Visión general
- Comprender Spark Streaming y su funcionamiento.
- Obtenga información sobre Windows en Spark Streaming con un ejemplo.
Introducción
Según IBM, el 60% de toda la información sensorial pierde valor en unos pocos milisegundos si no se actúa sobre ella. Teniendo en cuenta que el mercado de Big Data y análisis ha alcanzado los $ 125 mil millones y una gran parte de esto se atribuirá a IoT en el futuro, la incapacidad de aprovechar la información en tiempo real resultará en una pérdida de miles de millones de dólares.
Ejemplos de algunas de estas aplicaciones incluyen una empresa de telecomunicaciones, que calcula cuántos de sus usuarios han usado Whatsapp en los últimos 30 minutos, un minorista que lleva un registro de la cantidad de personas que han dicho cosas positivas sobre sus productos hoy en las redes sociales, o un agencia de aplicación de la ley que busca a un sospechoso utilizando datos de CCTV de tráfico.
Esta es la razón principal por la que los sistemas de procesamiento de flujos como Spark Streaming definirán el futuro de la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico.... en tiempo real. También existe una necesidad creciente de analizar tanto los datos en reposo como los datos en movimiento para impulsar las aplicaciones, lo que hace que sistemas como Spark, que pueden hacer ambas cosas, sean aún más atractivos y poderosos. Es un sistema para todas las temporadas de Big Data.
Aprenderá cómo Spark Streaming no solo mantiene intacta la API de Spark familiar, sino que también, bajo el capó, utiliza RDD para el almacenamiento y la tolerancia a fallas. Esto permite a los profesionales de Spark saltar al mundo del streaming desde el principio. Con eso en mente, vayamos directo a ello.
Introducción a Spark Streaming | de Harshit Agarwal | Medio
Tabla de contenido
- Apache SparkApache Spark es un motor de procesamiento de datos de código abierto que permite el análisis de grandes volúmenes de información de manera rápida y eficiente. Su diseño se basa en la memoria, lo que optimiza el rendimiento en comparación con otras herramientas de procesamiento por lotes. Spark es ampliamente utilizado en aplicaciones de big data, machine learning y análisis en tiempo real, gracias a su facilidad de uso y...
- Ecosistema Apache Spark
- Spark Streaming: DStreams
- Spark Streaming: contexto de transmisión
- Ejemplo: recuento de palabras
- Spark Streaming: Ventana
- Una ventana basada en: recuento de palabras
- Un (más eficiente) basado en ventanas: recuento de palabras
- Spark Streaming: operaciones de salida
Apache Spark
Apache Spark es un motor informático unificado y un conjunto de bibliotecas para el procesamiento de datos en paralelo en clústeres de computadoras. En el momento de escribir este artículo, Spark es el motor de código abierto más desarrollado para esta tarea, lo que lo convierte en una herramienta estándar para cualquier desarrollador o científico de datos interesado en big data.
Spark es compatible con varios lenguajes de programación ampliamente utilizados (Python, Java, Scala y R), incluye bibliotecas para diversas tareas que van desde SQL hasta transmisión y aprendizaje automático, y se ejecuta en cualquier lugar, desde una computadora portátil hasta un clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... de miles de servidores. Esto hace que sea un sistema fácil de comenzar y escalar hasta el procesamiento de big data o una escala increíblemente grande. A continuación se muestran algunas de las características de Spark:
-
Motor rápido y de uso general para el procesamiento de datos a gran escala
-
Spark puede respaldar de manera eficiente más tipos de cálculos
-
Puede leer / escribir en cualquier sistema compatible con Hadoop (por ejemplo, HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información...)
- Velocidad: almacenamiento de datos en memoria para consultas iterativas muy rápidas
-
el sistema también es más eficiente que MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data.... para aplicaciones complejas que se ejecutan en el disco
-
hasta 40 veces más rápido que Hadoop
-
Ingesta datos de muchas fuentes: Kafka, Twitter, HDFS, sockets TCP
-
Los resultados se pueden enviar a sistemas de archivos, bases de datos, paneles en vivo, pero no solo
-

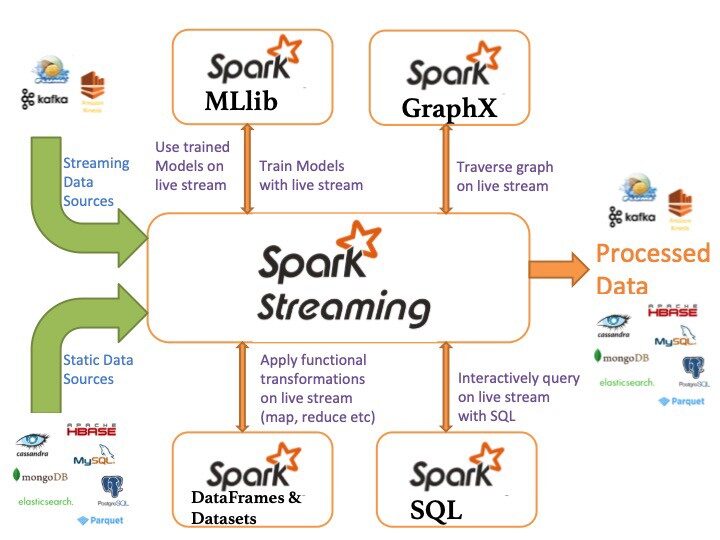
Ecosistema Apache Spark
Los siguientes son los componentes del ecosistema Apache Spark:
- Spark Core: funcionalidad básica de Spark (programación de tareas, administración de memoria, recuperación de fallas, interacción de sistemas de almacenamiento).
-
Spark SQL: paquete para trabajar con datos estructurados consultados a través de SQL y HiveQL
-
Spark Streaming: un componente que permite el procesamiento de transmisiones de datos en vivo (por ejemplo, archivos de registro, mensajes de actualizaciones de estado)
- MLLib: MLLib es una biblioteca de aprendizaje automático como Mahout. Está construido sobre Spark y tiene la capacidad de admitir muchos algoritmos de aprendizaje automático.
- GraphX: Para gráficos y cálculos gráficos, Spark tiene su propio motor de cálculo gráfico, llamado GraphX. Es similar a otras herramientas o bases de datos de procesamiento de gráficos ampliamente utilizadas, como Neo4j, Giraffe y muchas otras bases de datos de gráficos distribuidos.
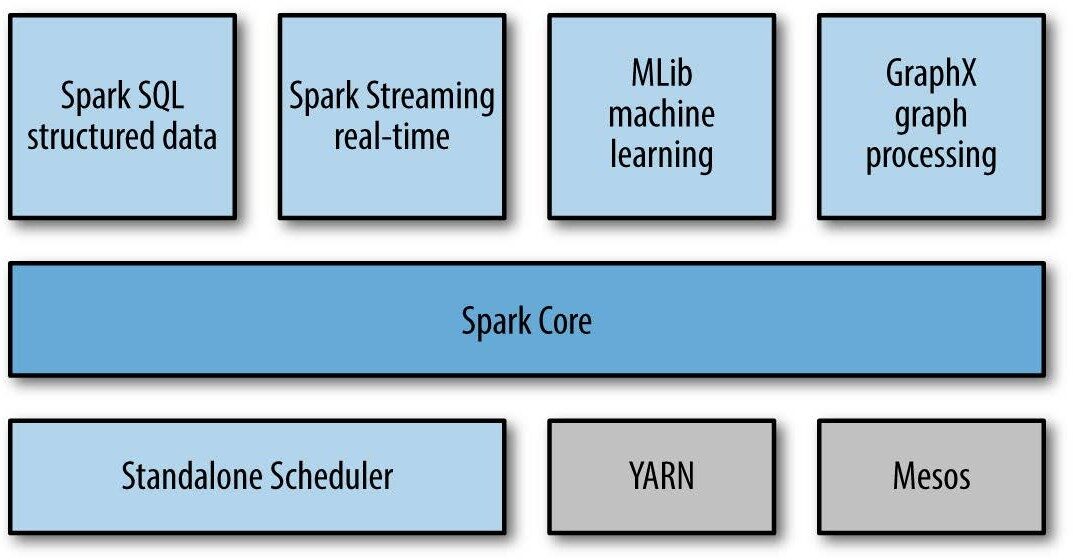
Spark Streaming: abstracciones
Spark Streaming tiene un arquitectura de micro lotes como sigue:
-
trata la transmisión como una serie de lotes de datos
-
Se crean nuevos lotes a intervalos de tiempo regulares.
-
el tamaño de los intervalos de tiempo se llama lote intervalo
-
el intervalo de lote suele estar entre 500 ms y varios segundos
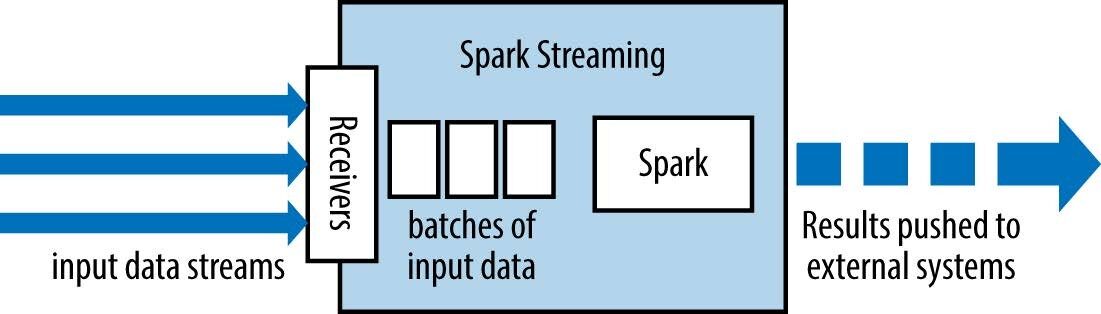
El valor de reducción de cada ventana se calcula de forma incremental.
Secuencia discretizada (DStream)
Corriente discretizada o DStream es la abstracción básica proporcionada por Spark Streaming. Representa un flujo continuo de datos, ya sea el flujo de datos de entrada recibido de la fuente o el flujo de datos procesados generado al transformar el flujo de entrada. Internamente, un DStream está representado por una serie continua de RDD, que es la abstracción de Spark de un conjunto de datos distribuido e inmutable (ver Guía de programación de Spark para más detalles). Cada RDD en un DStream contiene datos de un cierto intervalo.
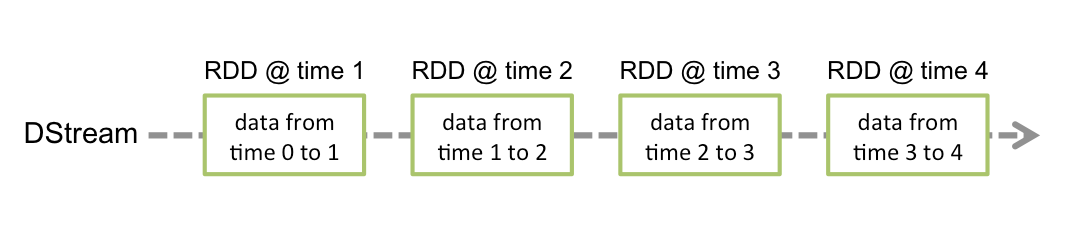
- Las transformaciones RDD son calculadas por el motor Spark
-
las operaciones de DStream ocultan la mayoría de estos detalles
-
Cualquier operación aplicada en un DStream se traduce en operaciones en los RDD subyacentes.
-
El valor de reducción de cada ventana se calcula de forma incremental.
Spark Streaming: contexto de transmisión
Es el principal punto de entrada para la funcionalidad Spark Streaming. Proporciona métodos utilizados para crear DStreams de varias fuentes de entrada. Streaming Spark se puede crear proporcionando una URL maestra de Spark y un nombre de aplicación, o desde una configuración org.apache.spark.SparkConf, o desde un org.apache.spark.SparkContext existente. Se puede acceder al SparkContext asociado usando context.sparkContext.
Después de crear y transformar DStreams, la computación de transmisión se puede iniciar y detener usando context.start() y, respectivamente. context.awaitTermination() permite que el hilo actual espere la terminación del contexto por stop() o por una excepción.
Para ejecutar una aplicación SparkStreaming, necesitamos definir StreamingContext. Se especializa SparkContext para aplicaciones de transmisión.
El contexto de transmisión en Java se puede definir de la siguiente manera:
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, batchInterval);
dónde:
-
Maestro es una URL de clúster Spark, Mesos o YARNYARN es un gestor de paquetes para JavaScript que permite la instalación y gestión eficiente de dependencias en proyectos de desarrollo. Desarrollado por Facebook, se caracteriza por su rapidez y seguridad en comparación con otros gestores. YARN utiliza un sistema de caché para optimizar las instalaciones y proporciona un archivo de bloqueo para garantizar la consistencia de las versiones de las dependencias en diferentes entornos de desarrollo....; para ejecutar su código en modo local, use «local[K]”Donde K> = 2 representa el paralelismo
-
nombre de la aplicación es el nombre de su aplicación
-
intervalo de lote intervalo de tiempo (en segundos) de cada lote
Una vez construidas, ofrecen dos tipos de operaciones:
Algunos ejemplos son: map (), filter () y reduceByKey ()
-
-
transformaciones con estado: utiliza datos de lotes anteriores para calcular los resultados del lote actual. Incluyen ventanas deslizantes, seguimiento del estado a lo largo del tiempo, etc.
-
Tenga en cuenta que un contexto de transmisión se puede iniciar solo una vez y debe iniciarse después de que configuremos todas las DStreams y las operaciones de salida.
Fuentes de datos básicas
A continuación se enumeran las fuentes de datos básicas de Spark Streaming:
- Flujos de archivos: Se utiliza para leer datos de archivos en cualquier sistema de archivos compatible con la API de HDFS (es decir, HDFS, S3, NFS, etc.), se puede crear un DStream como:
... = streamingContext.fileStream<...>(directory);
- Streams basados en receptores personalizados: DStreams se pueden crear con flujos de datos recibidos a través de receptores personalizados, extendiendo la clase Receiver
... = streamingContext.queueStream(queueOfRDDs)
- Cola de RDD como flujo: Para probar una aplicación Spark Streaming con datos de prueba, también se puede crear un DStream basado en una cola de RDD, utilizando
... = streamingContext.queueStream(queueOfRDDs)
La mayoría de las transformaciones tienen la misma sintaxis que la aplicada a los RDD
-
Transformación
Sentido
mapa (func)
Devuelve un nuevo DStream pasando cada elemento del DStream de origen a través de una función func.
flatMap (func)
Similar al mapa, pero cada elemento de entrada se puede asignar a 0 o más elementos de salida.
filtro (func)
Devuelva un nuevo DStream seleccionando solo los registros del DStream de origen en el que func devuelve verdadero.
unión (otherStream)
Devuelve un nuevo DStream que contiene la unión de los elementos del origen DStream y otherDStream.
unirse (otro flujo)
Cuando se llama a dos DStreams de pares (K, V) y (K, W), devuelve un nuevo DStream de (K, (V, W)) pares con todos los pares de elementos para cada clave.
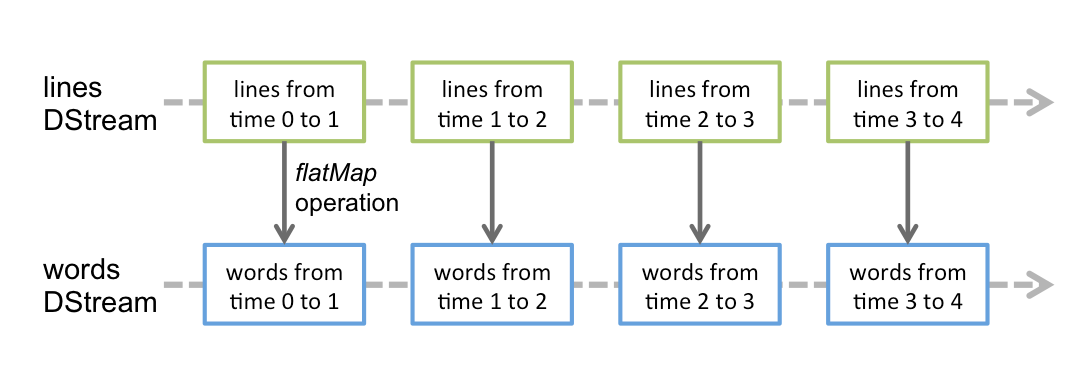
Ejemplo: recuento de palabras
SparkConf sparkConf = new SparkConf()
.setMaster("local[2]").setAppName("WordCount");
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<String> lines = ssc.socketTextStream( ... );
JavaDStream<String> words = lines.flatMap(...);
JavaPairDStream<String, Integer> wordCounts = words
.mapToPair(s -> new Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
Spark Streaming: Ventana
La función de ventana más simple es una ventana, que le permite crear un nuevo DStream, calculado aplicando los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de ventana al antiguo DStream. Puede utilizar cualquiera de las operaciones de DStream en la nueva transmisión, de modo que obtenga toda la flexibilidad que desee.
Los cálculos en ventanas le permiten aplicar transformaciones sobre una ventana deslizante de datos. Cualquier operación de ventana necesita especificar dos parámetros:
- ventana largo
- La duración de la ventana en segundos.
- corredizo intervalo
- El intervalo en el que se realiza la operación de ventana en segundos.
- Estos parámetros deben ser múltiplos del intervalo de lote.
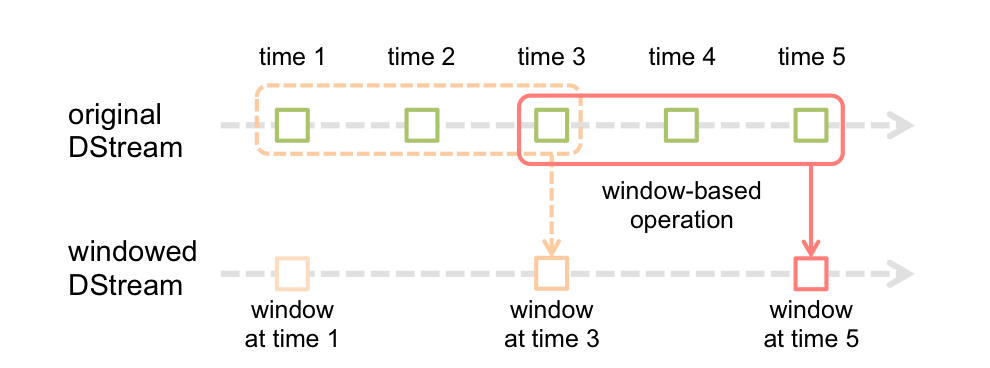
window(windowLength, slideInterval)
Devuelve un nuevo DStream que se calcula en función de lotes en ventana.
... JavaStreamingContext ssc = ... JavaReceiverInputDStream<String> lines = ... JavaDStream<String> linesInWindow = lines.window(WINDOW_SIZE, SLIDING_INTERVAL); JavaPairDStream<String, Integer> wordCounts = linesInWindow.flatMap(SPLIT_LINE) .mapToPair(s -> new Tuple2<>(s, 1)) .reduceByKey((i1, i2) -> i1 + i2);
- reduceByWindow (func, InvFunc, windowLength, slideInterval)
- Devuelve una nueva secuencia de un solo elemento, creada agregando elementos en la secuencia durante un intervalo deslizante usando func (que debe ser asociativo).
- El valor de reducción de cada ventana se calcula de forma incremental.
- reduceByKeyAndWindow (func, InvFunc, windowLength, slideInterval)
- Cuando se llama en un DStream de (K, V) pares, devuelve un nuevo DStream de (K, V) pares donde los valores para cada clave se agregan usando la función de reducción dada func sobre lotes en una ventana corrediza.
Para realizar estas transformaciones, necesitamos definir un directorio de puntos de control
Basado en ventana: recuento de palabras
... JavaPairDStream<String, Integer> wordCountPairs = ssc.socketTextStream(...) .flatMap(x -> Arrays.asList(SPACE.split(x)).iterator()) .mapToPair(s -> new Tuple2<>(s, 1)); JavaPairDStream<String, Integer> wordCounts = wordCountPairs .reduceByKeyAndWindow((i1, i2) -> i1 + i2, WINDOW_SIZE, SLIDING_INTERVAL); wordCounts.print(); wordCounts.foreachRDD(new SaveAsLocalFile());
Un (más eficiente) basado en ventanas: recuento de palabras
En una versión más eficiente, el valor de reducción de cada ventana se calcula de forma incremental.
Tenga en cuenta que los puntos de verificación deben estar habilitados para utilizar esta operación.
... ssc.checkpoint(LOCAL_CHECKPOINT_DIR); ... JavaPairDStream<String, Integer> wordCounts = wordCountPairs.reduceByKeyAndWindow( (i1, i2) -> i1 + i2, (i1, i2) -> i1 - i2, WINDOW_SIZE, SLIDING_INTERVAL);
Spark Streaming: operaciones de salida
Las operaciones de salida permiten que los datos de DStream se envíen a sistemas externos como una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... o un sistema de archivos
-
Operación de salida
Sentido
impresión()
Imprime los primeros diez elementos de cada lote de datos en un DStream en el nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... del controlador que ejecuta la aplicación.
saveAsTextFiles (prefijo, [suffix])
Guarde el contenido de este DStream como archivos de texto. El nombre de archivo en cada intervalo de lote se genera según el prefijo.
saveAsHadoopFiles (prefijo, [suffix])
Guarde el contenido de este DStream como archivos Hadoop.
saveAsObjectFiles (prefijo, [suffix])
Guarde el contenido de este DStream como SequenceFiles de objetos Java serializados.
foreachRDD (func)
Operador de salida genérico que aplica una función, func, a cada RDD generado a partir de la secuencia.
Referencias en línea
• Documentación de Spark
• Documentación de Spark
Conclusión
Debe quedar claro que Spark Streaming presenta una forma poderosa de escribir aplicaciones de transmisión. Tomar un trabajo por lotes que ya está ejecutando y convertirlo en un trabajo de transmisión casi sin cambios de código es simple y extremadamente útil desde el punto de vista de la ingeniería si necesita que este trabajo interactúe estrechamente con el resto de su aplicación de procesamiento de datos.
Le recomiendo que consulte los siguientes recursos de ingeniería de datos para mejorar su conocimiento:
Si le gustó el artículo, deje un comentario en la sección de comentarios a continuación.





