Este artículo fue publicado como parte del Blogatón de ciencia de datos
La imputación es una técnica utilizada para reemplazar los datos faltantes con algún valor sustituto para retener la mayor parte de los datos / información del conjunto de datos. Estas técnicas se utilizan porque eliminar los datos del conjunto de datos cada vez no es factible y puede conducir a una reducción en el tamaño del conjunto de datos en gran medida, lo que no solo genera preocupaciones por sesgar el conjunto de datos, sino que también conduce a un análisis incorrecto.
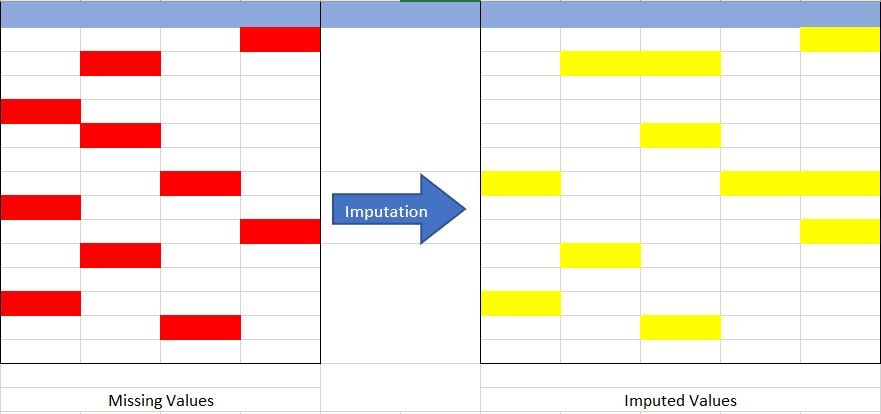
Fuente: creado por el autor
¿No está seguro de qué datos faltan? ¿Cómo ocurre? ¿Y su tipo? Echa un vistazo AQUÍ para saber más al respecto.
Entendamos el concepto de imputación de la Fig {Fig 1} anterior. En la imagen de arriba, he intentado representar los datos que faltan en la tabla de la izquierda (marcados en rojo) y mediante el uso de las técnicas de imputación hemos completado el conjunto de datos que faltan en la tabla de la derecha (marcados en amarillo), sin reducir el tamaño real de el conjunto de datos. Si nos damos cuenta aquí, hemos aumentado el tamaño de la columna, lo que es posible en la imputación (agregando la imputación de la categoría «Falta»).
¿Por qué es importante la imputación?
Entonces, después de conocer la definición de imputación, la siguiente pregunta es ¿Por qué deberíamos usarla y qué pasaría si no la uso?
Aquí vamos con las respuestas a las preguntas anteriores.
Usamos la imputación porque los datos faltantes pueden causar los siguientes problemas: –
- Incompatible con la mayoría de las bibliotecas de Python utilizadas en Machine Learning: – Sí, has leído bien. Al usar las bibliotecas para ML (la más común es skLearn), no tienen una disposición para manejar automáticamente estos datos faltantes y pueden generar errores.
- Distorsión en el conjunto de datos: – Una gran cantidad de datos faltantes puede causar distorsiones en la distribución de la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos...., es decir, puede aumentar o disminuir el valor de una categoría particular en el conjunto de datos.
- Afecta al modelo final: – los datos faltantes pueden causar un sesgo en el conjunto de datos y pueden llevar a un análisis defectuoso por parte del modelo.
Otra y la razón más importante es «Queremos restaurar el conjunto de datos completo». Esto ocurre principalmente en el caso en el que no queremos perder (más) datos de nuestro conjunto de datos, ya que todos son importantes y, en segundo lugar, el tamaño del conjunto de datos no es muy grande y eliminar parte de él puede tener un impacto significativo. en el modelo final.
Excelente..!! obtuvimos algunos conceptos básicos de datos perdidos e imputación. Ahora, echemos un vistazo a las diferentes técnicas de imputación y compárelas. Pero antes de saltar a él, tenemos que conocer los tipos de datos en nuestro conjunto de datos.
Suena extraño..!!! No se preocupe… La mayoría de los datos son de 4 tipos: – Numérico, Categórico, Fecha-hora y Mixto. Estos nombres se explican por sí mismos, por lo que no profundizan mucho ni los describen.
Fig 2: – Tipos de datos
Fuente: creado por el autor
Técnicas de imputación
Pasando a lo más destacado de este artículo … Técnicas utilizadas en imputación …
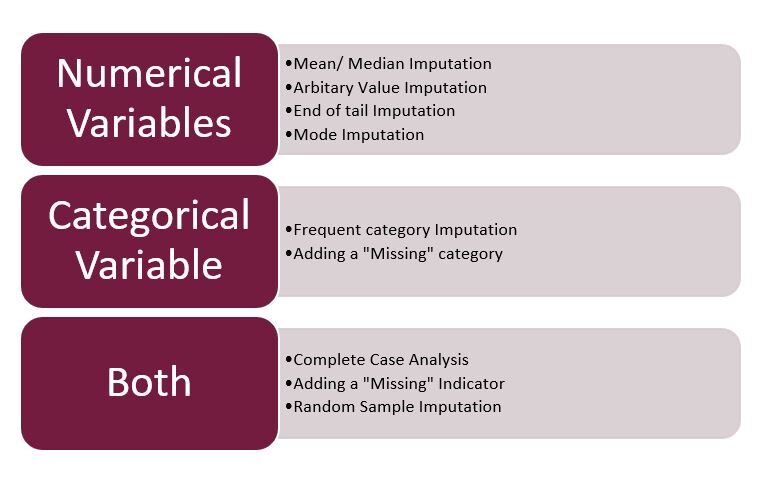
Fig 3: – Técnicas de imputación
Fuente: creado por el autor
Nota: – Aquí me centraré únicamente en la imputación mixta, numérica y categórica. La fecha y la hora formarán parte del próximo artículo.
1. Análisis de caso completo (CCA): –
Este es un método bastante sencillo para manejar los datos faltantes, que elimina directamente las filas que tienen datos faltantes, es decir, consideramos solo aquellas filas en las que tenemos datos completos, es decir, no faltan datos. Este método también se conoce popularmente como «eliminación por lista».
- Supuestos: –
- Faltan datos al azar (MAR).
- Los datos faltantes se eliminan por completo de la tabla.
- Ventajas: –
- Fácil de implementar.
- No se requiere manipulación de datos.
- Limitaciones: –
- Los datos eliminados pueden ser informativos.
- Puede provocar la eliminación de gran parte de los datos.
- Puede crear un sesgo en el conjunto de datos, si se elimina una gran cantidad de un tipo particular de variable.
- El modelo de producción no sabrá qué hacer con los datos que faltan.
- Cuándo usar:-
- Los datos son MAR (Missing At Random).
- Bueno para datos mixtos, numéricos y categóricos.
- Los datos que faltan no son más del 5% al 6% del conjunto de datos.
- Los datos no contienen mucha información y no sesgarán el conjunto de datos.
- Código:-
## To check the shape of original dataset
train_df.shape
## Output (614 rows & 13 columns) (614,13)
## Finding the columns that have Null Values(Missing Data) ## We are using a for loop for all the columns present in dataset with average null values greater than 0
na_variables = [ var for var in train_df.columns if train_df[var].isnull().mean() > 0 ]
## Output of column names with null values ['Gender','Married','Dependents','Self_Employed','LoanAmount','Loan_Amount_Term','Credit_History']
## También podemos ver los valores nulos medios presentes en estas columnas {Mostrado en la imagen a continuación}
data_na = trainf_df[na_variables].isnull (). mean ()
## Implementing the CCA techniques to remove Missing Data data_cca = train_df(axis=0) ### axis=0 is used for specifying rows
## Verifying the final shape of the remaining dataset data_cca.shape
## Output (480 rows & 13 Columns) (480,13)
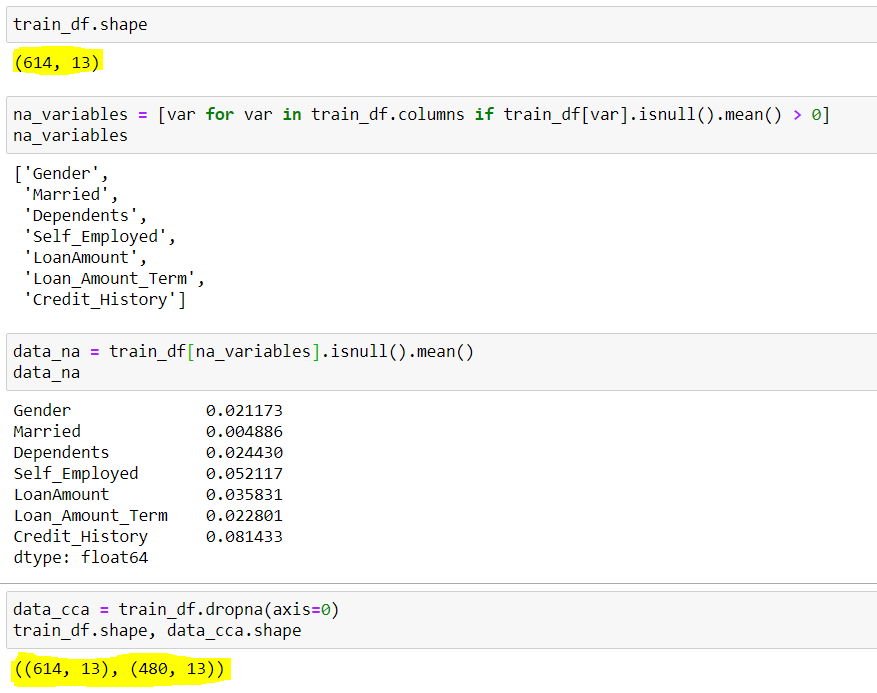
Figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... 3: – CCA
Fuente: Creado por el autor
Aquí podemos ver, el conjunto de datos tenía inicialmente 614 filas y 13 columnas, de las cuales 7 filas tenían datos faltantes(variables_variables), sus filas medias faltantes se muestran mediante data_na. Observamos que, aparte de y , todos tienen una media inferior al 5%. Entonces, según el CCA, eliminamos las filas con datos faltantes, lo que resultó en un conjunto de datos con solo 480 filas. Aquí se puede ver alrededor del 20% de la reducción de datos, lo que puede causar muchos problemas en el futuro.
2. Imputación de valor arbitrario
Esta es una técnica importante que se utiliza en la imputación, ya que puede manejar tanto las variables numéricas como las categóricas. Esta técnica establece que agrupamos los valores faltantes en una columna y los asignamos a un nuevo valor que está lejos del rango de esa columna. En general, utilizamos valores como 99999999 o -9999999 o «Falta» o «No definido» para variables numéricas y categóricas.
- Supuestos: –
- Los datos no faltan al azar.
- Los datos faltantes se imputan con un valor arbitrario que no forma parte del conjunto de datos ni de la media / medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... / moda de los datos.
- Ventajas: –
- Fácil de implementar.
- Podemos usarlo en producción.
- Conserva la importancia de los «valores perdidos» si existe.
- Desventajas: –
- Puede distorsionar la distribución de la variable original.
- Los valores arbitrarios pueden crear valores atípicos.
- Se requiere precaución adicional al seleccionar el valor arbitrario.
- Cuándo usar:-
- Cuando los datos no son MAR (Missing At Random).
- Apto para todos.
- Código:-
## Finding the columns that have Null Values(Missing Data) ## We are using a for loop for all the columns present in dataset with average null values greater than 0
na_variables = [ var for var in train_df.columns if train_df[var].isnull().mean() > 0 ]
## Output of column names with null values ['Gender','Married','Dependents','Self_Employed','LoanAmount','Loan_Amount_Term','Credit_History']
## Use Gender column to find the unique values in the column train_df['Gender'].unique()
## Output array(['Male','Female',nan])
## Here nan represent Missing Data
## Using Arbitary Imputation technique, we will Impute missing Gender with "Missing" {You can use any other value also}
arb_impute = train_df['Gender'].fillna('Missing')
arb.impute.unique()
## Output array(['Male','Female','Missing'])
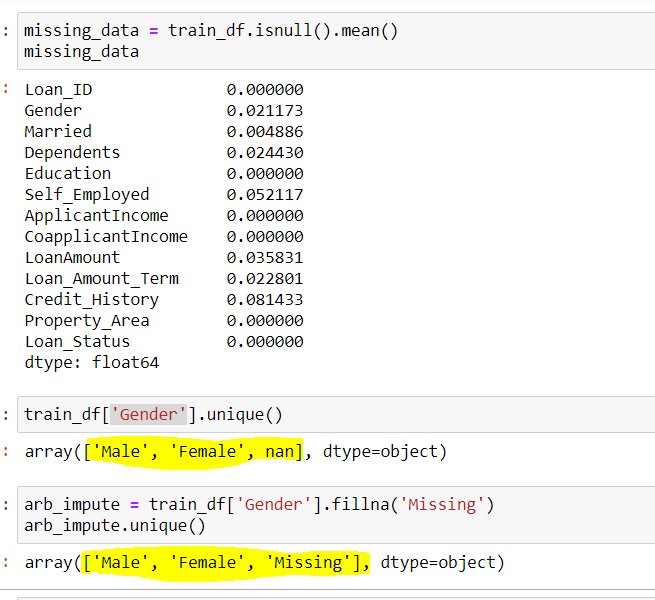
Fig 4: – Imputación arbitraria
Fuente: creado por el autor
Podemos ver aquí la columna Género tenía 2 valores únicos {‘Macho femenino’} y pocos valores perdidos {nan}. Al usar la imputación arbitraria, llenamos los valores de {nan} en esta columna con {faltante}, por lo que se obtienen 3 valores únicos para la variable ‘Género’.
3. Imputación de categoría frecuente
Esta técnica dice reemplazar el valor faltante con la variable con la frecuencia más alta o en palabras simples reemplazando los valores con la Moda de esa columna. Esta técnica también se conoce como Imputación de modo.
- Supuestos: –
- Faltan datos al azar.
- Existe una alta probabilidad de que los datos faltantes se parezcan a la mayoría de los datos.
- Ventajas: –
- La implementación es sencilla.
- Podemos obtener un conjunto de datos completo en muy poco tiempo.
- Podemos utilizar esta técnica en el modelo de producción.
- Desventajas: –
- Cuanto mayor sea el porcentaje de valores perdidos, mayor será la distorsión.
- Puede dar lugar a una sobrerrepresentación de una categoría en particular.
- Puede distorsionar la distribución de la variable original.
- Cuándo usar:-
- Faltan datos al azar (MAR)
- Los datos que faltan no son más del 5% al 6% del conjunto de datos.
- Código:-
## finding the count of unique values in Gender train_df['Gender'].groupby(train_df['Gender']).count()
## Output (489 Male & 112 Female) Male 489 Female 112
## Male has higgest frequency. We can also do it by checking the mode train_df['Gender'].mode()
## Output Male
## Using Frequent Category Imputer
frq_impute = train_df['Gender'].fillna('Male')
frq_impute.unique()
## Output array(['Male','Female'])
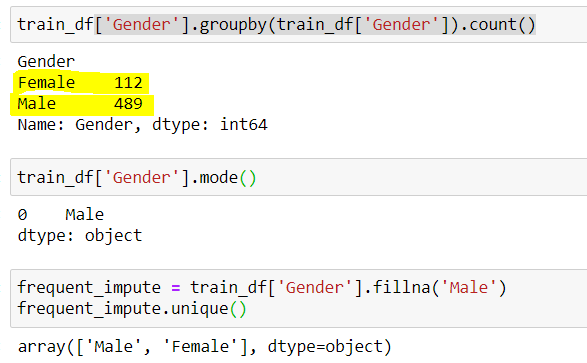
Fig 4: – Imputación de categoría frecuente
Fuente: creado por el autor
Aquí notamos que «Masculino» fue la categoría más frecuente, por lo que la usamos para reemplazar los datos faltantes. Ahora nos quedan solo 2 categorías, es decir, masculino y femenino.
Por lo tanto, podemos ver que cada técnica tiene sus ventajas y desventajas, y depende del conjunto de datos y la situación para la cual las diferentes técnicas que vamos a utilizar.
Eso es todo de aquí …
Hasta entonces, este es Shashank Singhal, un entusiasta del Big Data y la ciencia de datos.
Feliz aprendizaje…
Si te gustó mi artículo puedes seguirme AQUÍ
Perfil de Linkedin:- www.linkedin.com/in/shashank-singhal-1806
Nota: – Todas las imágenes utilizadas anteriormente fueron creadas por mí (autor).
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





