Introducción
El resumen de texto es una de esas aplicaciones del procesamiento del lenguaje natural (PNL) que seguramente tendrá un gran impacto en nuestras vidas. Con los medios digitales en crecimiento y las publicaciones en constante crecimiento, ¿quién tiene tiempo para revisar artículos / documentos / libros completos para decidir si son útiles o no? Afortunadamente, esta tecnología ya está aquí.
¿Te has encontrado con la aplicación móvil? en pantalones cortos? Es una aplicación de noticias innovadora que convierte artículos de noticias en un resumen de 60 palabras. Y eso es exactamente lo que vamos a aprender en este artículo: Resumen de texto automático.
El resumen automático de texto es uno de los problemas más desafiantes e interesantes en el campo del procesamiento del lenguaje natural (PNL). Es un proceso de generación de un resumen de texto conciso y significativo a partir de múltiples recursos de texto, como libros, artículos de noticias, publicaciones de blogs, artículos de investigación, correos electrónicos y tweets.
La demanda de sistemas automáticos de resumen de texto está aumentando en estos días gracias a la disponibilidad de grandes cantidades de datos textuales.
A través de este artículo, exploraremos los dominios del resumen de texto. Entenderemos cómo funciona el algoritmo TextRank y también lo implementaremos en Python. Abróchate el cinturón, ¡este va a ser un viaje divertido!
Tabla de contenido
- Enfoques de resumen de texto
- Comprensión del algoritmo TextRank
- Comprensión de la declaración del problema
- Implementación del algoritmo TextRank
- ¿Que sigue?
Enfoques de resumen de texto
El resumen automático de texto ganó atención ya en la década de 1950. A trabajo de investigación, publicado por Hans Peter Luhn a fines de la década de 1950, titulado «La creación automática de resúmenes de literatura», utilizó características como la frecuencia de palabras y la frecuencia de frases para extraer oraciones importantes del texto con fines de resumen.
Otro importante investigar, realizado por Harold P. Edmundson a fines de la década de 1960, utilizó métodos como la presencia de palabras clave, las palabras utilizadas en el título que aparecen en el texto y la ubicación de las oraciones, para extraer oraciones significativas para el resumen del texto. Desde entonces, se han publicado muchos estudios importantes y emocionantes para abordar el desafío del resumen automático de texto.
TEl resumen de extensión se puede dividir en dos categorías: Resumen extractivo y Resumen abstracto.
- Resumen extractivo: Estos métodos se basan en extraer varias partes, como frases y oraciones, de un fragmento de texto y apilarlas para crear un resumen. Por lo tanto, identificar las oraciones correctas para resumir es de suma importancia en un método extractivo.
- Resumen abstracto: Estos métodos utilizan técnicas avanzadas de PNL para generar un resumen completamente nuevo. Es posible que algunas partes de este resumen ni siquiera aparezcan en el texto original.
En este artículo, nos centraremos en el resumen extractivo técnica.
Comprensión del algoritmo TextRank
Antes de comenzar con el algoritmo TextRank, hay otro algoritmo con el que deberíamos familiarizarnos: el algoritmo PageRank. De hecho, ¡esto realmente inspiró a TextRank! PageRank se utiliza principalmente para clasificar páginas web en los resultados de búsqueda en línea. Entendamos rápidamente los conceptos básicos de este algoritmo con la ayuda de un ejemplo.
Algoritmo de PageRank
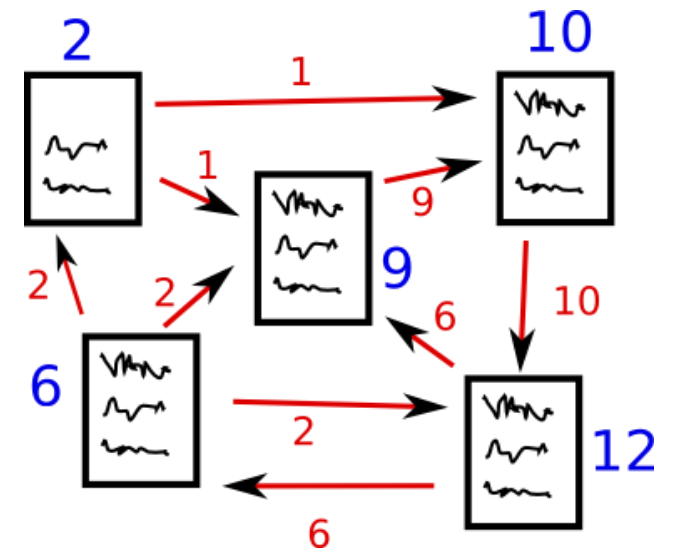
Fuente: http://www.scottbot.net/HIAL/
Supongamos que tenemos 4 páginas web: w1, w2, w3 y w4. Estas páginas contienen enlaces que se apuntan entre sí. Es posible que algunas páginas no tengan ningún vínculo; se denominan páginas colgantes.

- La página web w1 tiene enlaces que dirigen a w2 y w4
- w2 tiene enlaces para w3 y w1
- w4 tiene enlaces solo para la página web w1
- w3 no tiene enlaces y, por lo tanto, se llamará página colgante
Para clasificar estas páginas, tendríamos que calcular una puntuación llamada Puntuación de PageRank. Esta puntuación es la probabilidad de que un usuario visite esa página.
Para capturar las probabilidades de que los usuarios naveguen de una página a otra, crearemos un cuadrado matriz M, que tiene n filas yn columnas, donde norte es el número de páginas web.
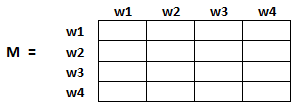
Cada elemento de esta matriz denota la probabilidad de que un usuario pase de una página web a otra. Por ejemplo, la celda resaltada a continuación contiene la probabilidad de transición de w1 a w2.
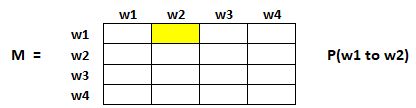
La inicialización de las probabilidades se explica en los siguientes pasos:
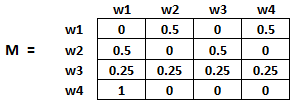
- Probabilidad de pasar de la página i a la j, es decir, M[ i ][ j ], se inicializa con 1 / (número de enlaces únicos en la página web wi)
- Si no hay un vínculo entre la página i y j, entonces la probabilidad se inicializará con 0
- Si un usuario ha aterrizado en una página colgante, se supone que es igualmente probable que haga la transición a cualquier página. Por lo tanto, M[ i ][ j ] se inicializará con 1 / (número de páginas web)
Por lo tanto, en nuestro caso, la matriz M se inicializará de la siguiente manera:
Finalmente, los valores de esta matriz se actualizarán de forma iterativa para llegar a las clasificaciones de la página web.
Algoritmo de rango de texto
Entendamos el algoritmo TextRank, ahora que conocemos el PageRank. He enumerado las similitudes entre estos dos algoritmos a continuación:
- En lugar de páginas web, usamos oraciones.
- La similitud entre dos frases cualesquiera se utiliza como equivalente a la probabilidad de transición de la página web.
- Las puntuaciones de similitud se almacenan en una matriz cuadrada, similar a la matriz M utilizada para PageRank
TextRank es una técnica de resumen de texto extractiva y no supervisada. Echemos un vistazo al flujo del algoritmo TextRank que seguiremos:
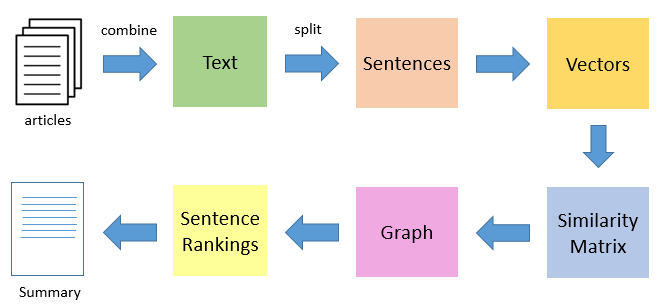
- El primer paso sería concatenar todo el texto contenido en los artículos.
- Luego divide el texto en oraciones individuales
- En el siguiente paso, encontraremos la representación vectorial (incrustaciones de palabras) para todas y cada una de las frases.
- Las similitudes entre los vectores de oración se calculan y almacenan en una matriz.
- Luego, la matriz de similitud se convierte en un gráfico, con oraciones como vértices y puntuaciones de similitud como aristas, para el cálculo del rango de oraciones.
- Finalmente, un cierto número de oraciones mejor clasificadas forman el resumen final.
Entonces, sin más preámbulos, ¡encienda nuestros Jupyter Notebooks y comencemos a codificar!
Nota: Si desea obtener más información sobre la teoría de gráficos, le recomiendo que consulte este artículo.
Comprensión de la declaración del problema
Siendo un gran aficionado al tenis, siempre trato de mantenerme actualizado con lo que está sucediendo en el deporte revisando religiosamente tantas actualizaciones de tenis en línea como sea posible. Sin embargo, ¡esto ha demostrado ser un trabajo bastante difícil! Hay demasiados recursos y el tiempo es una limitación.
Por lo tanto, decidí diseñar un sistema que pudiera prepararme un resumen con viñetas escaneando varios artículos. ¿Cómo hacer esto? Eso es lo que te mostraré en este tutorial. Aplicaremos el algoritmo TextRank en un conjunto de datos de artículos raspados con el objetivo de crear un resumen agradable y conciso.
Tenga en cuenta que esta es esencialmente una tarea de resumen de un solo dominio y varios documentos, es decir, tomaremos varios artículos como entrada y generaremos un único resumen con viñetas. El resumen de texto de varios dominios no se trata en este artículo, pero siéntase libre de probarlo al final.
Puede descargar el conjunto de datos que usaremos desde aquí.
Implementación del algoritmo TextRank
Entonces, sin más preámbulos, encienda sus Jupyter Notebooks e implementemos lo que hemos aprendido hasta ahora.
Importar bibliotecas necesarias
Primero, importe las bibliotecas que aprovecharemos para este desafío.
import numpy as np
import pandas as pd
import nltk
nltk.download('punkt') # one time execution
import re
Leer los datos
Ahora leamos nuestro conjunto de datos. He proporcionado el enlace para descargar los datos en la sección anterior (en caso de que se lo haya perdido).
df = pd.read_csv("tennis_articles_v4.csv")
Inspeccionar los datos
Echemos un vistazo rápido a los datos.
df.head()

Tenemos 3 columnas en nuestro conjunto de datos: ‘article_id’, ‘article_text’ y ‘source’. Estamos más interesados en la columna ‘article_text’ ya que contiene el texto de los artículos. Imprimamos algunos de los valores de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... solo para ver cómo se ven.
df['article_text'][0]
Producción:
"Maria Sharapova has basically no friends as tennis players on the WTA Tour. The Russian player has no problems in openly speaking about it and in a recent interview she said: 'I don't really hide any feelings too much. I think everyone knows this is my job here. When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net...
df['article_text'][1]
BASEL, Switzerland (AP), Roger Federer advanced to the 14th Swiss Indoors final of his career by beating seventh-seeded Daniil Medvedev 6-1, 6-4 on Saturday. Seeking a ninth title at his hometown event, and a 99th overall, Federer will play 93th-ranked Marius Copil on Sunday. Federer dominated the 20th-ranked Medvedev and had his first match-point chance to break serve again at 5-1...
df['article_text'][2]
Roger Federer has revealed that organisers of the re-launched and condensed Davis Cup gave him three days to decide if he would commit to the controversial competition. Speaking at the Swiss Indoors tournament where he will play in Sundays final against Romanian qualifier Marius Copil, the world number three said that given the impossibly short time frame to make a decision, he opted out of any commitment...
Ahora tenemos 2 opciones: podemos resumir cada artículo individualmente o podemos generar un resumen único para todos los artículos. Para nuestro propósito, seguiremos adelante con este último.
Dividir texto en oraciones
Ahora el siguiente paso es dividir el texto en oraciones individuales. Usaremos el sent_tokenize () función de la nltk biblioteca para hacer esto.
from nltk.tokenize import sent_tokenize sentences = [] for s in df['article_text']: sentences.append(sent_tokenize(s)) sentences = [y for x in sentences for y in x] # flatten list
Imprimamos algunos elementos de la lista. frases.
sentences[:5]
Producción:
['Maria Sharapova has basically no friends as tennis players on the WTA Tour.', "The Russian player has no problems in openly speaking about it and in a recent interview she said: 'I don't really hide any feelings too much.", 'I think everyone knows this is my job here.', "When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match.", "I'm a pretty competitive girl."]
Descarga GloVe Word Embeddings
Guante Las incrustaciones de palabras son representaciones vectoriales de palabras. Estas incrustaciones de palabras se utilizarán para crear vectores para nuestras oraciones. También podríamos haber usado los enfoques Bag-of-Words o TF-IDF para crear características para nuestras oraciones, pero estos métodos ignoran el orden de las palabras (y el número de características suele ser bastante grande).
Usaremos los pre-entrenados Wikipedia 2014 + Gigaword 5 Vectores GloVe disponibles aquí. Aviso: el tamaño de estas incrustaciones de palabras es de 822 MB.
!wget http://nlp.stanford.edu/data/glove.6B.zip !unzip glove*.zip
Extraigamos las palabras incrustadas o vectores de palabras.
# Extract word vectors
word_embeddings = {}
f = open('glove.6B.100d.txt', encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype="float32")
word_embeddings[word] = coefs
f.close()
len(word_embeddings)
400000
Ahora tenemos vectores de palabras para 400.000 términos diferentes almacenados en el diccionario: ‘word_embeddings’.
Preprocesamiento de texto
Siempre es una buena práctica hacer que sus datos textuales estén libres de ruido tanto como sea posible. Entonces, hagamos una limpieza básica de texto.
# remove punctuations, numbers and special characters
clean_sentences = pd.Series(sentences).str.replace("[^a-zA-Z]", " ")
# make alphabets lowercase
clean_sentences = [s.lower() for s in clean_sentences]
Elimine las palabras vacías (palabras de uso común de un idioma: es, am, the, of, in, etc.) presentes en las oraciones. Si no ha descargado nltk-stopwords, luego ejecute la siguiente línea de código:
nltk.download('stopwords')
Ahora podemos importar las palabras vacías.
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
Definamos una función para eliminar estas palabras vacías de nuestro conjunto de datos.
# function to remove stopwords def remove_stopwords(sen): sen_new = " ".join([i for i in sen if i not in stop_words]) return sen_new
# remove stopwords from the sentences clean_sentences = [remove_stopwords(r.split()) for r in clean_sentences]
Usaremos clean_sentences para crear vectores para oraciones en nuestros datos con la ayuda de los vectores de palabras GloVe.
Representación vectorial de oraciones
# Extract word vectors
word_embeddings = {}
f = open('glove.6B.100d.txt', encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype="float32")
word_embeddings[word] = coefs
f.close()
Ahora, creemos vectores para nuestras oraciones. Primero buscaremos vectores (cada uno de los elementos de tamaño 100) para las palabras constituyentes en una oración y luego tomaremos la media / promedio de esos vectores para llegar a un vector consolidado para la oración.
sentence_vectors = []
for i in clean_sentences:
if len(i) != 0:
v = sum([word_embeddings.get(w, np.zeros((100,))) for w in i.split()])/(len(i.split())+0.001)
else:
v = np.zeros((100,))
sentence_vectors.append(v)
Nota: Para obtener más prácticas recomendadas para el procesamiento previo de texto, puede consultar nuestro curso en video, Procesamiento de lenguaje natural (NLP) usando Python.
Preparación de la matriz de similitud
El siguiente paso es encontrar similitudes entre las oraciones, y usaremos el enfoque de similitud de coseno para este desafío. Creemos una matriz de similitud vacía para esta tarea y poblamos con similitudes de coseno de las oraciones.
Primero definamos una matriz cero de dimensiones (n * n). Inicializaremos esta matriz con puntuaciones de similitud de coseno de las oraciones. Aquí, norte es el número de oraciones.
# similarity matrix sim_mat = np.zeros([len(sentences), len(sentences)])
Usaremos Coseno Similarity para calcular la similitud entre un par de oraciones.
from sklearn.metrics.pairwise import cosine_similarity
E inicialice la matriz con puntuaciones de similitud de coseno.
for i in range(len(sentences)):
for j in range(len(sentences)):
if i != j:
sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,100), sentence_vectors[j].reshape(1,100))[0,0]
Aplicación del algoritmo de PageRank
Antes de continuar, convierta la matriz de similitud sim_mat en un gráfico. Los nodos de este gráfico representarán las oraciones y los bordes representarán las puntuaciones de similitud entre las oraciones. En este gráfico, aplicaremos el algoritmo PageRank para llegar a la clasificación de las oraciones.
import networkx as nx nx_graph = nx.from_numpy_array(sim_mat) scores = nx.pagerank(nx_graph)
Extracción de resumen
Finalmente, es hora de extraer las N oraciones principales en función de sus clasificaciones para la generación de resumen.
ranked_sentences = sorted(((scores[i],s) for i,s in enumerate(sentences)), reverse=True)
# Extract top 10 sentences as the summary for i in range(10): print(ranked_sentences[i][1])
When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match. Major players feel that a big event in late November combined with one in January before the Australian Open will mean too much tennis and too little rest. Speaking at the Swiss Indoors tournament where he will play in Sundays final against Romanian qualifier Marius Copil, the world number three said that given the impossibly short time frame to make a decision, he opted out of any commitment. "I felt like the best weeks that I had to get to know players when I was playing were the Fed Cup weeks or the Olympic weeks, not necessarily during the tournaments. Currently in ninth place, Nishikori with a win could move to within 125 points of the cut for the eight-man event in London next month. He used his first break point to close out the first set before going up 3-0 in the second and wrapping up the win on his first match point. The Spaniard broke Anderson twice in the second but didn't get another chance on the South African's serve in the final set. "We also had the impression that at this stage it might be better to play matches than to train. The competition is set to feature 18 countries in the November 18-24 finals in Madrid next year, and will replace the classic home-and-away ties played four times per year for decades. Federer said earlier this month in Shanghai in that his chances of playing the Davis Cup were all but non-existent.
¡Y ahí vamos! Un resumen asombroso, ordenado, conciso y útil para nuestros artículos.
¿Que sigue?
El resumen automático de texto es un tema candente de investigación y, en este artículo, hemos cubierto solo la punta del iceberg. En el futuro, exploraremos la técnica de resumen de texto abstracto donde el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... juega un papel importante. Además, también podemos examinar las siguientes tareas de resumen:
Específico del problema
- Resumen de texto de varios dominios
- Resumen de un solo documento
- Resumen de texto en varios idiomas (fuente en algún idioma y resumen en otro idioma)
Específico del algoritmo
- Resumen de texto usando RNN y LSTM
- Resumen de texto mediante aprendizaje por refuerzoEl aprendizaje por refuerzo es una técnica de inteligencia artificial que permite a un agente aprender a tomar decisiones mediante la interacción con un entorno. A través de la retroalimentación en forma de recompensas o castigos, el agente optimiza su comportamiento para maximizar las recompensas acumuladas. Este enfoque se utiliza en diversas aplicaciones, desde videojuegos hasta robótica y sistemas de recomendación, destacándose por su capacidad de aprender estrategias complejas....
- Resumen de texto mediante redes generativas de confrontación (GAN)
Notas finales
Espero que esta publicación te haya ayudado a comprender el concepto de resumen automático de texto. Tiene una variedad de casos de uso y ha generado aplicaciones extremadamente exitosas. Ya sea para aprovechar su negocio o simplemente para su propio conocimiento, el resumen de texto es un enfoque con el que todos los entusiastas de la PNL deberían estar familiarizados.
Intentaré cubrir la técnica de resumen de texto abstractivo utilizando técnicas avanzadas en un artículo futuro. Mientras tanto, siéntase libre de usar la sección de comentarios a continuación para hacerme saber sus pensamientos o hacer cualquier pregunta que pueda tener sobre este artículo.





