Este artículo fue publicado como parte del Blogatón de ciencia de datos
Intro
Nosotros, los humanos, leemos textos casi cada minuto de nuestra vida. ¿No sería genial si nuestras máquinas o sistemas también pudieran leer el texto como lo hacemos nosotros? Pero la pregunta más importante es «¿Cómo hacemos que nuestras máquinas lean»? Aquí es donde entra en escena el reconocimiento óptico de caracteres (OCR).
Reconocimiento óptico de caracteres (OCR)
El reconocimiento óptico de caracteres (OCR) es una técnica de lectura o captura de texto de fotografías impresas o escaneadas, imágenes escritas a mano y convertirlas en un formato digital que se puede editar y buscar.
Aplicaciones
OCR tiene muchas aplicaciones en los negocios actuales. Algunos de ellos se enumeran a continuación:
- Reconocimiento de pasaportes en aeropuertos
- Automatización de la entrada de datos
- Reconocimiento de matrículas
- Extraer información de la tarjeta de presentación en una lista de contactos
- Conversión de documentos escritos a mano en imágenes electrónicas
- Creación de archivos PDF con capacidad de búsqueda
- Crea archivos audibles (texto a audio)
Algunas de las herramientas de OCR de código abierto son Tesseract, OCRopus.
En este artículo, nos centraremos en Tesseract OCR. Y para leer las imágenes necesitamos OpenCV.
Instalación de Tesseract OCR:
Descargue el instalador más reciente para Windows 10 desde «https://github.com/UB-Mannheim/tesseract/wiki“. Ejecute el archivo .exe una vez que se descargue.
Nota: No olvide copiar la ruta de instalación del software de archivo. Lo necesitaremos más adelante ya que necesitamos agregar la ruta del ejecutable tesseract en el código si el directorio de instalación es diferente al predeterminado.
La ruta de instalación típica en los sistemas Windows es C: Archivos de programa.
Entonces, en mi caso, es «C: Archivos de programa Tesseract-OCRtesseract.exe“.
A continuación, para instalar el contenedor de Python para Tesseract, abra el símbolo del sistema y ejecute el comando «pip instalar pytesseract“.
OpenCV
OpenCV (Open Source Computer Vision) es una biblioteca de código abierto para aplicaciones de procesamiento de imágenes, aprendizaje automático y visión por computadora.
OpenCV-Python es la API de Python para OpenCV.
Para instalarlo, abra el símbolo del sistema y ejecute el comando «pip instalar opencv-python“.
Crear script de OCR de muestra
1. Leer una imagen de muestra
import cv2
Lea la imagen usando el método cv2.imread () y guárdela en una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... “img”.
img = cv2.imread("image.jpg")
Si es necesario, cambie el tamaño de la imagen usando el método cv2.resize ()
img = cv2.resize(img, (400, 400))
Mostrar la imagen usando el método cv2.imshow ()
cv2.imshow("Image", img)
Muestre la ventana infinitamente (para evitar que el kernel se bloquee)
cv2.waitKey(0)
Cerrar todas las ventanas abiertas
cv2.destroyAllWindows()
2. Conversión de imagen en cadena
import pytesseract
Establecer la ruta de tesseract en el código
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
El siguiente error ocurre si no establecemos la ruta.

Para convertir una imagen en una cadena, use pytesseract.image_to_string (img) y guárdelo en una variable «texto»
text = pytesseract.image_to_string(img)
imprimir el resultado
print(text)
Código completo:
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
img = cv2.imread("image.jpg")
img = cv2.resize(img, (400, 450))
cv2.imshow("Image", img)
text = pytesseract.image_to_string(img)
print(text)
cv2.waitKey(0)
cv2.destroyAllWindows()
La salida del código anterior:
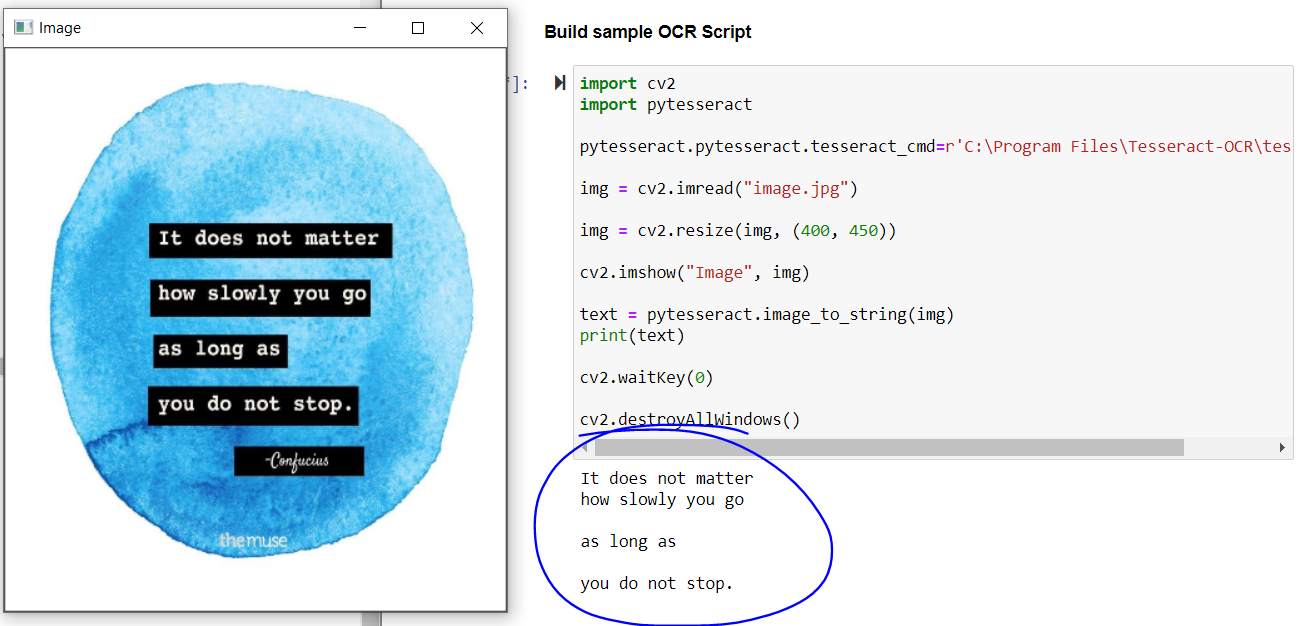
La salida del código anterior
Si observamos el resultado, la cita principal se extrae perfectamente, pero no se obtiene el nombre del filósofo y el texto en la parte inferior de la imagen.
Para extraer el texto con precisión y evitar la caída de la precisión, debemos realizar un procesamiento previo de la imagen. Encontré este artículo (https://towardsdatascience.com/pre-processing-in-ocr-fc231c6035a7) bastante útil. Consúltelo para comprender mejor las técnicas de preprocesamiento.
¡Perfecto! Ahora que tenemos los conceptos básicos requeridos, veamos algunas aplicaciones simples de OCR.
1. Creación de nubes de palabras en imágenes de revisión
La nube de palabras es una representación visual de la frecuencia de las palabras. Cuanto más grande aparece la palabra en una nube de palabras, más comúnmente se usa la palabra en el texto.
Para esto, tomé algunas instantáneas de reseñas de Amazon para el producto Apple iPad 8th Generation.
Imagen de muestra
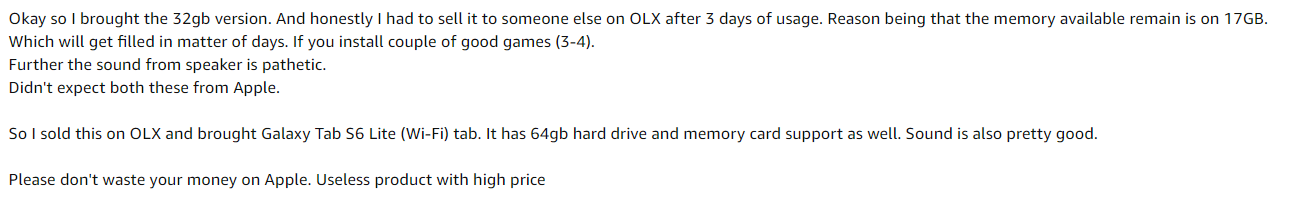
Pasos:
- Cree una lista de todas las imágenes de revisión disponibles
- Si es necesario, vea las imágenes usando el método cv2.imshow ()
- Leer texto de imágenes usando pytesseract
- Crea un marco de datos
- Procesar previamente el texto: eliminar caracteres especiales, detener palabras
- Construya nubes de palabras positivas y negativas
Paso 1: crea una lista de todas las imágenes de revisión disponibles
import os folderPath = "Reviews" myRevList = os.listdir(folderPath)
Paso 2: Si es necesario, vea las imágenes usando el método cv2.imshow ()
for image in myRevList:
img = cv2.imread(f'{folderPath}/{image}')
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Paso 3: lee el texto de las imágenes usando pytesseract
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
corpus = []
for images in myRevList:
img = cv2.imread(f'{folderPath}/{images}')
if img is None:
corpus.append("Could not read the image.")
else:
rev = pytesseract.image_to_string(img)
corpus.append(rev)
list(corpus)
corpus
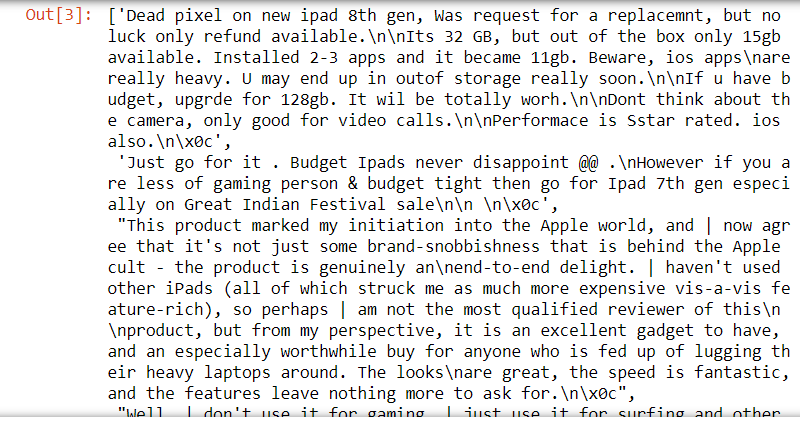
Paso 4: crea un marco de datos
import pandas as pd data = pd.DataFrame(list(corpus), columns=['Review']) data

Paso 5: preprocesar el texto: eliminar caracteres especiales, palabras vacías
#removing special characters
import re
def clean(text):
return re.sub('[^A-Za-z0-9" "]+', ' ', text)
data['Cleaned Review'] = data['Review'].apply(clean)
data

Eliminando palabras vacías de la ‘Revisión limpia’ y agregando todas las palabras restantes a una variable de lista «final_list».
-
# removing stopwords import nltk from nltk.corpus import stopwords nltk.download("punkt") from nltk import word_tokenize stop_words = stopwords.words('english') final_list = [] for column in data[['Cleaned Review']]: columnSeriesObj = data[column] all_rev = columnSeriesObj.values for i in range(len(all_rev)): tokens = word_tokenize(all_rev[i]) for word in tokens: if word.lower() not in stop_words: final_list.append(word)
Paso 6: Construya nubes de palabras positivas y negativas
Instale la biblioteca de nube de palabras con el comando «pip instalar wordcloud“.
En el idioma inglés, tenemos un conjunto predefinido de palabras positivas y negativas llamadas Opinion Lexicons. Estos archivos se pueden descargar desde Enlace o directamente de mi Repositorio de GitHub.
Una vez que se descargan los archivos, lea esos archivos en el código y cree una lista de palabras positivas y negativas.
with open(r"opinion-lexicon-Englishpositive-words.txt","r") as pos:
poswords = pos.read().split("n")
with open(r"opinion-lexicon-Englishnegative-words.txt","r") as neg:
negwords = neg.read().split("n")
Importación de bibliotecas para generar y mostrar nubes de palabras.
import matplotlib.pyplot as plt from wordcloud import WordCloud
Nube de palabras positivas
# Choosing the only words which are present in poswords
pos_in_pos = " ".join([w for w in final_list if w in poswords])
wordcloud_pos = WordCloud(
background_color="black",
width=1800,
height=1400
).generate(pos_in_pos)
plt.imshow(wordcloud_pos)

La palabra “bueno” es la palabra más utilizada que nos llama la atención. Si miramos hacia atrás en las revisiones, la gente ha escrito críticas diciendo que el iPad tiene una buena pantalla, buen sonido, buen software y hardware.
Nube de palabras negativas
# Choosing the only words which are present in negwords
neg_in_neg = " ".join([w for w in final_list if w in negwords])
wordcloud_neg = WordCloud(
background_color="black",
width=1800,
height=1400
).generate(neg_in_neg)
plt.imshow(wordcloud_neg)

Las palabras caro, atascado, golpeado, decepción se destacaron en la nube de palabras negativas. Si miramos el contexto de la palabra atascado, dice «Aunque tiene solo 3 GB de RAM, nunca se atasca», lo cual es algo positivo sobre el dispositivo.
Por lo tanto, es bueno crear nubes de palabras de bigrama / trigrama para no perderse el contexto.
2. Cree archivos audibles (texto a audio)
gTTS es una biblioteca de Python con la API de conversión de texto a voz de Google Translate.
Para instalar, ejecute el comando «pip install gtts”En el símbolo del sistema.
Importar bibliotecas necesarias
import cv2 import pytesseract from gtts import gTTS import os
Establecer la ruta de tesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe'
Lea la imagen usando cv2.imread () y tome el texto de la imagen usando pytesseract y guárdelo en una variable.
rev = cv2.imread("Reviews15.PNG")
# display the image using cv2.imshow() method
# cv2.imshow("Image", rev)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# grab the text from image using pytesseract
txt = pytesseract.image_to_string(rev)
print(txt)
Configure el idioma y cree una conversión del texto a audio usando gTTS sin pasar por el texto, el idioma
language="en" outObj = gTTS(text=txt, lang=language, slow=False)
Guarde el archivo de audio como «rev.mp3»
outObj.save("rev.mp3")
reproducir el archivo de audio
os.system('rev.mp3')
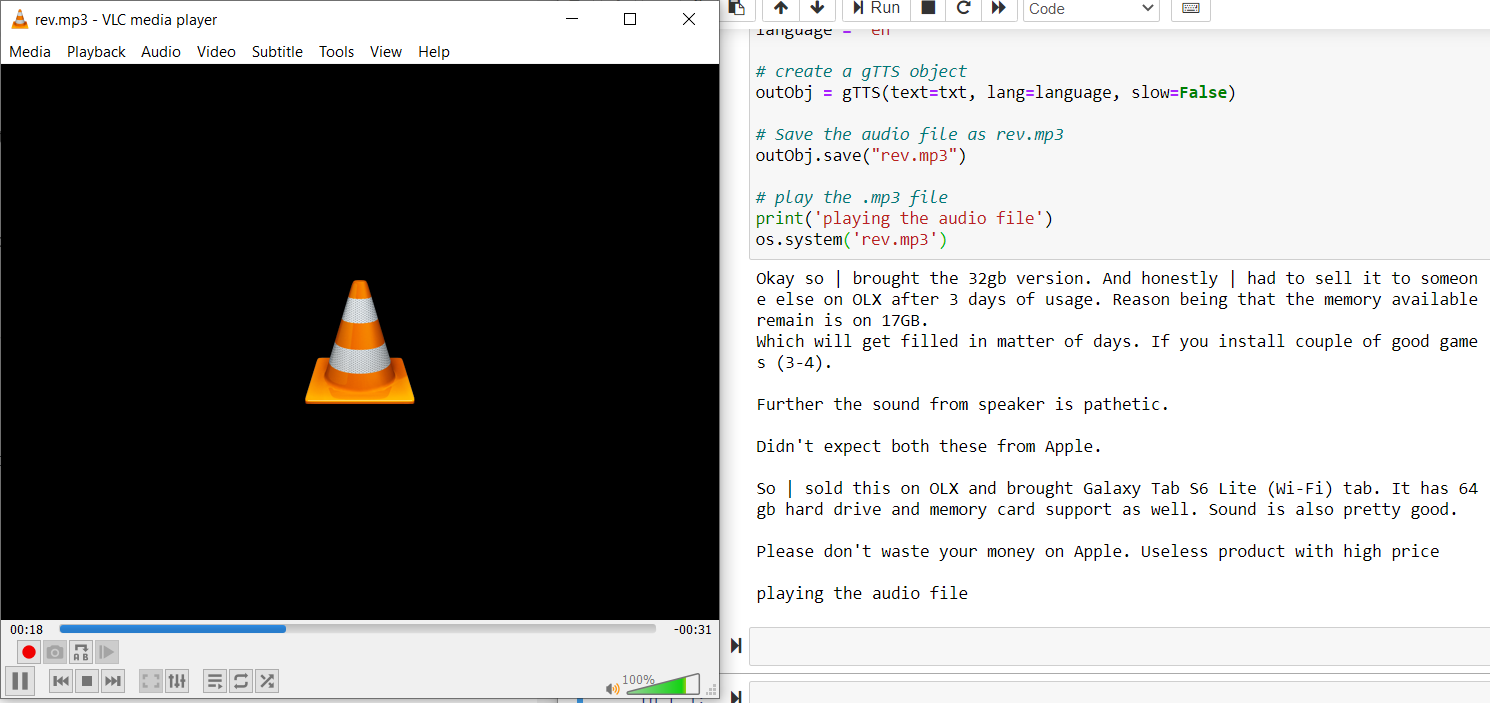
Código completo:
-
import cv2 import pytesseract from gtts import gTTS import os rev = cv2.imread("Reviews15.PNG") # cv2.imshow("Image", rev) # cv2.waitKey(0) # cv2.destroyAllWindows() txt = pytesseract.image_to_string(rev) print(txt) language="en" outObj = gTTS(text=txt, lang=language, slow=False) outObj.save("rev.mp3") print('playing the audio file') os.system('rev.mp3')
Notas finales
Al final de este artículo, hemos entendido el concepto de reconocimiento óptico de caracteres (OCR) y estamos familiarizados con la lectura de imágenes con OpenCV y con la captura de texto de las imágenes con pytesseract. Hemos visto dos aplicaciones básicas de OCR: construir nubes de palabras, crear archivos audibles mediante la conversión de texto a voz usando gTTS.
Referencias:
Espero que este artículo sea informativo y, por favor, avíseme si tiene alguna consulta o comentario relacionado con este artículo en la sección de comentarios. Aprendizaje feliz 😊
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





