y los datos … Todo esto estará mediado por el software – Satya Nadella
Introducción:
zing los resultados del modelo, o tratando de ajustar el modelo, los elementos visuales facilitan la interpretación del resultado.
Convencionalmente, las imágenes se generan a partir de un complemento o una biblioteca y se representan en las aplicaciones web que nos permiten al usuario final interactuar e interpretar los resultados. Estas imágenes pueden ser estáticas o parcialmente interactivas en silos.
Entonces, ¿hay alguna manera de reunir lo mejor de la visualización de datos y las tecnologías web en un solo lugar? Sí, es posible y estas aplicaciones se denominan Aplicaciones de datos.

fuente: shiny.rstudio.com
Las aplicaciones de datos facilitan que los expertos en la materia, los responsables de la toma de decisiones empresariales o los consumidores interactúen con los datos, grandes y pequeños.
Se diferencian de los informes de BI estáticos en que ofrecen interacción ad hoc a través de una interfaz intuitiva adaptada al caso de uso específico. También se diferencian de la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico.... automatizada impulsada por el aprendizaje automático, ya que están diseñadas para el «humano en el ciclo» en contraposición a la toma de decisiones automatizada.
Esto los hace perfectos para análisis que requieren una combinación de datos e intuición. Estas aplicaciones facilitan la investigación y la exploración de datos. La investigación de datos ocurre como reacción a un evento o anomalía específicos.
El usuario combina los datos del evento con otras fuentes de datos y datos históricos para identificar la causa raíz y tomar medidas. Esto conduce a cientos o miles de pequeños conocimientos que marcan una gran diferencia en conjunto.
Hay varias bibliotecas tanto en R (Shiny) como en Python (Plotly Dash, Streamlit, Wave, etc.) para crear aplicaciones de datos.
En este artículo, exploraremos cómo se puede usar R shiny para construir una aplicación que le permita al usuario dividir el conjunto de datos en entrenar / probar, construir múltiples modelos, generar métricas de modelos, visualizar el resultado y tomar la decisión sobre la marcha.
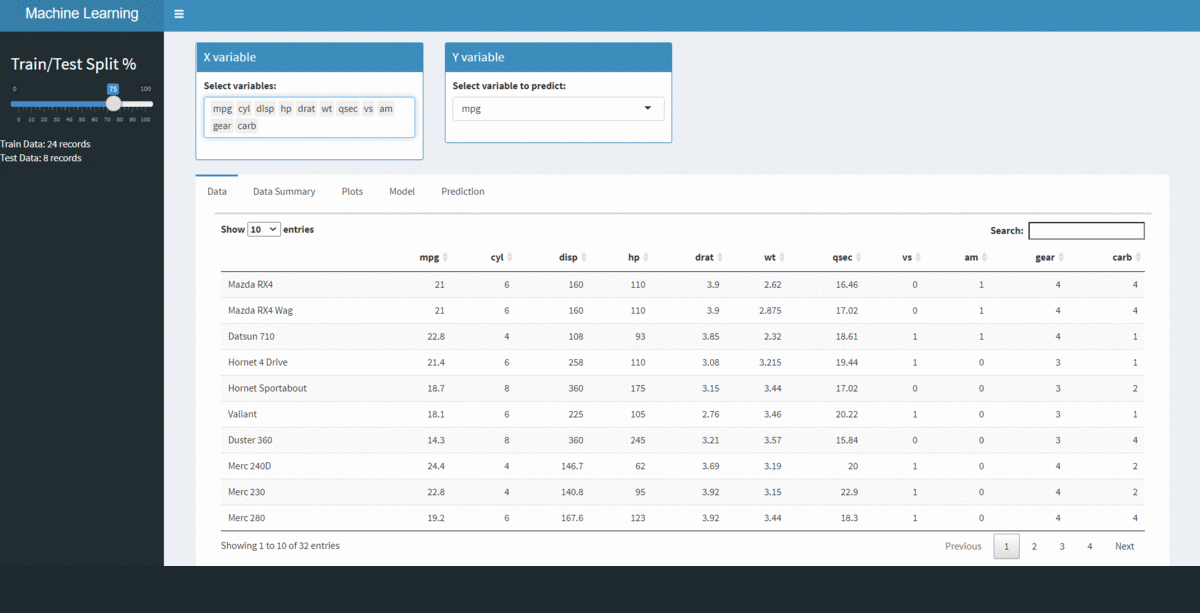
Al final de este artículo, crearemos la siguiente aplicación. Tenga en cuenta las distintas pestañas de la página de inicio.
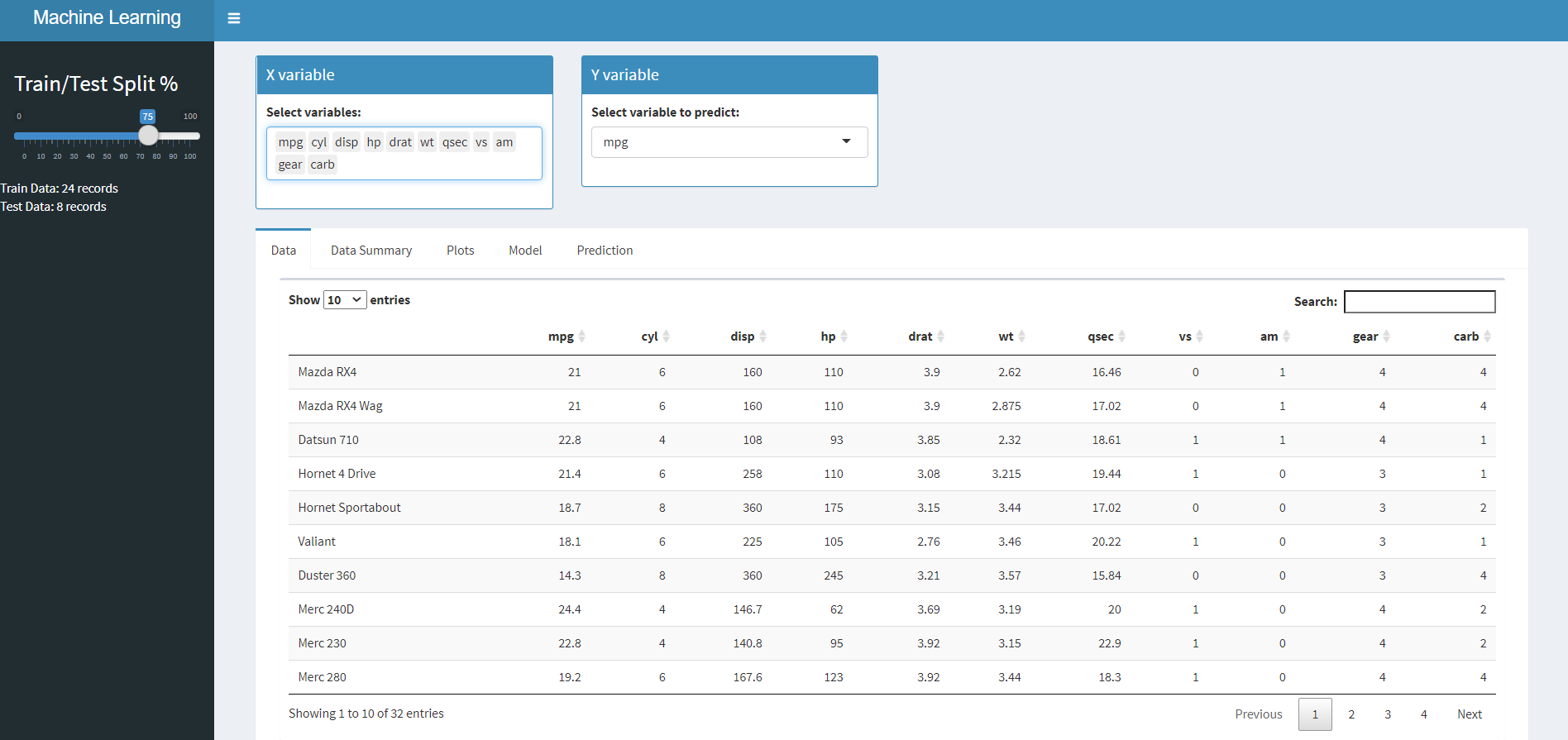
Empezando:
Nosotros usaremos mtcars conjunto de datos para esta aplicación. Una vez que probamos y nos aseguramos de que la interfaz de usuario y las funcionalidades del servidor funcionan como se esperaba, podemos cambiar el conjunto de datos y la aplicación debería funcionar igual de bien con un procesamiento de datos mínimo si es necesario.
Primero, instalemos el shiny y cargámoslo. La aplicación Shiny tiene principalmente dos archivos, uno de interfaz de usuario y uno de servidor:
install.packages("shiny")
library("shiny")
Interfaz de usuario (UI):
Aquí es donde define su diseño: marcadoresLos "marcadores" son herramientas lingüísticas que se utilizan para guiar la estructura y el flujo de un texto. Su función principal es señalar relaciones entre ideas, como la adición, contraste o causa y efecto. Ejemplos comunes incluyen "además", "sin embargo" y "por lo tanto". Estos elementos no solo mejoran la cohesión del escrito, sino que también facilitan la comprensión por parte del lector, haciendo el contenido más accesible y claro.... de posición que se completarán en el tiempo de ejecución a partir de los datos / gráficos procesados del servidor.
Servidor:
Aquí es donde escribe la mayor parte de la lógica, la discusión de datos, el trazado, etc. La mayor parte del trabajo pesado se realiza aquí.
Agreguemos los dos campos desplegables, uno para las variables independientes y el otro para seleccionar el objetivo.
dashboardBody(
fluidPage(
box(
selectInput(
"SelectX",
label = "Select variables:",
choices = names(mtcars),
multiple = TRUE,
selected = names(mtcars)
),
solidHeader = TRUE,
width = "3",
status = "primary",
title = "X variable"
),
box(
selectInput("SelectY", label = "Select variable to predict:", choices = names(mtcars)),
solidHeader = TRUE,
width = "3",
status = "primary",
title = "Y variable"
)
A continuación, agregaremos un control deslizante en el panelUn panel es un grupo de expertos que se reúne para discutir y analizar un tema específico. Estos foros son comunes en conferencias, seminarios y debates públicos, donde los participantes comparten sus conocimientos y perspectivas. Los paneles pueden abordar diversas áreas, desde la ciencia hasta la política, y su objetivo es fomentar el intercambio de ideas y la reflexión crítica entre los asistentes.... lateral para dividir el conjunto de datos para entrenar y probar según la selección del usuario.
dashboardSidebar(
sliderInput(
"Slider1",
label = h3("Train/Test Split %"),
min = 0,
max = 100,
value = 75
),
textOutput("cntTrain"),
textOutput("cntTest"),
Ahora, crearemos varias pestañas, cada una de las cuales tiene una funcionalidad específica como se detalla a continuación:
Datos – Para ver los datos brutos en forma tabular,
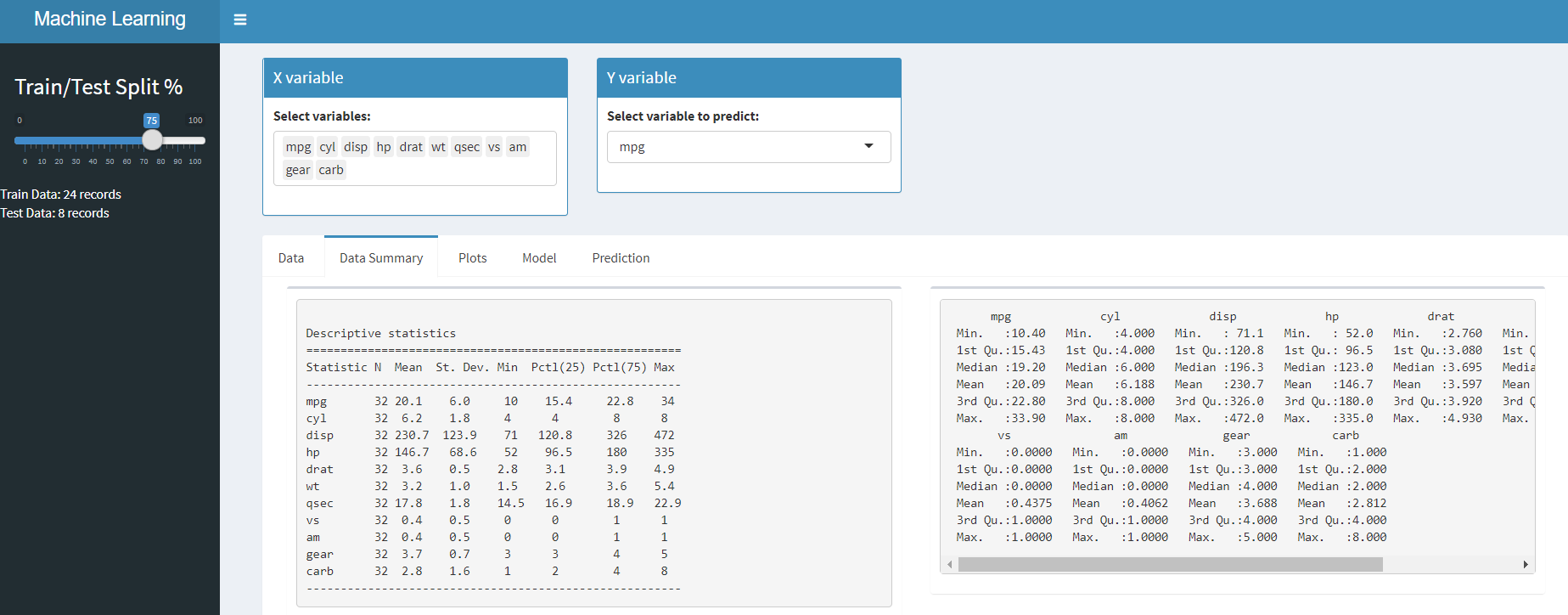
Resumen de datos – Ver las estadísticas básicas de nuestro conjunto de datos.
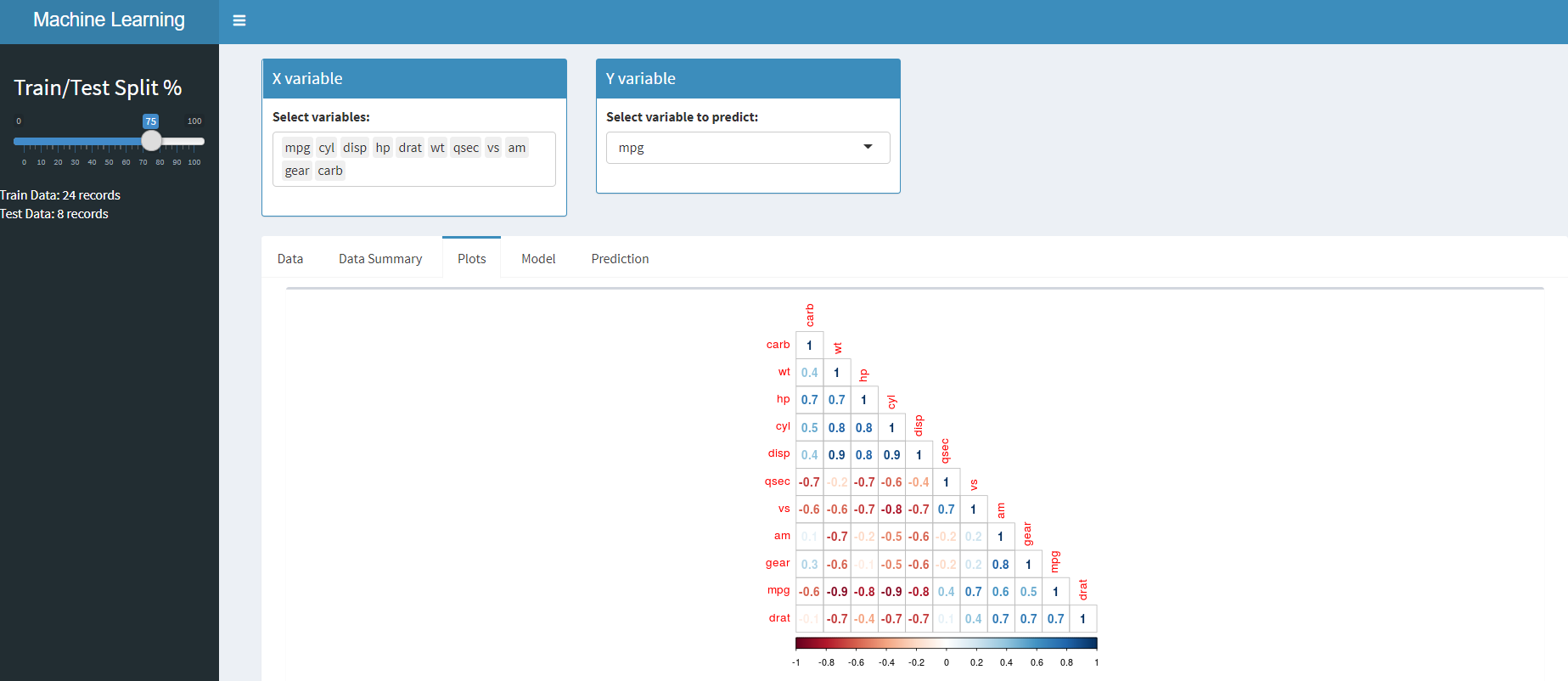
Parcelas – En este caso, crearemos solo un gráfico de correlación, pero se pueden agregar gráficos más relevantes si es necesario.
Modelo – Construya un modelo de regresión lineal basado en la selección del usuario de variables X, Y y divisiones de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... / prueba
Predicción – Predecir en el conjunto de prueba.
fluidPage(
tabBox(
id = "tabset1",
height = "1000px",
width = 12,
tabPanel("Data",
box(withSpinner(DTOutput(
"Data"
)), width = 12)),
tabPanel(
"Data Summary",
box(withSpinner(verbatimTextOutput("Summ")), width = 6),
box(withSpinner(verbatimTextOutput("Summ_old")), width = 6)
),
tabPanel("Plots",
box(withSpinner(plotOutput(
"Corr"
)), width = 12)),
#box(withSpinner(verbatimTextOutput("CorrMatrix")), width = 12),
tabPanel(
"Model",
box(
withSpinner(verbatimTextOutput("Model")),
width = 6,
title = "Model Summary"
),
box(
withSpinner(verbatimTextOutput("ImpVar")),
width = 5,
title = "Variable Importance"
)
),
#textOutput("correlation_accuracy"),
tabPanel(
"Prediction",
box(withSpinner(plotOutput("Prediction")), width = 6, title = "Best Fit Line"),
box(withSpinner(plotOutput("residualPlots")), width = 6, title = "Diagnostic Plots")
)
)
Ahora que hemos creado nuestra interfaz de usuario, procederemos a implementar la lógica del servidor para completar la interfaz de usuario en función de la selección del usuario: interactividad.
Llenando la pestaña de datos: Usamos el marco de datos mtcars y lo guardamos en un objeto por su nombre InputDataset y luego llene la interfaz de usuario usando renderDT () función.
Tenga en cuenta el uso de tirantes al final del objeto InputDataset (). Esto se hace porque es un objeto reactivo, lo que significa que cualquier cambio en este objeto tendrá un impacto en otros lugares donde se hace referencia a él en la aplicación.
InputDataset <- reactive({
mtcars
})
output$Data <- renderDT(InputDataset())
En líneas similares, puede usar resumen() y correlación función para completar el resumen de datos y la correlación trama pestaña. Puede acceder al código del lado del servidor desde GitHub
Ahora que hemos visto cómo se completan los datos, construyamos un modelo de regresión lineal y también veamos la importancia de las variables.
f <- reactive({
as.formula(paste(input$SelectY, "~."))
})
Linear_Model <- reactive({
lm(f(), data = trainingData())
})
output$Model <- renderPrint(summary(Linear_Model()))
output$Model_new <-
renderPrint(
stargazer(
Linear_Model(),
type = "text",
title = "Model Results",
digits = 1,
out = "table1.txt"
)
)
tmpImp <- reactive({
#varImp(Linear_Model())
imp <- as.data.frame(varImp(Linear_Model()))
imp <- data.frame(overall = imp$Overall,
names = rownames(imp))
imp[order(imp$overall, decreasing = T),]
})
output$ImpVar <- renderPrint(tmpImp())
Implementemos la lógica para el predicción pestaña donde usaremos nuestro modelo de la sección anterior para predecir el conjunto de datos de prueba y también generar gráficos residuales.
actuals_preds <-
reactive({
data.frame(cbind(actuals = tmp(), predicted = price_predict()))
})
Fit <-
reactive({
(
plot(
actuals_preds()$actuals,
actuals_preds()$predicted,
pch = 16,
cex = 1.3,
col = "blue",
main = "Best Fit Line",
xlab = "Actual",
ylab = "Predicted"
)
)
})
output$Prediction <- renderPlot(Fit())
output$residualPlots <- renderPlot({
par(mfrow = c(2, 2)) # Change the panel layout to 2 x 2
plot(Linear_Model())
par(mfrow = c(1, 1)) # Change back to 1 x 1
})
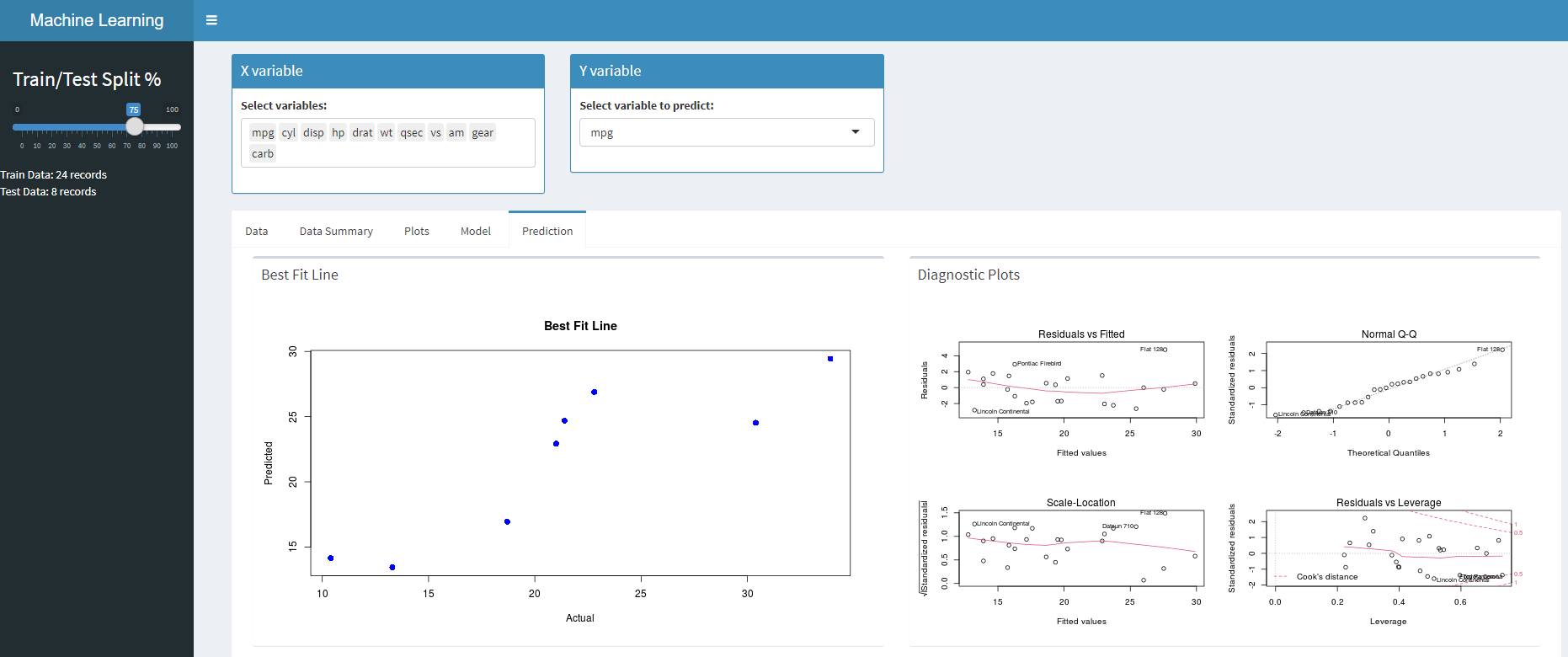
Puede acceder al código completo desde GitHub. Una vez que ejecute su aplicación, verá la página de inicio cargada. Puede navegar a varias secciones, realizar cambios en las variables, crear modelos y también predecir en la prueba sobre la marcha siguiendo los pasos a continuación.

Paso 1:
Seleccione la división de datos de tren / prueba preferida en el panel izquierdo.
Paso 2:
Seleccione las variables X e Y de los menús desplegables.
Paso 3:
Navegue a las pestañas respectivas para ver el resultado:
Conclusión:
El objetivo del blog era construir una aplicación de datos usando R Shiny. Esta fue una implementación muy básica con todos los controles integrados.
Solo para hacerlo un poco más interesante, elegí traer un aspecto de construcción de modelos a la aplicación para mostrar cómo se pueden construir aplicaciones basadas en modelos en poco tiempo.
Junto con los elementos Shiny, puede usar elementos HTML para estilizar su contenido en su aplicación.
¡¡¡Felices aprendizajes !!!!
Puedes conectarte conmigo – Linkedin
Puede encontrar el código como referencia: Github
Referencias
https://shiny.rstudio.com/tutorial/
https://unsplash.com/
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





