Este artículo fue publicado como parte del Blogatón de ciencia de datos
Un sistema de recomendación es una de las principales aplicaciones de la ciencia de datos. Cada empresa de Internet de consumo requiere un sistema de recomendación como Netflix, Youtube, un servicio de noticias, etc. Lo que desea mostrar de una amplia gama de artículos es un sistema de recomendación.

Tabla de contenido
- Introducción a un sistema de recomendaciones
- Tipos de sistema de recomendación
- Sistema de recomendación de libros
- Filtrado basado en contenido
- Filtrado colaborativo
- Filtrado híbrido
- Sistema de recomendaciones prácticas
- Descripción del conjunto de datos
- Preprocesar datos
- Realizar EDA
- Agrupación
- Predicciones
- Notas finales
¿Qué es realmente el sistema de recomendación?
Un motor de recomendación es una clase de aprendizaje automático que ofrece sugerencias relevantes al cliente. Antes del sistema de recomendación, la mayor tendencia a comprar era aceptar una sugerencia de los amigos. Pero ahora Google sabe qué noticias leerá, Youtube sabe qué tipo de videos verá en función de su historial de búsqueda, historial de reproducciones o historial de compras.
Un sistema de recomendación ayuda a una organización a crear clientes leales y generar confianza en los productos y servicios deseados para los que llegaron a su sitio. El sistema de recomendación actual es tan poderoso que también puede manejar al nuevo cliente que ha visitado el sitio por primera vez. Recomiendan los productos que están en tendencia o están altamente calificados y también pueden recomendar los productos que aportan el máximo beneficio a la empresa.
Tipos de sistema de recomendación
Un sistema de recomendación generalmente se construye usando 3 técnicas que son el filtrado basado en contenido, el filtrado colaborativo y una combinación de ambos.
1) Filtrado basado en contenido
El algoritmo recomienda un producto similar a los que se usaron como mirados. En palabras simples, en este algoritmo, tratamos de encontrar un elemento que se parezca. Por ejemplo, a una persona le gusta ver tomas de Sachin Tendulkar, por lo que también le puede gustar ver tomas de Ricky Ponting porque los dos videos tienen etiquetas y categorías similares.
Solo que se ve similar entre el contenido y no se enfoca más en la persona que está viendo esto. Solo recomienda el producto que tiene la puntuación más alta según las preferencias pasadas.
2) Filtrado basado en colaboración
Los sistemas de recomendación de filtrado basados en la colaboración se basan en interacciones pasadas de usuarios y elementos de destino. En palabras simples, tratamos de buscar clientes similares y ofrecer productos basados en lo que ha elegido su apariencia. Entendamos con un ejemplo. X e Y son dos usuarios similares y el usuario X ha visto películas A, B y C. Y el usuario Y ha visto películas B, C y D, entonces recomendaremos una película a un usuario Y y una película D a un usuario X.
Youtube ha cambiado su sistema de recomendaciones de una técnica de filtrado basada en contenido a una basada en colaboración. Si has experimentado alguna vez, también hay videos que no tienen nada que ver con tu historial, pero también lo recomienda porque la otra persona similar a ti lo ha visto.
3) Método de filtrado híbrido
Básicamente es una combinación de los dos métodos anteriores. Es un modelo demasiado complejo que recomienda un producto en función de su historial y de usuarios similares como usted.
Hay algunas organizaciones que utilizan este método como Facebook que muestra noticias que son importantes para ti y para otros también en tu red y lo mismo es utilizado por Linkedin también.
Sistema de recomendación de libros
Un sistema de recomendación de libros es un tipo de sistema de recomendación en el que tenemos que recomendar libros similares al lector en función de su interés. El sistema de recomendación de libros es utilizado por sitios web en línea que proporcionan libros electrónicos como Google Play Books, biblioteca abierta, buenas lecturas, etc.
En este artículo, utilizaremos el método de filtrado basado en colaboración para crear un sistema de recomendación de libros. Puede descargar el conjunto de datos desde aquí
Implementación práctica del sistema de recomendaciones
Ensuciemos nuestras manos mientras intentamos implementar un sistema de recomendación de libros usando filtrado colaborativo.
Descripción del conjunto de datos
tenemos 3 archivos en nuestro conjunto de datos que se extraen de algunos libros que venden sitios web.
- Libros: primero se trata de libros que contienen toda la información relacionada con los libros, como el autor, el título, el año de publicación, etc.
- Usuarios: el segundo archivo contiene información del usuario registrado, como identificación de usuario, ubicación.
- calificaciones: las calificaciones contienen información como qué usuario ha otorgado la calificación a qué libro.
Entonces, basándonos en estos tres archivos, podemos construir un poderoso modelo de filtrado colaborativo. empecemos.
Cargar datos
comencemos por importar bibliotecas y cargar conjuntos de datos. mientras cargamos el archivo tenemos algunos problemas como.
- Los valores del archivo CSV están separados por punto y coma, no por coma.
- Hay algunas líneas que no funcionan como si no pudiéramos importarlas con pandas y arroja un error porque Python es un lenguaje interpretado.
- La codificación de un archivo está en latín
Entonces, mientras cargamos datos, tenemos que manejar estas excepciones y después de ejecutar el siguiente código, recibirá una advertencia y mostrará qué líneas tienen un error que hemos omitido durante la carga.
import numpy as np
import pandas as pd
books = pd.read_csv("BX-Books.csv", sep=';', encoding="latin-1", error_bad_lines=False)
users = pd.read_csv("BX-Users.csv", sep=';', encoding="latin-1", error_bad_lines=False)
ratings = pd.read_csv("BX-Book-Ratings.csv", sep=';', encoding="latin-1", error_bad_lines=False)
Procesamiento previo de datos
Ahora, en el archivo de libros, tenemos algunas columnas adicionales que no son necesarias para nuestra tarea, como las URL de las imágenes. Y cambiaremos el nombre de las columnas de cada archivo ya que el nombre de la columna contiene espacio y letras mayúsculas para que lo corrijamos para que sea fácil de usar.
books = books[['ISBN', 'Book-Title', 'Book-Author', 'Year-Of-Publication', 'Publisher']]
books.rename(columns = {'Book-Title':'title', 'Book-Author':'author', 'Year-Of-Publication':'year', 'Publisher':'publisher'}, inplace=True)
users.rename(columns = {'User-ID':'user_id', 'Location':'location', 'Age':'age'}, inplace=True)
ratings.rename(columns = {'User-ID':'user_id', 'Book-Rating':'rating'}, inplace=True)
Ahora, si ve el encabezado de cada marco de datos, podrá ver algo como esto.
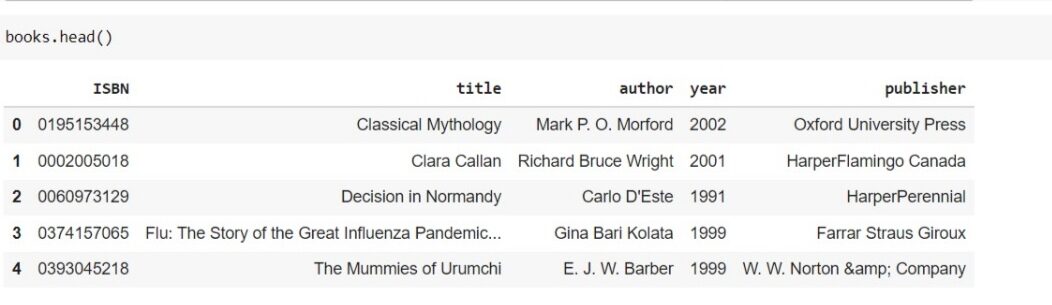
El conjunto de datos es confiable y se puede considerar como un gran conjunto de datos. Tenemos 271360 libros de datos y el total de usuarios registrados en el sitio web es de aproximadamente 278000 y han dado una calificación de cerca de 11 lakh. por lo tanto, podemos decir que el conjunto de datos que tenemos es bueno y confiable.
Aproximación al planteamiento de un problema
No queremos encontrar similitudes entre usuarios o libros. queremos hacer eso Si hay un usuario A que ha leído y le han gustado libros xey, y al usuario B también le han gustado estos dos libros y ahora el usuario A ha leído y le ha gustado algún libro z que no es leído por B, así que tenemos que recomendar z book al usuario B. Esto es lo que es el filtrado colaborativo.
Entonces, esto se logra usando la factorización de matrices, crearemos una matriz donde las columnas serán los usuarios y los índices serán los libros y el valor será la calificación. Como si tuviéramos que crear una tabla dinámicaLa tabla dinámica es una herramienta poderosa en programas de hoja de cálculo, como Microsoft Excel y Google Sheets. Permite resumir, analizar y visualizar grandes volúmenes de datos de manera eficiente. A través de su interfaz intuitiva, los usuarios pueden reorganizar la información, aplicar filtros y crear informes personalizados, facilitando la toma de decisiones informadas en diversos contextos, desde el ámbito empresarial hasta la investigación académica.....
Un gran defecto con una declaración de problema en el conjunto de datos.
Si tomamos todos los libros y todos los usuarios para modelar, ¿no crees que creará un problema? Entonces lo que tenemos que hacer es disminuir el número de usuarios y libros porque no podemos considerar a un usuario que solo se ha registrado en el sitio web o que solo ha leído uno o dos libros. En tal usuario, no podemos confiar en recomendar libros a otros porque tenemos que extraer conocimiento de los datos. Entonces, limitaremos este número y tomaremos un usuario que haya calificado al menos 200 libros y también limitaremos los libros y tomaremos solo aquellos libros que hayan recibido al menos 50 calificaciones de un usuario.
Análisis exploratorio de datos
Así que comencemos con el análisis y preparemos el conjunto de datos como discutimos para el modelado. veamos cuántos usuarios han otorgado calificaciones y extraemos aquellos usuarios que han otorgado más de 200 calificaciones.
ratings['user_id'].value_counts()
Paso 1) Extraiga usuarios y calificaciones de más de 200
cuando ejecuta el código anterior, podemos ver que solo 105283 personas han otorgado una calificación entre 278000. Ahora extraeremos los identificadores de usuario que han otorgado más de 200 calificaciones y cuando tengamos los identificadores de usuario extraeremos las calificaciones de solo este identificador de usuario del marco de datos de calificación.
x = ratings['user_id'].value_counts() > 200 y = x[x].index #user_ids print(y.shape) ratings = ratings[ratings['user_id'].isin(y)]
paso-2) Fusionar calificaciones con libros
Entonces hay 900 usuarios que han otorgado una calificación de 5.2 lakh y esto es lo que queremos. Ahora fusionaremos las calificaciones con los libros en base al ISBN para que obtengamos la calificación de cada usuario en cada ID de libro y el usuario que no ha calificado esa ID de libro, el valor será cero.
rating_with_books = ratings.merge(books, on='ISBN') rating_with_books.head()

paso-3) Extraiga libros que hayan recibido más de 50 calificaciones.
Ahora el tamaño del marco de datos ha disminuido y tenemos 4.8 lakh porque cuando fusionamos el marco de datos, no teníamos todos los datos de identificación del libro. Ahora contaremos la calificación de cada libro, por lo que agruparemos los datos según el título y los datos agregados según la calificación.
number_rating = rating_with_books.groupby('title')['rating'].count().reset_index()
number_rating.rename(columns= {'rating':'number_of_ratings'}, inplace=True)
final_rating = rating_with_books.merge(number_rating, on='title')
final_rating.shape
final_rating = final_rating[final_rating['number_of_ratings'] >= 50]
final_rating.drop_duplicates(['user_id','title'], inplace=True)
tenemos que eliminar los valores duplicados porque si el mismo usuario ha calificado el mismo libro varias veces, se creará un problema. Finalmente, tenemos un conjunto de datos con ese usuario que ha calificado más de 200 libros y libros que recibieron más de 50 calificaciones. la forma del marco de datos final es 59850 filas y 8 columnas.
Paso 4) Crear tabla dinámica
Como comentamos anteriormente, crearemos una tabla dinámica en la que las columnas serán los identificadores de usuario, el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... será el título del libro y el valor las calificaciones. Y la identificación de usuario que no ha calificado ningún libro tendrá valor como NAN, así que imputelo con cero.
book_pivot = final_rating.pivot_table(columns="user_id", index='title', values="rating") book_pivot.fillna(0, inplace=True)
Podemos ver que los más de 11 usuarios se han eliminado porque sus calificaciones estaban en aquellos libros que no reciben más de 50 calificaciones, por lo que se eliminan de la imagen.
Modelado
Hemos preparado nuestro conjunto de datos para modelar. Usaremos el algoritmo de vecinos más cercanos, que es el mismo que el de K más cercano, que se usa para la agrupación basada en la distancia euclidiana.
Pero aquí, en la tabla dinámica, tenemos muchos valores cero y en la agrupación, esta potencia de cálculo aumentará para calcular la distancia de los valores cero, por lo que convertiremos la tabla dinámica en la matriz dispersa y luego la alimentaremos al modelo.
from scipy.sparse import csr_matrix book_sparse = csr_matrix(book_pivot)
Ahora entrenaremos el algoritmo de vecinos más cercanos. aquí tenemos que especificar un algoritmo que es bruto significa encontrar la distancia de cada punto a todos los demás puntos.
from sklearn.neighbors import NearestNeighbors model = NearestNeighbors(algorithm='brute') model.fit(book_sparse)
Hagamos una predicción y veamos si sugiere libros o no. encontraremos los vecinos más cercanos a la identificación del libro de entrada y después de eso, imprimiremos los 5 libros principales que están más cerca de esos libros. Nos proporcionará la distancia y la identificación del libro a esa distancia. pasemos a Harry Potter, que tiene 237 índices.
distances, suggestions = model.kneighbors(book_pivot.iloc[237, :].values.reshape(1, -1))
imprimamos todos los libros sugeridos.
for i in range(len(suggestions)): print(book_pivot.index[suggestions[i]])
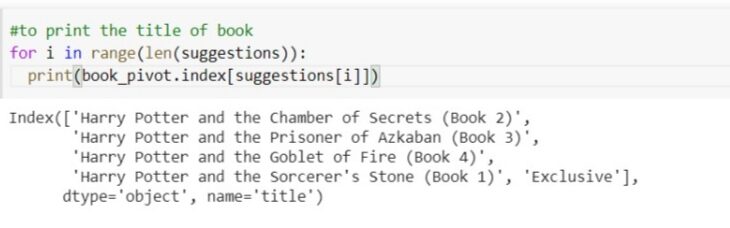
por lo tanto, hemos construido con éxito un sistema de recomendación de libros.
Notas finales
¡Viva! Tenemos que construir un sistema de recomendación de libros confiable y usted puede modificarlo y convertirlo en un proyecto final. Este es un maravilloso proyecto de aprendizaje sin supervisión en el que hemos realizado muchos preprocesos y puedes explorar más el conjunto de datos y, si encuentras algo más interesante, compártelo en el cuadro de comentarios.
Espero que haya sido fácil ponerse al día con cada método y seguir el artículo. Si tiene alguna consulta, publíquela en la sección de comentarios a continuación. Estaré encantado de ayudarte con cualquier consulta.
Sobre el Autor
Raghav Agrawal
Estoy cursando mi licenciatura en informática. Me gusta mucho la ciencia de datos y el big data. Me encanta trabajar con datos y aprender nuevas tecnologías. Por favor, siéntete libre de conectarte conmigo en Linkedin.
Si te gusta mi artículo, por favor, léelo también a los demás. Enlace
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





