Introducción

(SR) es el proceso de recuperacion alta resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... (HORA) imágenes de baja resolucion (LR) imágenes. Es una clase importante de técnicas de procesamiento de imágenes en visión por computadora y procesamiento de imágenes y disfruta de una amplia gama de aplicaciones del mundo real, como imágenes médicas, imágenes satelitales, vigilancia y seguridad, imágenes astronómicas, entre otras.
Con el avance en las técnicas de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... en los últimos años, los modelos de SR basados en el aprendizaje profundo se han explorado activamente y, a menudo, logran un rendimiento de vanguardia en varios puntos de referencia de SR. Se han aplicado una variedad de métodos de aprendizaje profundo para resolver tareas de SR, que van desde el método basado en las redes neuronales convolucionales (CNN) hasta los recientes y prometedores enfoques de SR basados en redes generativas adversas.
Problema
El problema de la supresolución de imágenes (SR), en particular la superresolución de una sola imagen (SISR), ha ganado mucha atención en la comunidad de investigadores. SISR tiene como objetivo reconstruir una imagen de alta resolución ISR de una sola imagen de baja resolución ILR. Generalmente, la relación entre yoLR y la imagen original de alta resolución IHORA puede variar según la situación. Muchos estudios asumen que yoLR es una versión bicúbica reducida de IHORA, pero otros factores degradantes como el desenfoque, la destrucción o el ruido también se pueden considerar para aplicaciones prácticas.
En este artículo, nos centraremos en aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... métodos para tareas de superresolución. Al utilizar imágenes de FC como objetivo y LR como entrada, podemos tratar este problema como un problema de aprendizaje supervisado.
Métodos de muestreo superior
Antes de comprender el resto de la teoría detrás de la superresolución, debemos comprender muestreo (Aumentar la resolución espacial de las imágenes o simplemente aumentar el número de filas / columnas de píxeles o ambos en la imagen) y sus diversos métodos.
1. Métodos basados en interpolación – La interpolación de imágenes (escalado de imágenes) se refiere al cambio de tamaño de imágenes digitales y es ampliamente utilizada por aplicaciones relacionadas con imágenes. Los métodos tradicionales incluyen interpolación del vecino más cercano, interpolación lineal, bilineal, bicúbica, etc.
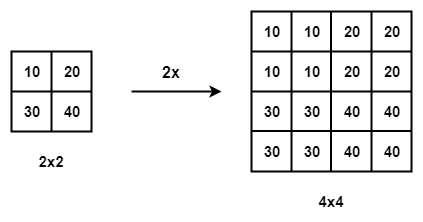
Interpolación del vecino más cercano con la escala de 2
- Interpolación del vecino más cercano – La interpolación del vecino más cercano es un algoritmo simple e intuitivo. Selecciona el valor del píxel más cercano para cada posición a interpolar independientemente de cualquier otro píxel.
- Interpolación bilineal – La interpolación bilineal (BLI) primero realiza la interpolación lineal en un eje de la imagen y luego en el otro eje. Dado que da como resultado una interpolación cuadrática con un campo receptivo de 2 × 2, muestra un rendimiento mucho mejor que la interpolación del vecino más cercano, manteniendo una velocidad relativamente rápida.
- Interpolación bicúbica – De manera similar, la interpolación bicúbica (BCI) realiza la interpolación cúbica en cada uno de los dos ejes. En comparación con BLI, la BCI tiene en cuenta 4 × 4 píxeles y da como resultado resultados más suaves con menos artefactos pero una velocidad mucho menor. Referir a esto para una discusión detallada.
Deficiencias – Los métodos basados en interpolación a menudo introducen algunos efectos secundarios como complejidad computacional, amplificación de ruido, resultados borrosos, etc.
2. Muestreo ascendente basado en el aprendizaje – Para superar las deficiencias de los métodos basados en interpolación y aprender sobremuestreo de un extremo a otro, la capa de convolución transpuesta y la capa de subpíxeles se introducen en el campo SR.
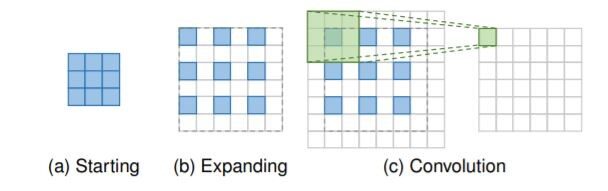
Capa de convolución transpuesta: los cuadros azules indican la entrada,
y los recuadros verdes indican el kernel y la salida de convolución.
- Convolución transpuesta: layer, también conocida como capa de deconvolución, intenta realizar una transformación opuesta a una convolución normal, es decir, predecir la posible entrada en función de mapas de características del tamaño de la salida de convolución. Específicamente, aumenta la resolución de la imagen expandiendo la imagen insertando ceros y realizando una convolución.
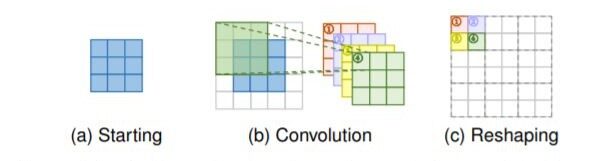
Capa de subpíxeles: los cuadros azules indican la entrada y los cuadros con otros colores indican diferentes operaciones de convolución y diferentes mapas de características de salida.
- Capa de subpíxeles: La capa de subpíxeles, otra capa de muestreo ascendente que se puede aprender de un extremo a otro, realiza el muestreo superior generando una pluralidad de canales por convolución y luego remodelando los programas. Dentro de esta capa, se aplica en primer lugar una convolución para producir salidas con
s2 canales de tiempo, donde s es el factor de escala. Suponiendo que el tamaño de entrada es h × w × c, el tamaño de salida será h × w × s2C. Después de eso, la operación de remodelación se realiza para producir salidas con tamaño sh × sw × c
Marcos de superresolución
Dado que la superresolución de la imagen es un problema mal planteado, cómo realizar un muestreo superior (es decir, generar una salida de frecuencia cardíaca a partir de la entrada LR) es el problema clave. Hay principalmente cuatro marcos de modelo basados en las operaciones de muestreo superior empleadas y sus ubicaciones en el modelo (consulte la tabla anterior).
1. Súper resolución de muestreo previo –
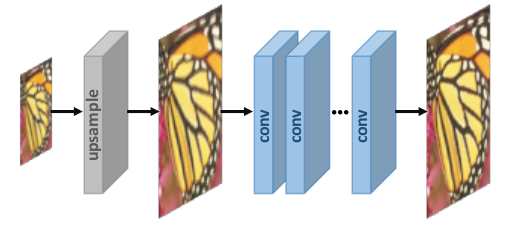
No hacemos un mapeo directo de imágenes LR a imágenes HR ya que se considera una tarea difícil. Utilizamos algoritmos tradicionales de muestreo superior para obtener imágenes de mayor resolución y luego refinarlas utilizando redes neuronales profundas es una solución sencilla. Por ejemplo, las imágenes LR se muestrean a imágenes HR gruesas con el tamaño deseado mediante interpolación bicúbica. Luego, se aplican CNN profundos a estas imágenes para reconstruir imágenes de alta calidad.
2. Súper resolución posterior al muestreo:
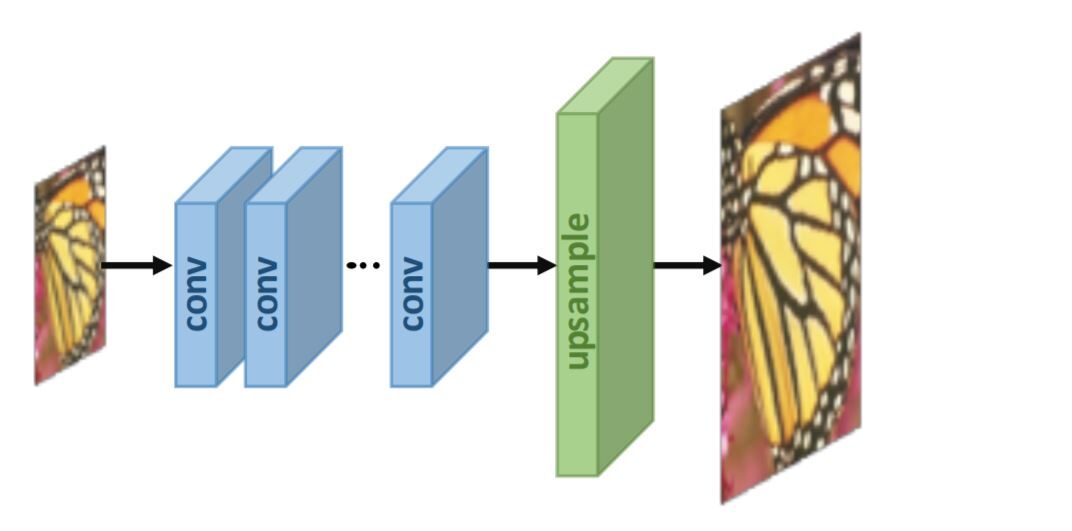
Para mejorar la eficiencia computacional y hacer un uso completo de la tecnología de aprendizaje profundo para aumentar la resolución automáticamente, los investigadores proponen realizar la mayoría de los cálculos en un espacio de baja dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... reemplazando el muestreo predefinido con capas de aprendizaje de extremo a extremo integradas al final de los modelos. En los trabajos pioneros de este marco, a saber, SR posterior al muestreo, las imágenes de entrada de LR se introducen en CNN profundos sin aumentar la resolución, y las capas de muestreo superior que se pueden aprender de un extremo a otro se aplican al final de la red.
Aprendiendo estrategias
En el campo de la superresolución, las funciones de pérdida se utilizan para
medir el error de reconstrucción y orientar la optimización del modelo. En los primeros tiempos, los investigadores suelen emplear Pérdida L2 por píxeles (error cuadrático medio), pero luego descubre que no puede medir el
calidad de reconstrucción con mucha precisión. Por lo tanto, una variedad
de funciones de pérdida (p. ej., pérdida de contenido, los adversarioss) se adoptan para medir mejor la reconstrucción
error y producir resultados más realistas y de mayor calidad.
- Pérdida de Pixelwise L1 – Diferencia absoluta entre los píxeles de la imagen HR de verdad del suelo y la generada.
- Pérdida de Pixelwise L2 – Diferencia cuadrática media entre los píxeles de la imagen HR de verdad del suelo y la generada.
- Pérdida de contenido – la pérdida de contenido se indica como la distancia euclidiana entre las representaciones de alto nivel de la imagen de salida y la imagen de destino. Las funciones de alto nivel se obtienen pasando a través de CNN previamente entrenados como VGG y ResNet.
- Pérdida adversaria – Basado en GAN, donde tratamos el modelo SR como un generador y definimos un discriminador adicional para juzgar si la imagen de entrada se genera o no.
- PSNR – La relación pico señal-ruido (PSNR) es una métrica objetiva de uso común para medir la calidad de reconstrucción de una transformación con pérdidas. PSNR es inversamente proporcional al logaritmo del error cuadrático medio (MSE) entre la imagen real del terreno y la imagen generada.
En MSE, soy un sin ruido metro×norte imagen monocromática (verdad fundamental) y K es la imagen generada (aproximación ruidosa). En PSNR, MAXI representa el valor máximo de píxeles posible de la imagen.
Diseño de red
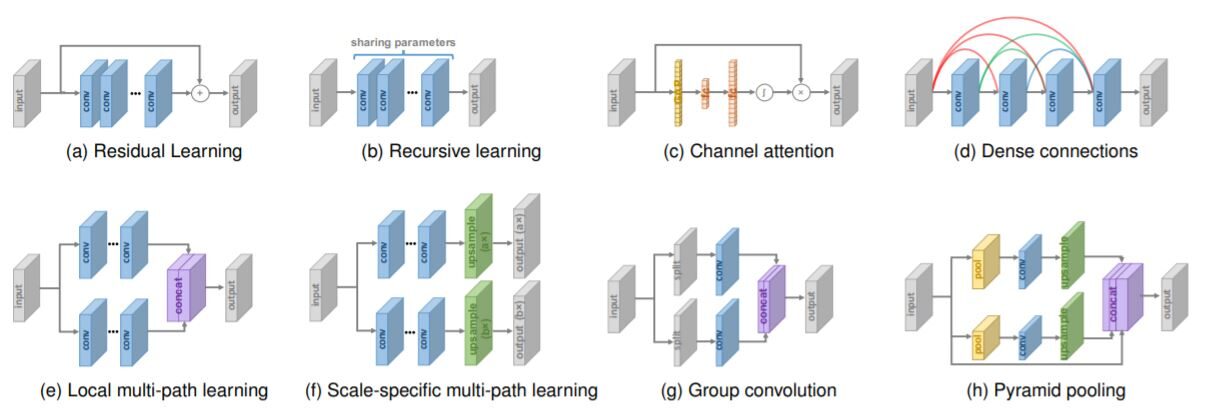
Varios diseños de red en arquitectura de superresolución
¡Suficiente de lo básico! Analicemos algunos de los Estado del arte métodos de superresolución –
Métodos de superresolución
Red de adversarios generativos de superresolución (SRGAN) – Utiliza la idea de GAN para la tarea de superresolución, es decir, el generador intentará producir una imagen a partir del ruido que será juzgada por el discriminador. Ambos seguirán entrenando para que el generador pueda generar imágenes que puedan coincidir con los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... reales.
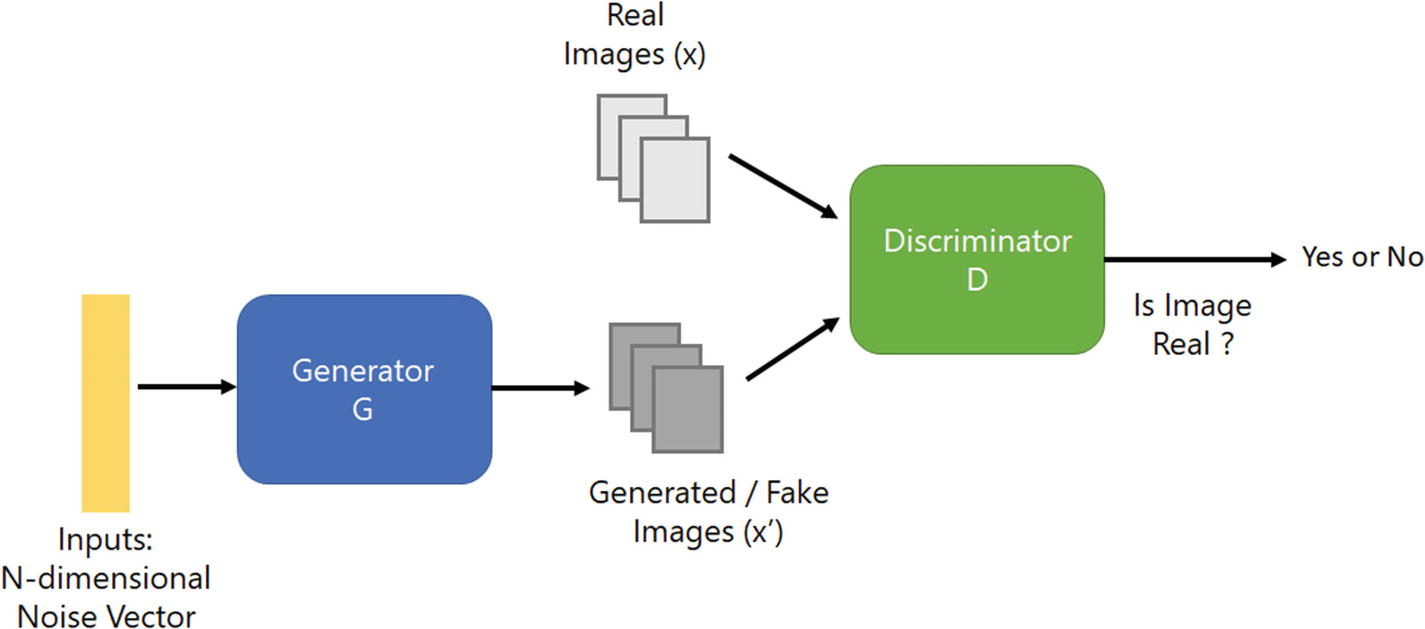
Arquitectura de la Red Adversaria Generativa
Hay varias formas de superresolución, pero hay un problema: ¿cómo podemos recuperar detalles de textura más finos de una imagen de baja resolución para que la imagen no se distorsione?
Los resultados tienen un PSNR alto; los medios tienen resultados de alta calidad, pero a menudo carecen de detalles de alta frecuencia.
Para lograr esto en SRGAN, usamos la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... perceptiva que comprende la pérdida de contenido y de adversario.
Comprobar el papeles originales para obtener información detallada.
Pasos –
1. Procesamos la HR (imágenes de alta resolución) para obtener imágenes LR con muestreo reducido. Ahora tenemos imágenes de HR y LR para el conjunto de datos de entrenamiento.
2. Pasamos imágenes LR a través de un generador que muestrea y proporciona imágenes SR.
3. Usamos el discriminador para distinguir la imagen de HR y propagar la pérdida de GAN para entrenar el discriminador y el generador.
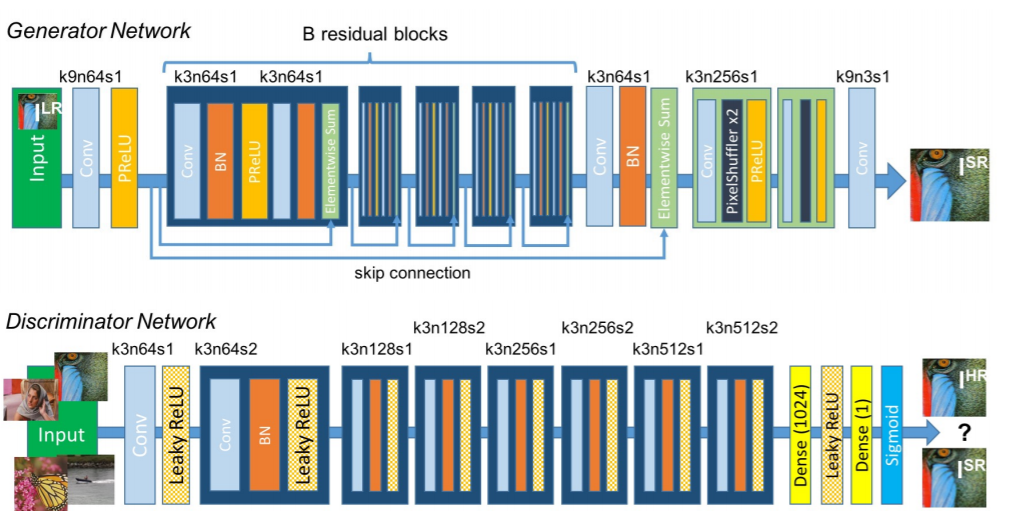
Arquitectura de red de SRGAN
Características clave del método:
- Tipo de marco de muestreo posterior
- Capa de subpíxeles para muestreo superior
- Contiene bloques residuales
- Utiliza pérdida de percepción
EDSR, MDSR – Exhibición de técnicas de aprendizaje residual
rendimiento mejorado de superresolución a través de redes neuronales convolucionales profundas (DCNN). Arquitectura de escala única Red de superresolución profunda mejorada (EDSR) maneja una escala de superresolución específica y Sistema de súper resolución profunda de múltiples escalas (MDSR) reconstruye varias escalas de imágenes de alta resolución en un solo modelo. La mejora significativa del rendimiento del modelo.
se debe a la optimización mediante la eliminación de módulos innecesarios en
redes residuales convencionales.
Comprobar el papeles originales para obtener información detallada.
Algunas de las características clave de los métodos:
- Bloques residuales – SRGAN aplicó con éxito la arquitectura ResNet al problema de superresolución con SRResNet, mejoraron aún más el rendimiento al emplear una mejor estructura ResNet. En la arquitectura propuesta –
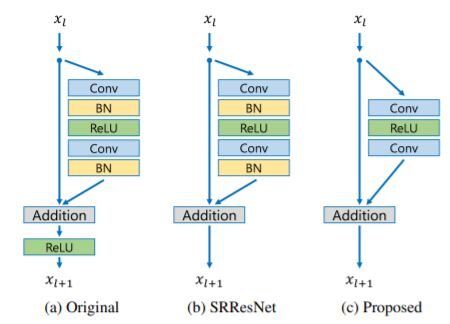
Comparación de los bloques residuales
- Quitaron las capas de normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... por lotes de la red como en SRResNets. Dado que las capas de normalización por lotes normalizan las características, eliminan la flexibilidad de rango de las redes al normalizar las características, es mejor eliminarlas.
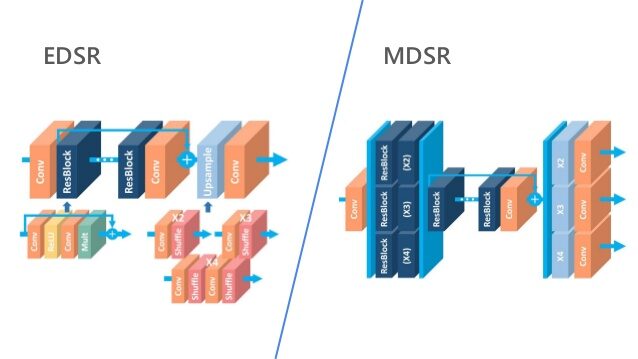
- En MDSR, propusieron una arquitectura multiescala que comparte la mayoría de los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... en diferentes escalas. El modelo multiescala propuesto utiliza significativamente menos parámetros que varios modelos de una sola escala, pero muestra un rendimiento comparable.
Código original de los métodos
¡Así que ahora hemos llegado al final del blog! Para obtener más información sobre la superresolución, consulte estos trabajos de encuesta.
Por favor comparta sus comentarios sobre el blog en la sección de comentarios. Aprendizaje feliz 🙂
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





