Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
¡Hola lectores!
El aprendizaje profundo se utiliza en muchas aplicaciones, como la detección de objetos, la detección de rostros, las tareas de procesamiento del lenguaje natural y muchas más. En este blog voy a construir un modelo que se utilizará para resolver Sudoku sin resolver a partir de una imagen usando deep learning, vamos a bibliotecas como OpenCV y TensorFlow. Si quieres saber más sobre OpenCV, consulta esto Enlace. Entonces empecemos.
- Si desea conocer las bibliotecas de Python para el procesamiento de imágenes, entonces mira esto Enlace.
- Para más artículos, haga clic aquí.

Imagen Fuente
El blog se divide en tres partes:
Parte 1: Modelo de clasificación de dígitos
Primero construiremos y entrenaremos una red neuronal en el conjunto de datos de imágenes Char74k para dígitos. Este modelo ayudará a clasificar los dígitos de las imágenes.
Parte 2: Leer y detectar el Sudoku a partir de una imagen
Esta sección contiene, identificando el rompecabezas a partir de una imagen con la ayuda de OpenCV, clasificar los dígitos en el rompecabezas Sudoku detectado usando la Parte 1, finalmente obtener los valores de las celdas del Sudoku y almacenarlos en una matriz.
Parte 3: Resolviendo el rompecabezas
Vamos a almacenar la matriz que obtuvimos en Pat-2 en forma de matriz y finalmente ejecutaremos un ciclo de recursividad para resolver el rompecabezas.
BIBLIOTECAS IMPORTADORAS
Vamos a importar todas las bibliotecas requeridas usando los siguientes comandos:
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import os, random import cv2 from glob import glob import sklearn from sklearn.model_selection import train_test_split import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.image import ImageDataGenerator from keras.preprocessing.image import ImageDataGenerator, load_img from keras.utils.np_utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Activation, Dropout, Dense, Flatten, BatchNormalization, Conv2D, MaxPooling2D from tensorflow.keras.optimizers import RMSprop from tensorflow.keras import backend as K from tensorflow.keras.preprocessing import image from sklearn.metrics import accuracy_score, classification_report from pathlib import Path from PIL import Image
Parte 1: Modelo de clasificación de dígitos
En esta sección, usaremos un modelo de clasificación de dígitos.
CARGANDO DATOS
Usaremos un conjunto de datos de imágenes para clasificar los números en una imagen. Los datos se especifican como características como imágenes y etiquetas como etiquetas.
#Loading the data
data = os.listdir("digits/Digits" )
data_X = []
data_y = []
data_classes = len(data)
for i in range (0,data_classes):
data_list = os.listdir("digits/Digits" +"/"+str(i))
for j in data_list:
pic = cv2.imread("digits/Digits" +"/"+str(i)+"/"+j)
pic = cv2.resize(pic,(32,32))
data_X.append(pic)
data_y.append(i)
if len(data_X) == len(data_y) :
print("Total Dataponits = ",len(data_X))
# Labels and images
data_X = np.array(data_X)
data_y = np.array(data_y)

CONJUNTO DE DATOS DIVIDIDO
Estamos dividiendo el conjunto de datos en conjuntos de tren, prueba y validación como lo hacemos en cualquier problema de aprendizaje automático.
#Spliting the train validation and test sets
train_X, test_X, train_y, test_y = train_test_split(data_X,data_y,test_size=0.05)
train_X, valid_X, train_y, valid_y = train_test_split(train_X,train_y,test_size=0.2)
print("Training Set Shape = ",train_X.shape)
print("Validation Set Shape = ",valid_X.shape)
print("Test Set Shape = ",test_X.shape)

Procesamiento previo de las imágenes para la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas...
En un paso de preprocesamiento, preprocesamos las características (imágenes) en escala de grises, normalizándolas y realzándolas con ecualización de histograma. Después de eso, conviértalos en matrices NumPp y luego modifíquelos y aumente los datos.
def Prep(img):
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #making image grayscale
img = cv2.equalizeHist(img) #Histogram equalization to enhance contrast
img = img/255 #normalizing
return img
train_X = np.array(list(map(Prep, train_X)))
test_X = np.array(list(map(Prep, test_X)))
valid_X= np.array(list(map(Prep, valid_X)))
#Reshaping the images
train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], train_X.shape[2],1)
test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], test_X.shape[2],1)
valid_X = valid_X.reshape(valid_X.shape[0], valid_X.shape[1], valid_X.shape[2],1)
#Augmentation
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, zoom_range=0.2, shear_range=0.1, rotation_range=10)
datagen.fit(train_X)
Una codificación en caliente
En esta sección, usaremos la codificación one-hot para etiquetar las clases.
train_y = to_categorical(train_y, data_classes) test_y = to_categorical(test_y, data_classes) valid_y = to_categorical(valid_y, data_classes)
CONSTRUCCIÓN DEL MODELO
Estamos utilizando una red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... para la construcción de modelos. Consta de los siguientes pasos:
#Creating a Neural Network model = Sequential() model.add((Conv2D(60,(5,5),input_shape=(32, 32, 1) ,padding = 'Same' ,activation='relu'))) model.add((Conv2D(60, (5,5),padding="same",activation='relu'))) model.add(MaxPooling2D(pool_size=(2,2))) #model.add(Dropout(0.25)) model.add((Conv2D(30, (3,3),padding="same", activation='relu'))) model.add((Conv2D(30, (3,3), padding="same", activation='relu'))) model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2))) model.add(Dropout(0.5)) model.add(Flatten()) model.add(Dense(500,activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.summary()
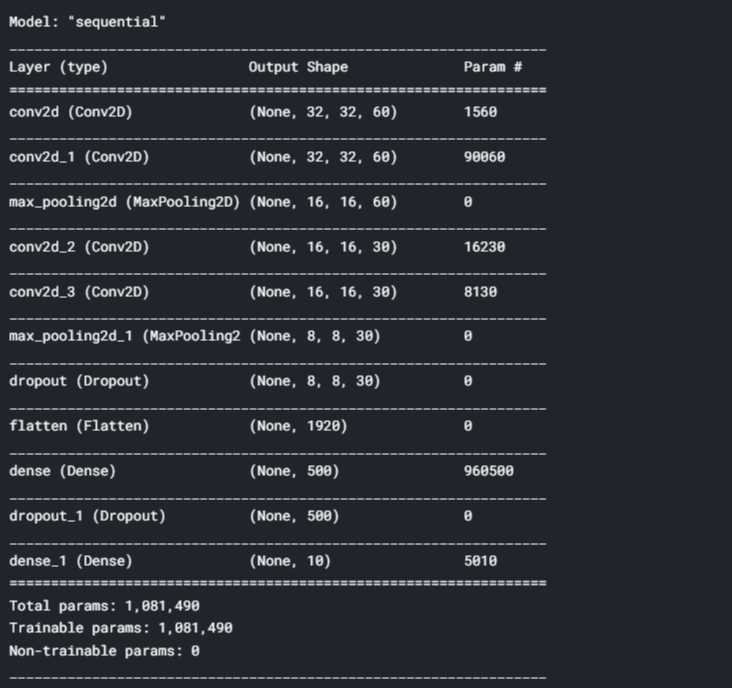
En este paso, compilaremos el modelo y probaremos el modelo en el conjunto de prueba como se muestra a continuación:
#Compiling the model
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon = 1e-08, decay=0.0)
model.compile(optimizer=optimizer,loss="categorical_crossentropy",metrics=['accuracy'])
#Fit the model
history = model.fit(datagen.flow(train_X, train_y, batch_size=32),
epochs = 30, validation_data = (valid_X, valid_y),
verbose = 2, steps_per_epoch= 200)
# Testing the model on the test set
score = model.evaluate(test_X, test_y, verbose=0)
print('Test Score=",score[0])
print("Test Accuracy =', score[1])

Parte 2: Leer y detectar el Sudoku a partir de una imagen
LEER EL ROMPECABEZAS SUDOKU
Leer un Sudoku usando OpenCv usando el siguiente código:
# Randomly select an image from the dataset folder="sudoku-box-detection/aug" a=random.choice(os.listdir(folder)) print(a) sudoku_a = cv2.imread(folder+'/'+a) plt.figure() plt.imshow(sudoku_a) plt.show()
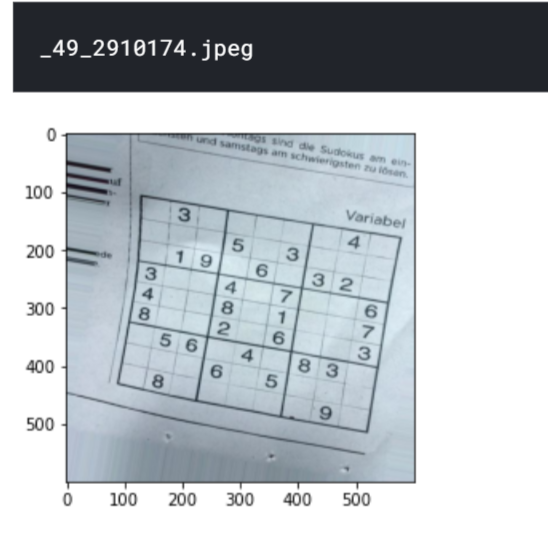
Preprocese la imagen para un análisis más detallado utilizando el siguiente código;
#Preprocessing image to be read
sudoku_a = cv2.resize(sudoku_a, (450,450))
# function to greyscale, blur and change the receptive threshold of image
def preprocess(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3),6)
#blur = cv2.bilateralFilter(gray,9,75,75)
threshold_img = cv2.adaptiveThreshold(blur,255,1,1,11,2)
return threshold_img
threshold = preprocess(sudoku_a)
#let's look at what we have got
plt.figure()
plt.imshow(threshold)
plt.show()
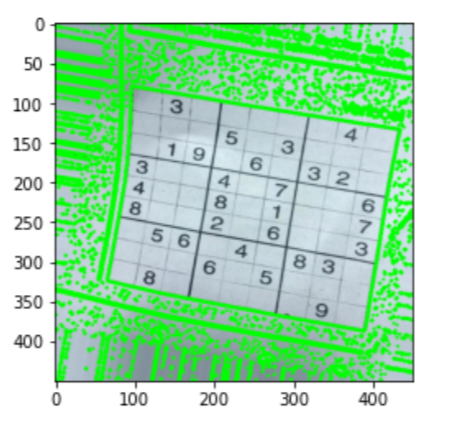
DETECTANDO CONTORNO
En esta sección, vamos a detectar el contorno. Seguimos detectando el contorno más grande de la imagen.
# Finding the outline of the sudoku puzzle in the image contour_1 = sudoku_a.copy() contour_2 = sudoku_a.copy() contour, hierarchy = cv2.findContours(threshold,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(contour_1, contour,-1,(0,255,0),3) #let's see what we got plt.figure() plt.imshow(contour_1) plt.show()
El siguiente código se usa para obtener el Sudoku recortado y bien alineado al remodelarlo.
def main_outline(contour):
biggest = np.array([])
max_area = 0
for i in contour:
area = cv2.contourArea(i)
if area >50:
peri = cv2.arcLength(i, True)
approx = cv2.approxPolyDP(i , 0.02* peri, True)
if area > max_area and len(approx) ==4:
biggest = approx
max_area = area
return biggest ,max_area
def reframe(points):
points = points.reshape((4, 2))
points_new = np.zeros((4,1,2),dtype = np.int32)
add = points.sum(1)
points_new[0] = points[np.argmin(add)]
points_new[3] = points[np.argmax(add)]
diff = np.diff(points, axis =1)
points_new[1] = points[np.argmin(diff)]
points_new[2] = points[np.argmax(diff)]
return points_new
def splitcells(img):
rows = np.vsplit(img,9)
boxes = []
for r in rows:
cols = np.hsplit(r,9)
for box in cols:
boxes.append(box)
return boxes
black_img = np.zeros((450,450,3), np.uint8)
biggest, maxArea = main_outline(contour)
if biggest.size != 0:
biggest = reframe(biggest)
cv2.drawContours(contour_2,biggest,-1, (0,255,0),10)
pts1 = np.float32(biggest)
pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]])
matrix = cv2.getPerspectiveTransform(pts1,pts2)
imagewrap = cv2.warpPerspective(sudoku_a,matrix,(450,450))
imagewrap =cv2.cvtColor(imagewrap, cv2.COLOR_BGR2GRAY)
plt.figure()
plt.imshow(imagewrap)
plt.show()
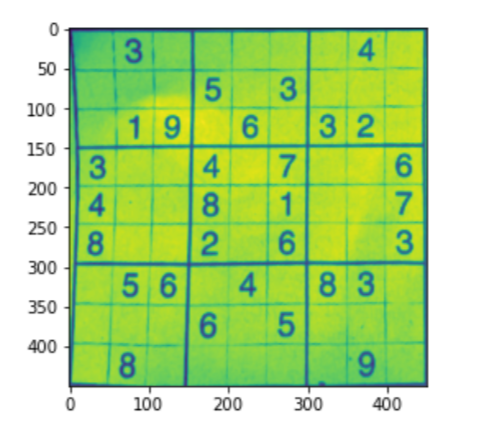
# Importing puzzle to be solved
puzzle = cv2.imread("su-puzzle/su.jpg")
#let's see what we got
plt.figure()
plt.imshow(puzzle)
plt.show()
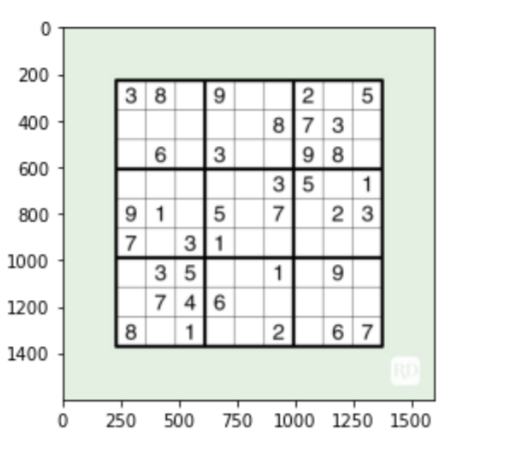
# Finding the outline of the sudoku puzzle in the image su_contour_1= su_puzzle.copy() su_contour_2= sudoku_a.copy() su_contour, hierarchy = cv2.findContours(su_puzzle,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(su_contour_1, su_contour,-1,(0,255,0),3) black_img = np.zeros((450,450,3), np.uint8) su_biggest, su_maxArea = main_outline(su_contour) if su_biggest.size != 0: su_biggest = reframe(su_biggest) cv2.drawContours(su_contour_2,su_biggest,-1, (0,255,0),10) su_pts1 = np.float32(su_biggest) su_pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]]) su_matrix = cv2.getPerspectiveTransform(su_pts1,su_pts2) su_imagewrap = cv2.warpPerspective(puzzle,su_matrix,(450,450)) su_imagewrap =cv2.cvtColor(su_imagewrap, cv2.COLOR_BGR2GRAY) plt.figure() plt.imshow(su_imagewrap) plt.show()
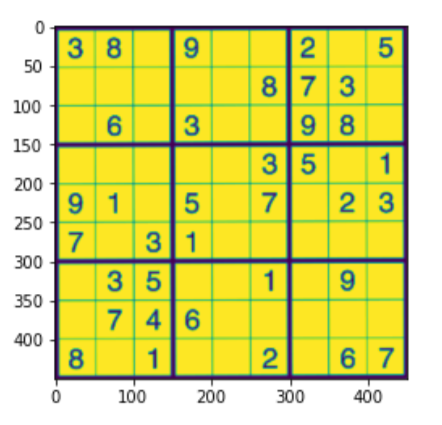
DIVIDIR LAS CÉLULAS Y CLASIFICAR LOS DÍGITOS
En esta sección, vamos a dividir las celdas y clasificar los dígitos.
- Primero divida el Sudoku en 81 celdas con dígitos o espacios vacíos
- Recortando las células
- Usar el modelo para clasificar los dígitos en las celdas de modo que las celdas vacías se clasifiquen como cero
- Finalmente, detecte la salida en una matriz de 81 dígitos.
sudoku_cell = splitcells(su_imagewrap) #Let's have alook at the last cell plt.figure() plt.imshow(sudoku_cell[58]) plt.show()
def CropCell(cells):
Cells_croped = []
for image in cells:
img = np.array(image)
img = img[4:46, 6:46]
img = Image.fromarray(img)
Cells_croped.append(img)
return Cells_croped
sudoku_cell_croped= CropCell(sudoku_cell)
#Let's have alook at the last cell
plt.figure()
plt.imshow(sudoku_cell_croped[58])
plt.show()
Parte 3: RESOLVER EL SODOKU
En esta sección vamos a realizar dos operaciones:
- Remodelando la matriz en una matriz de 9 x 9
- Resolver la matriz usando recursividad
# Reshaping the grid to a 9x9 matrix grid = np.reshape(grid,(9,9)) grid
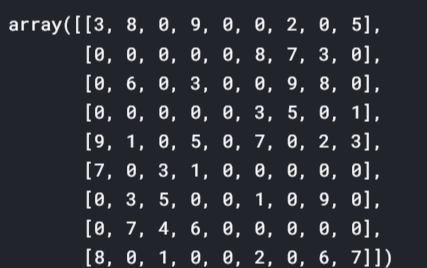
#For compairing plt.figure() plt.imshow(su_imagewrap) plt.show()
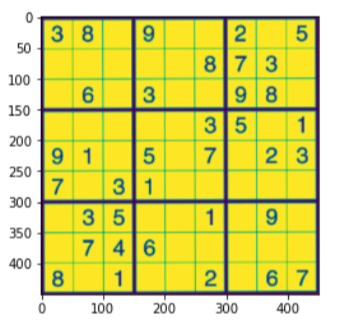
Verifique el siguiente código para resolver aún más el sudoku:
def next_box(quiz):
for row in range(9):
for col in range(9):
if quiz[row][col] == 0:
return (row, col)
return False
#Function to fill in the possible values by evaluating rows collumns and smaller cells
def possible (quiz,row, col, n):
#global quiz
for i in range (0,9):
if quiz[row][i] == n and row != i:
return False
for i in range (0,9):
if quiz[i][col] == n and col != i:
return False
row0 = (row)//3
col0 = (col)//3
for i in range(row0*3, row0*3 + 3):
for j in range(col0*3, col0*3 + 3):
if quiz[i][j]==n and (i,j) != (row, col):
return False
return True
#Recursion function to loop over untill a valid answer is found.
def solve(quiz):
val = next_box(quiz)
if val is False:
return True
else:
row, col = val
for n in range(1,10): #n is the possible solution
if possible(quiz,row, col, n):
quiz[row][col]=n
if solve(quiz):
return True
else:
quiz[row][col]=0
return
def Solved(quiz):
for row in range(9):
if row % 3 == 0 and row != 0:
print("....................")
for col in range(9):
if col % 3 == 0 and col != 0:
print("|", end=" ")
if col == 8:
print(quiz[row][col])
else:
print(str(quiz[row][col]) + " ", end="")
solve(grid)

Verifique el siguiente código para obtener el resultado final:
if solve(grid):
Solved(grid)
else:
print("Solution don't exist. Model misread digits.")
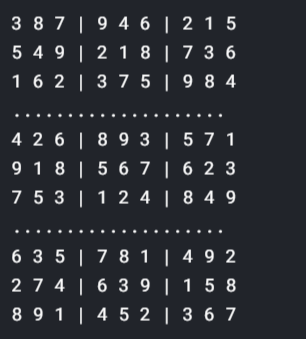
¡¡Viva!! Hemos terminado con la resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... de sudoku mediante el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... Si desea obtener más información, consulte los enlaces a continuación:
https://www.youtube.com/watch?v=G_UYXzGuqvM
https://www.kaggle.com/yashchoudhary/deep-sudoku-solver-multiple-approaches
https://www.youtube.com/watch?v=QR66rMS_ZfA
Notas finales
Entonces, en este artículo, tuvimos una discusión detallada sobre Resolver sudoku mediante el aprendizaje profundo. Espero que aprendas algo de este blog y te ayude en el futuro. Gracias por leer y tu paciencia. ¡Buena suerte!
Puedes consultar mis artículos aquí: Artículos
Identificación de correo: [email protected]
Conéctese conmigo en LinkedIn: LinkedIn.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





