Visión general
- SQL es un lenguaje imprescindible para cualquier persona en análisis o ciencia de datos.
- Aquí hay 8 ingeniosas técnicas de SQL para el análisis de datos con las que los profesionales de la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico.... y la ciencia de datos adorarán trabajar
Introducción
SQL es un engranaje clave en el arsenal de un profesional de la ciencia de datos. Hablo por experiencia: simplemente no puede esperar forjarse una carrera exitosa en análisis o ciencia de datos si aún no ha aprendido SQL.
¿Y por qué SQL es tan importante?
A medida que avanzamos hacia una nueva década, la velocidad a la que producimos y consumimos datos se dispara día a día. Para tomar decisiones inteligentes basadas en datos, las organizaciones de todo el mundo están contratando profesionales de datos como analistas de negocios y científicos de datos para extraer y desenterrar conocimientos del vasto tesoro de datos.
Y una de las herramientas más importantes necesarias para esto es, lo adivinó, ¡SQL!

El lenguaje de consulta estructurado (SQL) ha existido durante décadas. Es un lenguaje de programación utilizado para administrar los datos almacenados en bases de datos relacionales. La mayoría de las grandes empresas utilizan SQL en todo el mundo. Un analista de datos puede usar SQL para acceder, leer, manipular y analizar los datos almacenados en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... y generar información útil para impulsar un proceso de toma de decisiones informado.
En este artículo, discutiré 8 técnicas / consultas de SQL que lo prepararán para cualquier problema avanzado de análisis de datos. Tenga en cuenta que este artículo asume un conocimiento muy básico de SQL.
Sugeriría consultar los cursos a continuación si es nuevo en SQL y / o análisis de negocios:
Tabla de contenido
- Primero comprendamos el conjunto de datos
- Técnica SQL n. ° 1: contar filas y elementos
- Técnica SQL n. ° 2: funciones de agregación
- Técnica SQL # 3: Identificación de valores extremos
- Técnica SQL n. ° 4: corte de datos
- Técnica SQL n. ° 5: limitación de datos
- Técnica SQL n. ° 6: clasificación de datos
- Técnica SQL n. ° 7: patrones de filtrado
- Técnica SQL n. ° 8: agrupaciones, acumulación de datos y filtrado en grupos
Primero comprendamos el conjunto de datos
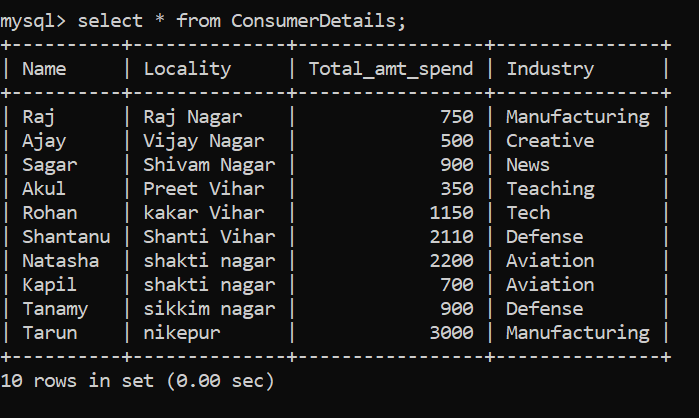
¿Cuál es la mejor forma de aprender a analizar datos? ¡Realizándolo uno al lado del otro en un conjunto de datos! Para este propósito, he creado un conjunto de datos ficticio de una tienda minorista. La tabla de datos del cliente está representada por ConsumerDetails.
Nuestro conjunto de datos consta de las siguientes columnas:
- Nombre – El nombre del consumidor
- Localidad – La localidad del cliente
- Total_amt_spend – La cantidad total de dinero gastado por el consumidor en la tienda.
- Industria – Significa la industria a la que pertenece el consumidor
Nota: – Usaré MySQL 5.7 para avanzar en el artículo. Puedes descargarlo desde aquí – Descargas de My SQL 5.7.
Técnica SQL n. ° 1: recuento de filas y elementos
Comenzaremos nuestro análisis con la consulta más simple, es decir, contando el número de filas en nuestra tabla. Haremos esto usando la función – COUNT ().
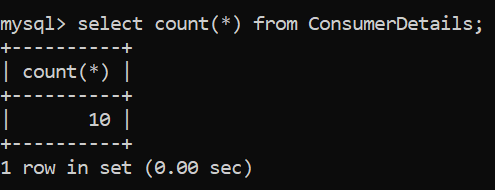
¡Excelente! Ahora sabemos el número de filas en nuestra tabla, que es 10. Puede parecer divertido usar esta función en un pequeño conjunto de datos de prueba, ¡pero puede ayudar mucho cuando sus filas llegan a millones!
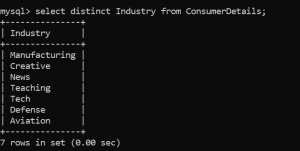
Muchas veces, nuestra tabla de datos está llena de valores duplicados. Para alcanzar el valor único, usamos la función DISTINCTLa palabra "DISTINCT" en inglés se traduce al español como "distinto" o "diferente". En el ámbito de la programación y las bases de datos, especialmente en SQL, se utiliza para eliminar duplicados en los resultados de consultas. Al aplicar la cláusula DISTINCT, se obtienen solo los valores únicos de un conjunto de datos, lo que facilita el análisis y la presentación de información relevante y no redundante.....
En nuestro conjunto de datos, ¿cómo podemos encontrar las industrias únicas a las que pertenecen los clientes?
Lo has adivinado bien. Podemos hacer esto usando la función DISTINCT.
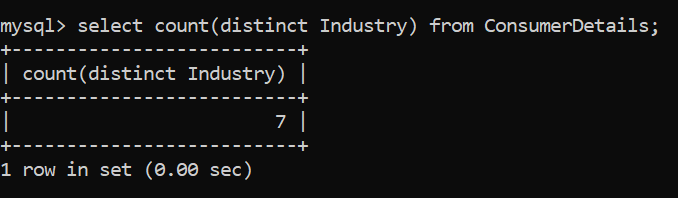
Incluso puede contar el número de filas únicas utilizando el recuento junto con distintos. Puede consultar la siguiente consulta:
Técnica SQL # 2 – Funciones de agregación
Las funciones de agregación son la base de cualquier tipo de análisis de datos. Nos brindan una descripción general del conjunto de datos. Algunas de las funciones que discutiremos son: SUM (), AVG () y STDDEV ().
Usamos el SUMA() función para calcular la suma de la columna numérica en una tabla.
Averigüemos la suma del monto gastado por cada uno de los clientes:
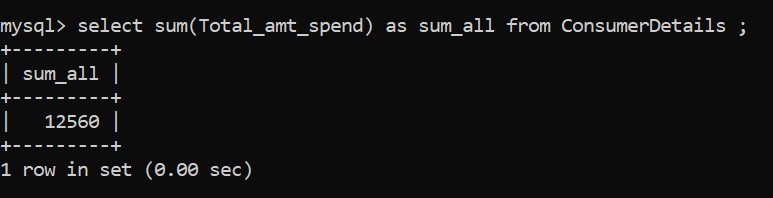
En el ejemplo anterior, suma_todos es la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... en la que se almacena el valor de la suma. La suma de la cantidad de dinero gastada por los consumidores es de Rs. 12.560.
Para calcular el promedio de las columnas numéricas, usamos el AVG () función. Encontremos el gasto promedio de los consumidores para nuestra tienda minorista:
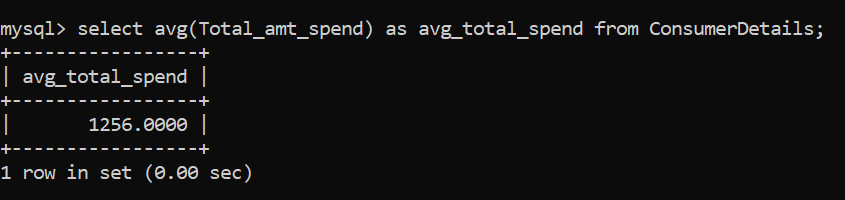
La cantidad promedio gastada por los clientes en la tienda minorista es de Rs. 1256.
-
Calcular la desviación estándar
Si ha mirado el conjunto de datos y luego el valor promedio del gasto de los consumidores, habrá notado que falta algo. El promedio no proporciona una imagen completa, así que busquemos otra métrica importante: la desviación estándar. La función es STDDEV ().
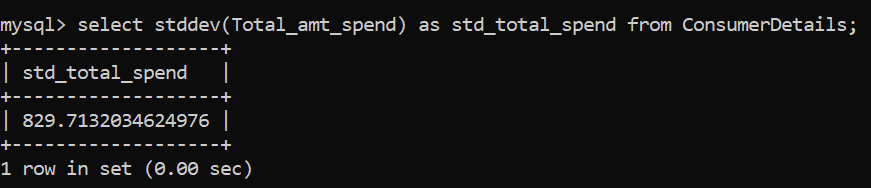
La desviación estándar resulta ser 829,7, lo que significa que hay una gran disparidad entre los gastos de los consumidores.
Técnica SQL # 3 – Identificación de valores extremos
El siguiente tipo de análisis es identificar los valores extremos que le ayudarán a comprender mejor los datos.
El valor numérico máximo se puede identificar mediante la función MAX (). Veamos cómo aplicarlo:
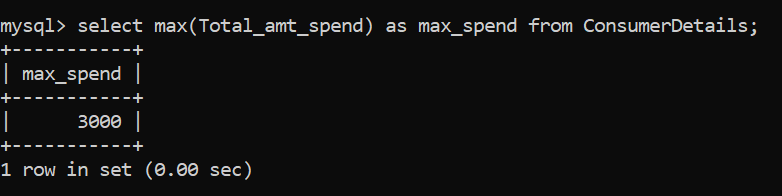
La cantidad máxima de dinero que gasta el consumidor en la tienda minorista es de Rs. 3000.
Similar a la función max, tenemos la función MIN () para identificar el valor numérico mínimo en una columna dada:
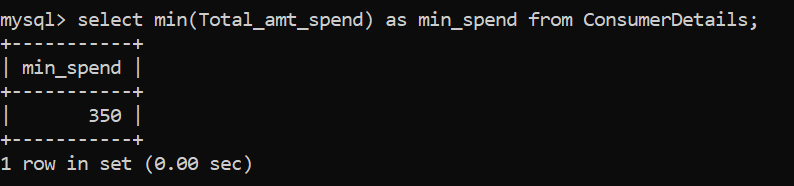
La cantidad mínima de dinero gastada por el consumidor de la tienda minorista es de Rs. 350.
Técnica SQL n. ° 4: corte de datos
Ahora, centrémonos en una de las partes más importantes del análisis de datos: dividir los datos. Esta sección del análisis formará la base para consultas avanzadas y lo ayudará a recuperar datos basados en algún tipo de condición.
- Digamos que la tienda minorista quiere encontrar clientes que provengan de una localidad, específicamente Shakti Nagar y Shanti Vihar. ¿Cuál será la consulta para esto?
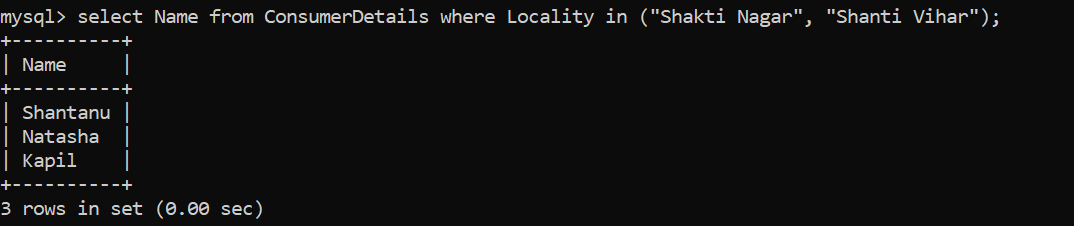
¡Genial, tenemos 3 clientes! Hemos utilizado la cláusula WHERE"WHERE" es un término en inglés que se traduce como "dónde" en español. Se utiliza para hacer preguntas sobre la ubicación de personas, objetos o eventos. En contextos gramaticales, puede funcionar como adverbio de lugar y es fundamental en la formación de preguntas. Su correcta aplicación es esencial en la comunicación cotidiana y en la enseñanza de idiomas, facilitando la comprensión y el intercambio de información sobre posiciones y direcciones.... para filtrar los datos en función de la condición de que los consumidores deberían vivir en la localidad: Shakti Nagar y Shanti Vihar. No usé la condición OR aquí. En su lugar, he usado el operador IN que nos permite especificar múltiples valores en la cláusula WHERE.
- Necesitamos encontrar a los clientes que viven en localidades específicas (Shakti Nagar y Shanti Vihar) y gastar una cantidad mayor a Rs. 2000.

En nuestro conjunto de datos, solo Shantanu y Natasha cumplen estas condiciones. Como deben cumplirse ambas condiciones, la condición AND se adapta mejor aquí. Veamos otro ejemplo para dividir nuestros datos.
- Esta vez, la tienda minorista quiere recuperar a todos los consumidores que gastan entre Rs. 1000 y Rs. 2000 para impulsar ofertas especiales de marketing. ¿Cuál será la consulta para esto?
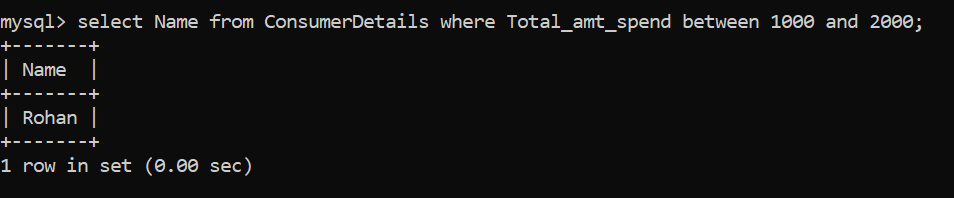
Otra forma de escribir la misma declaración sería:

¡Solo Rohan está despejando este criterio!
¡Excelente! Hemos llegado a la mitad de nuestro viaje. Construyamos más sobre el conocimiento que hemos adquirido hasta ahora.
Técnica SQL n. ° 5: limitación de datos
Digamos que queremos ver la tabla de datos que consta de millones de registros. No podemos usar la instrucción SELECTEl comando "SELECT" es fundamental en SQL, utilizado para consultar y recuperar datos de una base de datos. Permite especificar columnas y tablas, filtrando resultados mediante cláusulas como "WHERE" y ordenando con "ORDER BY". Su versatilidad lo convierte en una herramienta esencial para la manipulación y análisis de datos, facilitando la obtención de información específica de manera eficiente.... directamente ya que esto volcaría la tabla completa en nuestra pantalla, lo cual es engorroso y computacionalmente intensivo. En su lugar, podemos usar el LÍMITE cláusula:
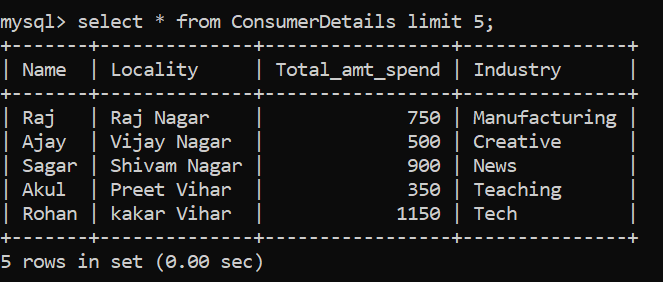
El comando SQL anterior nos ayuda a mostrar las primeras 5 filas de la tabla.
¿Qué hará si solo desea seleccionar la cuarta y quinta filas? Haremos uso de la cláusula OFFSET. La cláusula OFFSET omitirá el número especificado de filas. Vamos a ver cómo funciona:
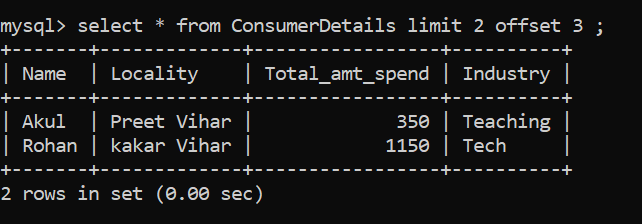
Técnica SQL n. ° 6: clasificación de datos
Ordenar datos nos ayuda a poner nuestros datos en perspectiva. Podemos realizar el proceso de clasificación usando la palabra clave – ORDER BYEl comando "ORDER BY" en SQL se utiliza para ordenar los resultados de una consulta en función de una o más columnas. Permite especificar el orden ascendente (ASC) o descendente (DESC) de los datos, facilitando la visualización y análisis de la información. Es una herramienta esencial para organizar datos en bases de datos, mejorando la comprensión y el acceso a la información relevante.....
La palabra clave se puede utilizar para clasificar los datos en orden ascendente o descendente. La palabra clave ORDER BY ordena los datos en orden ascendente de forma predeterminada.
Veamos un ejemplo en el que ordenamos los datos según la columna Total_amt_spend en orden ascendente:
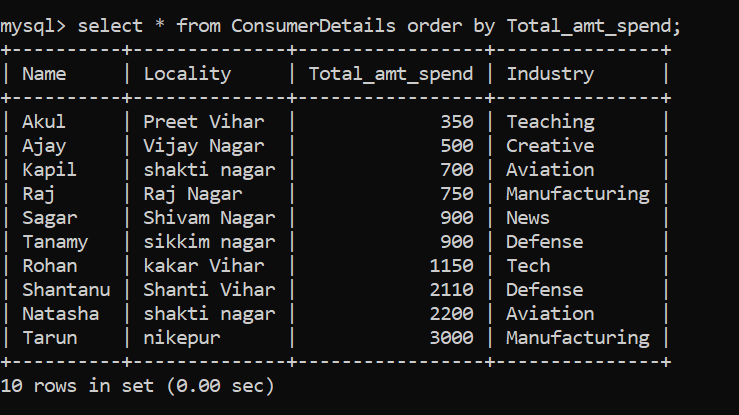
¡Impresionante! Para ordenar el conjunto de datos en orden descendente, podemos seguir el siguiente comando:
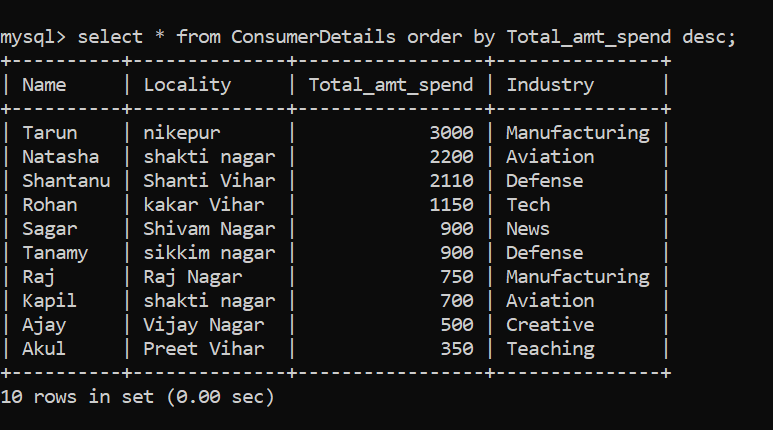
Técnica SQL # 7 – Patrones de filtrado
En las secciones anteriores, aprendimos cómo filtrar los datos en función de una o varias condiciones. Aquí, aprenderemos a filtrar las columnas que coinciden con un patrón específico. Para seguir adelante con esto, primero entenderemos el operador LIKE y los caracteres comodín.
El operador LIKE se usa en una cláusula WHERE para buscar un patrón específico en una columna.
El carácter comodín se utiliza para sustituir uno o más caracteres en una cadena. Estos se utilizan junto con el operador LIKE. Los dos caracteres comodín más comunes son:
-
- %: Representa 0 o más caracteres
- _ – Representa un solo carácter
En nuestro conjunto de datos minoristas ficticios, digamos que queremos todas las localidades que terminan con “Nagar”. Tómese un momento para comprender el enunciado del problema y piense cómo podemos resolverlo.
Intentemos resolver el problema. Requerimos todas las localidades que terminan con «Nagar» y pueden tener cualquier número de caracteres antes de esta cadena en particular. Por lo tanto, podemos hacer uso del comodín «%» antes de «Nagar»:
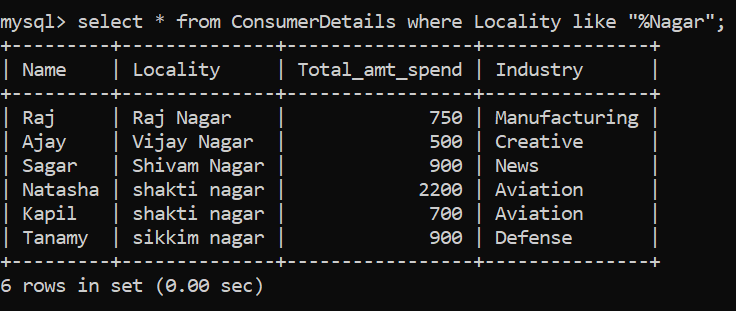
Impresionante, tenemos 6 localidades que terminan con este nombre. Observe que estamos usando el operador LIKE para realizar la coincidencia de patrones.
A continuación, intentaremos resolver otro problema basado en patrones. Queremos los nombres de los consumidores cuyo segundo carácter tiene «a» en sus respectivos nombres. Nuevamente, le sugiero que se tome un momento para comprender el problema y pensar en una lógica para resolverlo.
Analicemos el problema. Aquí, el segundo carácter debe ser «a». El primer carácter puede ser cualquier cosa, por lo que sustituimos esta letra por el comodín “_”. Después del segundo carácter, puede haber cualquier número de caracteres, por lo que sustituimos esos caracteres con el comodín «%». La coincidencia de patrones final se verá así:
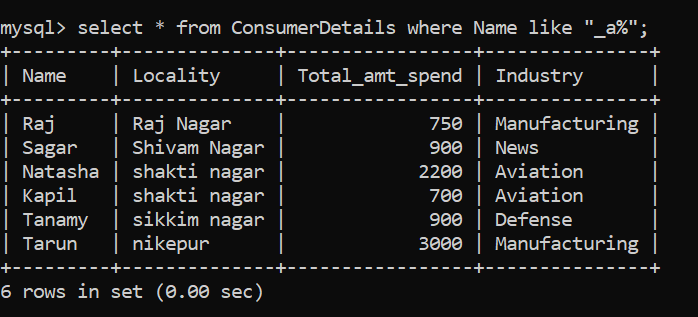
¡Tenemos 6 personas que satisfacen esta extraña condición!
Técnica SQL n. ° 8: agrupaciones, acumulación de datos y filtrado en grupos
Finalmente hemos llegado a una de las herramientas de análisis más poderosas en SQL: la agrupación de datos que se realiza utilizando la instrucción GROUP BYLa cláusula "GROUP BY" en SQL se utiliza para agrupar filas que comparten valores en columnas específicas. Esto permite realizar funciones de agregación, como SUM, COUNT o AVG, sobre los grupos resultantes. Su uso es fundamental para analizar datos y obtener resúmenes estadísticos. Es importante recordar que todas las columnas seleccionadas que no forman parte de una función de agregación deben incluirse en la cláusula "GROUP BY"..... La aplicación más útil de esta declaración es encontrar la distribución de variables categóricas. Esto se hace usando la instrucción GROUP BY junto con funciones de agregación como – COUNT, SUM, AVG, etc.
Tratemos de entender esto mejor tomando un enunciado del problema. La tienda minorista desea encontrar el número de clientes correspondiente a las industrias a las que pertenece:

Observamos que el recuento de clientes pertenecientes a las distintas industrias es más o menos el mismo. Entonces, avancemos y encontremos la suma de los gastos de los clientes agrupados por la industria a la que pertenecen:
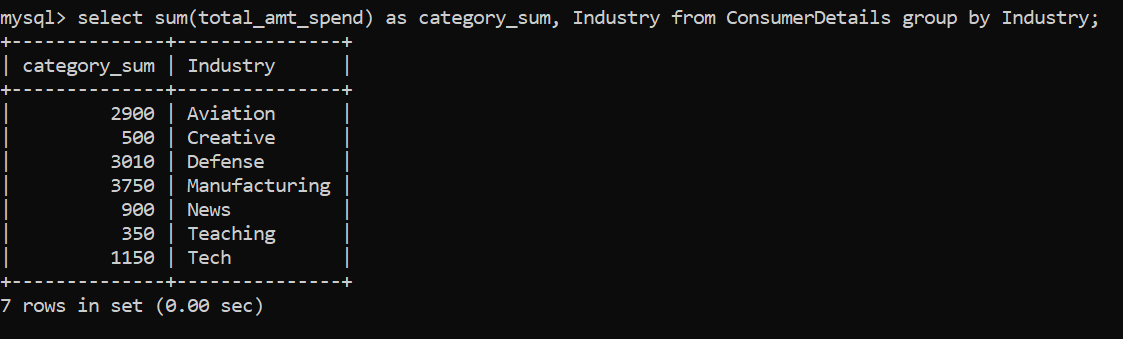
Podemos observar que la máxima cantidad de dinero gastada es por los clientes pertenecientes a la Fabricación industria. Esto parece un poco fácil, ¿verdad? Demos un paso adelante y lo hagamos más complicado.
Ahora, el minorista quiere encontrar las industrias cuyas Suma total es mayor que 2500. Para resolver este problema, volveremos a agrupar los datos según la industria y luego usaremos la cláusula HAVINGEl verbo "haber" en español es un auxiliar fundamental que se utiliza para formar tiempos compuestos. Su conjugación varía según el tiempo y el sujeto, siendo "he", "has", "ha", "hemos", "habéis" y "han" las formas del presente. Además, en algunas regiones, se usa "haber" como un verbo impersonal para indicar existencia, como en "hay" para "there is/are". Su correcta utilización es esencial para una comunicación efectiva en español.....
La cláusula HAVING es como la cláusula WHERE pero solo para filtrar los datos agrupados. Recuerde, siempre vendrá después de la instrucción GROUP BY.

Tenemos solo 3 categorías que satisfacen las condiciones: Aviación, Defensa, y Fabricación. Pero para hacerlo más claro, también agregaré la palabra clave ORDER BY para hacerlo más intuitivo:

Notas finales
Estoy muy contento de que hayas llegado tan lejos. Estos son los componentes básicos de todas las consultas de análisis de datos en SQL. También puede realizar consultas avanzadas utilizando estos fundamentos. En este artículo, utilicé MySQL 5.7 para establecer los ejemplos.
Realmente espero que estas consultas SQL le ayuden en su día a día cuando esté analizando datos complejos. ¿Tiene alguno de sus consejos y trucos para analizar datos en SQL? ¡Házmelo saber en los comentarios!





